
Hurtownia danych. Jezioro danych. Dom nad jeziorem. Jeśli żadne z tych słów nie rezonuje z tobą przynajmniej trochę, to twoja praca najwyraźniej nie jest związana z danymi.
Byłoby to jednak dość nierealistyczne założenie, ponieważ dzisiaj wydaje się, że wszystko jest związane z danymi. Albo jak lubią to opisywać liderzy korporacji:
- Biznes zorientowany na dane i oparty na danych.
- Dane w dowolnym miejscu i czasie.
Spis treści:
Najważniejszy zasób
Wygląda na to, że dane stały się najcenniejszym zasobem coraz większej liczby firm. Pamiętam, że duże korporacje zawsze generowały dużo danych, myślę, że każdego miesiąca terabajty nowych danych. To było jeszcze 10-15 lat temu. Ale teraz możesz łatwo wygenerować taką ilość danych w ciągu kilku dni. Można by zapytać, czy jest to naprawdę konieczne, nawet jeśli jest to jakaś treść, z której każdy będzie korzystał. I tak, zdecydowanie nie jest 😃.
Nie wszystkie treści będą przydatne, a niektóre części ani razu. Często byłem świadkiem na pierwszej linii frontu, jak firmy generowały ogromne ilości danych, które po udanym załadowaniu stawały się bezużyteczne.
Ale to już nie aktualne. Przechowywanie danych – teraz w chmurze – jest tanie, źródła danych rosną wykładniczo, a dziś nikt nie jest w stanie przewidzieć, czego będzie potrzebował za rok, kiedy nowe usługi zostaną włączone do systemu. W tym momencie nawet stare dane mogą stać się cenne.
Dlatego strategia polega na przechowywaniu jak największej ilości danych. Ale także w jak najbardziej efektownej formie. Dzięki temu dane mogą być nie tylko skutecznie zapisywane, ale także wyszukiwane, ponownie wykorzystywane lub przekształcane i dalej rozpowszechniane.
Przyjrzyjmy się trzem natywnym sposobom osiągnięcia tego w AWS:
- Baza danych Athena – tani i skuteczny, choć prosty sposób na stworzenie jeziora danych w chmurze.
- Redshift Database – poważna chmurowa wersja hurtowni danych, która może zastąpić większość obecnych rozwiązań on-premise, nie nadążając za wykładniczym przyrostem danych.
- Databricks – połączenie jeziora danych i hurtowni danych w jedno rozwiązanie, z pewnym bonusem do tego wszystkiego.
Data Lake od AWS Athena
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Jezioro danych to miejsce, w którym można szybko przechowywać dane przychodzące w formie nieustrukturyzowanej, częściowo ustrukturyzowanej lub ustrukturyzowanej. Jednocześnie nie oczekujesz, że te dane zostaną zmodyfikowane po ich zapisaniu. Zamiast tego chcesz, aby były jak najbardziej atomowe i niezmienne. Tylko to zapewni największe możliwości ponownego wykorzystania na późniejszych etapach. Jeśli utraciłbyś tę atomową właściwość danych zaraz po pierwszym załadowaniu do jeziora danych, nie ma możliwości odzyskania tych utraconych informacji.
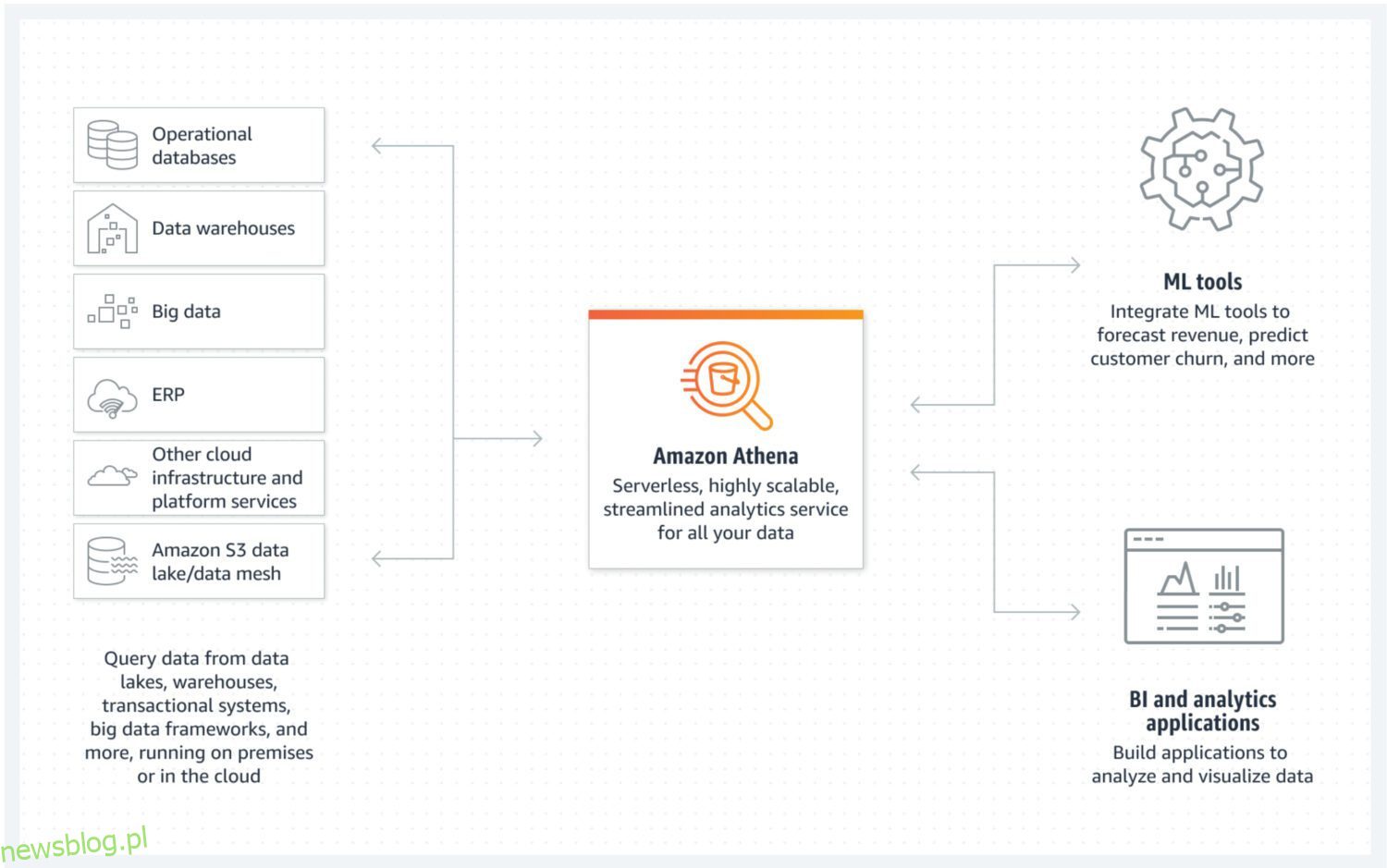
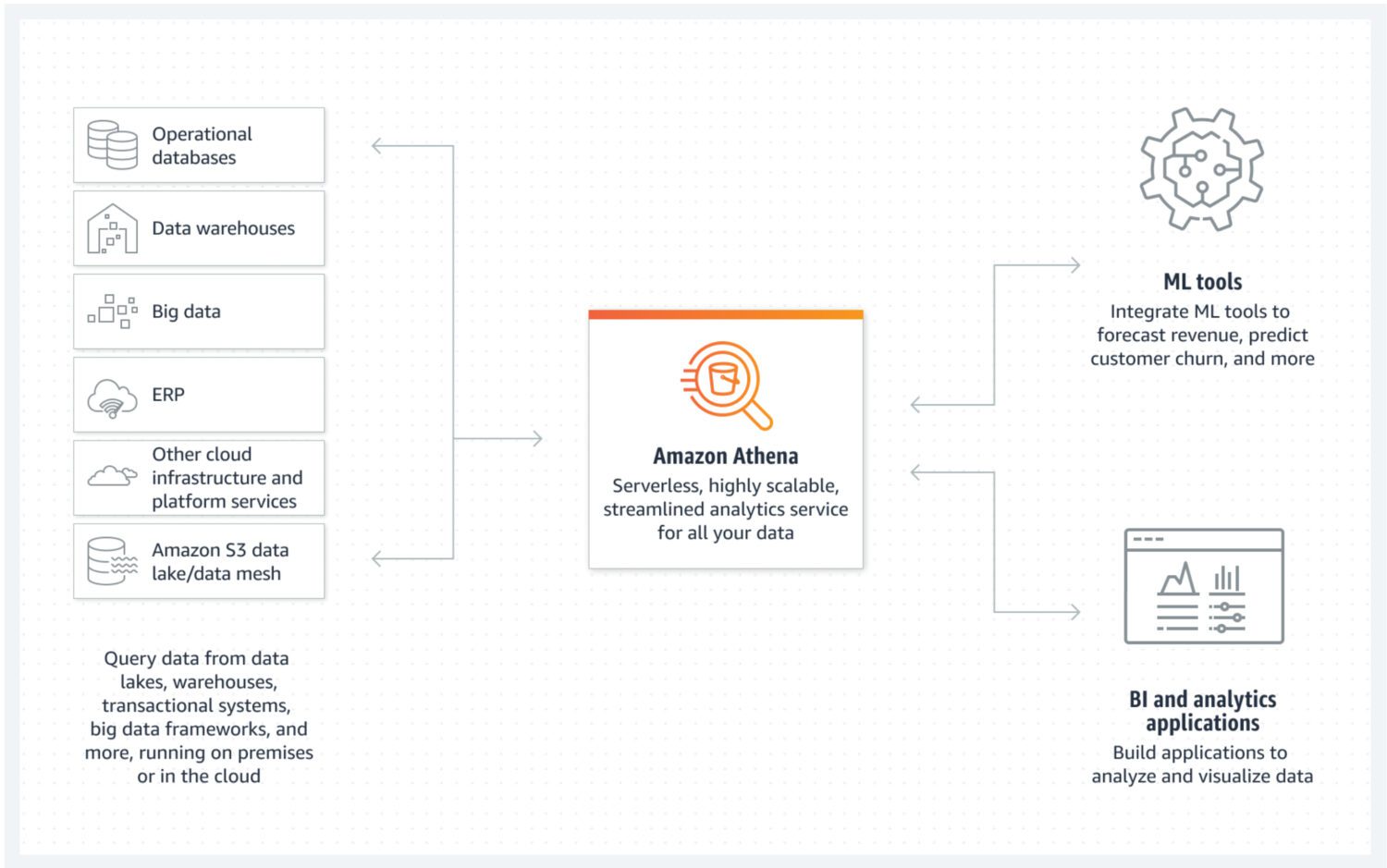
AWS Athena to baza danych z pamięcią masową bezpośrednio w zasobnikach S3 i bez działających w tle klastrów serwerów. Oznacza to, że jest to naprawdę tania usługa data lake. Strukturyzowane formaty plików, takie jak Parquet lub pliki z wartościami rozdzielanymi przecinkami (CSV), umożliwiają zachowanie organizacji danych. Zasobnik S3 przechowuje pliki, a Athena odwołuje się do nich za każdym razem, gdy procesy wybierają dane z bazy danych.
Athena nie obsługuje różnych funkcji uznawanych za standardowe, takich jak instrukcje aktualizacji. Dlatego musisz spojrzeć na Atenę jako na bardzo prostą opcję. Z drugiej strony pomaga zapobiegać modyfikacjom twojego atomowego jeziora danych tylko dlatego, że nie możesz 😐.
Obsługuje indeksowanie i partycjonowanie, co czyni go użytecznym do efektywnego wykonywania instrukcji select i tworzenia logicznie oddzielnych porcji danych (na przykład oddzielonych datami lub kluczowymi kolumnami). Można go również bardzo łatwo skalować w poziomie, ponieważ jest to tak skomplikowane, jak dodawanie nowych zasobników do infrastruktury.

Plusy i minusy
Korzyści do rozważenia:
- Fakt, że Athena jest tania (składająca się tylko z segmentów S3 i kosztów użytkowania SQL na użycie) stanowi największą zaletę. Jeśli chcesz zbudować niedrogie jezioro danych w AWS, to jest to.
- Jako usługa natywna, Athena może łatwo integrować się z innymi przydatnymi usługami AWS, takimi jak Amazon QuickSight do wizualizacji danych lub AWS Glue Data Catalog w celu tworzenia trwałych ustrukturyzowanych metadanych.
- Najlepsze do uruchamiania zapytań ad hoc na dużej ilości ustrukturyzowanych lub nieustrukturyzowanych danych bez utrzymywania wokół nich całej infrastruktury.
Wady do rozważenia:
- Athena nie jest szczególnie skuteczna w szybkim zwracaniu złożonych zapytań wybierających, zwłaszcza jeśli zapytania nie są zgodne z założeniami modelu danych dotyczącymi sposobu, w jaki zaprojektowano żądanie danych z jeziora danych.
- To również czyni go mniej elastycznym w odniesieniu do potencjalnych przyszłych zmian w modelu danych.
- Athena nie obsługuje żadnych dodatkowych zaawansowanych funkcjonalności, a jeśli chcesz, aby coś konkretnego było częścią usługi, musisz to zaimplementować na wierzchu.
- Jeśli spodziewasz się wykorzystania danych data lake w jakiejś bardziej zaawansowanej warstwie prezentacji, często jedynym wyborem jest połączenie ich z inną usługą bazodanową bardziej odpowiednią do tego celu, jak AWS Aurora lub AWS Dynamo DB.
Cel i rzeczywisty przypadek użycia
Wybierz Athenę, jeśli celem jest stworzenie prostego jeziora danych bez zaawansowanych funkcjonalności przypominających hurtownię danych. Na przykład, jeśli nie oczekujesz poważnych, wysokowydajnych zapytań analitycznych, które są regularnie uruchamiane w jeziorze danych. Zamiast tego priorytetem jest posiadanie puli niezmiennych danych z łatwym rozszerzeniem przechowywania danych.
Nie musisz już zbytnio martwić się brakiem miejsca. Nawet koszt magazynowania zasobników S3 można jeszcze bardziej obniżyć, wdrażając politykę cyklu życia danych. Zasadniczo oznacza to przenoszenie danych między różnymi typami segmentów S3, ukierunkowanych bardziej na cele archiwalne z wolniejszym czasem powrotu do przetwarzania, ale niższymi kosztami.
Wspaniałą cechą Atheny jest to, że automatycznie tworzy plik składający się z danych, które są częścią wyniku zapytania SQL. Następnie możesz wziąć ten plik i użyć go w dowolnym celu. Jest to więc dobra opcja, jeśli masz wiele usług lambda, które dalej przetwarzają dane w wielu krokach. Każdy wynik lambda będzie automatycznie wynikiem w ustrukturyzowanym formacie pliku jako dane wejściowe gotowe do dalszego przetwarzania.
Athena to dobra opcja w sytuacjach, gdy do Twojej infrastruktury chmurowej trafia duża ilość nieprzetworzonych danych, których nie trzeba przetwarzać w momencie ładowania. Oznacza to, że wszystko, czego potrzebujesz, to szybkie przechowywanie w chmurze w łatwej do zrozumienia strukturze.
Innym przypadkiem użycia byłoby stworzenie dedykowanej przestrzeni do celów archiwizacji danych dla innego serwisu. W takim przypadku Athena DB stałaby się tanim miejscem na kopie zapasowe dla wszystkich danych, których nie potrzebujesz w tej chwili, ale może się to zmienić w przyszłości. W tym momencie po prostu pochłoniesz dane i wyślesz je dalej.
Hurtownia danych od AWS Redshift
 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Hurtownia danych to miejsce, w którym dane są przechowywane w bardzo uporządkowany sposób. Łatwy do załadowania i wyjęcia. Intencją jest uruchomienie dużej liczby bardzo złożonych zapytań, łączących wiele tabel za pomocą złożonych sprzężeń. Dostępne są różne funkcje analityczne do obliczania różnych statystyk na podstawie istniejących danych. Ostatecznym celem jest wyodrębnienie przyszłych prognoz i faktów, które można wykorzystać w przyszłości, korzystając z istniejących danych.
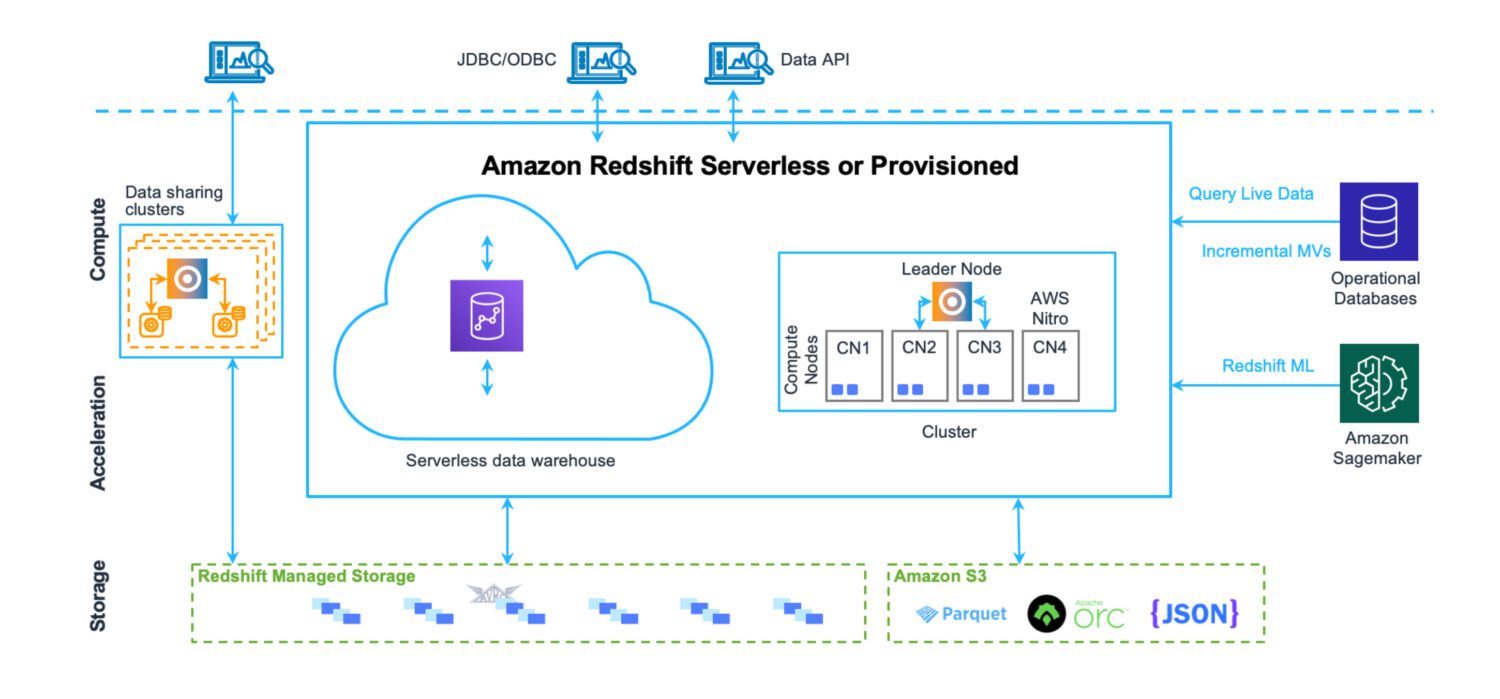
Redshift to pełnoprawny system hurtowni danych. Z serwerami klastrowymi do dostrajania i skalowania — w poziomie i w pionie oraz systemem pamięci masowej bazy danych zoptymalizowanym pod kątem szybkich zwrotów złożonych zapytań. Chociaż dzisiaj możesz uruchomić Redshift również w trybie bezserwerowym. Nie ma żadnych plików na S3 ani nic podobnego. Jest to standardowy serwer klastra bazy danych z własnym formatem przechowywania.
Ma gotowe narzędzia do monitorowania wydajności, a także konfigurowalne metryki na pulpicie nawigacyjnym, których możesz używać i obserwować, aby dostosować wydajność do swojego przypadku użycia. Administracja jest również dostępna za pośrednictwem oddzielnych pulpitów nawigacyjnych. Zrozumienie wszystkich możliwych funkcji i ustawień oraz ich wpływu na klaster wymaga trochę wysiłku. Nigdzie jednak nie jest to tak skomplikowane, jak kiedyś było administrowanie serwerami Oracle w przypadku rozwiązań on-premise.
Chociaż istnieją różne limity AWS w Redshift, które wyznaczają pewne granice korzystania z niego na co dzień (na przykład sztywne limity liczby jednoczesnych aktywnych użytkowników lub sesji w jednym klastrze bazy danych), fakt, że operacje są wykonywane naprawdę szybko pomaga w pewnym stopniu obejść te ograniczenia.

Plusy i minusy
Korzyści do rozważenia:
- Natywna usługa hurtowni danych w chmurze AWS, którą można łatwo zintegrować z innymi usługami.
- Centralne miejsce do przechowywania, monitorowania i pozyskiwania różnych typów źródeł danych z bardzo różnych systemów źródłowych.
- Jeśli kiedykolwiek chciałeś mieć bezserwerową hurtownię danych bez infrastruktury do jej utrzymania, teraz możesz.
- Zoptymalizowany pod kątem wysokowydajnych analiz i raportów. W przeciwieństwie do rozwiązania typu data lake istnieje silny relacyjny model danych do przechowywania wszystkich przychodzących danych.
- Silnik bazy danych Redshift wywodzi się z PostgreSQL, co zapewnia wysoką kompatybilność z innymi systemami bazodanowymi.
- Bardzo przydatne instrukcje COPY i UNLOAD do ładowania i rozładowywania danych zi do zasobników S3.
Wady do rozważenia:
- Redshift nie obsługuje dużej liczby jednoczesnych aktywnych sesji. Sesje będą zawieszane i przetwarzane sekwencyjnie. Chociaż w większości przypadków może to nie stanowić problemu, ponieważ operacje są naprawdę szybkie, jest to czynnik ograniczający w systemach z wieloma aktywnymi użytkownikami.
- Mimo że Redshift obsługuje wiele funkcjonalności znanych wcześniej z dojrzałych systemów Oracle, to wciąż nie jest na tym samym poziomie. Niektóre oczekiwane funkcje mogą po prostu nie istnieć (takie jak wyzwalacze DB). Lub Redshift obsługuje je w dość ograniczonej formie (jak zmaterializowane widoki).
- Ilekroć potrzebujesz bardziej zaawansowanego niestandardowego zadania przetwarzania danych, musisz utworzyć je od podstaw. W większości przypadków używaj języka kodu Python lub JavaScript. Nie jest to tak naturalne jak PL/SQL w przypadku systemu Oracle, gdzie nawet funkcja i procedury używają języka bardzo podobnego do zapytań SQL.
Cel i rzeczywisty przypadek użycia
Redshift może być Twoim centralnym magazynem dla wszystkich różnych źródeł danych, które wcześniej znajdowały się poza chmurą. Jest to ważny zamiennik poprzednich rozwiązań hurtowni danych Oracle. Ponieważ jest to jednocześnie relacyjna baza danych, migracja z Oracle jest nawet dość prostą operacją.
Jeśli masz jakieś istniejące rozwiązania hurtowni danych w wielu miejscach, które nie są tak naprawdę ujednolicone pod względem podejścia, struktury lub predefiniowanego zestawu wspólnych procesów do uruchamiania nad danymi, Redshift jest doskonałym wyborem.
To po prostu zapewni Ci możliwość połączenia wszystkich różnych systemów hurtowni danych z różnych miejsc i krajów pod jednym dachem. Nadal możesz je rozdzielić według kraju, aby dane pozostały bezpieczne i dostępne tylko dla tych, którzy ich potrzebują. Ale jednocześnie pozwoli Ci zbudować ujednolicone rozwiązanie magazynowe obejmujące wszystkie dane korporacyjne.
Innym przypadkiem może być sytuacja, w której celem jest zbudowanie platformy hurtowni danych z rozbudowanym wsparciem samoobsługi. Można to rozumieć jako zestaw przetwarzania, który mogą zbudować poszczególni użytkownicy systemu. Ale jednocześnie nigdy nie są częścią rozwiązania wspólnej platformy. Oznacza to, że takie usługi pozostaną dostępne tylko dla twórcy lub grupy osób zdefiniowanej przez twórcę. Nie wpłyną one w żaden sposób na pozostałych użytkowników.
Sprawdź nasze porównanie między Datalake i Datawarehouse.
Lakehouse przez Databricks na AWS
 Źródło: databricks.com
Źródło: databricks.com
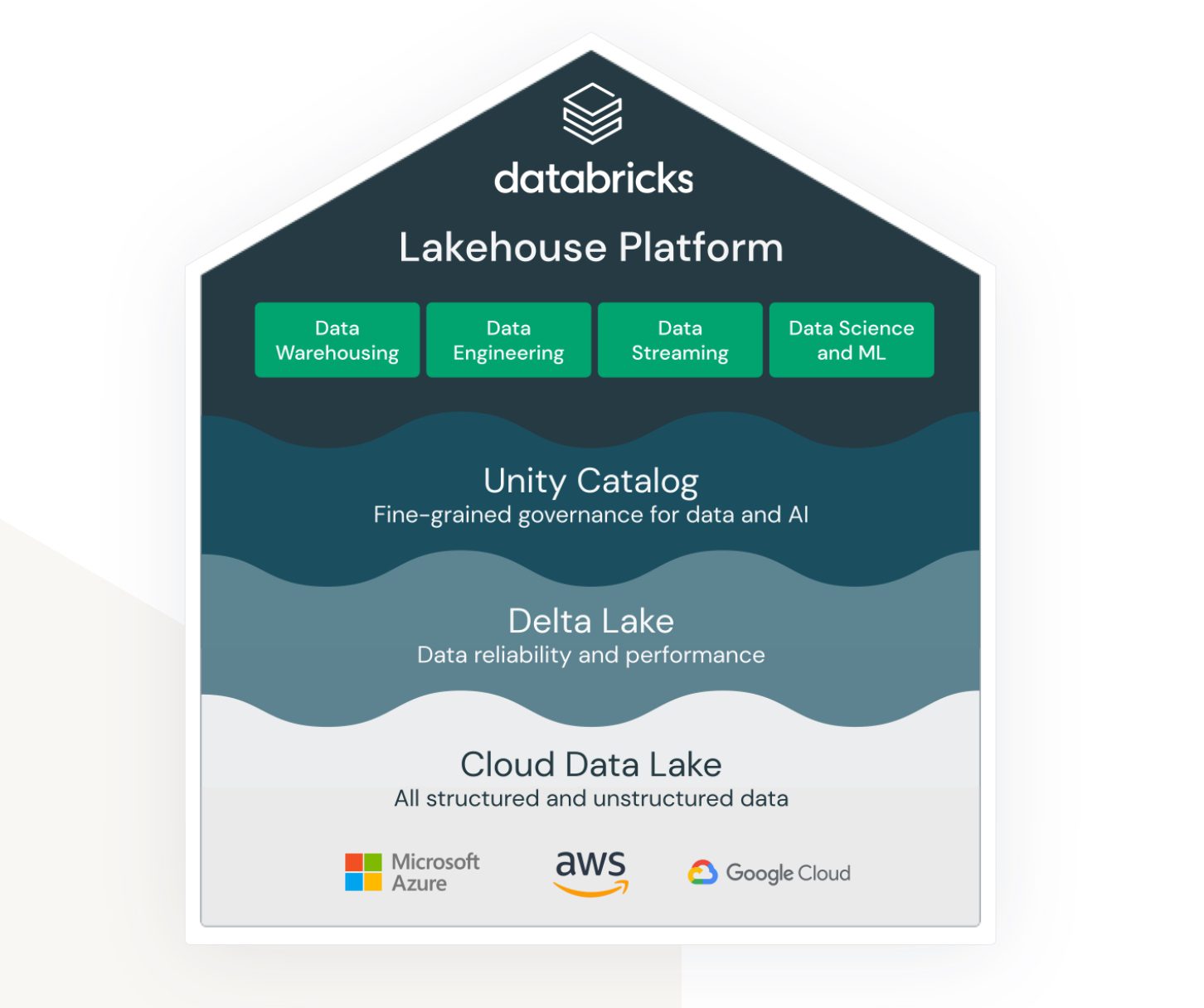
Lakehouse to termin, który jest naprawdę powiązany z usługą datakostki. Nawet jeśli nie jest to natywna usługa AWS, bardzo dobrze żyje i działa w ekosystemie AWS oraz zapewnia różne opcje łączenia i integracji z innymi usługami AWS.
Datakostki mają na celu połączenie ze sobą (wcześniej) bardzo różnych obszarów:
- Rozwiązanie do przechowywania danych typu data lake danych nieustrukturyzowanych, częściowo ustrukturyzowanych i ustrukturyzowanych.
- Rozwiązanie dla ustrukturyzowanych hurtowni danych i szybko dostępnych danych zapytań (zwanych także Delta Lake).
- Rozwiązanie wspierające analitykę i przetwarzanie oparte na uczeniu maszynowym w jeziorze danych.
- Zarządzanie danymi we wszystkich powyższych obszarach ze scentralizowaną administracją i gotowymi narzędziami wspierającymi produktywność różnych typów programistów i użytkowników.
Jest to wspólna platforma, z której mogą jednocześnie korzystać inżynierowie danych, programiści SQL i naukowcy zajmujący się uczeniem maszynowym. Każda z grup dysponuje także zestawem narzędzi, za pomocą których może realizować swoje zadania.
Dlatego Databricks mają na celu rozwiązanie typu „jack-of-all”, próbując połączyć zalety jeziora danych i hurtowni danych w jednym rozwiązaniu. Ponadto zapewnia narzędzia do testowania i uruchamiania modeli uczenia maszynowego bezpośrednio na już utworzonych magazynach danych.

Plusy i minusy
Korzyści do rozważenia:
- Datakostki to wysoce skalowalna platforma danych. Skaluje się w zależności od wielkości obciążenia i robi to nawet automatycznie.
- Jest to środowisko współpracy dla analityków danych, inżynierów danych i analityków biznesowych. Możliwość robienia tego wszystkiego w tej samej przestrzeni i razem to wielka korzyść. Nie tylko z perspektywy organizacyjnej, ale także pomaga zaoszczędzić kolejny koszt, który w przeciwnym razie byłby potrzebny w przypadku oddzielnych środowisk.
- AWS Databricks bezproblemowo integruje się z innymi usługami AWS, takimi jak Amazon S3, Amazon Redshift i Amazon EMR. Pozwala to użytkownikom na łatwe przenoszenie danych między usługami i korzystanie z pełnego zakresu usług chmurowych AWS.
Wady do rozważenia:
- Kostki danych mogą być skomplikowane w konfigurowaniu i zarządzaniu, szczególnie w przypadku użytkowników, którzy są nowicjuszami w przetwarzaniu dużych zbiorów danych. Wymaga to znacznego poziomu wiedzy technicznej, aby w pełni wykorzystać platformę.
- Chociaż Datakostki są opłacalne pod względem modelu cenowego „pay-as-you-go”, nadal mogą być drogie w przypadku projektów przetwarzania danych na dużą skalę. Koszty korzystania z platformy mogą szybko się sumować, zwłaszcza jeśli użytkownicy muszą zwiększyć swoje zasoby.
- Datakostki zapewniają szereg gotowych narzędzi i szablonów, ale może to również stanowić ograniczenie dla użytkowników, którzy potrzebują więcej opcji dostosowywania. Platforma może nie być odpowiednia dla użytkowników, którzy wymagają większej elastyczności i kontroli nad przepływami pracy związanymi z przetwarzaniem dużych zbiorów danych.
Cel i rzeczywisty przypadek użycia
AWS Databricks najlepiej nadaje się dla dużych korporacji z bardzo dużą ilością danych. W tym przypadku może pokryć wymóg ładowania i kontekstualizacji różnych źródeł danych z różnych systemów zewnętrznych.
Często wymogiem jest dostarczanie danych w czasie rzeczywistym. Oznacza to, że od momentu pojawienia się danych w systemie źródłowym procesy powinny natychmiast pobierać oraz przetwarzać i przechowywać dane w datakostkach natychmiast lub z minimalnym opóźnieniem. Jeśli opóźnienie przekracza minutę, uważa się, że przetwarzanie odbywa się w czasie zbliżonym do rzeczywistego. W każdym razie oba scenariusze są często osiągalne dzięki platformie Databricks. Wynika to głównie z dużej liczby adapterów i interfejsów czasu rzeczywistego łączących się z różnymi innymi natywnymi usługami AWS.
Databricks łatwo integruje się również z systemami Informatica ETL. Ilekroć system organizacji już intensywnie korzysta z ekosystemu Informatica, Databricks wygląda na dobry, kompatybilny dodatek do platformy.
Ostatnie słowa
Ponieważ ilość danych rośnie wykładniczo, dobrze jest wiedzieć, że istnieją rozwiązania, które skutecznie sobie z tym poradzą. To, co kiedyś było koszmarem w administrowaniu i utrzymaniu, teraz wymaga bardzo niewielkiej pracy administracyjnej. Zespół może skupić się na tworzeniu wartości z danych.
W zależności od potrzeb wystarczy wybrać serwis, który sobie z tym poradzi. Podczas gdy AWS Databricks jest czymś, czego prawdopodobnie będziesz musiał się trzymać po podjęciu decyzji, inne alternatywy są dość bardziej elastyczne, nawet jeśli mają mniej możliwości, zwłaszcza ich tryby bezserwerowe. Późniejsza migracja do innego rozwiązania jest dość łatwa.