

W tej erze Internetu istnieją terabajty i petabajty danych, z wykładniczym wzrostem na tym samym poziomie. Ale w jaki sposób wykorzystujemy te dane i tłumaczymy je na przydatne informacje, aby poprawić dostępność usług?
Prawidłowe, nowatorskie i zrozumiałe dane to wszystko, czego potrzebują firmy do swoich modeli odkrywania wiedzy.
Z tego powodu firmy stosują analizy na wiele różnych sposobów, aby odkryć dane wysokiej jakości.
Ale gdzie to wszystko się zaczyna? Odpowiedzią jest walka o dane.
Zacznijmy!
Spis treści:
Co to jest walka o dane?
Awansowanie danych to czynność czyszczenia, strukturyzowania i przekształcania nieprzetworzonych danych w formaty, które upraszczają procesy analizy danych. Wymiana danych często wiąże się z pracą z niechlujnymi i złożonymi zestawami danych, które nie są gotowe na procesy potoku danych. Żądanie danych przenosi surowe dane do ulepszonego stanu lub udoskonalone dane do zoptymalizowanego stanu i poziomu gotowości produkcyjnej.
Niektóre ze znanych zadań w walce z danymi obejmują:
- Scalanie wielu zestawów danych w jeden duży zestaw danych do analizy.
- Badanie brakujących/luk w danych.
- Usuwanie wartości odstających lub anomalii w zbiorach danych.
- Standaryzacja wejść.
Duże magazyny danych zaangażowane w procesy przetwarzania danych zwykle wykraczają poza ręczne dostrajanie, co wymaga zautomatyzowanych metod przygotowywania danych w celu uzyskania dokładniejszych i bardziej jakościowych danych.
Cele walki o dane
Oprócz przygotowania danych do analizy jako większego celu, inne cele obejmują:
- Tworzenie prawidłowych i nowatorskich danych z nieuporządkowanych danych, aby stymulować podejmowanie decyzji w firmach.
- Standaryzacja surowych danych do formatów, które mogą przyswajać systemy Big Data.
- Skrócenie czasu spędzanego przez analityków danych na tworzeniu modeli danych dzięki prezentowaniu uporządkowanych danych.
- Tworzenie spójności, kompletności, użyteczności i bezpieczeństwa dla dowolnego zestawu danych używanego lub przechowywanego w hurtowni danych.
Typowe podejścia do konfliktu danych
Odkrywanie
Zanim inżynierowie danych rozpoczną zadania związane z przygotowaniem danych, muszą zrozumieć, w jaki sposób są one przechowywane, rozmiar, jakie rekordy są przechowywane, formaty kodowania i inne atrybuty opisujące dowolny zbiór danych.
Strukturyzacja
Proces ten polega na organizowaniu danych w łatwych do użycia formatach. Surowe zestawy danych mogą wymagać uporządkowania wyglądu kolumn, liczby wierszy i dostrojenia innych atrybutów danych w celu uproszczenia analizy.
Czyszczenie
Ustrukturyzowane zbiory danych należy pozbyć się nieodłącznych błędów i wszystkiego, co może zniekształcić dane. Czyszczenie wiąże się zatem z usuwaniem wielu wpisów komórek z podobnymi danymi, usuwaniem pustych komórek i danych odstających, standaryzacją danych wejściowych, zmienianiem nazw mylących atrybutów i nie tylko.
Wzbogacanie
Gdy dane przejdą etapy strukturyzacji i czyszczenia, należy ocenić użyteczność danych i uzupełnić je o wartości z innych zbiorów danych, które nie zapewniają pożądanej jakości danych.
Walidacja
Proces walidacji obejmuje iteracyjne aspekty programowania, które rzucają światło na jakość, spójność, użyteczność i bezpieczeństwo danych. Faza walidacji zapewnia realizację wszystkich zadań transformacji i oznaczanie zestawów danych jako gotowych do faz analizy i modelowania.
Przedstawianie
Po przejściu wszystkich etapów pogmatwane zestawy danych są prezentowane/udostępniane w organizacji w celu analizy. Na tym etapie udostępniana jest również dokumentacja kroków przygotowawczych i metadane generowane w trakcie procesu spornego.
Talend
Talend to ujednolicona platforma do zarządzania danymi w 3 tkankach danych, która zapewnia niezawodne i zdrowe dane. Talend przedstawia Integrację danych, Aplikację i integrację oraz Integralność i zarządzanie danymi. Przetwarzanie danych w Talend odbywa się za pomocą narzędzia typu „wskaż i kliknij” opartego na przeglądarce, które umożliwia wsadowe, zbiorcze i bieżące przygotowywanie danych – profilowanie danych, czyszczenie i dokumentowanie.
Tkanina danych Talend obsługuje każdy etap cyklu życia danych, starannie równoważąc dostępność danych, użyteczność, bezpieczeństwo i integralność wszystkich danych biznesowych.
Czy kiedykolwiek martwiłeś się o swoje różnorodne źródła danych? Zunifikowane podejście Talend zapewnia szybką integrację danych ze wszystkich źródeł danych (bazy danych, magazyny w chmurze i punkty końcowe API) – umożliwiając transformację i mapowanie wszystkich danych z bezproblemową kontrolą jakości.
Integracja danych w Talend jest możliwa dzięki narzędziom samoobsługowym, takim jak konektory, które umożliwiają programistom automatyczne pobieranie danych z dowolnego źródła i odpowiednią kategoryzację danych.
Cechy Talendu
Uniwersalna integracja danych
Talend pozwala firmom zebrać dowolny typ danych z różnych źródeł danych – środowisk w chmurze lub On-prem.
Elastyczny
Talend wykracza poza dostawcę lub platformę, budując potoki danych ze zintegrowanych danych. Po utworzeniu potoków danych z pozyskiwanych danych, Talend umożliwia ich uruchamianie w dowolnym miejscu.
Jakość danych
Dzięki możliwościom uczenia maszynowego, takim jak deduplikacja danych, walidacja i standaryzacja, Talend automatycznie czyści przetworzone dane.
Wsparcie dla integracji aplikacji i API
Po nadaniu znaczenia Twoim danym za pomocą narzędzi samoobsługowych Talend, możesz udostępniać swoje dane za pomocą przyjaznych dla użytkownika interfejsów API. Punkty końcowe interfejsu API Talend mogą udostępniać Twoje zasoby danych na platformach SaaS, JSON, AVRO i B2B dzięki zaawansowanym narzędziom do mapowania i transformacji danych.
R

R to dobrze rozwinięty i skuteczny język programowania do eksploracyjnej analizy danych w zastosowaniach naukowych i biznesowych.
Zbudowany jako darmowe oprogramowanie do obliczeń statystycznych i grafiki, R jest zarówno językiem, jak i środowiskiem do uzgadniania danych, modelowania i wizualizacji. Środowisko R zapewnia pakiet pakietów oprogramowania, podczas gdy język R integruje szereg technik statystycznych, klastrowania, klasyfikacji, analizy i grafiki, które pomagają manipulować danymi.
Cechy R
Bogaty zestaw pakietów
Inżynierowie danych mają do wyboru ponad 10 000 standardowych pakietów i rozszerzeń z kompleksowej sieci archiwum R (CRAN). Upraszcza to spory i analizę danych.
Niezwykle potężny
Dzięki dostępnym pakietom obliczeniowym rozproszonym, R może wykonywać złożone i proste manipulacje (matematyczne i statystyczne) na obiektach danych i zestawach danych w ciągu kilku sekund.
Wsparcie dla wielu platform
R jest niezależny od platformy i może działać w wielu systemach operacyjnych. Jest również kompatybilny z innymi językami programowania, które pomagają w manipulowaniu ciężkimi zadaniami obliczeniowymi.
Nauka R jest łatwa.
Trifakt

Trifakt to interaktywne środowisko chmurowe do profilowania danych, które działają w oparciu o modele uczenia maszynowego i analizy. To narzędzie do inżynierii danych ma na celu tworzenie zrozumiałych danych niezależnie od tego, jak niechlujne lub złożone są zestawy danych. Użytkownicy mogą usuwać podwójne wpisy i wypełniać puste komórki w zestawach danych za pomocą deduplikacji i transformacji liniowych.
To narzędzie do zbierania danych wykrywa wartości odstające i nieprawidłowe dane w dowolnym zbiorze danych. Wystarczy jedno kliknięcie i przeciągnięcie, aby dostępne dane były klasyfikowane i inteligentnie przekształcane za pomocą sugestii opartych na uczeniu maszynowym, które przyspieszają przygotowywanie danych.
Walka o dane w Trifacta odbywa się za pomocą atrakcyjnych profili wizualnych, które mogą pomieścić personel nietechniczny i techniczny. Dzięki wizualizowanym i inteligentnym przekształceniom Trifacta szczyci się swoim projektem z myślą o użytkownikach.
Niezależnie od tego, czy pobierają dane ze zbiorczych baz danych, hurtowni danych czy jezior danych, użytkownicy są chronieni przed złożonością przygotowania danych.
Cechy Trifacta
Bezproblemowa integracja z chmurą
Obsługuje obciążenia przygotowawcze w dowolnej chmurze lub środowisku hybrydowym, aby umożliwić programistom pozyskiwanie zestawów danych do prowadzenia sporów bez względu na to, gdzie mieszkają.
Wiele metod standaryzacji danych
Trifacta wrangler posiada kilka mechanizmów identyfikacji wzorców w danych i standaryzacji danych wyjściowych. Inżynierowie danych mogą wybrać standaryzację według wzorca, funkcji lub mieszać i dopasowywać.
Prosty przepływ pracy
Trifacta organizuje prace związane z przygotowaniem danych w formie przepływów. Przepływ zawiera jeden lub więcej zestawów danych oraz skojarzone z nimi receptury (zdefiniowane kroki, które przekształcają dane).
W związku z tym przepływ skraca czas, jaki programiści poświęcają na importowanie, spory, profilowanie i eksportowanie danych.
Otwórz zawęź
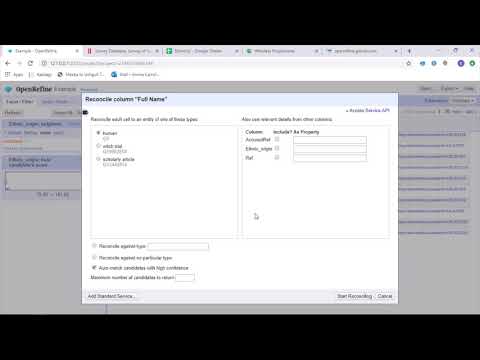
Otwórz zawęź to dojrzałe, otwarte narzędzie do pracy z niechlujnymi danymi. Jako narzędzie do czyszczenia danych, OpenRefine eksploruje zestawy danych w ciągu kilku sekund, stosując złożone transformacje komórek w celu przedstawienia żądanych formatów danych.
OpenRefine podchodzi do przetwarzania danych poprzez filtry i partycje w zestawach danych przy użyciu wyrażeń regularnych. Korzystając z wbudowanego języka General Refine Expression, inżynierowie danych mogą uczyć się i wyświetlać dane za pomocą aspektów, filtrów i technik sortowania przed wykonaniem zaawansowanych operacji na danych w celu wyodrębnienia encji.
OpenRefine pozwala użytkownikom pracować nad danymi jako projektami, w których zestawy danych z wielu plików komputerowych, internetowych adresów URL i baz danych mogą być wciągane do takich projektów z możliwością uruchamiania lokalnie na komputerach użytkowników.
Za pomocą wyrażeń programiści mogą rozszerzyć czyszczenie i transformację danych o zadania, takie jak dzielenie/łączenie komórek wielowartościowych, dostosowywanie aspektów i pobieranie danych do kolumn przy użyciu zewnętrznych adresów URL.
Funkcje OpenRefine
Narzędzie wieloplatformowe
OpenRefine jest stworzony do pracy z systemami operacyjnymi Windows, Mac i Linux poprzez konfiguracje instalatora do pobrania.
Bogaty zestaw API
Zawiera interfejs API OpenRefine, interfejs API rozszerzenia danych, interfejs API uzgadniania i inne interfejsy API, które wspierają interakcję użytkowników z danymi.
Datamer

Datameer to narzędzie do transformacji danych SaaS, stworzone w celu uproszczenia przeszukiwania danych i integracji poprzez procesy inżynierii oprogramowania. Datameer umożliwia ekstrakcję, transformację i ładowanie zestawów danych do hurtowni danych w chmurze, takich jak Snowflake.
To narzędzie do zarządzania danymi działa dobrze ze standardowymi formatami zestawów danych, takimi jak CSV i JSON, umożliwiając inżynierom importowanie danych w różnych formatach w celu agregacji.
Datameer oferuje dokumentację danych podobną do katalogu, głębokie profilowanie danych i wykrywanie, aby spełnić wszystkie potrzeby związane z transformacją danych. Narzędzie utrzymuje głęboki profil danych wizualnych, który umożliwia użytkownikom śledzenie nieprawidłowych, brakujących lub odstających pól i wartości oraz ogólnego kształtu danych.
Działając na skalowalnej hurtowni danych, Datameer przekształca dane w celu uzyskania znaczącej analizy dzięki wydajnym stosom danych i funkcjom podobnym do programu Excel.
Datameer przedstawia hybrydowy interfejs użytkownika z kodem i bez kodu, aby dostosować się do szerokich zespołów analityki danych, które mogą łatwo budować złożone potoki ETL.
Funkcje Datameera
Wiele środowisk użytkownika
Zawiera wieloosobowe środowiska do transformacji danych — niskokodowe, kodowe i hybrydowe, aby wspierać osoby znające się na technologii i osoby nie znające technologii.
Współdzielone obszary robocze
Datameer umożliwia zespołom ponowne wykorzystanie i współpracę nad modelami w celu przyspieszenia projektów.
Bogata dokumentacja danych
Datameer obsługuje zarówno systemową, jak i generowaną przez użytkowników dokumentację danych za pomocą metadanych i opisów, tagów i komentarzy w stylu wiki.
Ostatnie słowa 👩🏫
Analiza danych to złożony proces, który wymaga odpowiedniej organizacji danych w celu wyciągnięcia znaczących wniosków i dokonania prognoz. Narzędzia Data Wrangling pomagają formatować duże ilości nieprzetworzonych danych, aby ułatwić wykonywanie zaawansowanych analiz. Wybierz najlepsze narzędzie, które odpowiada Twoim wymaganiom i zostań specjalistą od Analytics!
Możesz polubić:
Najlepsze narzędzia CSV do konwersji, formatowania i walidacji.