
Graficzne bazy danych przechowują wysoce połączone, gęste dane i wydajnie przetwarzają zapytania. Ale czy wiesz, kiedy użyć której bazy danych wykresów? Przeczytaj, aby dowiedzieć się więcej.
„Dane to nowy olej”. Rozwój każdej organizacji opiera się na tym, jak efektywnie przechowują i wykorzystują dane. Każdego dnia generowanych jest 2,5 trylionów bajtów danych. Dlatego potrzebujemy odpornych na błędy systemów i magazynów, w których dane mogą być skutecznie przechowywane i zarządzane. Początkowo stosowano relacyjne bazy danych.
Jednak w miarę upływu czasu ilość i rodzaj danych szybko się zmieniały. W związku z tym pojawiła się potrzeba przechowywania wideo, audio, obrazów itp. Był to punkt wyjścia do rozwoju baz danych SQL, NoSQL, Hadoop, baz danych wykresów itp. Każda z nich ma swoje własne przypadki użycia i zajmuje się różnymi formatami danych. Bazy danych grafów zostały opracowane w celu uproszczenia operacji na danych i efektywnego przechowywania.
Spis treści:
Graficzne bazy danych
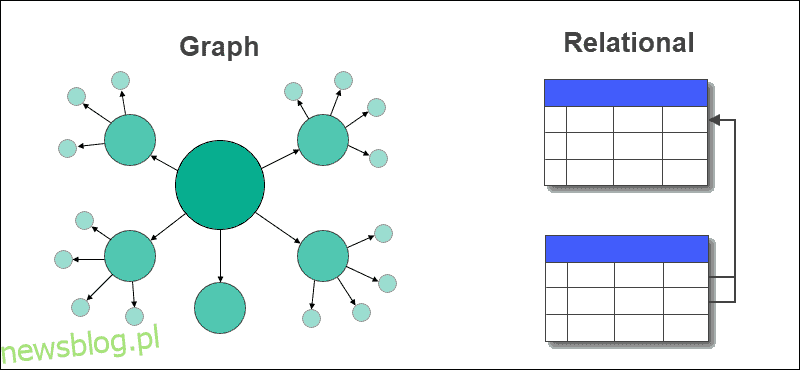
Wykres to struktura danych reprezentowana w postaci węzłów i krawędzi. Baza danych to zbiór tabel przechowujących dane i relacje między danymi. Wykresowa baza danych to baza danych, która przechowuje dane w węzłach oraz relacje istniejące w danych w postaci krawędzi. Grafowe bazy danych pomagają obsługiwać zapytania w czasie rzeczywistym i efektywnie zarządzać relacjami wiele-do-wielu między podmiotami.
Popularne modele danych wykresów obejmują wykresy właściwości i wykresy RDF. Analizy i zapytania są w większości wykonywane za pomocą wykresów właściwości. Integracja danych odbywa się za pomocą wykresów RDF. Różnica między grafami Property i RDF polega na tym, że grafy RDF są reprezentowane w postaci trójek, tj. podmiotu, predykatu i obiektu.
Bazy grafowe przechowują dane w węzłach oraz relacje między danymi w postaci krawędzi między węzłami. Krawędzie wykresu mogą być skierowane (jednokierunkowe) lub nieskierowane (dwukierunkowe).
Przetwarzanie zapytań odbywa się poprzez przechodzenie przez wykres. Algorytmy przechodzenia przez grafy, które pomagają znaleźć ścieżkę od jednego węzła do drugiego, odległość między węzłami, znaleźć wzorce, pętle na grafie oraz możliwość tworzenia klastrów itp., są wykorzystywane do skutecznego odpowiadania na zapytania.
Zastosowania grafowych baz danych
Do wykrywania oszustw wykorzystywane są grafowe bazy danych. Węzły / jednostki mogą być nazwiskami osób, adresami, datami urodzenia itp. oraz niektórymi fałszywymi adresami IP, numerami urządzeń itp. Gdy fałszywy węzeł wchodzi w interakcję z nieoszukanym węzłem, tworzone są między nimi łącza, które są oznaczane jako podejrzany.
Serwisy społecznościowe wykorzystują bazy danych wykresów, aby pokazać rekomendacje osób, z którymi możemy chcieć się połączyć, oraz treści, które chcemy przeglądać. Odbywa się to za pomocą przemierzania wykresów w bazie danych.
Mapowanie sieci i zarządzanie infrastrukturą, elementy konfiguracji itp. są również skutecznie przechowywane i zarządzane za pomocą grafowych baz danych.
Baza danych wykresów a relacyjna baza danych
W bazie danych wykresów tabele z wierszami i kolumnami są zastępowane węzłami i krawędziami. Relacje między danymi są przechowywane na krawędziach w grafowej bazie danych.
Relacyjna baza danych przechowuje relacje między tabelami przy użyciu kluczy obcych i innych tabel. Wyodrębnianie danych lub wykonywanie zapytań jest łatwe i nie wymaga złożonych złączeń w grafowej bazie danych, ale nie jest tak w przypadku relacyjnych baz danych.
Relacyjne bazy danych są najbardziej odpowiednie do przypadków użycia, które obejmują transakcje, podczas gdy bazy danych grafów są odpowiednie dla aplikacji o dużej liczbie relacji i danych.
Grafowe bazy danych obsługują dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane, podczas gdy relacyjne bazy danych muszą mieć ustalony schemat.
Grafowe bazy danych spełniają wymagania dynamiczne, podczas gdy relacyjne bazy danych są zwykle używane do rozwiązywania znanych i statycznych problemów.
 Wykres a relacyjne bazy danych
Wykres a relacyjne bazy danych
Przyjrzyjmy się teraz najlepszym grafowym rozwiązaniom baz danych.
Cayley
Cayley to graficzna baza danych o otwartym kodzie źródłowym opracowana przez Apache 2.0. Został zbudowany przy użyciu Go i działa na połączonych danych. Cayley to baza danych używana podczas budowania Freebase i wykresu wiedzy Google. Obsługuje wiele języków zapytań, takich jak MQL i JavaScript, z obiektem graficznym opartym na Gremlinie.
Jest łatwy w użyciu, szybki i ma budowę modułową. Może integrować się i współdziałać z różnymi sklepami zaplecza, takimi jak LevelDB, MongoDB i Bolt. Obsługuje różne interfejsy API innych firm napisane w wielu językach, takich jak Java, .NET, Rust, Haskell, Ruby, PHP, Javascript i Clojure. Można go wdrożyć w Docker i Kubernetes. Kluczowymi obszarami, w których używany jest Cayley, są technologie informacyjne, oprogramowanie komputerowe i usługi finansowe.
Amazonka Neptuna
Amazon Neptune jest znany z tego, że działa wyjątkowo dobrze na silnie połączonych zestawach danych. Jest niezawodny, bezpieczny, w pełni zarządzany i obsługuje otwarte API. Może przechowywać miliardy relacji i danych zapytań z bardzo niskim opóźnieniem wynoszącym kilka milisekund.
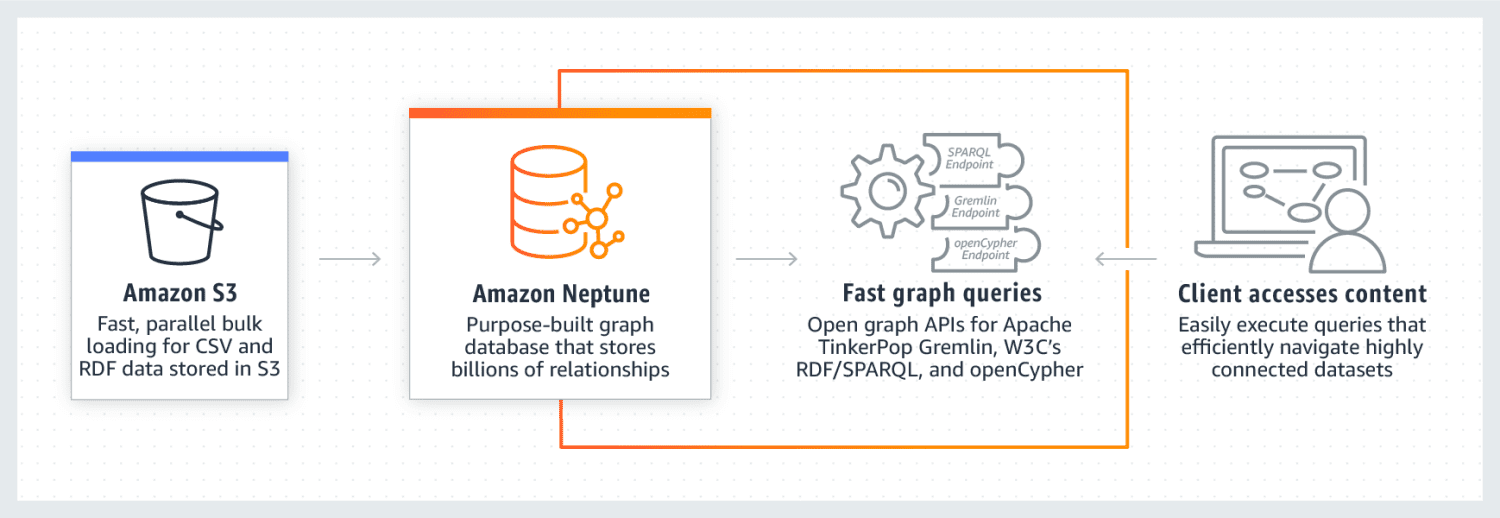
Model danych wykresu Neptuna składa się z 4 pozycji, a mianowicie podmiotu (S), predykatu (P), obiektu (O) i wykresu (G). Każda z tych pozycji służy do przechowywania pozycji węzła źródłowego, węzła docelowego, relacji między nimi oraz ich właściwości.
Wykorzystuje również pamięć podręczną, która przyspiesza wykonywanie zapytań odczytowych. Dane są przechowywane w postaci klastrów DB. Każdy klaster składa się z podstawowej instancji bazy danych i repliki instancji bazy danych do odczytu. Neptune jest bardzo bezpieczny, ponieważ wykorzystuje uwierzytelnianie uprawnień, certyfikację SSL i monitorowanie dzienników. Migracja danych z innych źródeł do Amazon Neptune jest również łatwa. Zapewnia również odporność, tworząc repliki i okresowe kopie zapasowe. Niektóre firmy korzystające z Neptune to Herren, Onedot, Juncture i Hi Platform.
Neo4j
Neo4j to skalowalna, bezpieczna, dostępna na żądanie i niezawodna baza danych wykresów. Neo4j został zbudowany w Javie, używając Cypher jako języka zapytań. Wykorzystuje protokół Bolt, a wszystkie transakcje odbywają się za pośrednictwem punktu końcowego HTTP. Jest znacznie szybszy w odpowiadaniu na zapytania w porównaniu z innymi relacyjnymi bazami danych. Nie ma narzutu związanego z połączeniami złożonymi, a jego optymalizacje działają dobrze, gdy rozmiar zestawu danych jest duży i silnie połączony. Oferuje zalety przechowywania wykresów wraz z właściwościami ACID relacyjnej bazy danych.

Neo4j obsługuje różne języki, takie jak Java, .NET, Node.js, Ruby, Python itp., za pomocą sterowników. Jest również używany w przepływach pracy z danymi grafowymi, analizami i uczeniem maszynowym. Neo4j Aura DB to odporna na błędy iw pełni zarządzana baza danych w chmurze. Firmy takie jak Microsoft, Cisco, Adobe, eBay, IBM, Samsung itp. korzystają z Neo4j.
ArangoDB
ArangoDB to wielomodelowa baza danych typu open source. Podejście wielomodelowe umożliwia użytkownikom tworzenie zapytań w dowolnym, wybranym przez siebie języku zapytań. Węzły i krawędzie ArangoDB to dokumenty JSON. Każdy dokument posiada unikalny identyfikator. Relacje między dwoma węzłami są wskazywane w postaci krawędzi, a ich unikalne identyfikatory są przechowywane. Jego dobra wydajność wynika z obecności indeksu skrótu.

Udoskonalono przechodzenie, sprzężenia i wyszukiwania w bazach danych. Pomaga w projektowaniu, skalowaniu i dostosowywaniu się do różnych architektur. Odgrywa ważną rolę w złożonych zadaniach związanych z analizą danych, takich jak wyodrębnianie funkcji i wyszukiwanie zaawansowane.
ArrangoDB może działać w środowisku chmurowym i jest kompatybilny z systemami Mac OS, Linux i Windows. Uwierzytelnianie LDAP, maskowanie danych i algorytmy szyfrowania zapewniają bezpieczeństwo bazy danych. Jest używany w zarządzaniu ryzykiem, IAM, wykrywaniu oszustw, infrastrukturze sieciowej, silnikach rekomendacji itp. Accenture, Cisco, Dish i VMware to niektóre organizacje korzystające z ArangoDB.
DataStax
DataStax to chmurowa baza danych NoSQL jako usługa zbudowana na Apache Cassandra. Jest wysoce skalowalny i wykorzystuje architekturę natywną dla chmury. Jest niezawodny i bezpieczny. Każdy dokument przechowywany w DataStax posiada indeks, który pomaga w łatwym wyszukiwaniu i szybkim pobieraniu danych. Fragmenty są tworzone na zindeksowanych danych. Do budowy aplikacji można wykorzystać różne źródła danych za pomocą narzędzi Datastax Enterprise, Kafka i Docker.
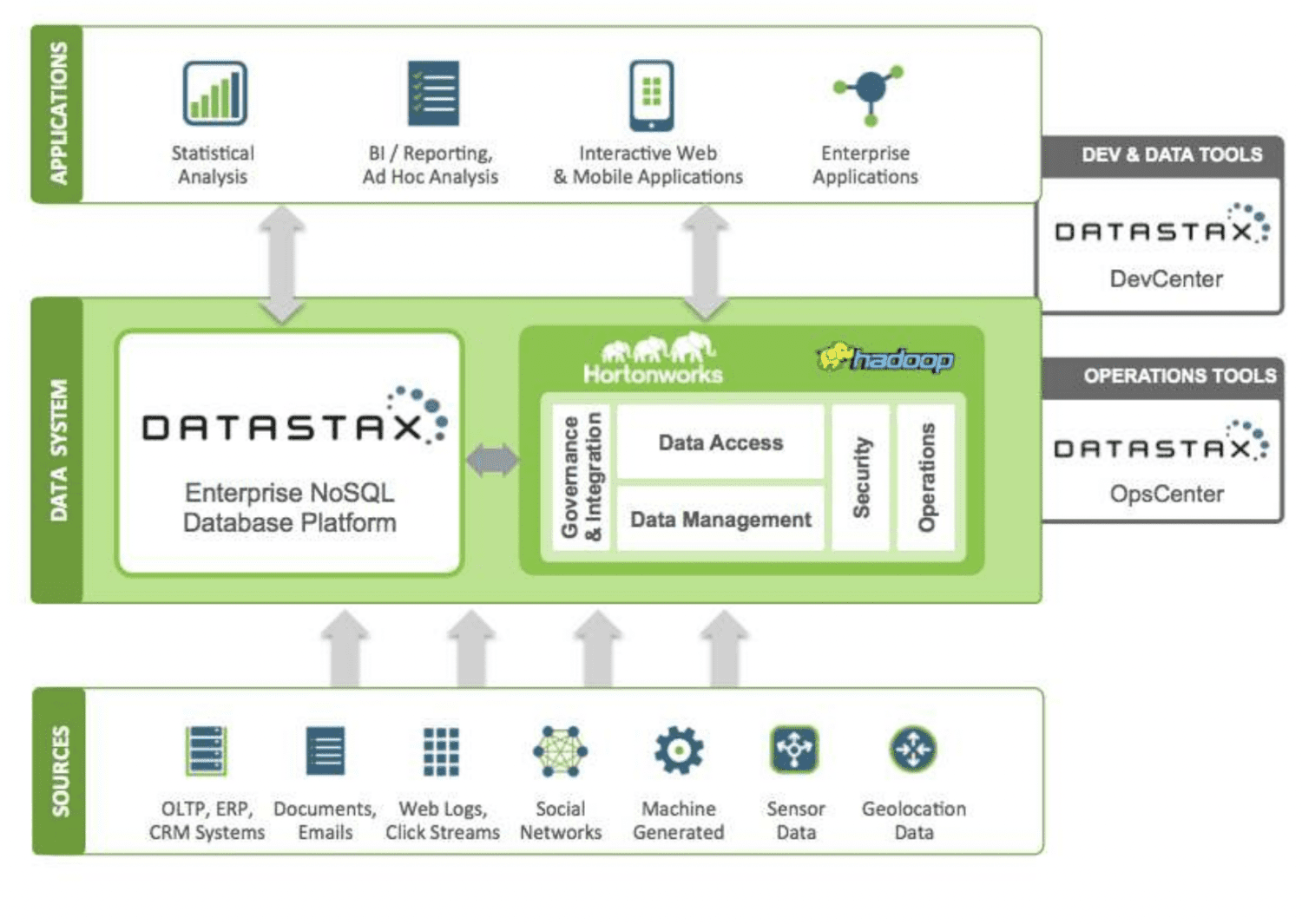
Dane zebrane ze źródeł są przesyłane do ekosystemu Hadoop i DataStax. Hadoop zarządza bezpieczeństwem, operacjami, dostępem do danych i zarządzaniem poprzez interakcję z DataStax. Dane są dopracowywane za pomocą narzędzi programistycznych i operacyjnych Datastax.
Analizowane informacje są następnie wykorzystywane do analizy statystycznej, aplikacji korporacyjnych, raportowania itp. Ponieważ jest to chmura, klienci płacą za to, z czego korzystają, a ceny są rozsądne. Verizon, CapitalOne, TMobile i Overstock to niektóre firmy korzystające z DataStax.
Zorientuj DB
OrientDB to graficzna baza danych, która efektywnie zarządza danymi i pomaga tworzyć wizualne reprezentacje do prezentacji danych. Jest to wielomodelowa baza danych wykresów i została zbudowana w języku Java. Przechowuje dane w postaci par klucz-wartość, dokumentów, modeli obiektów itp. Składa się z 3 istotnych komponentów: edytora wykresów, zapytania studio i konsoli wiersza poleceń.
Edytor wykresów służy do wizualizacji danych i interakcji z nimi. Interfejs zapytań Studio służy do wykonywania zapytań i natychmiastowego dostarczania danych wyjściowych w formacie obrazkowym i tabelarycznym. Konsola wiersza poleceń służy do odpytywania danych z OrientDB. Ma rozproszoną architekturę z wieloma serwerami, które mogą wykonywać operacje odczytu i zapisu. Serwery replik służą do wykonywania operacji odczytu i zapytań. Obsługuje indeksowanie i jest również zgodny z ACID. Niektóre firmy korzystające z OrientDB to Comcast Corporation i Blackfriars Group.
Dgraf
Dgraph to baza danych wykresów w chmurze, która obsługuje GraphQL. Został zbudowany przy użyciu Go. Minimalizuje połączenia sieciowe i zmniejsza opóźnienia, maksymalizując współbieżne przetwarzanie zapytań. Bezproblemowa integracja Dgraph z GraphQL pomaga w łatwym tworzeniu aplikacji backendowych GraphQL.

Mutacja GraphQL jest przekazywana przez funkcję Lambda, która współdziała z bazą danych i potokiem danych. Upraszcza to przetwarzanie zapytań. Jest skalowalny w poziomie, co oznacza, że liczba zasobów wzrasta wraz ze wzrostem liczby zapytań i danych. Zapewnia różne funkcje, takie jak autoryzacja oparta na JWT, wizualizator danych, uwierzytelnianie w chmurze, kopie zapasowe danych itp. Niektóre organizacje korzystające z Dgraph obejmują Intuit, intel i Factset.
Tygrysograf
Tigergraph to baza danych grafów właściwości opracowana w C++. Jest wysoce skalowalny i wykonuje zaawansowane analizy na silnie połączonych danych. Wykorzystuje natywną strukturę wykresów do przechowywania danych i silnik przetwarzania wykresów do przetwarzania danych. Baza danych jest przechowywana na dysku iw pamięci, a także wykorzystuje pamięć podręczną procesora do szybkiego wyszukiwania. Wykorzystuje funkcję Map Reduce do równoległego przetwarzania danych.
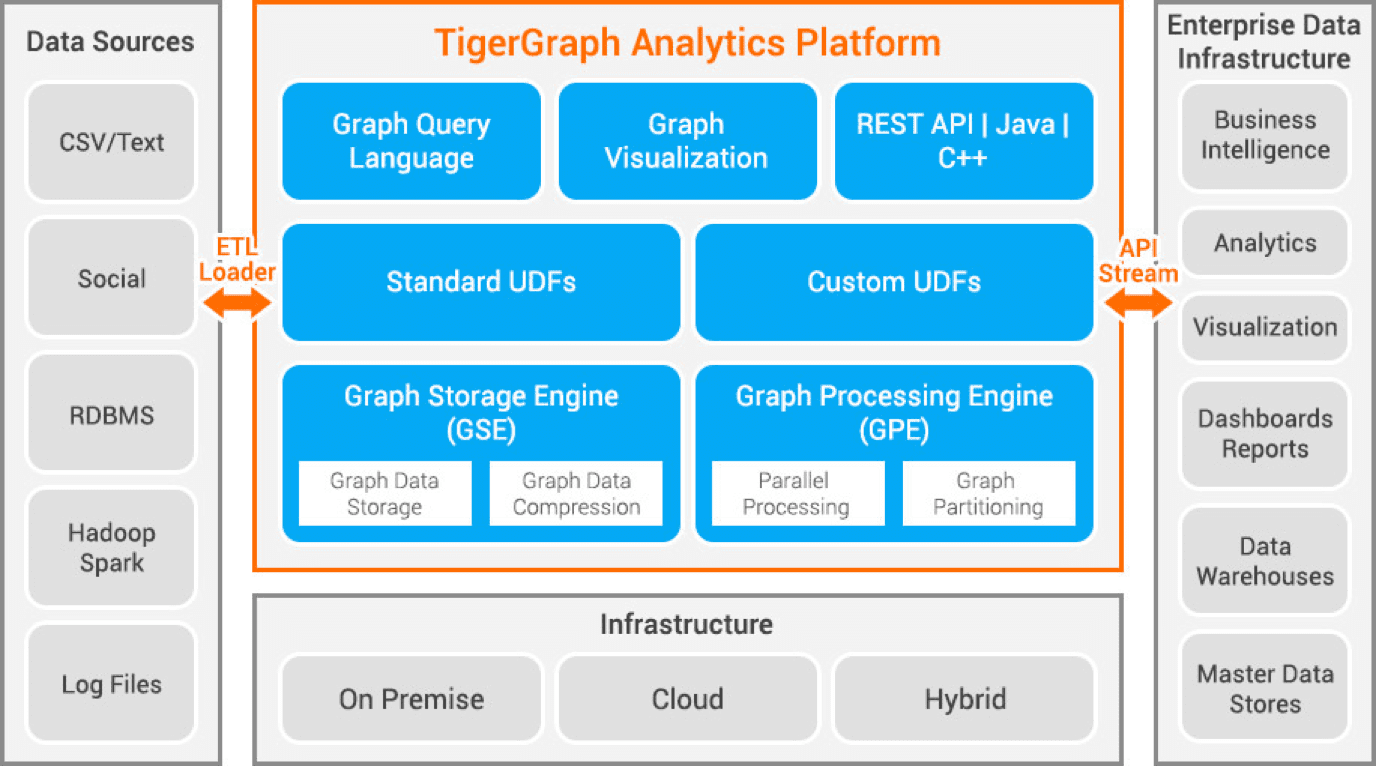
Jest niezwykle szybki i skalowalny. Wykonuje obliczenia równoległe i zapewnia aktualizacje w czasie rzeczywistym. Wykorzystuje techniki kompresji danych i kompresuje dane 10x. Dzieli dane na serwery automatycznie, oszczędzając czas i wysiłek wymagany do ręcznego fragmentowania danych. Służy do wykrywania oszustw w gospodarstwach domowych, zarządzania łańcuchem dostaw i poprawy opieki zdrowotnej. JPMorgan Chase, Intuit i United Health Group to niektóre organizacje korzystające z Tigergraph.
AllegroWykres
AllegroGraph wykorzystuje technologię grafu wiedzy o zdarzeniach encji do wykonywania analiz i podejmowania decyzji dotyczących wysoce połączonych, złożonych i gęstych danych. Dane są przechowywane w formacie JSON i JSON-LD w węzłach wykresu. Wykorzystuje architekturę protokołu REST. Zajmuje się również bardzo dużymi zestawami danych, dzieląc dane na podstawie określonych kryteriów i rozprowadzając je w wielu repozytoriach bazy wiedzy.
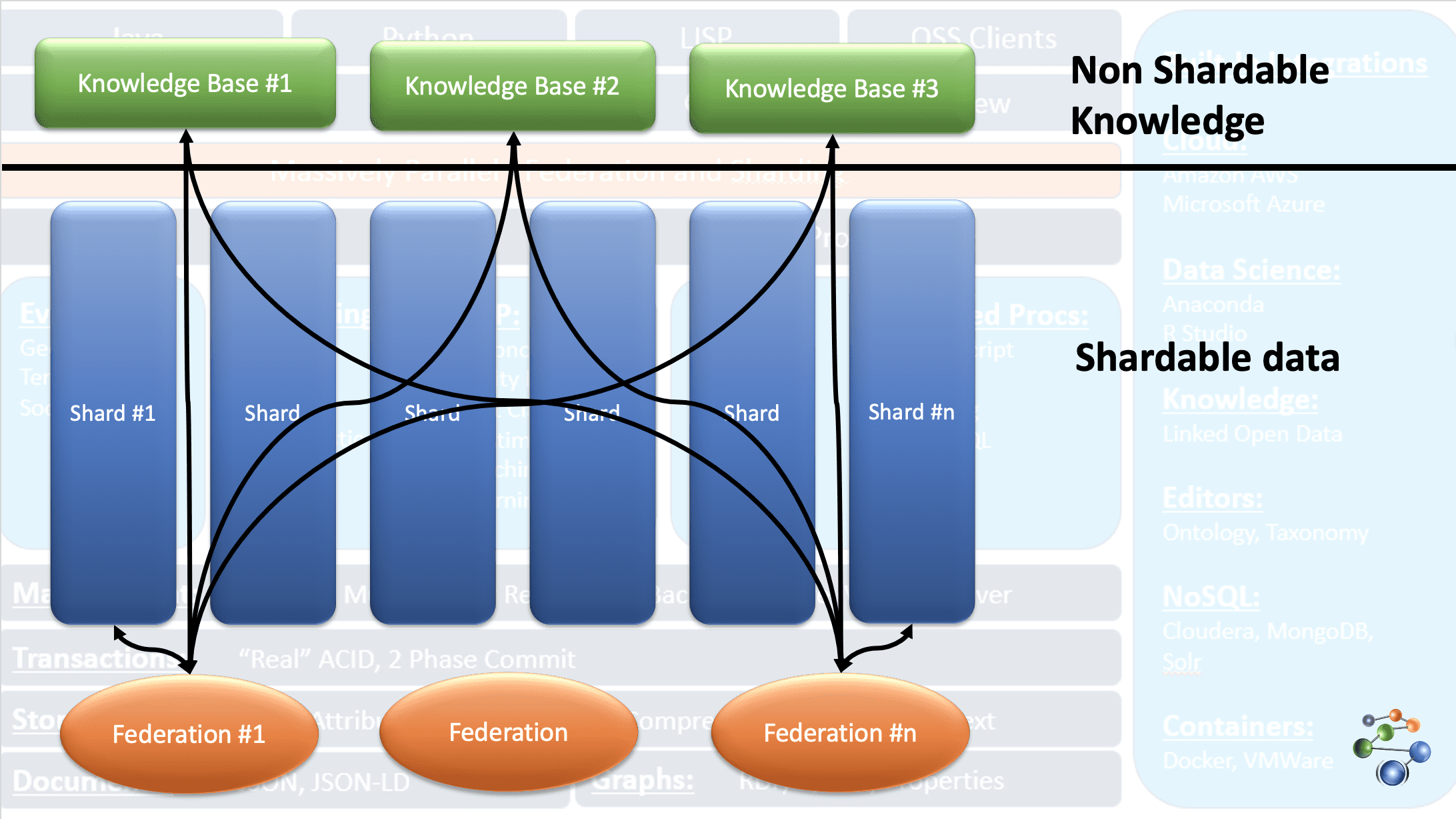
Jest to możliwe dzięki funkcji FedShard bazy danych AllegroGraph. Realizacja zapytań odbywa się poprzez połączenie federacji z repozytoriami bazy wiedzy. Obsługuje typy schematów XML i wykorzystuje potrójne indeksy. Przechowuje dane geoprzestrzenne, takie jak szerokości i długości geograficzne oraz dane czasowe, takie jak data, znacznik czasu itp. Jest również kompatybilny z systemami Windows, Mac i Linux. Znajduje zastosowanie w wykrywaniu oszustw, opiece zdrowotnej, identyfikacji podmiotów, przewidywaniu ryzyka itp.
Stardog
Stardog to grafowa baza danych, która wykonuje wirtualizację danych grafowych i łączy dane z hurtowni danych i jezior danych bez fizycznego kopiowania danych do nowej lokalizacji. Stardog jest zbudowany na otwartych standardach RDF. Obsługuje dane strukturalne, częściowo ustrukturyzowane i nieustrukturyzowane. Ten rodzaj materializacji wykonywany przez Stardoga zapewnia elastyczność. Jest to jedyna grafowa baza danych, która łączy grafy wiedzy i wirtualizację.
Stardog wykorzystuje silnik wnioskowania zasilany przez sztuczną inteligencję do wydajnego przetwarzania i dostarczania danych wyjściowych zapytań. Jest to graficzna baza danych zgodna z ACID. Obsługiwane są współbieżne odczyty i zapisy. Z łatwością obsługuje złożone zapytania dzięki najnowocześniejszej architekturze. Jest używany w zarządzaniu zasobami IT, zarządzaniu danymi i analityce oraz zapewnia wysoką dostępność. Niektóre firmy korzystające ze Stardoga to Cisco, eBay, NASA i Finra.
Ostatnie słowa
Bazy danych wykresów pomagają w łatwym wyszukiwaniu relacji wiele-do-wielu i efektywnym przechowywaniu danych. Są skalowalne, bezpieczne i można je zintegrować z wieloma narzędziami, interfejsami API i językami innych firm. W ostatnich latach zostały zintegrowane z chmurą i zapewniają najlepszą wydajność.
Upraszczają złożone sprzężenia w proste zapytania, co ułatwia programistom. Zadania wymagające dużej ilości danych, takie jak IoT i Big Data, są również grafowymi bazami danych. Będą one nadal ewoluować i z pewnością rozszerzą się na inne przypadki użycia w przyszłości.