
Macierz pomyłek to narzędzie do oceny wydajności typu klasyfikacji nadzorowanych algorytmów uczenia maszynowego.
Spis treści:
Co to jest macierz pomyłek?
My, ludzie, postrzegamy rzeczy inaczej – nawet prawdę i kłamstwa. To, co może wydawać mi się linią o długości 10 cm, może wydawać się tobie 9 cm. Ale rzeczywista wartość może wynosić 9, 10 lub coś innego. Domyślamy się, że jest to przewidywana wartość!
Jak myśli ludzki mózg
Podobnie jak nasz mózg stosuje własną logikę, aby coś przewidzieć, maszyny stosują różne algorytmy (zwane algorytmami uczenia maszynowego), aby uzyskać przewidywaną wartość pytania. Ponownie te wartości mogą być takie same lub różne od wartości rzeczywistej.
W konkurencyjnym świecie chcielibyśmy wiedzieć, czy nasze przewidywania są słuszne, czy nie, aby zrozumieć nasze wyniki. W ten sam sposób możemy określić wydajność algorytmu uczenia maszynowego na podstawie liczby prawidłowo wykonanych predykcji.
Czym więc jest algorytm uczenia maszynowego?
Maszyny próbują uzyskać określone odpowiedzi na problem, stosując określoną logikę lub zestaw instrukcji, zwanych algorytmami uczenia maszynowego. Algorytmy uczenia maszynowego są trzech typów – nadzorowane, nienadzorowane lub wzmacniające.
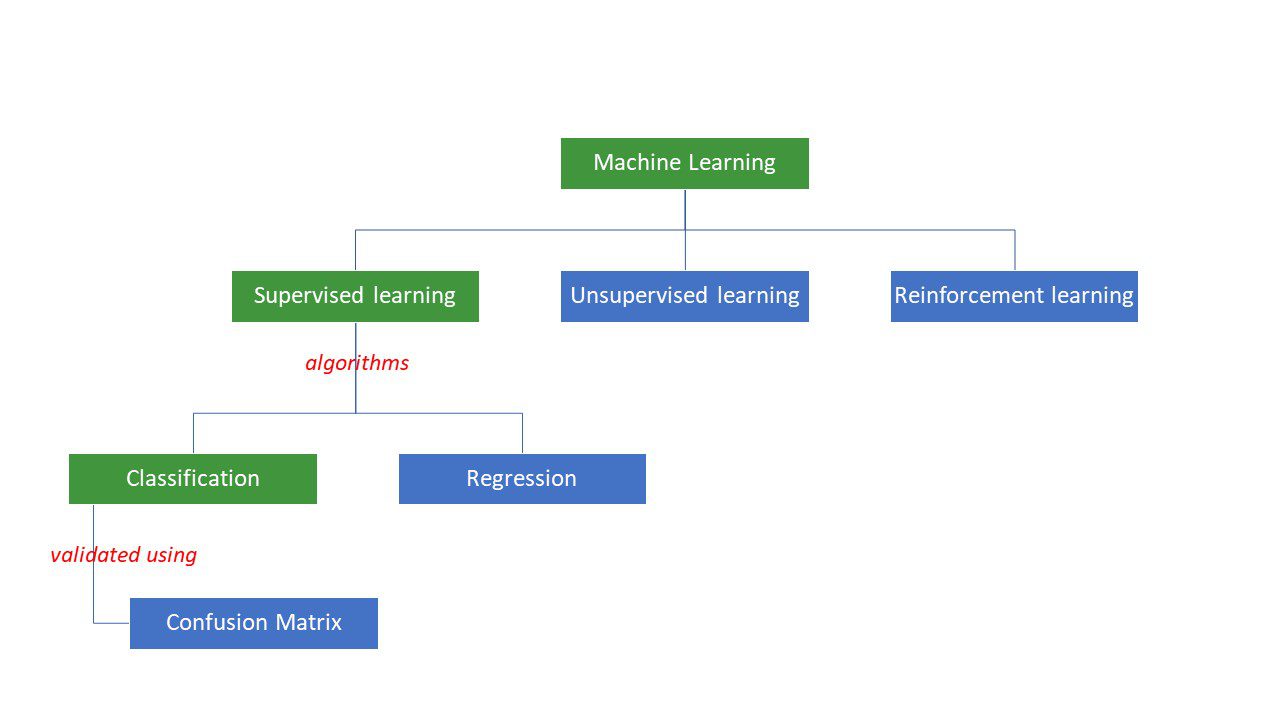 Typy algorytmów uczenia maszynowego
Typy algorytmów uczenia maszynowego
Nadzorowane są najprostsze typy algorytmów, gdzie już znamy odpowiedź i trenujemy maszyny, aby do niej dotarły, trenując algorytm z dużą ilością danych – tak samo jak dziecko rozróżniałoby osoby w różnych grupach wiekowych przyglądając się ich rysom w kółko.
Nadzorowane algorytmy ML są dwojakiego rodzaju – klasyfikacja i regresja.
Algorytmy klasyfikacji klasyfikują lub sortują dane na podstawie pewnego zestawu kryteriów. Na przykład, jeśli chcesz, aby Twój algorytm grupował klientów na podstawie ich preferencji żywieniowych – tych, którzy lubią pizzę i tych, którzy nie lubią pizzy, użyjesz algorytmu klasyfikacji, takiego jak drzewo decyzyjne, losowy las, naiwny Bayes lub SVM (wsparcie Maszyna wektorowa).
Który z tych algorytmów wykonałby najlepsze zadanie? Dlaczego miałbyś wybrać jeden algorytm a nie drugi?
Wprowadź macierz zamieszania….
Macierz pomyłek to macierz lub tabela, która zawiera informacje o dokładności algorytmu klasyfikacji w klasyfikacji zbioru danych. Cóż, nazwa nie ma mylić ludzi, ale zbyt wiele błędnych przewidywań prawdopodobnie oznacza, że algorytm się pomylił😉!
Tak więc macierz pomyłek jest metodą oceny wydajności algorytmu klasyfikacji.
Jak?
Załóżmy, że zastosowałeś różne algorytmy do naszego wcześniej wspomnianego problemu binarnego: klasyfikuj (segreguj) ludzi na podstawie tego, czy lubią pizzę, czy nie. Aby ocenić algorytm, którego wartości są najbliższe prawidłowej odpowiedzi, użyjesz macierzy pomyłek. W przypadku problemu klasyfikacji binarnej (lubię/nie lubię, prawda/fałsz, 1/0) macierz pomyłek podaje cztery wartości siatki, a mianowicie:
- Prawdziwie pozytywna (TP)
- Prawdziwie negatywna (TN)
- Fałszywy wynik pozytywny (FP)
- Fałszywy negatywny (FN)
Jakie są cztery siatki w macierzy pomyłek?
Cztery wartości wyznaczone za pomocą macierzy pomyłek tworzą siatki macierzy.
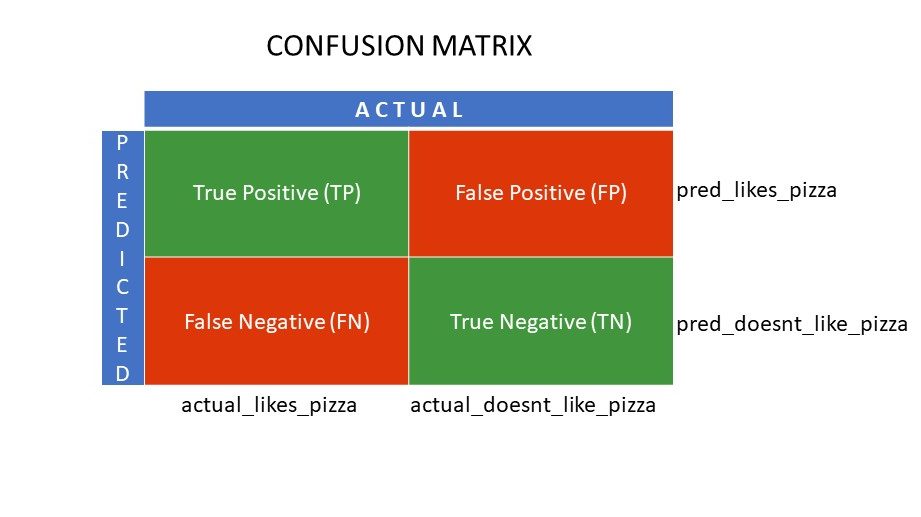 Siatki macierzy pomyłek
Siatki macierzy pomyłek
True Positive (TP) i True Negative (TN) to wartości poprawnie przewidywane przez algorytm klasyfikacji,
- TP reprezentuje tych, którzy lubią pizzę, a model poprawnie je sklasyfikował,
- TN reprezentuje tych, którzy nie lubią pizzy, a model poprawnie je sklasyfikował,
Fałszywie pozytywne (FP) i Fałszywie negatywne (FN) to wartości, które są błędnie przewidywane przez klasyfikator,
- FP reprezentuje tych, którzy nie lubią pizzy (negatywne), ale klasyfikator przewidział, że lubią pizzę (błędnie pozytywne). FP jest również nazywany błędem typu I.
- FN reprezentuje tych, którzy lubią pizzę (pozytywne), ale klasyfikator przewidział, że nie (błędnie negatywne). FN jest również nazywany błędem typu II.
Aby lepiej zrozumieć tę koncepcję, weźmy scenariusz z życia wzięty.
Załóżmy, że masz zestaw danych 400 osób, które przeszły test Covida. Teraz masz wyniki różnych algorytmów, które określiły liczbę osób z dodatnim i ujemnym wynikiem Covid.
Oto dwie macierze pomyłek dla porównania:
Patrząc na oba, możesz pokusić się o stwierdzenie, że pierwszy algorytm jest dokładniejszy. Aby jednak uzyskać konkretny wynik, potrzebujemy pewnych metryk, które mogą mierzyć dokładność, precyzję i wiele innych wartości, które dowodzą, który algorytm jest lepszy.
Metryki wykorzystujące macierz pomyłek i ich znaczenie
Główne wskaźniki, które pomagają nam zdecydować, czy klasyfikator wykonał właściwe prognozy, to:
#1. Przywołanie/czułość
Recall or Sensitivity lub True Positive Rate (TPR) lub Prawdopodobieństwo wykrycia to stosunek poprawnych pozytywnych prognoz (TP) do wszystkich pozytywnych wyników (tj. TP i FN).
R = TP/(TP + FN)
Przypomnienie jest miarą prawidłowych wyników dodatnich zwróconych z liczby poprawnych wyników dodatnich, które można było uzyskać. Wyższa wartość Recall oznacza mniej wyników fałszywie negatywnych, co jest dobre dla algorytmu. Użyj Przypomnij, gdy ważne jest, aby wiedzieć, że wyniki fałszywie negatywne. Na przykład, jeśli dana osoba ma wiele blokad w sercu, a model pokazuje, że jest całkowicie w porządku, może to okazać się śmiertelne.
#2. Precyzja
Precyzja jest miarą prawidłowych wyników dodatnich spośród wszystkich przewidywanych wyników dodatnich, w tym zarówno prawdziwych, jak i fałszywie dodatnich.
Pr = TP/(TP + FP)
Precyzja jest bardzo ważna, gdy fałszywe alarmy są zbyt ważne, aby je zignorować. Na przykład, jeśli dana osoba nie ma cukrzycy, ale model to pokazuje, a lekarz przepisuje określone leki. Może to prowadzić do poważnych skutków ubocznych.
#3. Specyficzność
Swoistość lub True Negative Rate (TNR) to prawidłowe wyniki ujemne spośród wszystkich wyników, które mogły być ujemne.
S = TN/(TN + FP)
Jest to miara tego, jak dobrze Twój klasyfikator identyfikuje wartości ujemne.
#4. Precyzja
Dokładność to liczba poprawnych prognoz z całkowitej liczby prognoz. Tak więc, jeśli znalazłeś poprawnie 20 dodatnich i 10 ujemnych wartości z próbki 50, dokładność twojego modelu wyniesie 30/50.
Dokładność A = (TP + TN)/(TP + TN + FP + FN)
#5. Rozpowszechnienie
Częstość występowania jest miarą liczby pozytywnych wyników uzyskanych spośród wszystkich wyników.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Punktacja F
Czasami trudno jest porównać dwa klasyfikatory (modele) używając tylko Precyzji i Recall, które są po prostu średnimi arytmetycznymi kombinacji czterech siatek. W takich przypadkach możemy użyć F Score lub F1 Score, która jest średnią harmoniczną – która jest dokładniejsza, ponieważ nie różni się zbytnio dla ekstremalnie wysokich wartości. Wyższy wynik F (max 1) wskazuje na lepszy model.
Wynik F = 2*Precyzja*Przypomnienie/ (Przypomnienie + Precyzja)
Kiedy ważne jest, aby zająć się zarówno fałszywie pozytywnymi, jak i fałszywie negatywnymi, wynik F1 jest dobrą metryką. Na przykład ci, którzy nie są nosicielami wirusa (ale algorytm tak wykazał) nie muszą być niepotrzebnie izolowane. W ten sam sposób należy odizolować te, które są dodatnie wobec Covida (ale algorytm powiedział, że tak nie jest).
7. krzywe ROC
Parametry takie jak Dokładność i Precyzja są dobrymi metrykami, jeśli dane są zrównoważone. W przypadku niezrównoważonego zbioru danych wysoka dokładność niekoniecznie oznacza, że klasyfikator jest wydajny. Na przykład 90 na 100 uczniów w grupie zna język hiszpański. Teraz, nawet jeśli twój algorytm mówi, że wszyscy 100 znają hiszpański, jego dokładność wyniesie 90%, co może dać błędny obraz modelu. W przypadku niezrównoważonych zestawów danych metryki, takie jak ROC, są bardziej skutecznymi wyznacznikami.
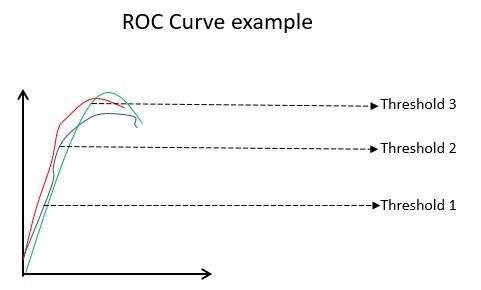 Przykład krzywej ROC
Przykład krzywej ROC
Krzywa ROC (Receiver Operating Characteristic) przedstawia wizualnie wydajność binarnego modelu klasyfikacji przy różnych progach klasyfikacji. Jest to wykres TPR (True Positive Rate) względem FPR (False Positive Rate), który jest obliczany jako (1-swoistość) przy różnych wartościach progowych. Najdokładniejszą wartością progową jest wartość najbardziej zbliżona do 45 stopni (lewy górny róg) na wykresie. Jeśli próg będzie zbyt wysoki, nie będziemy mieli wielu fałszywych trafień, ale otrzymamy więcej fałszywych trafień i odwrotnie.
Ogólnie rzecz biorąc, gdy wykreśla się krzywą ROC dla różnych modeli, ten, który ma największy obszar pod krzywą (AUC) jest uważany za lepszy model.
Obliczmy wszystkie wartości metryk dla naszych macierzy pomyłek Klasyfikatora I i Klasyfikatora II:
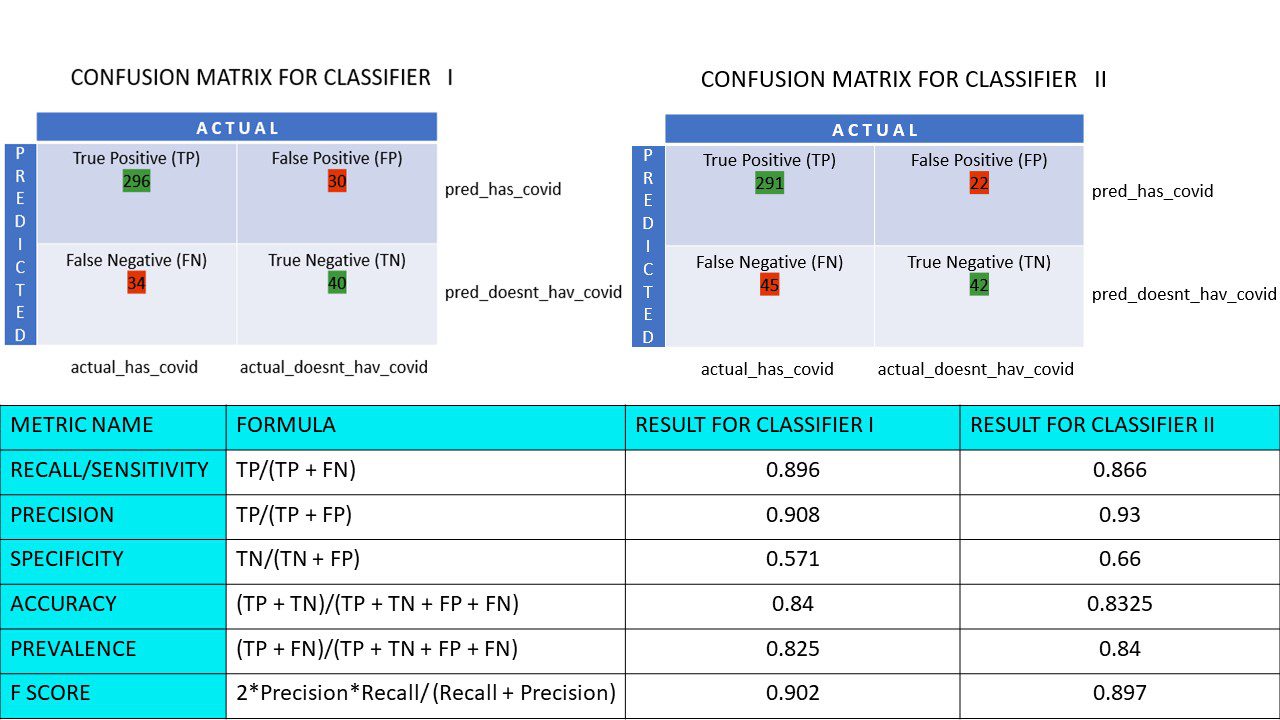 Porównanie metryczne dla klasyfikatorów 1 i 2 ankiety pizzy
Porównanie metryczne dla klasyfikatorów 1 i 2 ankiety pizzy
Widzimy, że precyzja jest większa w klasyfikatorze II, podczas gdy dokładność jest nieco wyższa w klasyfikatorze I. W zależności od problemu decydenci mogą wybrać klasyfikator I lub II.
N x N macierz pomyłek
Do tej pory widzieliśmy macierz pomyłek dla klasyfikatorów binarnych. A gdyby było więcej kategorii niż tylko tak/nie lub lubię/nie lubię. Na przykład, jeśli twój algorytm miał sortować obrazy w kolorach czerwonym, zielonym i niebieskim. Ten rodzaj klasyfikacji nazywa się klasyfikacją wieloklasową. Liczba zmiennych wyjściowych również decyduje o wielkości macierzy. Zatem w tym przypadku macierz pomyłek będzie wynosić 3×3.
 Macierz pomyłek dla klasyfikatora wieloklasowego
Macierz pomyłek dla klasyfikatora wieloklasowego
Streszczenie
Matryca pomyłek to świetny system oceny, ponieważ dostarcza szczegółowych informacji na temat działania algorytmu klasyfikacji. Sprawdza się dobrze zarówno w klasyfikatorach binarnych, jak i wieloklasowych, gdzie należy zadbać o więcej niż 2 parametry. Łatwo jest zwizualizować macierz pomyłek, a wszystkie inne metryki wydajności, takie jak wynik F, precyzja, ROC i dokładność, możemy wygenerować za pomocą macierzy pomyłek.
Możesz również przyjrzeć się, jak wybrać algorytmy ML dla problemów regresji.