

Skrobanie sieci może wydawać się proste, ale może okazać się dość złożonym przedsięwzięciem. Wielu właścicieli witryn stara się aktywnie chronić przed nimi w celu ochrony swoich danych, co w większości wyklucza uruchomienie wewnętrznego skryptu do wielokrotnego pobierania danych z witryn docelowych. Do wydajnego skrobania potrzebne jest specjalistyczne narzędzie, takie jak API Scrapestack które mamy zamiar przejrzeć. Korzystając z niego, możesz szybko i skutecznie zeskrobać prawie każdą stronę internetową oraz wyodrębnić zawarte w niej informacje i odpowiednio je wykorzystać. Scrapestack zapewnia szybki i łatwy w użyciu oraz wysoce skalowalny sposób zgarniania stron internetowych.

Zanim przejdziemy do bardziej szczegółowych informacji na temat API Scrapestackzaczniemy od omówienia skrobania. Wyjaśnimy, co to jest i dlaczego jest tak szeroko stosowane w Internecie. Mówiąc o Internecie, przyjrzymy się konkretnemu przypadkowi skrobania Internetu, ponieważ właśnie to API Scrapestack jest stworzony do tego, a my przedstawimy również niektóre z najważniejszych powodów, dla których ktokolwiek używałby interfejsu API zgarniającego innej firmy, takiego jak ten. Po krótkim wyjaśnieniu, czym jest interfejs API REST, w końcu przejdziemy do sedna sprawy, gdy go przedstawimy API Scrapestack. Najpierw omówimy produkt, a następnie przeanalizujemy niektóre z jego najlepszych funkcji. Zobaczymy, jak łatwe jest korzystanie z interfejsu API, zanim przedstawimy wielopoziomową strukturę cenową usługi.
Spis treści:
Skrobanie w pigułce
Skrobanie danych to proces wydobywania danych z danych wyjściowych czytelnych dla człowieka pochodzących z innego programu lub procesu. Różni się od innych form przesyłania danych na kilka sposobów. Przesyłanie danych między programami odbywa się zwykle przy użyciu struktur danych odpowiednich do automatycznego przetwarzania przez komputery. Te formaty i protokoły wymiany są sztywno ustrukturyzowane, dobrze udokumentowane, łatwe do analizy i utrzymują dwuznaczność na minimalnym poziomie. Te transmisje zazwyczaj nie są w ogóle czytelne dla człowieka. Są zaprojektowane tak, aby były wydajne i szybkie. Głównym elementem odróżniającym zgarnianie danych od innych form wymiany danych jest to, że dane wyjściowe, które są zgarniane, są zwykle przeznaczone do wyświetlania użytkownikowi końcowemu, a nie jako dane wejściowe do innego programu. W związku z tym rzadko jest dokumentowany lub konstruowany w celu wygodnego parsowania.
Istnieje kilka powodów, dla których warto sięgać po dane. Na przykład najczęściej wykonuje się to albo w celu połączenia ze starszym systemem, który nie ma innego mechanizmu kompatybilnego z obecnymi mechanizmami przesyłania. Można go również użyć do pobrania danych z systemu innej firmy, który nie zapewnia wygodniejszego interfejsu API. W tym ostatnim przypadku właściciel systemu zewnętrznego może postrzegać zgarnianie danych jako niepożądane z powodów takich jak zwiększone obciążenie systemu, utrata przychodów z reklam lub utrata kontroli nad zawartością informacji.
Choć jest to powszechne, skrobanie danych jest zwykle uważane za doraźną, nieelegacyjną technikę, która jest często stosowana w ostateczności, gdy nie jest dostępny żaden inny mechanizm wymiany danych. Skrobanie danych jest często związane z wyższym nakładem programowania i przetwarzania, ponieważ wyświetlacze wyjściowe przeznaczone do spożycia przez ludzi często często zmieniają strukturę. Chociaż ludzie mogą łatwo dostosować się do tych zmian, program komputerowy może nie zostać poproszony o odczyt danych w określonym formacie lub z określonej lokalizacji bez wiedzy na temat sprawdzania poprawności wyników.
Szczególny przypadek skrobania sieci
Skrobanie stron internetowych to po prostu określony rodzaj zgrywania danych, który służy do pobierania danych ze stron internetowych. Jak wiadomo, strony internetowe są tworzone przy użyciu tekstowych języków znaczników, takich jak HTML i XHTML. Są one jednak zwykle zaprojektowane dla użytkowników końcowych będących ludźmi, a nie dla łatwości zautomatyzowanego użytkowania. Jest to główny powód, dla którego skrobaki internetowe, takie jak API Scrapestack zostały stworzone. Skrobaczka to interfejs API lub narzędzie, które wyodrębnia dane ze strony internetowej.
Ponieważ organizacje zazwyczaj bardzo chronią swoje dane, duże witryny zwykle używają algorytmów obronnych, aby chronić je przed skrobaczkami. Mogą na przykład ograniczyć liczbę żądań, które może wysłać IP lub sieć IP. Najlepsze narzędzia do skrobania sieci obejmują mechanizmy przeciwdziałające tym zabezpieczeniom.
Korzystanie z interfejsu API zgarniającego innej firmy
Usuwanie danych z prostej, statycznej strony internetowej jest raczej łatwe do wdrożenia. Niestety, proste, statyczne strony internetowe należą do odległej przeszłości, a najnowocześniejsze strony internetowe używają różnych technologii, aby zapewnić dynamiczną treść odwiedzającym. W tym przypadku skorzystanie z narzędzia innej firmy może być korzystne. Narzędzia te zajmą się wszystkimi szczegółami i pojawią się w witrynie, którą próbują zeskrobać jako zwykły użytkownik. Niektórzy posuną się nawet za wypełnianie formularzy. Ale najlepszym powodem, dla którego ktokolwiek użyłby narzędzia do skrobania innych firm, takiego jak API Scrapestack jest wygoda. Korzystanie z niego po prostu znacznie ułatwia.
Co to jest interfejs API REST?
Interfejs API, który oznacza interfejs programowania aplikacji, jest sposobem na wywołanie jednego programu lub procesu z innego. Co więcej, wywołany proces nie musi nawet działać na tym samym urządzeniu co odbiorca. Jeśli chodzi o część REST, jest to nieco bardziej skomplikowane. Spróbujmy wyjaśnić.
REST (skrót od REpresentational State Transfer) to styl architektury oprogramowania, który określa zestaw ograniczeń, które należy stosować do tworzenia usług internetowych. Te, które są zgodne ze stylem architektonicznym REST, nazywane są usługami internetowymi RESTful i oferują interoperacyjność między systemami komputerowymi w Internecie. Ponadto umożliwiają systemom żądającym dostęp do tekstowych reprezentacji różnych zasobów sieciowych i manipulowanie nimi za pomocą jednolitego i predefiniowanego zestawu operacji bezstanowych.
Mówiąc prościej, interfejs API REST to taki, do którego można łatwo uzyskać dostęp za pomocą standardowych wywołań internetowych, takich jak HTTP „get”, „post”, „put” i „delete”, i które zwracają żądane dane w zorganizowany sposób. W konkretnym przypadku API Scrapestack, wykorzystuje popularny format JSON. Wyniki można zatem łatwo przetwarzać przy użyciu popularnych języków, takich jak Javascript. Inne narzędzia mogą korzystać z innych formatów, przy czym XML jest niezwykle popularny. Specyfikacja REST nakazuje jedynie stosowanie ustalonego, predefiniowanego formatu.
Przedstawiamy The Scrapestack API
The API Scrapestack jest, musisz to rozgryźć, API REST do zgarniania stron internetowych. Krótko mówiąc, Scrapestack API może zamienić dowolną stronę internetową w dane, które można wykorzystać. Jest to usługa API oparta na chmurze, która pozwala użytkownikom na zeskrobywanie stron internetowych bez martwienia się o problemy techniczne, takie jak serwery proxy, bloki IP, kierowanie geograficzne, rozwiązywanie problemów CAPTCHA i inne. Aby go użyć, wystarczy podać prawidłowy adres URL witryny, a w ciągu kilku milisekund interfejs API Scrapestack zwróci pełną treść HTML witryny w odpowiedzi. Otrzymana zawartość będzie wyświetlana w widoku przeglądarki, w tym renderowanie JavaScript, a nie rzeczywisty kod, który jest częścią strony internetowej. Narzędzie jest napędzane przez jeden z najmocniejszych na rynku silników do zgarniania i oferuje jedno z najlepszych rozwiązań dla wszystkich twoich wymagań dotyczących zgarniania.
The API Scrapestack jest rozwijany i utrzymywany przez warstwa, firma z siedzibą w Londynie w Wielkiej Brytanii i Wiedniu w Austrii. Jest to ta sama firma, która stoi za kilkoma popularnymi produktami API i SaaS na całym świecie, w tym stertą pogody, fakturowaniem i projektowaniem. Z tej potężnej infrastruktury korzysta ponad 2000 organizacji na całym świecie. Obecnie usługa online, która jest zbudowana do przetwarzania milionów adresów IP proxy, przeglądarek i CAPTCHA, obsługuje ponad miliard żądań miesięcznie i oferuje imponujący średni czas sprawności 99,9%. Gwarantuje to, że usługa będzie dostępna, gdy jej potrzebujesz.
Przewodnik po głównych funkcjach API Scrapestack
Jeśli chodzi o funkcje, API Scrapestack nie pozostawia wiele do życzenia, bez względu na to, dlaczego musisz zeskrobać strony internetowe lub jakie dane chcesz uzyskać, produkt najprawdopodobniej doskonale pasuje do twoich potrzeb. Omówmy pokrótce niektóre z najważniejszych funkcji tego narzędzia.
Miliony serwerów proxy i adresów IP
Jednym ze sposobów ochrony stron internetowych przed skrobaniem jest identyfikacja źródłowych adresów IP generujących wiele kolejnych żądań. Z tego powodu narzędzie do skrobania stron internetowych musi używać różnych adresów IP dla każdego żądania. The API Scrapestack rozwiązuje ten problem, oferując ogromną pulę ponad trzydziestu pięciu milionów adresów IP w centrach danych i serwerach pośredniczących, rozmieszczonych w kilkudziesięciu globalnych dostawcach usług internetowych, a także obsługując prawdziwe urządzenia, inteligentne próby i rotację adresów IP. Zapewnia to, że żądania zgarniania najprawdopodobniej pozostaną niezauważone w witrynach, które są zeskrobywane.
Najczęściej używane są centrum danych lub „standardowe” proxy. Nie są własnością żadnego konkretnego dostawcy usług internetowych i po prostu maskują początkowy adres IP, wyświetlając źródłowy adres IP proxy centrum danych i informacje powiązane z firmą, która jest właścicielem odpowiedniego centrum danych.
Jeśli chodzi o serwery proxy do zastosowań domowych lub „premium”, zapewniają one adresy IP, które są podłączone do rzeczywistych adresów domowych i urządzeń domowych. To znacznie zmniejsza prawdopodobieństwo zablokowania ich podczas skrobania sieci. Korzystanie z pośredniczących serwerów pośredniczących w usuwaniu stron internetowych ułatwia obchodzenie się z treściami blokowanymi geograficznie i gromadzenie dużych ilości danych.
Ponad sto globalnych lokalizacji
Niektóre witryny zwracają różne informacje w zależności od lokalizacji, z której pochodzi żądanie. Podobnie niektóre witryny akceptują żądania tylko z niektórych lokalizacji. Jednym z takich przykładów jest strona internetowa taka jak Netflix, która akceptuje tylko lokalne połączenia przychodzące. Netflix w USA jest dostępny tylko z adresów IP z siedzibą w USA, a kanadyjski Netflix jest dostępny tylko z kanadyjskich adresów IP. The API Scrapestack pozwala wybrać spośród ponad stu obsługiwanych globalnych lokalizacji w celu wysyłania żądań API do zgarniania stron internetowych. Masz również możliwość korzystania z losowych celów geograficznych, obsługujących szereg dużych miast na całym świecie.
Solidna infrastruktura
Usługa oparta na chmurze, taka jak API Scrapestack jest tak dobry, jak infrastruktura, na której jest zbudowany. W tym celu jest to solidna usługa z imponującym czasem sprawności. Korzystanie z usługi pozwala zgarniać sieć z niezrównaną prędkością. Będziesz także korzystać z wielu zaawansowanych funkcji, takich jak współbieżne żądania API, rozwiązywanie CAPTCHA, obsługa przeglądarki i renderowanie JS. Usługa jest zbudowana na bazie warstwa infrastruktura chmurowa. To sprawia, że usługa jest wysoce skalowalna i jest w stanie obsłużyć wszystko – od tysięcy żądań API miesięcznie aż do milionów dziennie. Jest zasilany przez system, który skaluje się w górę i w dół w zależności od potrzeb i może zapewnić najwyższy możliwy czas odpowiedzi na każde żądanie API na dowolnym poziomie wykorzystania.
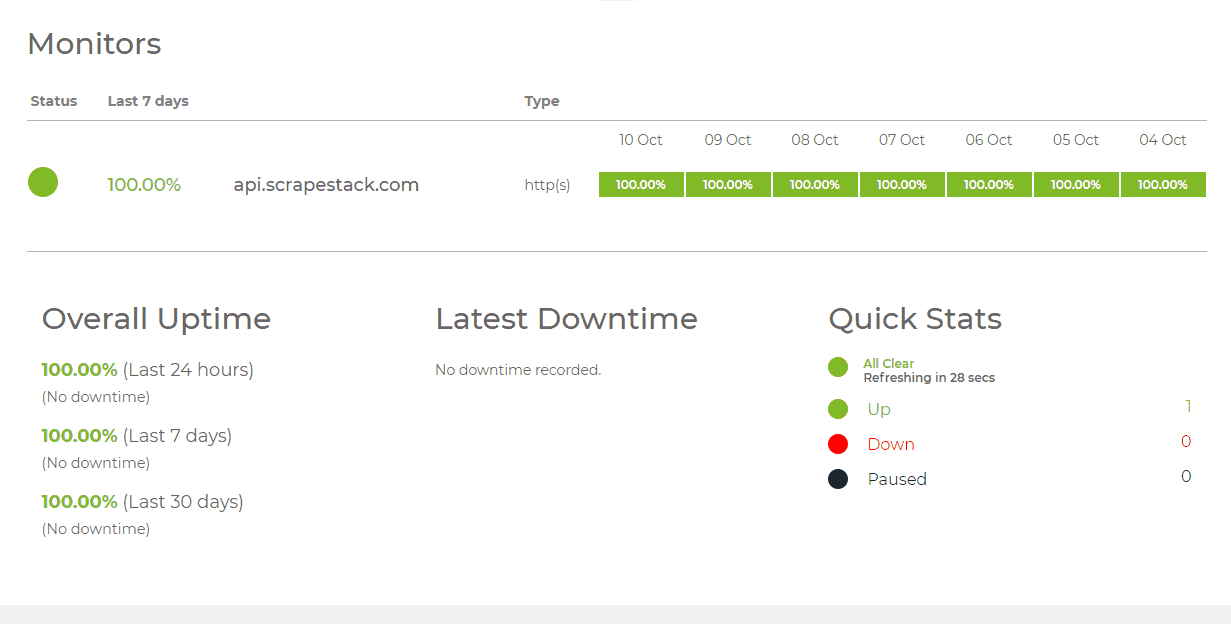
Za pomocą The Kosz na śmieci API
Używając API Scrapestack jest tak proste, jak to tylko możliwe. Pierwszym krokiem jest oczywiście założenie konta. Utworzenie go ujawni unikalny klucz dostępu API, którego należy użyć przy każdym żądaniu do uwierzytelnienia przy pomocy API. Robisz to, dodając parametr access_key do podstawowego adresu URL interfejsu API i ustawiając go na klucz dostępu API.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY
Płatne plany obsługują 256-bitowe szyfrowanie HTTPS. Aby go użyć, wystarczy użyć HTTPS zamiast HTTP w wywołaniach API.
Najbardziej podstawowy typ żądania jest trafnie określany jako „podstawowy” wniosek. W najbardziej podstawowej formie wystarczy podać klucz dostępu do interfejsu API i adres URL strony, którą chcesz zeskrobać. Na przykład, aby zeskrobać stronę https://apple.com, żądanie wygląda następująco:
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com
Pamiętaj, że do żądań można dodać kilka opcjonalnych parametrów. Za chwilę omówimy niektóre z nich bardziej szczegółowo.
Po pomyślnym wykonaniu interfejs API odpowiada surowymi danymi HTML docelowego adresu URL strony internetowej. Oto jak wygląda typowa odpowiedź na podstawowe zapytanie. Pamiętaj, że został skrócony w celu zwiększenia czytelności. Rzeczywista odpowiedź obejmowałaby cały kod w pliku
i Sekcje.(...) // 44 lines skipped (...) // 394 lines skipped
Parametry opcjonalne
Pierwszym i najczęściej używanym parametrem opcjonalnym jest z pewnością Renderowanie JavaScript. Jest dostępny we wszystkich płatnych planach. Jak wiadomo, niektóre strony internetowe wyświetlają niezbędne elementy strony przy użyciu JavaScript. Oznacza to, że przy początkowym ładowaniu strony niektóre treści nie są obecne – a zatem nie można ich zeskrobać. Po włączeniu parametru render_js, API Scrapestack uzyska dostęp do sieci docelowej za pomocą przeglądarki bezgłowej (Google Chrome) i pozwoli na renderowanie elementów strony JavaScript przed dostarczeniem ostatecznego wyniku skrobania. Włączenie tej opcji polega na dodaniu parametru render_js do adresu URL żądania interfejsu API i ustawieniu go na 1.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & render_js = 1
Kolejnym przydatnym parametrem opcjonalnym jest możliwość określenia Lokalizacje proxy, dostępne również we wszystkich płatnych planach. The API Scrapestack korzysta z puli ponad 35 milionów adresów IP na całym świecie. Domyślnie automatycznie obróci adresy IP w taki sposób, że ten sam adres IP nigdy nie będzie używany dwa razy z rzędu. Korzystając z opcjonalnego parametru API proxy_location, możesz wybrać konkretny kraj, podając jego dwuliterowy kod kraju. Na przykład w poniższym przykładzie podano au (Australia) jako lokalizację proxy. Zapytanie zostanie zatem uruchomione z adresu IP z Australii.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & proxy_location = au
The Premium Proxy to kolejna interesująca opcja. Oto jak to działa. Domyślnie API Scrapestack zawsze używa standardowych serwerów proxy (centrum danych) do zgrywania żądań. I chociaż są one najczęściej używanymi serwerami proxy w Internecie, są również znacznie bardziej prawdopodobne, że zostaną zablokowane podczas próby zeskrobania danych.
Jeśli subskrybujesz abonament profesjonalny lub wyższy, API Scrapestack umożliwia dostęp do serwerów proxy premium (mieszkaniowych). Są one powiązane z prawdziwymi adresami zamieszkania i dlatego znacznie mniej prawdopodobne jest ich zablokowanie podczas skrobania danych w Internecie. Podobnie jak inne parametry opcjonalne, użycie tej opcji polega jedynie na dodaniu parametru premium_proxy do żądania zgarniania i ustawieniu go na 1.
https://api.scrapestack.com/scrape ? access_key = YOUR_ACCESS_KEY & url = https://apple.com & premium_proxy = 1
Chociaż możemy kontynuować przez dłuższy czas, obejmując wiele opcji dostępnych w API Scrapestack, naszym celem jest sprawdzenie produktu, a nie napisanie instrukcji obsługi. Poza tym Kosz na śmieci Witryna ma bardzo dokładną dokumentację i powinna być głównym źródłem informacji na temat tego, jak to zrobić.
Informacje o cenie
The API Scrapestack usługa jest dostępna w ramach kilku planów cenowych. Na najniższym poziomie Bezpłatny plan oferuje sposób na zapoznanie się z interfejsem API. Ma podstawową funkcjonalność API i ograniczenie do 10 000 żądań API miesięcznie. Jeśli chcesz uruchomić więcej zapytań lub potrzebujesz bardziej zaawansowanego zestawu funkcji, takich jak współbieżne żądania lub dostęp do proxy Premium, możesz wybrać jeden z dostępnych płatnych planów.
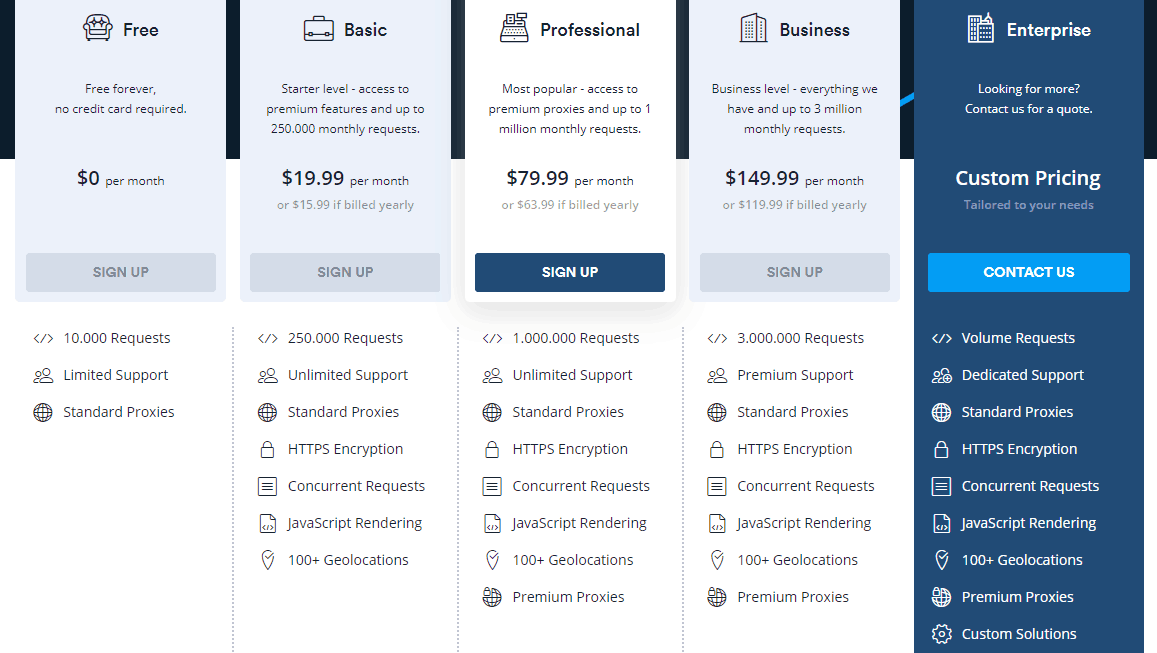
W przypadku większości płatnych planów oferujących podobny zestaw funkcji decydującym czynnikiem, jeśli chodzi o wymagania techniczne, będzie często liczba żądań interfejsu API, które należy składać co miesiąc. Płatności można dokonać kartą kredytową lub PayPal. Ponadto klienci korporacyjni i klienci o dużych obrotach mogą poprosić o włączenie rocznych płatności przelewem bankowym. Mówiąc o rocznej płatności, wybranie tej opcji uprawnia cię do 20% rabatu w porównaniu do płatności miesięcznych, dzięki czemu produkt jest jeszcze bardziej przystępny. Jeśli nie masz pewności co do częstotliwości rozliczeń, pamiętaj, że możesz (względnie) łatwo przełączyć się z miesięcznego na roczny iz powrotem. Obejmuje to jednak najpierw obniżenie abonamentu bezpłatnego i natychmiastowe przejście do abonamentu płatnego.
Dolna linia
Bez względu na to, jak proste lub skomplikowane może być potrzeby skrobania sieci, API Scrapestack najprawdopodobniej pomoże Ci osiągnąć cele w prosty i łatwy sposób. Z imponującą niezawodnością i skalowalnością. Ta usługa w chmurze bezbłędnie dostosuje się do prawie każdej sytuacji. Ma wszystkie opcje, których może potrzebować, i oferuje środki, by sfałszować twoje próby zgarniania za milionami adresów IP.
Nadal nie jestem pewien, czy API Scrapestack jest odpowiedni dla ciebie? Dlaczego nie skorzystasz z dostępnego bezpłatnego abonamentu i wypróbujesz usługę w wersji próbnej? Jestem prawie pewien, że zaskoczy Cię moja ogólna użyteczność i wydajność.