
Zbudowanie zautomatyzowanego systemu oprogramowania oznaczało skonfigurowanie wielu serwerów z dedykowaną konfiguracją procesora, pamięcią, pamięcią masową i innymi zasobami na wiele lat. Następnie utworzono zespół administratorów do zarządzania tymi systemami. Następnie zespół programistów przejął infrastrukturę i zaczął tworzyć procesy łączące serwery.
Ten proces może być skomplikowany, ponieważ obejmuje wiele różnych grup pracujących razem na rzecz wspólnego celu. Te konflikty interesów mogą wtedy stanowić problem.
Może to być również dość kosztowne. Wymaga to posiadania administratorów na liście płac. Serwery, które działają w sposób ciągły, zużywają zasoby, mimo że nie są używane.
Aby utrzymać najlepszą wydajność w czasie, potrzebujesz rozwiązania do automatycznego skalowania, które automatycznie skaluje zasoby serwera.
Platforma chmurowa ma jedną zaletę: umożliwia tworzenie kompleksowej architektury bez konieczności konfigurowania klastra serwerów. Z punktu widzenia administracji nie ma czego utrzymywać.
Jest to opłacalna opcja dla startupów i faz projektów o minimalnej opłacalności produktu (MVP). Jest to dobry punkt wyjścia, jeśli trudno jest przewidzieć przyszłe obciążenia produkcyjne i aktywność użytkowników. W tym przypadku określenie konfiguracji serwerów klastrowych może być trudne.
Automatyzacja procesów za pośrednictwem bezserwerowych usług w chmurze jest tym, co wyróżnia architekturę bezserwerową. Łączy usługi i daje wyniki podobne do tradycyjnych serwerów klastrowych.
To jest przykład budowania takiej architektury z wykorzystaniem wyłącznie natywnych usług AWS.
Spis treści:
Pobieranie przepływu bezserwerowego usług
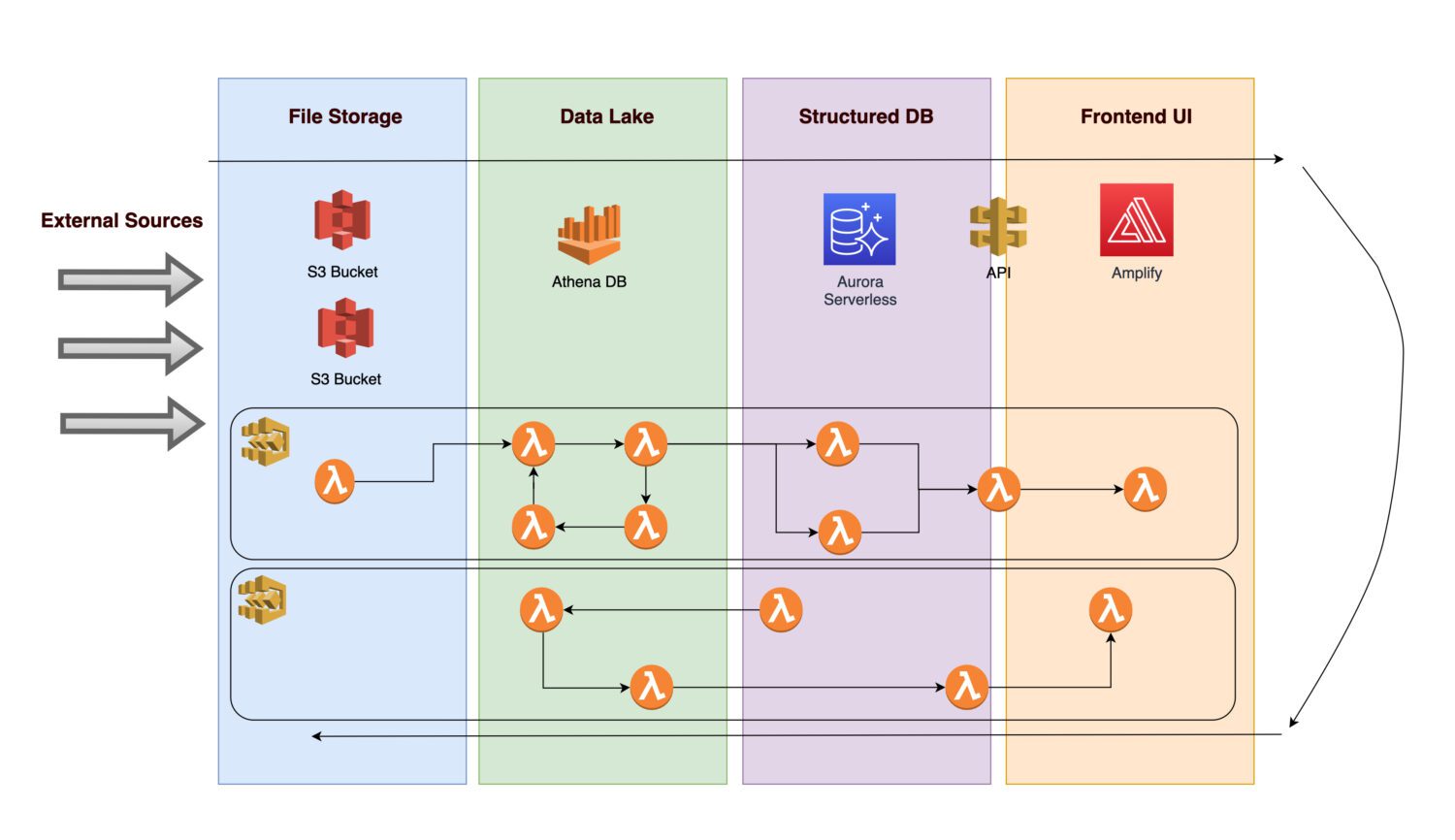
Wyobraź sobie, że chciałbyś stworzyć platformę do gromadzenia różnych danych i obrazów (lub zdjęć) infrastruktury niektórych konkretnych aktywów (może to być dowolny zasób produkcyjny lub użytkowy).
- Aby przyszłe analizy były możliwe, konieczne jest, aby dane przychodzące zostały najpierw przetworzone.
- Po zastosowaniu reguł biznesowych procedura zaplecza zapisuje obliczone wyniki jako znormalizowane informacje w relacyjnej bazie danych.
- Front-end aplikacji, który wyświetla znormalizowane czyste dane, umożliwia użytkownikom przeglądanie wyników.
Przyjrzyjmy się, jakie komponenty może zawierać architektura.
Łyżki AWS S3
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
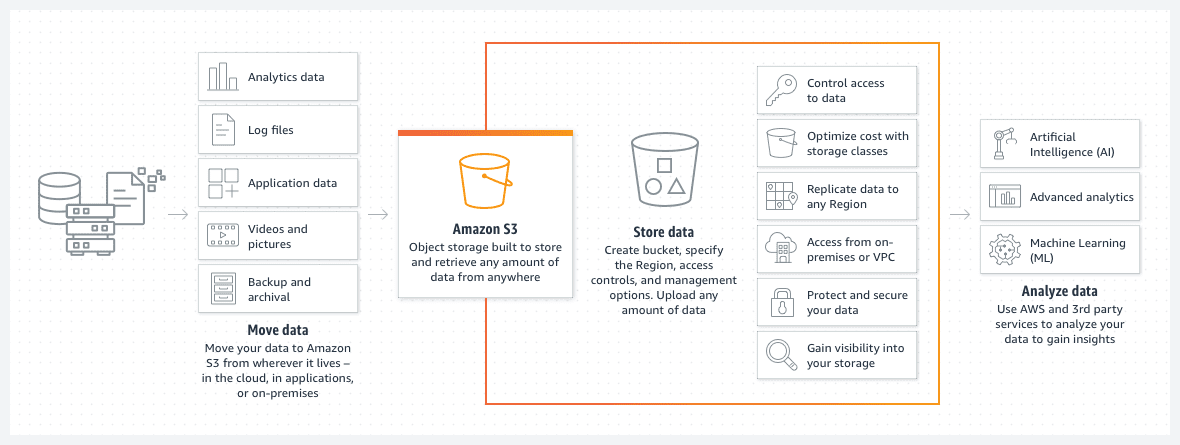
Kubełki Amazon S3 to świetny sposób na przechowywanie plików lub zdjęć w chmurze AWS. Cena magazynowania na kubełku S3 jest wyjątkowo niska. Co więcej, wprowadzenie polityki cyklu życia zasobnika S3 jeszcze bardziej obniża tę cenę.
Taka polityka automatycznie przeniesie starsze pliki do różnych klas segmentów S3, takich jak archiwum lub głęboki dostęp do archiwum. Klasy różnią się wtedy także szybkością czasu dostępu, ale w przypadku starych danych będzie to mniejszy problem. Służy głównie do dostępu do zarchiwizowanych danych w przypadku pilnego zdarzenia, a nie do standardowych potrzeb operacyjnych.
- Możesz organizować swoje dane w podfolderach.
- Należy ustawić odpowiednie ograniczenia uprawnień.
- Dodaj tagi do zasobników, aby ułatwić ich identyfikację i ewentualne użycie w ramach dynamicznych zasad zasobników S3.
- Wiadro jest z założenia bezserwerowe. To po prostu miejsce do przechowywania danych.
Zasobnik S3 jest z założenia bezserwerowy. To po prostu miejsce do przechowywania danych.
Baza danych AWS Athena
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
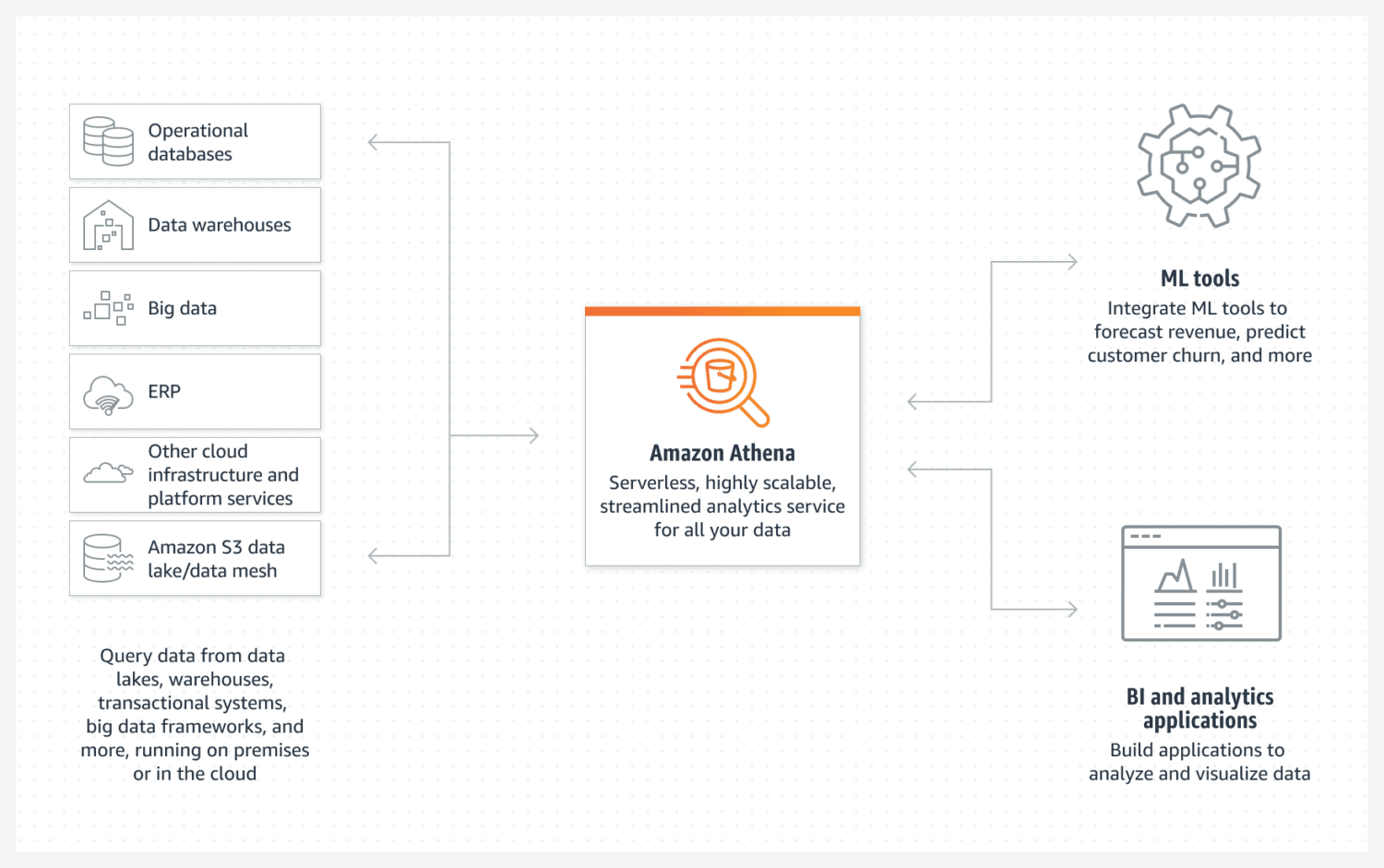
Athena ułatwia tworzenie podstawowego jeziora danych AWS. Jest to baza danych bez serwerów, która wykorzystuje wiadro S3 do przechowywania swoich danych. Organizacja danych jest utrzymywana przez ustrukturyzowane formaty plików, takie jak Parquet lub pliki z wartościami rozdzielanymi przecinkami (CSV). Zasobnik S3 przechowuje pliki, a Athena odwołuje się do nich za każdym razem, gdy procesy wybierają dane z bazy danych.
Należy tylko pamiętać, że Athena nie obsługuje różnych funkcji uważanych za standardowe, na przykład instrukcji aktualizacji. Dlatego musisz spojrzeć na Atenę jako na bardzo prostą opcję.
Obsługuje jednak indeksowanie i partycjonowanie. Można go również bardzo łatwo skalować w poziomie, ponieważ jest to tak skomplikowane, jak dodawanie nowych zasobników do infrastruktury. W większości przypadków może to wystarczyć do prostego, ale funkcjonalnego tworzenia jezior danych.
Aby uzyskać dobrą wydajność, niezbędny jest wybór najlepszego projektu danych z naciskiem na przyszłe wykorzystanie. Istotne jest, aby bardzo jasno określić sposób, w jaki chcesz wybrać dane. Ponowne tworzenie tabel później, gdy już istnieją i są wypełnione dużą ilością danych, jest trudne.
Athena DB to doskonały wybór i dobre dopasowanie do celu, jeśli chcesz stworzyć prostą i niezmienną pulę danych, którą można łatwo skalować w poziomie w czasie.
Baza danych AWS Aurora
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Athena DB przoduje w przechowywaniu niesprawdzonych danych. W końcu w ten sposób chcesz przechowywać oryginalne treści, aby zmaksymalizować ich ponowne wykorzystanie w przyszłości. Jednak dostarczanie wybranych wyników do aplikacji frontonu jest powolne.
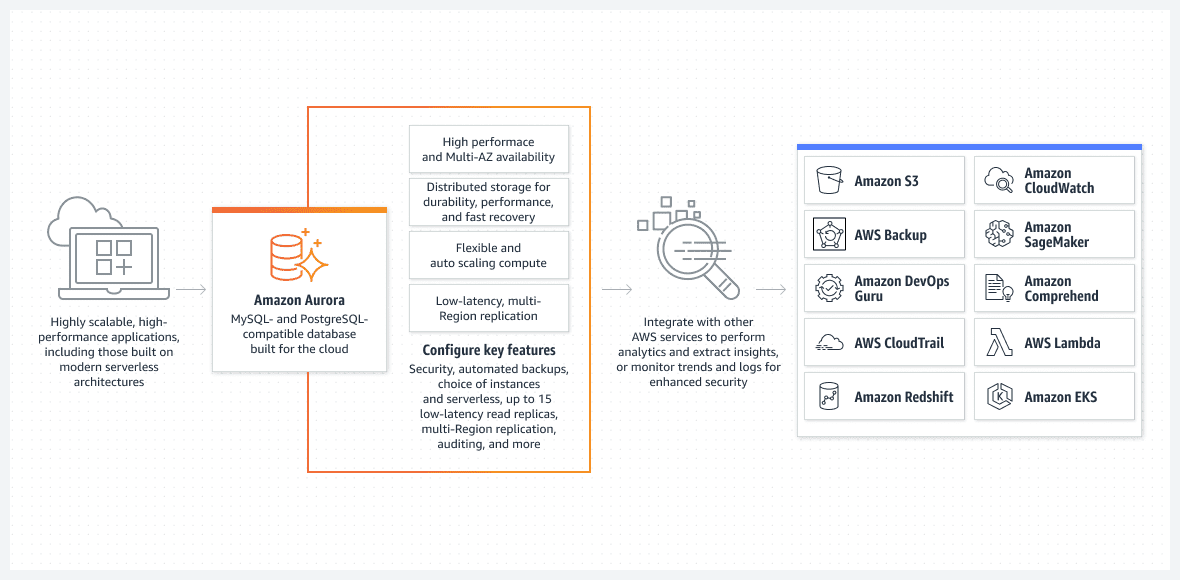
Jedną z najlepszych opcji, głównie z punktu widzenia łatwej konfiguracji, jest baza danych Aurora działająca w trybie serverless.
Aurora jest daleka od podstawowej bazy danych. Jest to jedno z najbardziej zaawansowanych natywnych rozwiązań relacyjnych baz danych w AWS. Jest to również wysoce złożone rozwiązanie natywnej relacyjnej bazy danych, które jest ulepszane z każdą wersją.
Aurora jest wyjątkowa, ponieważ może działać w trybie bezserwerowym, co wyróżnia ją spośród innych usług relacyjnych. Tak działa ten tryb:
- Aby skonfigurować klaster Aurora, użyj konsoli AWS. Będziesz musiał określić standardowe poziomy procesora i pamięci RAM, a także maksymalny interwał funkcji automatycznego skalowania. Wpłynie to na wydajność, którą klaster Aurora może dynamicznie dodawać lub usuwać. Na podstawie bieżącego wykorzystania bazy danych AWS decyduje o skalowaniu w górę lub w dół.
- Klaster Aurora nie uruchomi się, dopóki użytkownik lub proces nie zainicjuje prawdziwego żądania. Na przykład, gdy rozpocznie się zaplanowane przetwarzanie wsadowe. Lub jeśli aplikacja wykonuje wywołanie interfejsu API zaplecza w celu pobrania danych z bazy danych. Baza danych otworzy się automatycznie i pozostanie aktywna przez określony czas po zakończeniu procesów żądania.
- Klaster Aurora zostanie automatycznie zamknięty, jeśli w bazie danych nie będzie już żadnej pracy.
Aby podkreślić to jeszcze raz, bezserwerowa baza danych Aurora działa tylko wtedy, gdy musi wykonać prawdziwą pracę. Automatycznie uruchomiony klaster zostanie ponownie zamknięty, jeśli nie przetwarza żadnej pracy. Rzeczywista praca jest tym, za co płacisz, a nie czasem bezczynności.
Bezserwerowa Aurora jest w pełni zarządzana przez AWS i nie wymaga administratora.
Wzmocnienie AWS
Amplify oferuje bezserwerową platformę do szybkiego wdrażania aplikacji front-endowych wykonanych przy użyciu bibliotek JavaScript i React. Nie ma potrzeby konfigurowania serwerów klastrowych. Użyj konsoli AWS do bezpośredniego wdrożenia kodu lub użyj zautomatyzowanego potoku DevOps.
Możesz wywoływać interfejsy API zaplecza, aby uzyskać dostęp do danych przechowywanych w bazach danych. Te wywołania umożliwiają dostęp do rzeczywistych danych w aplikacji front-end. Główna optymalizacja wydajności na zapleczu powinna być wykonywana przez zespół. Możesz jeszcze bardziej zmniejszyć możliwość powolnej odpowiedzi w interfejsie użytkownika, jeśli zaprojektujesz efektywne instrukcje wyboru bezpośrednio w wywołaniach API.
Funkcje krokowe AWS
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Nawet jeśli wszystkie główne komponenty systemu są bezserwerowe, nie gwarantuje to całkowicie bezserwerowej architektury. Jest to możliwe tylko wtedy, gdy wszystkie procesy wsadowe między komponentami są bezserwerowe.
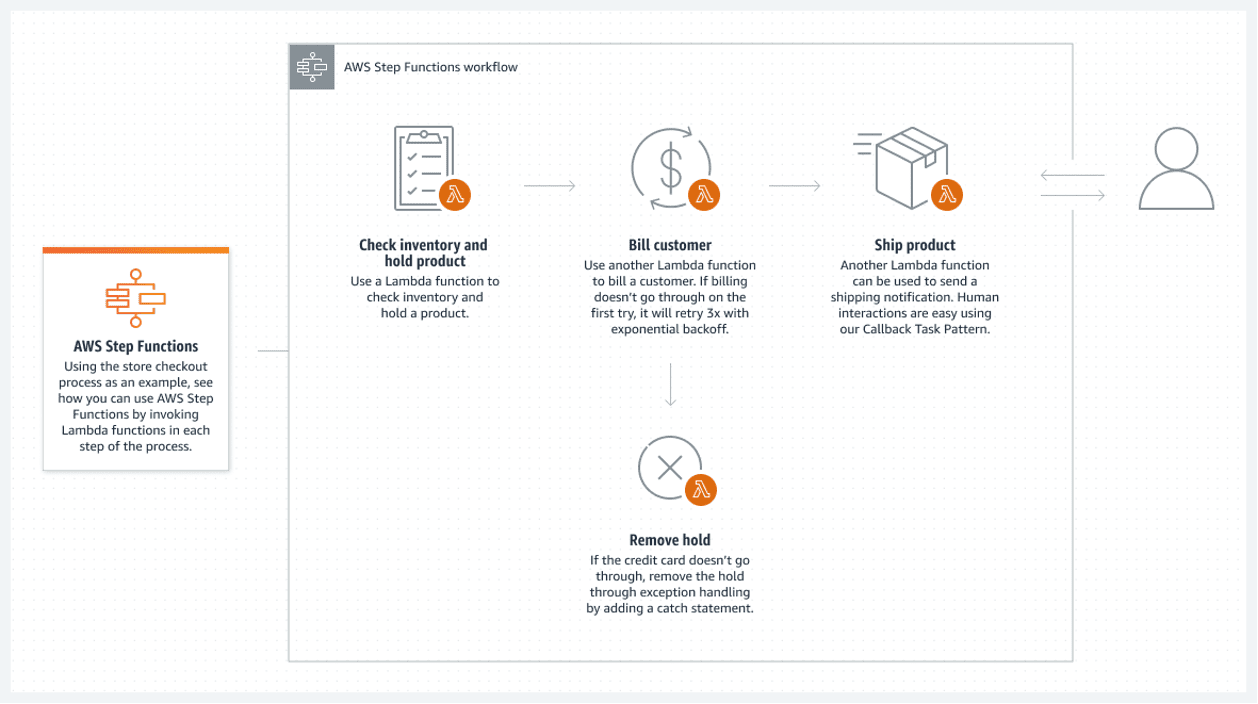
Funkcje AWS Step zapewniają najlepsze rozwiązanie w chmurze AWS. Połączona lista funkcji AWS Lambda tworzy funkcję krokową. Te funkcje tworzą schemat blokowy, który ma wyraźne stany początkowe i końcowe. Funkcja lambda, zwykle napisana w językach Python lub Node JS, to wykonywalny fragment kodu, który przetwarza wszystko, co jest potrzebne.
Poniżej znajduje się przykład wykonania funkcji krokowej:
Ten przepływ bezserwerowy ma jedną poważną wadę: każda funkcja lambda może działać maksymalnie przez 15 minut. Dlatego podzielenie przepływu na mniejsze funkcje lambda może sprawić, że będzie to mniej problematyczne.
Możliwe jest wywołanie wielu funkcji lambda jednocześnie w jednym kroku, co zasadniczo oznacza zrównoleglenie kroku z wieloma lambdami wykonywanymi jednocześnie. Po prostu poczekaj, aż wszystkie równoległe przetwarzanie lambda zakończy się, zanim przejdziesz dalej. Następnie przejdź do następnego przetwarzania lambda.
Ostatnie słowa
Architektura bezserwerowa oferuje wyjątkową możliwość stworzenia platformy chmurowej obejmującej cały krajobraz systemowy. Ta platforma jest skalowalna w poziomie i ma przy tym niskie koszty operacyjne.
Jest to idealne rozwiązanie dla projektów o ograniczonym budżecie. Jest to doskonała opcja eksploracji, zwykle wtedy, gdy nikt nie zna rzeczywistego obciążenia produkcyjnego. Jest to szczególnie ważne po pomyślnym włączeniu wszystkich użytkowników. Zespoły projektowe mogą nadal uzyskać ogólny obraz działania systemu. Możesz mieć wszystkie te korzyści i nadal nie musisz godzić się na kompromisy.
To pokrycie nie będzie odpowiednie dla wszystkich przypadków, szczególnie tych, które wymagają dużego użycia procesora. Jednak chmura AWS stale ewoluuje pod względem przypadków użycia bezserwerowego. Zwykle dobrym pomysłem jest przeprowadzenie dokładnych badań, zanim zdecydujesz się na opcję bezserwerową dla swojego następnego projektu chmurowego AWS.
Następnie sprawdź najlepsze bezserwerowe bazy danych dla nowoczesnych aplikacji.