

Dane stają się coraz ważniejsze dla budowania modeli uczenia maszynowego, testowania aplikacji i wyciągania wniosków biznesowych.
Jednak w celu zachowania zgodności z wieloma przepisami dotyczącymi danych są one często przechowywane i ściśle chronione. Uzyskanie dostępu do takich danych może zająć miesiące, aby uzyskać niezbędne podpisy. Alternatywnie, firmy mogą korzystać z danych syntetycznych.
Spis treści:
Co to są dane syntetyczne?
Źródło zdjęcia: Twinify
Dane syntetyczne to sztucznie generowane dane, które statystycznie przypominają stary zbiór danych. Może być używany z prawdziwymi danymi do wspierania i ulepszania modeli AI lub może być używany jako całkowity substytut.
Ponieważ nie należą one do żadnej osoby, której dane dotyczą, i nie zawierają żadnych informacji umożliwiających identyfikację ani danych wrażliwych, takich jak numery ubezpieczenia społecznego, mogą być wykorzystywane jako chroniąca prywatność alternatywa dla prawdziwych danych produkcyjnych.
Różnice między danymi rzeczywistymi a syntetycznymi
- Najważniejsza różnica polega na sposobie generowania tych dwóch typów danych. Prawdziwe dane pochodzą od prawdziwych osób, których dane zostały zebrane podczas ankiet lub podczas korzystania z Twojej aplikacji. Z drugiej strony dane syntetyczne są generowane sztucznie, ale nadal przypominają oryginalny zbiór danych.
- Druga różnica dotyczy przepisów o ochronie danych dotyczących danych rzeczywistych i syntetycznych. W przypadku prawdziwych danych podmioty powinny wiedzieć, jakie dane na ich temat są gromadzone i dlaczego są gromadzone, a także istnieją ograniczenia co do sposobu ich wykorzystania. Przepisy te nie mają jednak już zastosowania do danych syntetycznych, ponieważ danych tych nie można przyporządkować podmiotowi i nie zawierają one danych osobowych.
- Trzecia różnica dotyczy ilości dostępnych danych. Z prawdziwymi danymi możesz mieć tylko tyle, ile dają Ci użytkownicy. Z drugiej strony możesz generować tyle danych syntetycznych, ile chcesz.
Dlaczego warto rozważyć użycie danych syntetycznych
- Jest stosunkowo tańszy w produkcji, ponieważ można generować znacznie większe zestawy danych, przypominające mniejszy zestaw danych, który już posiadasz. Oznacza to, że modele uczenia maszynowego będą miały więcej danych do trenowania.
- Wygenerowane dane są automatycznie oznaczane i czyszczone. Oznacza to, że nie musisz tracić czasu na czasochłonne przygotowywanie danych do uczenia maszynowego lub analiz.
- Nie ma problemów z prywatnością, ponieważ dane nie umożliwiają identyfikacji osoby i nie należą do osoby, której dane dotyczą. Oznacza to, że możesz go swobodnie używać i udostępniać.
- Możesz przezwyciężyć stronniczość sztucznej inteligencji, upewniając się, że klasy mniejszościowe są dobrze reprezentowane. To pomaga budować uczciwą i odpowiedzialną sztuczną inteligencję.
Jak generować dane syntetyczne
Chociaż proces generowania różni się w zależności od używanego narzędzia, generalnie proces rozpoczyna się od podłączenia generatora do istniejącego zestawu danych. Następnie identyfikujesz pola identyfikujące osobę w swoim zbiorze danych i oznaczasz je w celu wykluczenia lub zaciemnienia.
Następnie generator zaczyna identyfikować typy danych pozostałych kolumn i wzorce statystyczne w tych kolumnach. Od tego momentu możesz generować tyle danych syntetycznych, ile potrzebujesz.
Zwykle można porównać wygenerowane dane z oryginalnym zestawem danych, aby zobaczyć, jak bardzo dane syntetyczne przypominają dane rzeczywiste.
Teraz przyjrzymy się narzędziom do generowania danych syntetycznych w celu trenowania modeli uczenia maszynowego.
Głównie AI

Głównie sztuczna inteligencja ma generator danych syntetycznych oparty na sztucznej inteligencji, który uczy się na podstawie wzorców statystycznych oryginalnego zestawu danych. Sztuczna inteligencja generuje następnie fikcyjne postacie, które są zgodne z wyuczonymi wzorcami.
Dzięki Mostly AI możesz generować całe bazy danych z integralnością referencyjną. Możesz zsyntetyzować wszelkiego rodzaju dane, które pomogą Ci zbudować lepsze modele AI.
Zsyntetyzowany.io

Wiodące firmy używają Synthesized.io do swoich inicjatyw AI. Aby używać syntezatora.io, należy określić wymagania dotyczące danych w pliku konfiguracyjnym YAML.
Następnie tworzysz zadanie i uruchamiasz je jako część potoku danych. Ma również bardzo hojny bezpłatny poziom, który pozwala eksperymentować i sprawdzać, czy odpowiada Twoim potrzebom w zakresie danych.
YDane

Dzięki YData możesz generować dane tabelaryczne, szeregi czasowe, transakcyjne, wielotabelowe i relacyjne. Pozwala to uniknąć problemów związanych z gromadzeniem, udostępnianiem i jakością danych.
Jest wyposażony w sztuczną inteligencję i zestaw SDK do interakcji z ich platformą. Ponadto mają hojny bezpłatny poziom, którego można użyć do demonstracji produktu.
Gretel AI

Gretel AI oferuje interfejsy API do generowania nieograniczonej ilości danych syntetycznych. Gretel ma generator danych typu open source, który można zainstalować i używać.
Alternatywnie możesz użyć ich REST API lub CLI, co wiąże się z kosztami. Ich cena jest jednak rozsądna i skaluje się wraz z wielkością firmy.
Kopuły
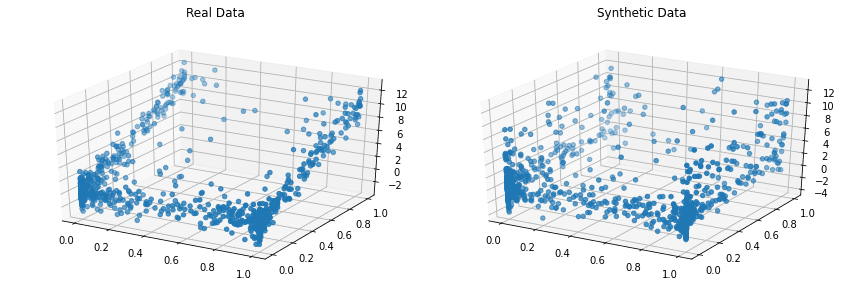
Copulas to biblioteka języka Python typu open source do modelowania rozkładów wielowymiarowych przy użyciu funkcji kopuły i generowania danych syntetycznych, które mają te same właściwości statystyczne.
Projekt rozpoczął się w 2018 roku na MIT w ramach projektu Synthetic Data Vault.
CTGAN
CTGAN składa się z generatorów, które są w stanie uczyć się z rzeczywistych danych z jednej tabeli i generować dane syntetyczne ze zidentyfikowanych wzorców.
Jest zaimplementowany jako biblioteka Pythona typu open source. CTGAN wraz z Copulas jest częścią projektu Synthetic Data Vault Project.
DoppelGANger
DoppelGANger to implementacja typu open source Generative Adversarial Networks do generowania danych syntetycznych.
DoppelGANger jest przydatny do generowania danych szeregów czasowych i jest używany przez firmy takie jak Gretel AI. Biblioteka Pythona jest dostępna za darmo i jest open source.
Syntezator

Synth to generator danych typu open source, który pomaga tworzyć realistyczne dane zgodnie ze specyfikacjami, ukrywać dane osobowe i opracowywać dane testowe dla aplikacji.
Możesz użyć Synth do generowania szeregów w czasie rzeczywistym i danych relacyjnych na potrzeby uczenia maszynowego. Synth jest również niezależny od bazy danych, dzięki czemu można go używać z bazami danych SQL i NoSQL.
Odch. SDV
SDV oznacza magazyn danych syntetycznych. SDV.dev to projekt oprogramowania, który rozpoczął się w MIT w 2016 roku i stworzył różne narzędzia do generowania danych syntetycznych.
Narzędzia te obejmują Copulas, CTGAN, DeepEcho i RDT. Te narzędzia są zaimplementowane jako otwarte biblioteki języka Python, z których można łatwo korzystać.
tofu
Tofu to biblioteka Pythona typu open source do generowania danych syntetycznych na podstawie danych z brytyjskich biobanków. W przeciwieństwie do narzędzi wspomnianych wcześniej, które pomogą Ci wygenerować wszelkiego rodzaju dane na podstawie istniejącego zestawu danych, Tofu generuje dane, które przypominają tylko dane z biobanku.
UK Biobank to badanie cech fenotypowych i genotypowych 500 000 osób dorosłych w średnim wieku z Wielkiej Brytanii.
Podwójnie
Twinify to pakiet oprogramowania używany jako biblioteka lub narzędzie wiersza poleceń do łączenia poufnych danych poprzez tworzenie danych syntetycznych z identycznymi rozkładami statystycznymi.

Aby korzystać z Twinify, dostarczasz rzeczywiste dane jako plik CSV, a on uczy się na podstawie danych, aby stworzyć model, który można wykorzystać do generowania danych syntetycznych. Jest całkowicie darmowy.
Datanamic
Datanamic pomaga tworzyć dane testowe dla aplikacji opartych na danych i uczenia maszynowego. Generuje dane na podstawie cech kolumn, takich jak adres e-mail, imię i nazwisko oraz numer telefonu.
Generatory danych Datanamic są konfigurowalne i obsługują większość baz danych, takich jak Oracle, MySQL, MySQL Server, MS Access i Postgres. Wspiera i zapewnia integralność referencyjną w generowanych danych.
Benerator
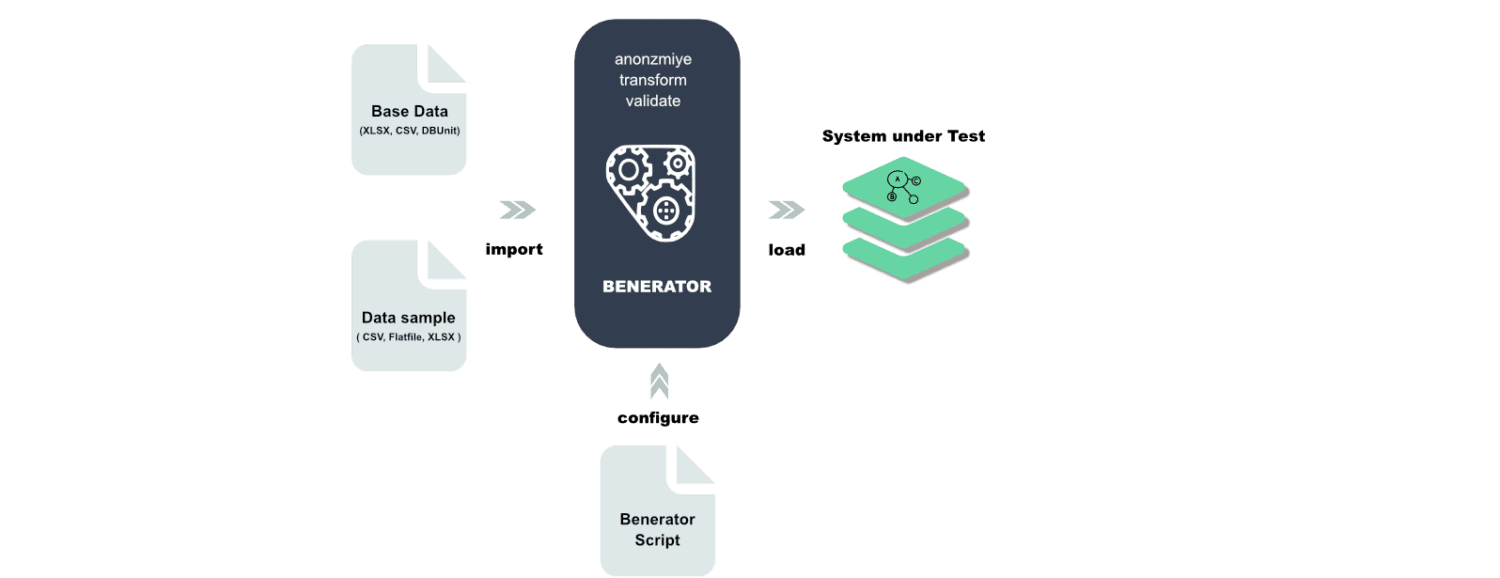
Benerator to oprogramowanie do zaciemniania, generowania i migracji danych do celów testowych i szkoleniowych. Korzystając z Beneratora, opisujesz dane za pomocą XML (Extensible Markup Language) i generujesz je za pomocą narzędzia wiersza poleceń.
Jest przeznaczony do użytku przez osoby niebędące programistami, a dzięki niemu można generować miliardy wierszy danych. Benerator jest darmowy i open-source.
Ostatnie słowa
Gartner szacuje, że do 2030 roku do uczenia maszynowego będzie wykorzystywanych więcej danych syntetycznych niż danych rzeczywistych.
Nietrudno zrozumieć, dlaczego, biorąc pod uwagę koszty i obawy dotyczące prywatności związane z wykorzystaniem prawdziwych danych. Dlatego konieczne jest, aby firmy zapoznały się z danymi syntetycznymi i różnymi narzędziami, które pomogą im w ich generowaniu.
Następnie sprawdź syntetyczne narzędzia monitorujące dla Twojej firmy online.