
Masz problem z debugowaniem kodu? Szukasz rozwiązań do rejestrowania, które mogą ułatwić debugowanie? Czytaj dalej, aby dowiedzieć się więcej.
Tworzenie oprogramowania przechodzi przez kilka faz: zbieranie wymagań, analiza, kodowanie, testowanie i konserwacja. Spośród wszystkich tych faz, faza kodowania/rozwoju wymaga dużo czasu i wysiłku. Inżynierowie oprogramowania zajmują się błędami składni, błędami logicznymi i błędami w czasie wykonywania. Błędy syntaktyczne są identyfikowane w czasie kompilacji i występują z powodu nieprzestrzegania przez kod zasad języka programowania.
Z drugiej strony, błędy logiczne i błędy czasu wykonywania nie mogą zostać zidentyfikowane przez zintegrowane środowisko programistyczne (IDE) i często są trudne do debugowania i naprawiania. Usuwanie błędów to czasochłonny proces i wymaga dużo debugowania.
Debugowanie to proces, w którym próbuje się zrozumieć, dlaczego napisany kod nie działa zgodnie z oczekiwaniami. Łatwo jest rozwiązać problem, gdy znamy błąd i dokładnie znamy wiersze w kodzie, w którym on występuje. Dlatego rejestrowanie jest bardzo przydatne do debugowania kodu.
Spis treści:
Co to jest rejestrowanie?
Rejestrowanie to technika, w której komunikaty są przechwytywane podczas wykonywania programu. Należy rejestrować tylko te komunikaty, które mogą im pomóc w debugowaniu. Tak więc wiedza o tym, kiedy dodać do kodu instrukcje dziennika, jest niezwykle ważna. Równie istotne jest również rozróżnianie instrukcji dziennika. Istnieją różne poziomy rejestrowania, takie jak informacje, ostrzeżenie, błąd, debugowanie i pełne. Oświadczenia o błędach i ostrzeżenia są używane do obsługi wyjątków.

Dane zwracane z funkcji, wyniki po manipulacji tablicami, dane pobierane z interfejsów API itp. to tylko niektóre przykłady danych, które można rejestrować za pomocą instrukcji info. Do szczegółowego opisu błędów służą dzienniki debugowania i pełne.
Dziennik debugowania zawiera informacje o śledzeniu stosu, parametrach wejścia-wyjścia itp. „Szczegółowy” nie jest tak szczegółowy jak dziennik „debugowania”, ale zawiera listę wszystkich zdarzeń, które miały miejsce. Dzienniki są zapisywane w konsoli, plikach i strumieniu wyjściowym. Narzędzia do zarządzania dziennikami mogą być używane do rejestrowania strukturalnego i sformatowanego.
Rejestrowanie Node.js
Nodejs to środowisko uruchomieniowe JavaScript. Aplikacje Node.js są asynchroniczne i nieblokujące i są używane w systemach intensywnie korzystających z danych i pracujących w czasie rzeczywistym. Najlepszym sposobem, aby dowiedzieć się więcej o Node.js, jest zapoznanie się z samouczkami Node.js i jego dokumentacją. Rejestrowanie jest wymagane w celu poprawy wydajności, rozwiązywania problemów i śledzenia błędów. Logowanie do Node.js odbywa się za pomocą wbudowanej funkcji console.log. Ponadto funkcja debugowania jest połączona z wieloma pakietami i może być skutecznie używana.
Oprogramowanie pośredniczące służy do zarządzania żądaniami i odpowiedziami. Oprogramowaniem pośrednim może być aplikacja lub dowolny inny framework JavaScript. Logowanie w oprogramowaniu pośredniczącym może odbywać się za pośrednictwem aplikacji i routerów. Każdy program rejestrujący Node.js musi użyć polecenia npm lub yarn install, aby zainstalować programy rejestrujące.
Npm oznacza „Node Package Manager”, a YARN oznacza „Yet Another Resource Negotiator”. Jednak Yarn jest preferowany w porównaniu z npm, ponieważ jest szybszy i instaluje pakiety równolegle.
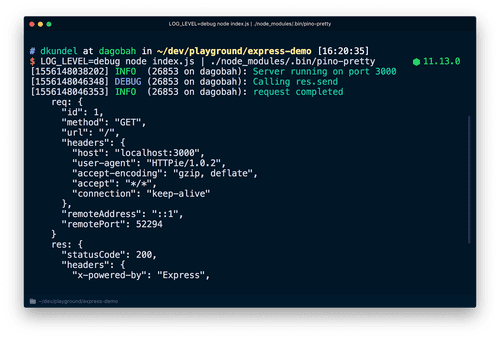
Poniżej wymieniono niektóre z najlepszych rejestratorów Node.js:
Pino
Pino to biblioteka będąca jednym z najlepszych loggerów dla aplikacji Node.js. Jest to oprogramowanie typu open source, niezwykle szybkie i rejestruje instrukcje w łatwym do odczytania formacie JSON. Niektóre z poziomów dziennika Pino to — komunikaty debugowania, ostrzeżenia, błędy i informacje. Instancję rejestratora Pino można zaimportować do projektu, a instrukcje console.log należy zastąpić instrukcjami logger.info.

Użyj następującego polecenia, aby zainstalować Pino:
$ npm install pino
Generowane logi są rozbudowane i w formacie JSON, z zaznaczeniem numeru linii logu, typu logu, czasu kiedy był logowany itp. Pino powoduje minimalne narzuty logowania w aplikacji i jest niezwykle elastyczny podczas przetwarzania logów.
Pino można zintegrować z frameworkami internetowymi, takimi jak Hapi, Restify, Express itp. Logi generowane przez Pino można również przechowywać w plikach. Do działania używa wątków roboczych i jest zgodny z TypeScript.
Winston
Winston obsługuje rejestrowanie dla różnych platform internetowych, koncentrując się przede wszystkim na elastyczności i rozszerzalności. Obsługuje wiele rodzajów transportu i może przechowywać logi w różnych lokalizacjach plików. Transporty to miejsca, w których przechowywane są komunikaty dziennika.
Wraz z niektórymi wbudowanymi transportami, takimi jak Http, Console, File i Stream, obsługuje inne transporty, takie jak Cloud Watch i MongoDB. Loguje się na różnych poziomach i formatach. Poziomy rejestrowania wskazują powagę problemu.

Poniżej przedstawiono różne poziomy rejestrowania:
{
error: 0,
warn: 1,
info: 2,
http: 3,
verbose: 4,
debug: 5,
silly: 6
}
Format wyjściowy dziennika można dostosować, filtrować i łączyć. Dzienniki zawierają informacje o sygnaturze czasowej, etykietach powiązanych z dziennikiem, milisekundach, które upłynęły od poprzedniego dziennika itp.
Winston zajmuje się również wyjątkami i niezrealizowanymi obietnicami. Zapewnia dodatkowe funkcje, takie jak wypełnianie zapytań, dzienniki strumieniowe itp. Po pierwsze, należy zainstalować Winston. Następnie tworzony jest obiekt konfiguracyjny Winston wraz z transportem do przechowywania dziennika. Obiekt rejestratora jest tworzony przy użyciu funkcji createLogger() i przesyłany jest do niego komunikat dziennika.
Węzeł Bunyan
Bunyan służy do szybkiego logowania w node.js w formacie JSON. Udostępnia również narzędzie CLI (interfejs wiersza poleceń) do przeglądania dzienników. Jest lekki i obsługuje różne środowiska uruchomieniowe, takie jak Node.js, Browserify, WebPack i NW.js. Format JSON dzienników jest dodatkowo upiększany za pomocą ładnej funkcji drukowania. Dzienniki mają różne poziomy, takie jak krytyczny, błąd, ostrzeżenie, informacje, debugowanie i śledzenie; każdy jest powiązany z wartością liczbową.

Wszystkie poziomy powyżej poziomu ustawionego dla instancji są rejestrowane. Strumień Bunyan to miejsce, w którym zapisywane są dane wyjściowe. Podkomponenty aplikacji można rejestrować za pomocą funkcji log.child(). Wszystkie rejestratory podrzędne są powiązane z określoną aplikacją nadrzędną. Typ strumienia może być plikiem, plikiem rotacyjnym, danymi surowymi itp. Przykładowy kod do definiowania strumienia pokazano poniżej:
var bunyan = require('bunyan');
var log = bunyan.createLogger({
name: "foo",
streams: [
{
stream: process.stderr,
level: "debug"
},
...
]
});
Bunyan obsługuje również logowanie DTrace. Sondy zaangażowane w rejestrowanie DTrace obejmują log-trace, log-warn, log-error, log-info, log-debug i log-fatal. Bunyan używa serializatorów do tworzenia dzienników w formacie JSON. Funkcje serializatora nie zgłaszają wyjątków i są obronne.
Poziom logowania
Loglevel służy do logowania w aplikacjach Javascript. Jest to również jeden z najlepszych rejestratorów Node.js, ponieważ jest lekki i prosty. Rejestruje dany poziom i używa do rejestrowania pojedynczego pliku bez zależności. Domyślny poziom rejestrowania to „ostrzegaj”. Dane wyjściowe dziennika są dobrze sformatowane wraz z numerami wierszy. Niektóre metody używane do rejestrowania to śledzenie, debugowanie, ostrzeganie, błędy i informacje.
Są odporne na awarie w każdym środowisku. getLogger() to metoda używana do pobierania obiektu rejestratora. Można go również łączyć z innymi wtyczkami, aby rozszerzyć jego funkcje. Niektóre z wtyczek to loglevel-plugin-prefix, loglevel-plugin-remote, ServerSend i DEBUG. Wtyczka do dodawania komunikatów prefiksowych do logowania jest pokazana poniżej:
var originalFactory = log.methodFactory;
log.methodFactory = function (methodName, logLevel, loggerName) {
var rawMethod = originalFactory(methodName, logLevel, loggerName);
return function (message) {
rawMethod("Newsflash: " + message);
};
};
log.setLevel(log.getLevel()); // Be sure to call setLevel method in order to apply plugin
Kompilacje są uruchamiane za pomocą polecenia npm run dist, a testy można uruchamiać za pomocą polecenia npm test. Poziom dziennika obsługuje pakiety Webjar, Bower i Atmosphere. Nowa wersja Loglevel jest wydawana za każdym razem, gdy dodawane są nowe funkcje.
Sygnał
Signale składa się z 19 rejestratorów dla aplikacji Javascript. Obsługuje TypeScript i rejestrowanie w zakresie. Składa się z liczników czasu, które pomagają rejestrować znacznik czasu, dane i nazwę pliku. Oprócz 19 loggerów, takich jak await, complete, fatal, fav, info itp., można tworzyć własne logi.
Dzienniki niestandardowe są tworzone przez zdefiniowanie obiektu JSON i pól z danymi rejestratora. Można również tworzyć interaktywne rejestratory. Gdy interaktywny rejestrator jest ustawiony na wartość true, nowe wartości z interaktywnych rejestratorów zastępują stare.
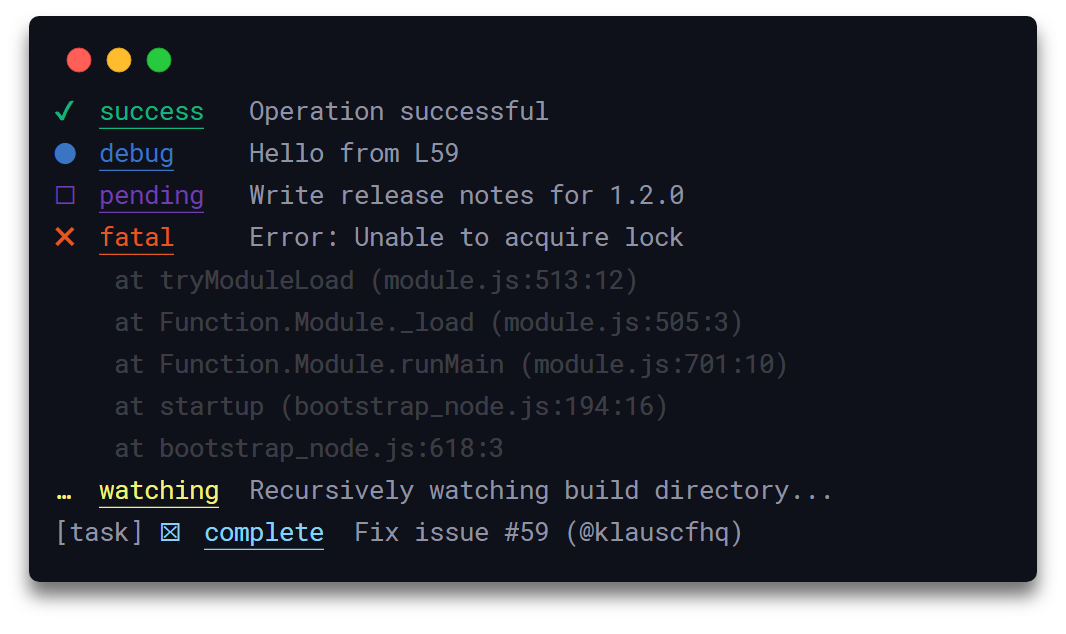
Najlepszą częścią Signale jest możliwość odfiltrowania tajnych lub poufnych informacji. W tablicy przechowywanych jest wiele wpisów tajnych. addSecrets() i clearSecrets() to funkcje służące do dodawania i usuwania sekretów z tablicy. Boostnote, Docz, Shower, Taskbook i Vant używają Signale do logowania. Składnia wywoływania interfejsów API z Signale jest następująca:
signale.<logger>(message[,message]|messageObj|errorObj)
Liczba pobrań Signale przekracza 1 milion w momencie pisania tego artykułu.
Kreślarz
Tracer służy do tworzenia szczegółowych komunikatów rejestrujących. Komunikaty rejestrowania składają się z sygnatur czasowych, nazw plików, numerów wierszy i nazw metod. Pakiety pomocnicze można zainstalować w celu dostosowania wyjściowego formatu rejestrowania. Pakiety pomocnicze można zainstalować za pomocą następującego polecenia.
npm install -dev tracer
Tracer obsługuje transport plików, strumieni i MongoDB. Obsługuje konsolę kolorów i warunki filtrowania w logowaniu. Początkowo znacznik musi zostać zainstalowany za pomocą npm install. Po drugie, należy utworzyć obiekt loggera i wybrać rodzaj konsoli. Następnie w obiekcie można określić różne poziomy lub typy rejestrowania w celu dalszego rejestrowania.
Dostosowane filtry można tworzyć, definiując funkcje synchroniczne z logiką biznesową obecną w treści funkcji. Mikro-szablony, takie jak tinytim, mogą być również używane do rejestrowania systemu.
Cabin.js
Kabina służy do rejestrowania aplikacji node.js po stronie serwera i klienta. Jest używany tam, gdzie wymagane jest maskowanie informacji wrażliwych i krytycznych. Obejmuje to numery kart kredytowych, nagłówki BasicAuth, sole, hasła, tokeny CSRF i numery kont bankowych. Poniższy fragment kodu pokazuje logowanie przy użyciu Cabin.js.
const Cabin = require('cabin');
const cabin = new Cabin();
cabin.info('hello world');
cabin.error(new Error('oops!'));
Składa się z ponad 1600 nazw pól. Jest to również zgodne z zasadą Bring Your Own Logger (BYOL). Dzięki temu jest kompatybilny z różnymi innymi rejestratorami, takimi jak Axe, Pino, Bunyan, Winston itp. Zmniejsza koszty przechowywania na dyskach dzięki automatycznemu buforowaniu strumieniowemu i kabinowemu. Jest kompatybilny z wieloma platformami i łatwy do debugowania.
Rejestrowanie po stronie serwera wymaga użycia oprogramowania pośredniczącego do routingu i automatycznego rejestrowania danych wyjściowych. Rejestrowanie po stronie przeglądarki wymaga żądań i skryptów XHR. Wykorzystuje Ax, który wyświetla metadane, tj. dane o danych, ślady stosu i inne błędy. SHOW_STACK i SHOW_META to zmienne logiczne ustawione na wartość prawda lub fałsz, aby pokazać lub ukryć ślady stosu i metadane.
Npmlog
Npmlog to podstawowy typ rejestratora, którego używa npm. Niektóre z używanych metod rejestrowania to poziom, rekord, maxRecordSize, prefixStyle, nagłówek i strumień. Obsługuje również logowanie w kolorze. Różne poziomy rejestrowania to głupie, szczegółowe, informacyjne, ostrzegawcze, http i błąd. Przykładowy fragment kodu do korzystania z dziennika npm pokazano poniżej.
var log = require('npmlog')
// additional stuff ---------------------------+
// message ----------+ |
// prefix ----+ | |
// level -+ | | |
// v v v v
log.info('fyi', 'I have a kitty cat: %j', myKittyCat)
Wszystkie komunikaty są pomijane, jeśli jako poziom rejestrowania określono „Nieskończoność”. Jeśli jako poziom dziennika określono „-Nieskończoność”, opcja wyświetlania komunikatów dziennika musi być włączona, aby można było zobaczyć dzienniki.
Do rejestrowania wykorzystywane są zdarzenia i obiekty komunikatów. Komunikaty prefiksowe są emitowane, gdy używane są zdarzenia prefiksowe. Obiekty stylu są używane do formatowania dzienników, na przykład dodawania koloru do tekstu i tła, stylu czcionki, takiego jak pogrubienie, kursywa, podkreślenie itp. Niektóre pakiety dzienników npm to brolog, npmlogger, npmdate log itp.
Ryk
Roarr to rejestrator dla Node.js, który nie wymaga inicjalizacji i generuje uporządkowane dane. Ma CLI i zmienne środowiskowe. Jest kompatybilny z przeglądarką. Może być zintegrowany z Fastify, Fastify, Elastic Search itp. Rozróżnia kod aplikacji od kodu zależności. Każdy komunikat dziennika składa się z kontekstu, komunikatu, sekwencji, czasu i wersji. Różne poziomy dzienników obejmują śledzenie, debugowanie, informacje, ostrzeżenie, błąd i krytyczny. Przykładowy fragment kodu dotyczący sposobu rejestrowania Roarr jest następujący:
import {
ROARR,
} from 'roarr';
ROARR.write = (message) => {
console.log(JSON.parse(message));
};
Można również wykonać serializację błędów, co oznacza, że wystąpienie z błędem może być rejestrowane wraz z kontekstem obiektu. Niektóre zmienne środowiskowe specyficzne dla Node.js i Roarr to ROARR_LOG i ROARR_STREAM. „adoptuj” to funkcja używana z node.js do przekazywania właściwości kontekstu na różne poziomy. Funkcje potomne mogą być również używane z oprogramowaniem pośredniczącym podczas logowania.
Ostatnie słowa
Rejestrowanie to metoda śledzenia różnych czynności i zdarzeń podczas wykonywania programu. Rejestrowanie odgrywa istotną rolę w debugowaniu kodu. Pomaga również w zwiększeniu czytelności kodu. Node.js to otwarte środowisko uruchomieniowe JavaScript. Niektóre z najlepszych rejestratorów Node.js to Pino, Winston, Bunyan, Signale, Tracer, Npmlog itp. Każdy typ rejestratora ma swoje własne funkcje, takie jak profilowanie, filtrowanie, przesyłanie strumieniowe i transport.
Niektóre rejestratory obsługują kolorowe konsole, a niektóre nadają się do obsługi poufnych informacji. Szczegółowe i sformatowane dzienniki najbardziej pomagają programistom, gdy próbują naprawić błędy w swoim kodzie. Format JSON jest ogólnie preferowany do rejestrowania, ponieważ rejestruje dane w postaci par klucz-wartość, dzięki czemu jest przyjazny dla użytkownika.
Rejestratory mogą być również zintegrowane z innymi aplikacjami i są kompatybilne z wieloma przeglądarkami. Zawsze zaleca się przyjrzenie się potrzebom i tworzonym aplikacjom przed wyborem typu rejestratora, którego chcesz użyć.
Możesz również przyjrzeć się, jak zainstalować Node.js i NPM w systemach Windows i macOS.