
Amazon Glue zyskuje na popularności, ponieważ wiele firm zaczęło korzystać z usług integracji danych zarządzanych.
ETL to proces, który przenosi dane ze źródłowej bazy danych do hurtowni danych. ETL jest złożony i trudny do wdrożenia dla wszystkich danych przedsiębiorstwa ze względu na swoją złożoność. Amazon wprowadził klej AWS, aby rozwiązać ten problem.
Deweloperzy ETL i inżynierowie danych używają Glue do tworzenia, monitorowania i uruchamiania przepływów pracy ETL.
Spis treści:
Co to jest klej AWS?
AWS Glue, bezserwerowa usługa integracji danych, ułatwia znajdowanie, przygotowywanie, przenoszenie i integrowanie danych z wielu źródeł. Jest to przydatne w przypadku uczenia maszynowego (ML) i analiz.
To radykalnie skraca czas potrzebny na przygotowanie danych do analizy. Automatycznie wyszukuje i wyświetla dane, generuje kod Scala lub Python w celu przesłania danych ze źródła oraz ładuje i przekształca zadanie zgodnie z określonymi w czasie zdarzeniami.
Pozwala to na elastyczne planowanie i tworzy środowisko Apache Spark, które można skalować w celu ukierunkowanego ładowania danych. Ponadto AWS Glue zapewnia kompleksowe monitorowanie i zmianę strumienia danych. AWS Glue to usługa bezserwerowa, która upraszcza skomplikowane operacje tworzenia aplikacji.
Pozwala na szybką integrację wielu ważnych danych. Ponadto szybko się psuje i autoryzuje dane.
Do czego służy klej AWS?
Ważne jest, aby znać najlepsze miejsca, w których można użyć Amazon Glue. To tylko kilka przykładów zastosowań kleju AWS, które powinieneś rozważyć.
- Glue to narzędzie, które umożliwia uruchamianie zapytań bezserwerowych na jeziorach danych Amazon S3. Amazon Glue to świetne narzędzie na początek. Dzięki temu wszystkie Twoje dane są dostępne w jednym interfejsie, co pozwala na ich analizę bez konieczności ich przenoszenia.
- Amazon Glue może być użyty do zrozumienia Twoich zasobów danych. Amazon Glue ułatwia przeszukiwanie różnych zestawów danych AWS za pomocą Katalogu danych. Możesz także zapisywać dane w wielu usługach AWS za pomocą wykazu danych, zachowując spójny widok.
- Klej może być pomocny przy tworzeniu przepływów pracy ETL opartych na zdarzeniach. Możesz wykonywać swoje operacje ETL z Amazon S3, wywołując zadania Glue ETL za pośrednictwem usługi AWS Lambda.
- AWS Glue może być również używany do czyszczenia, weryfikacji, formatowania i organizowania danych do przechowywania w jeziorze danych lub magazynie.
Jakie są składniki kleju AWS?
Poniżej znajdują się główne składniki AWS Glue:
- Katalog danych: ten katalog danych zawiera metadane i strukturę danych.
- Baza danych: jest to klucz do uzyskania dostępu i tworzenia bazy danych dla źródeł i celów.
- Tabela: Utwórz jedną lub kilka tabel w bazie danych, z których może korzystać zarówno miejsce docelowe, jak i źródło.
- Przeszukiwacz i klasyfikator: Przeszukiwacz pobiera dane ze źródła przy użyciu wbudowanych lub niestandardowych klasyfikacji. Tworzy/używa predefiniowanych tabel metadanych w katalogu danych.
- Praca: Jest to zadanie logiki biznesowej służące do wykonania zadania ETL. Ta logika biznesowa jest napisana wewnętrznie przez Apache Spark przy użyciu języków Python i scala.
- Wyzwalacz: Wyzwalacz ETL to urządzenie, które inicjuje wykonanie zadania ETL na żądanie lub w określonym czasie.
- Punkt końcowy do programowania: tworzy środowisko, w którym skrypt zadania ETL jest testowany, opracowywany i debugowany.
Zalety kleju AWS
Są to korzyści płynące z używania go w swoim miejscu pracy lub w organizacji.
- AWS Glue skanuje wszystkie dostępne dane za pomocą robota.
- Ostateczne przetworzone dane mogą być przechowywane w wielu miejscach (Amazon RDS i Amazon Redshift, Amazon S3 itp.
- Jest to usługa oparta na chmurze. Nie ma potrzeby wydawania pieniędzy na infrastrukturę lokalną.
- Ponieważ jest to bezserwerowy ETL, jest to opłacalny wybór.
- To jest szybkie. Natychmiast daje Ci kod ETL Python/Scala.
Najważniejsze cechy kleju AWS?
Amazon Glue ma wszystkie funkcje potrzebne do integracji danych, dzięki czemu możesz uzyskać lepszy wgląd i wykorzystać swoją wiedzę do dokonywania nowych postępów w ciągu kilku minut, a nie miesięcy. Oto niektóre z funkcji, o których powinieneś wiedzieć.
- Interfejs „przeciągnij i upuść”: edytor zadań typu „przeciągnij i upuść” umożliwia tworzenie procesu ETL. AWS Glue natychmiast zbuduje kod potrzebny do wyodrębnienia, konwersji i przesłania danych.
- Automatyczne wykrywanie schematu: Aby utworzyć przeszukiwacze, które łączą się z różnymi źródłami danych, możesz użyć usługi Glue. Organizuje dane i wydobywa odpowiednie informacje. Te dane mogą być następnie wykorzystane do monitorowania procesów ETL przez zadania ETL.
- Planowanie pracy: Klej może być używany na żądanie lub zgodnie z zaplanowanym harmonogramem. Harmonogram może służyć do budowania złożonych potoków ETL, ustanawiając zależności między zadaniami.
- Generowanie kodu: widoki elastyczne klejenia umożliwiają łatwe tworzenie zmaterializowanych widoków, które łączą i replikują dane z różnych źródeł danych bez konieczności pisania jakiegokolwiek zastrzeżonego kodu.
- Wbudowane uczenie maszynowe: Glue ma wbudowaną funkcję uczenia maszynowego o nazwie „Znajdź dopasowania”. Deduplikuje rekordy, które nie są idealnymi kopiami siebie.
- Punkty końcowe programisty: Jeśli chcesz aktywnie rozwijać swój kod ETL, Glue zapewnia punkty końcowe programisty, które umożliwiają modyfikowanie, debugowanie i testowanie tworzonego kodu.
- Glue DataBrew: Jest to narzędzie do przygotowywania danych, z którego mogą korzystać analitycy danych i naukowcy danych, aby pomóc im w czyszczeniu i normalizacji danych. Wykorzystuje aktywny i wizualny interfejs Glue DataBrew.
Jak działa wycena kleju AWS?
AWS Glue pobiera opłatę godzinową, która jest naliczana za sekundę dla robotów indeksujących (wykrywanie danych) i zadań ETL (przetwarzanie i ładowanie danych). Za dostęp i przechowywanie metadanych w Katalogu danych kleju AWS pobierana jest prosta opłata miesięczna.
Amazon Glue zaczyna się od 0,44 USD. Do wyboru są cztery plany:
- Zadania ETL, punkty końcowe programowania i inne zadania ETL są dostępne w cenie 0,44 USD
- Sesje interaktywne Crawlers są dostępne w cenie 0,44 USD
- Zadania DataBrew zaczynają się od 0,48 $
- Miesięczne przechowywanie i żądania do Data Catalog kosztują 1,00 USD
AWS nie oferuje darmowego planu Glue. Każda godzina będzie kosztować 0,44 USD za DPU. Średnio kosztowałoby to 21 USD dziennie. Ceny mogą się różnić w zależności od miejsca zamieszkania.
Kroki, aby skonfigurować AWS Glue
Katalog danych może służyć do szybkiego znajdowania i przeszukiwania wielu zestawów danych AWS bez konieczności przenoszenia danych. Po skatalogowaniu danych są one natychmiast dostępne do zapytania i wyszukiwania za pomocą Amazon Athena i Amazon EMR.
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS i bazy danych na Amazon EC2 – Odkryj swoje dane, przechowuj metadane i korzystaj z Katalogu danych kleju AWS, aby je odkryć
- Katalog danych kleju AWS – Zarządzaj danymi za pomocą katalogu danych działającego jako centralne repozytorium metadanych
- AWS Glue ETL – Odczytuj i zapisuj metadane w swoim katalogu danych
- Amazon Athena i Amazon Redshift, Amazon EMR, Amazon ETL — Pobierz katalog danych dla ETL, analiz i nie tylko.
Jak skonfigurować klej AWS?
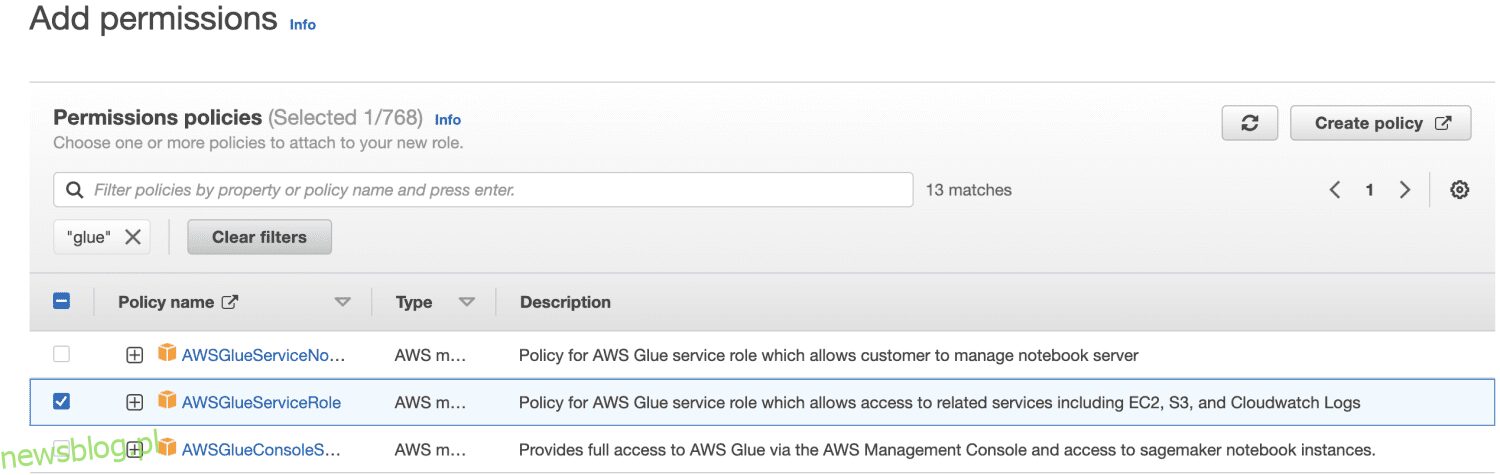
Najpierw zaloguj się do konsoli zarządzania AWS i otwórz konsolę uprawnień. Kliknij Utwórz rolę. Następnie dla typu roli znajdź Klej i wybierz Uprawnienia.
Wybieram AWSGlueServiceRole dla ogólnych uprawnień AWS Glue Studio i AWS Glue oraz zasady zarządzanej przez AWS AmazonS3FullAccess dla dostępu do zasobów Amazon S3.
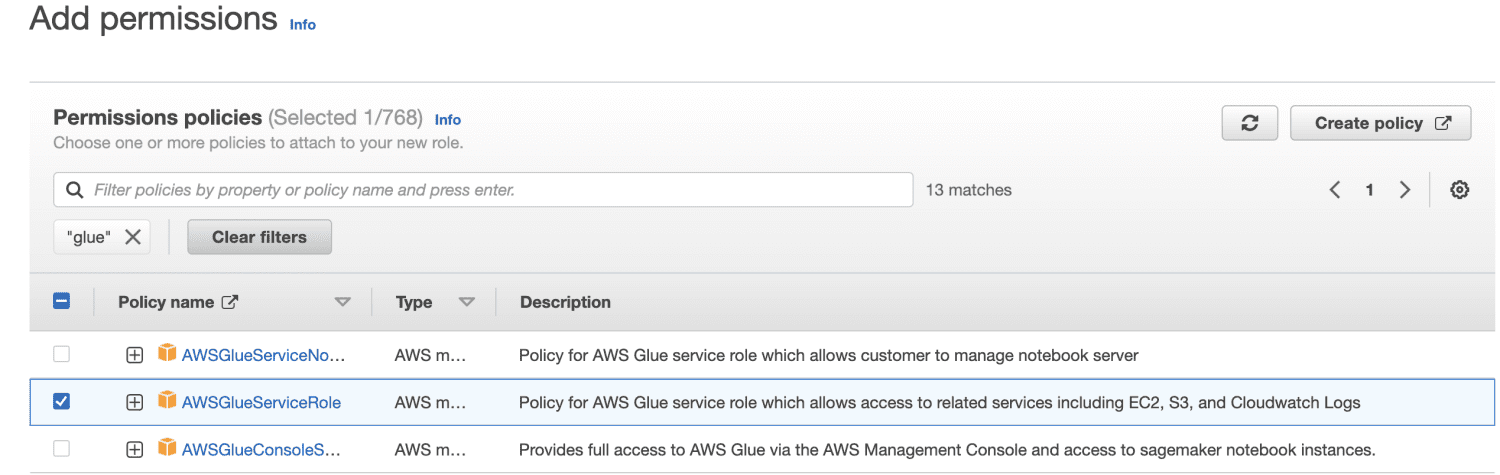
Wpisz nazwę roli.
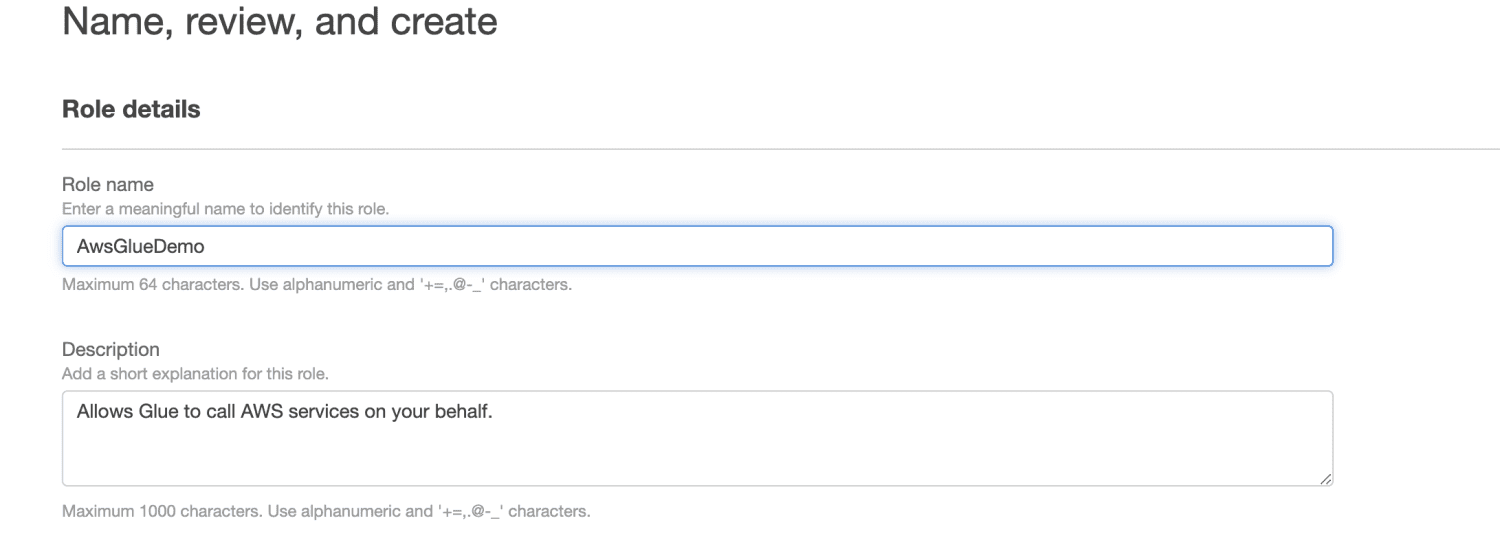
Kliknij Utwórz rolę.
Utwórz zasobnik Amazon S3.
Utwórz folder w zasobniku S3.
Wybierz plik do przesłania.
Na koniec prześlij plik do zasobnika.
Następnie otwórz AWS Glue z konsoli zarządzania AWS i utwórz bazę danych.
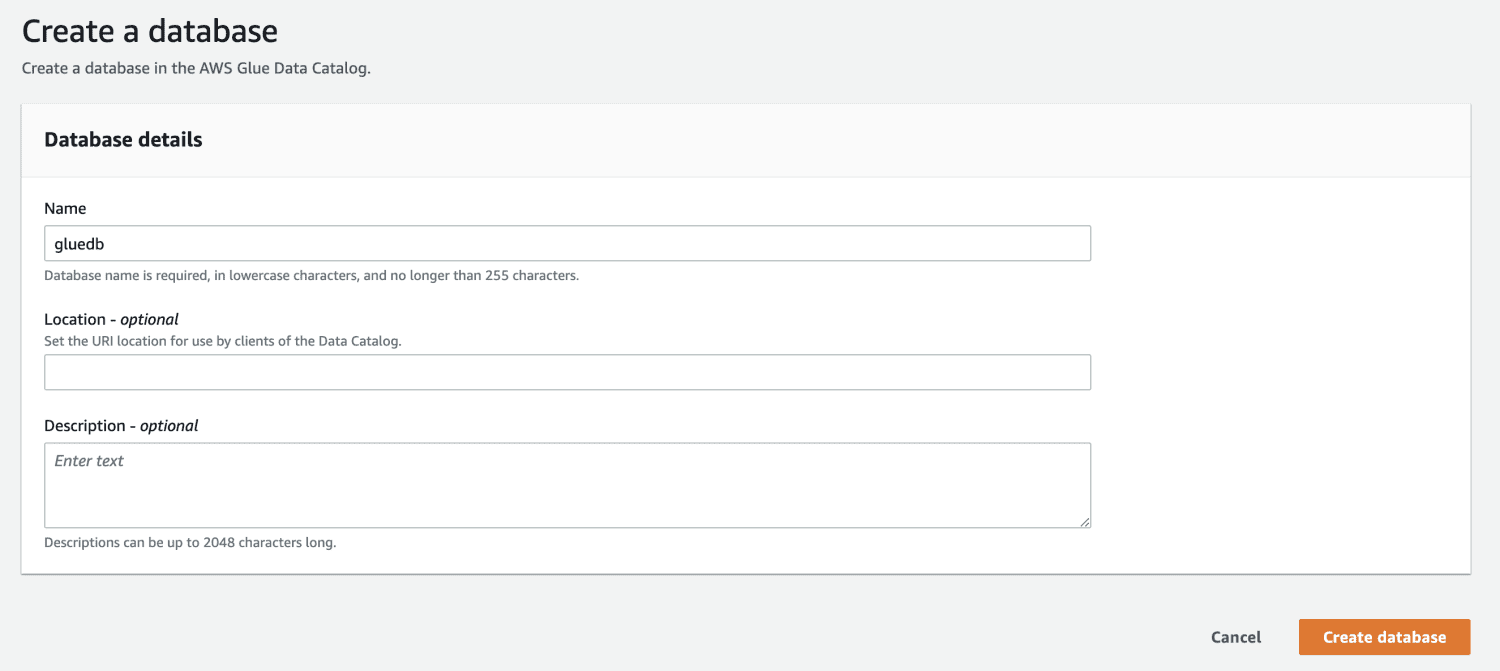
Teraz, gdy masz bazę danych w AWS Glue, utwórz robota indeksującego.
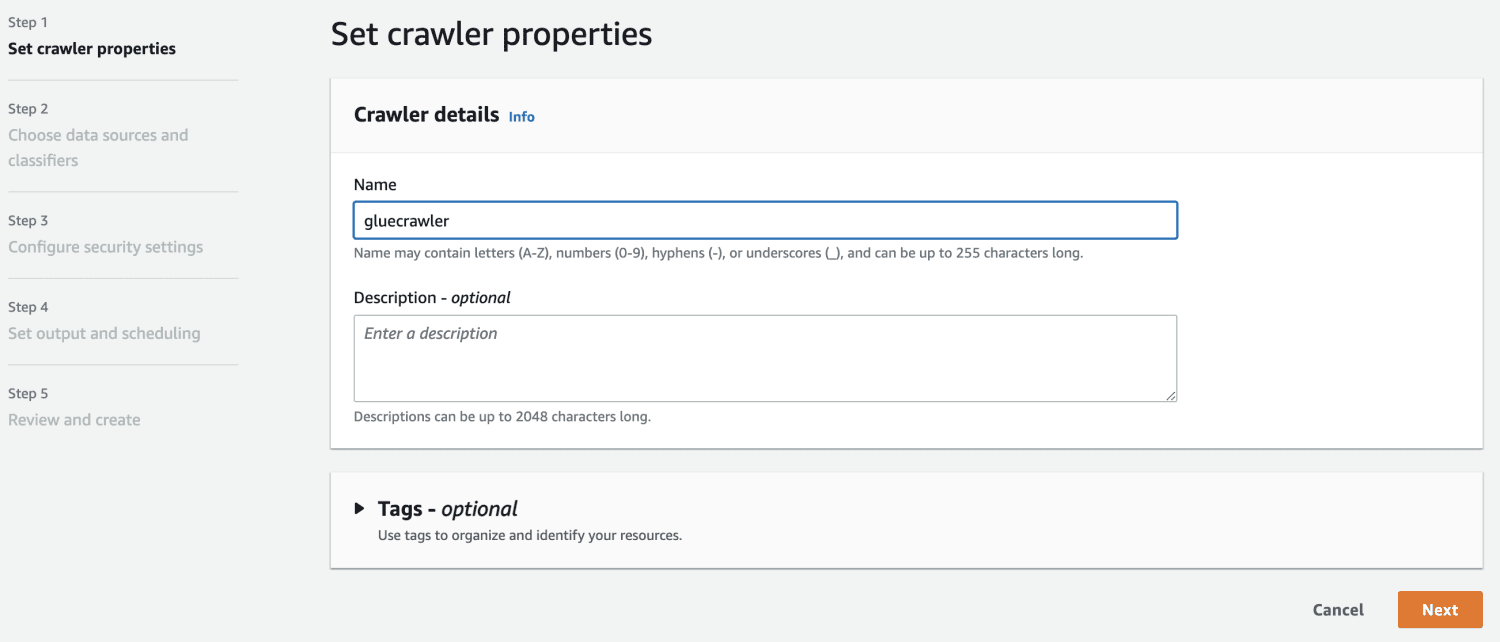
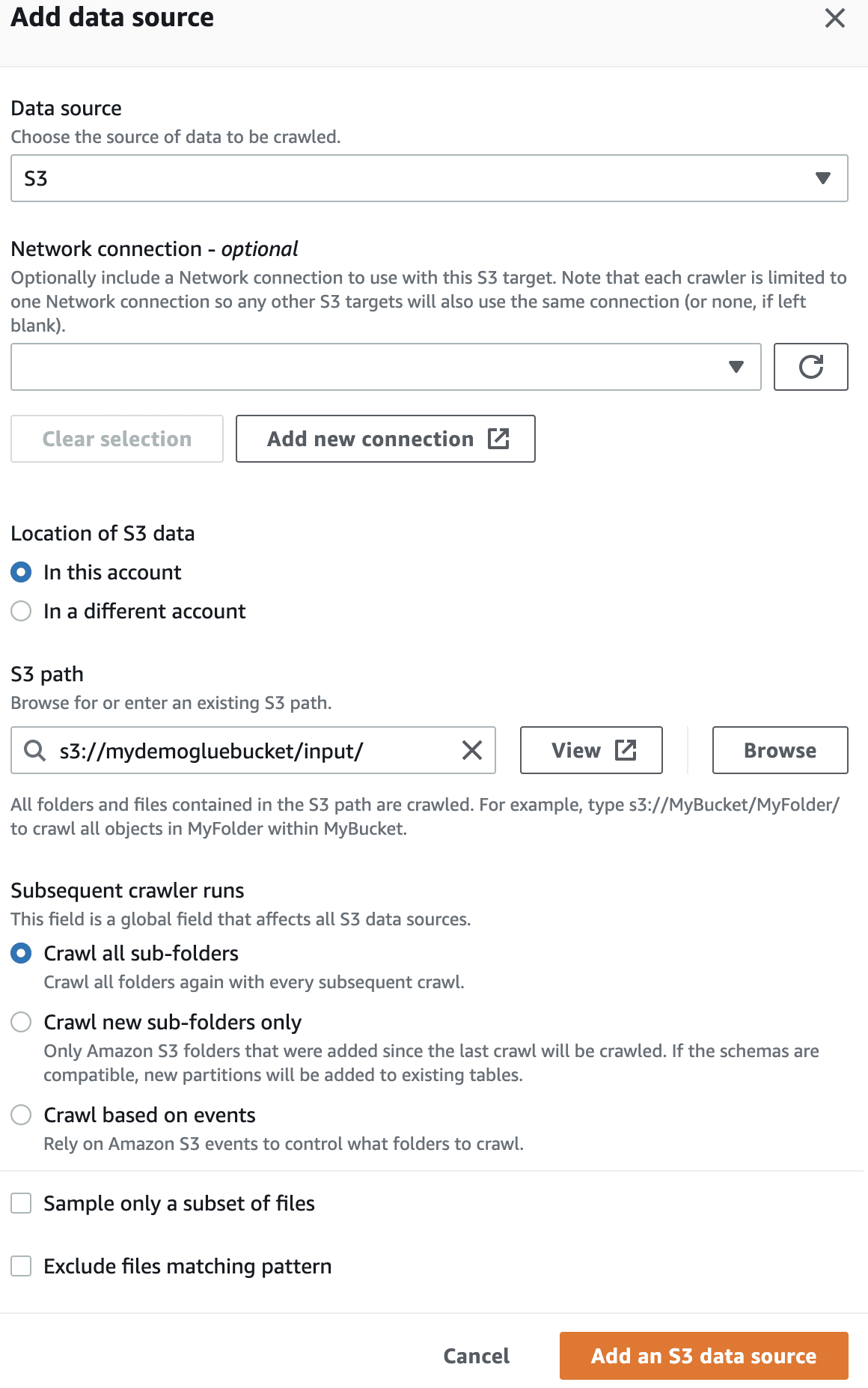
W źródle danych wybierz utworzony zasobnik S3.
Następnie wybierz rolę IaM dla AWS Glue, którą utworzyłeś na początku.
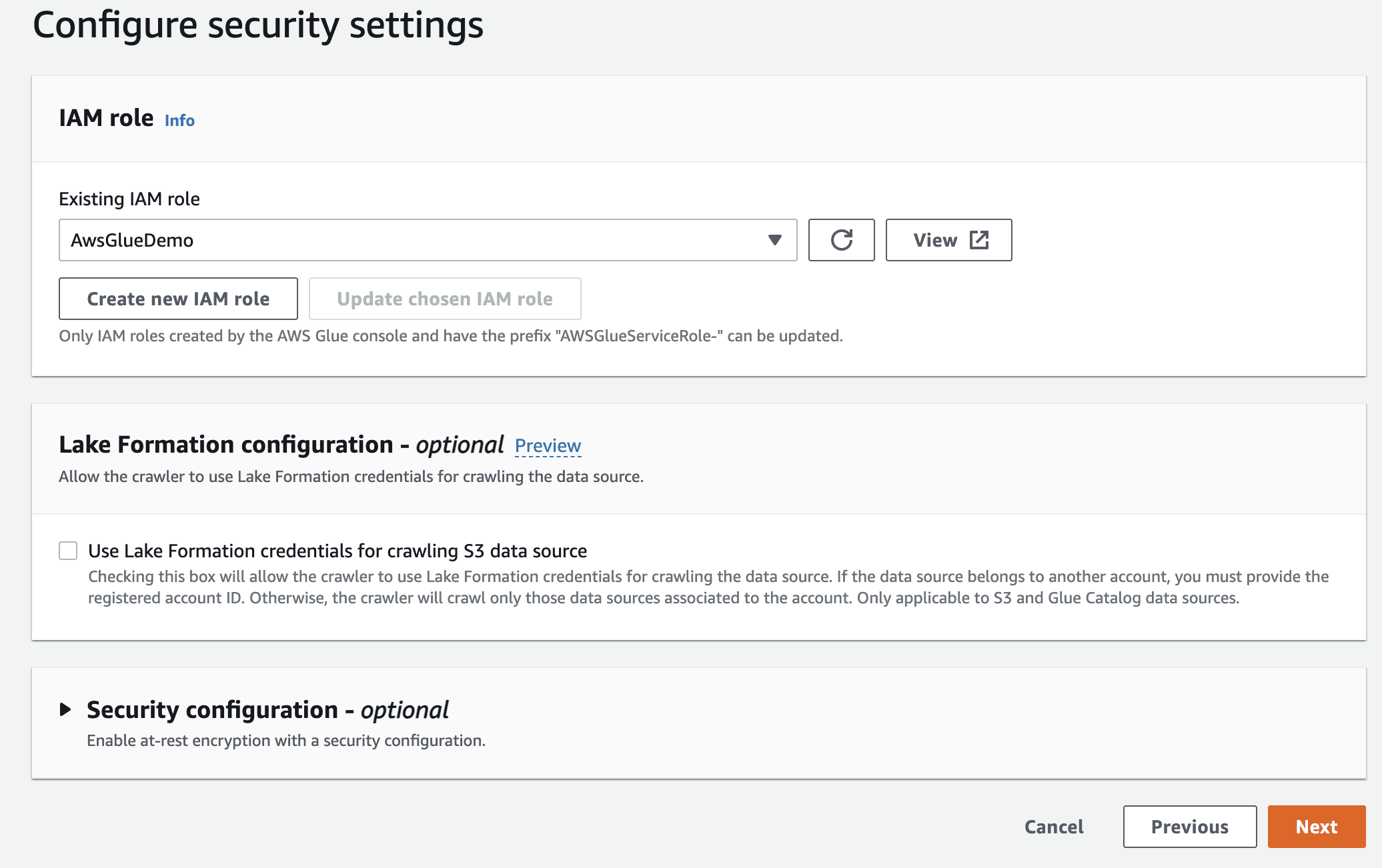
Na koniec w danych wyjściowych wybierz utworzoną bazę klejoną.
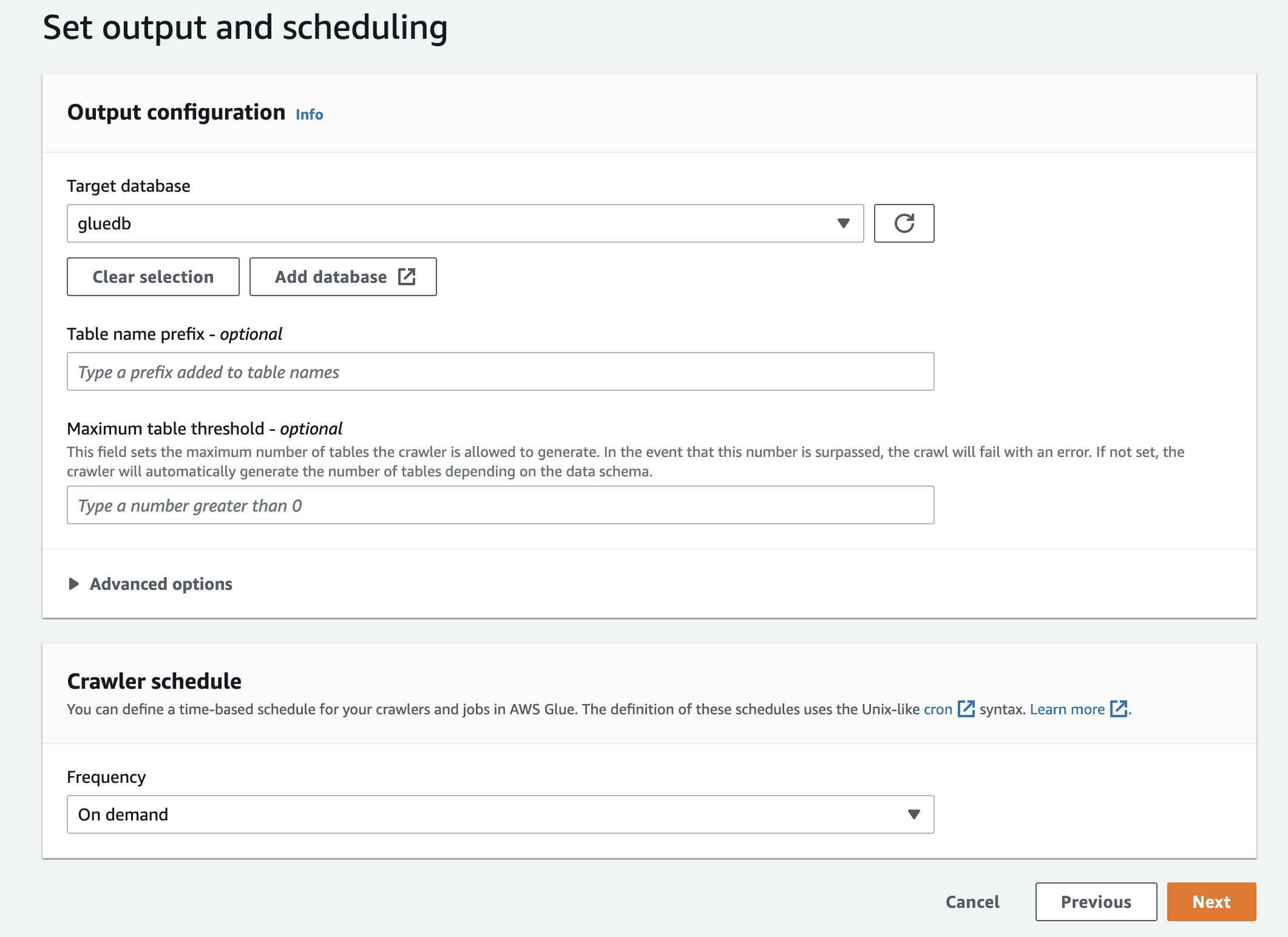
Przejrzyj wszystkie ustawienia i utwórz robota.
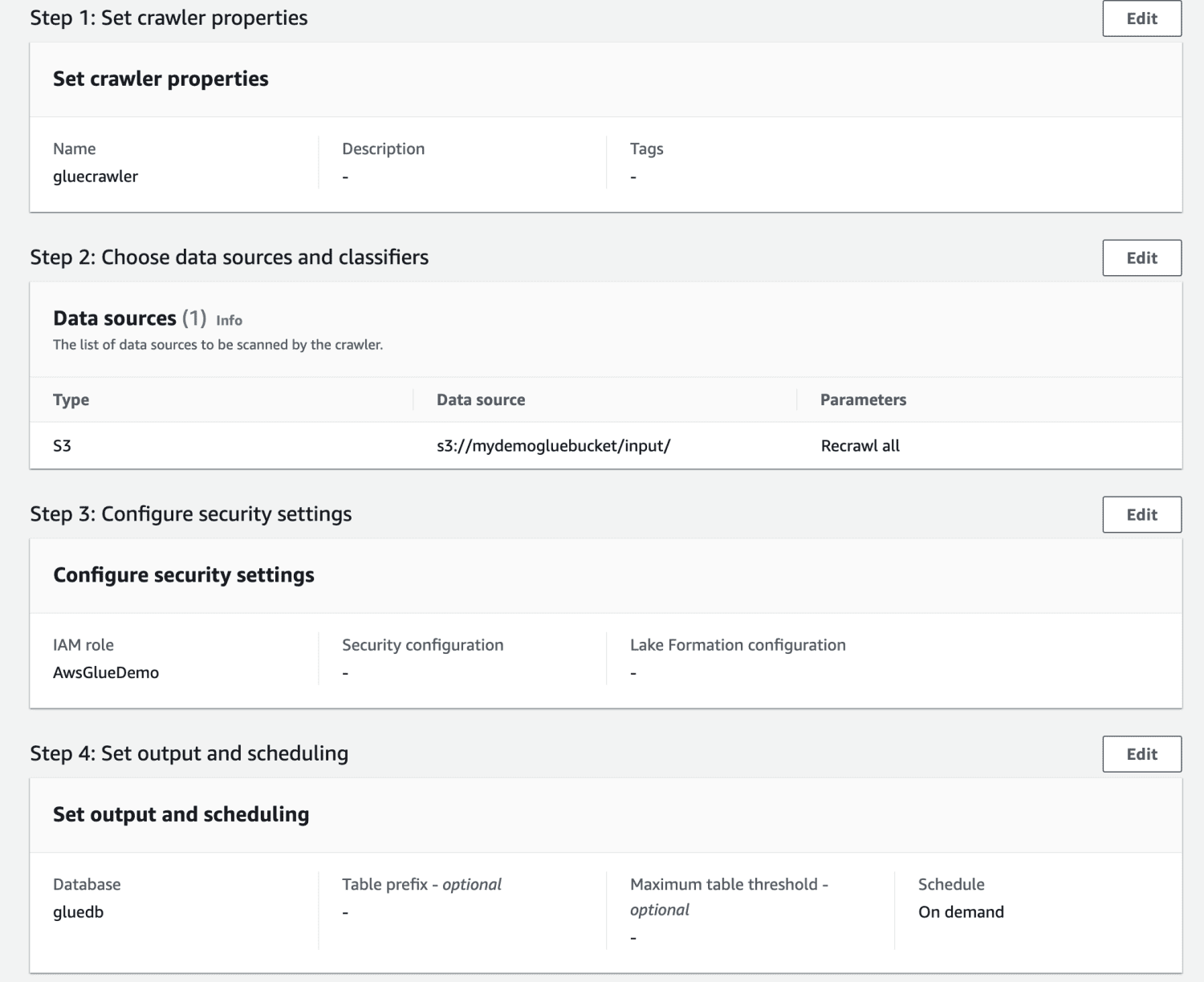
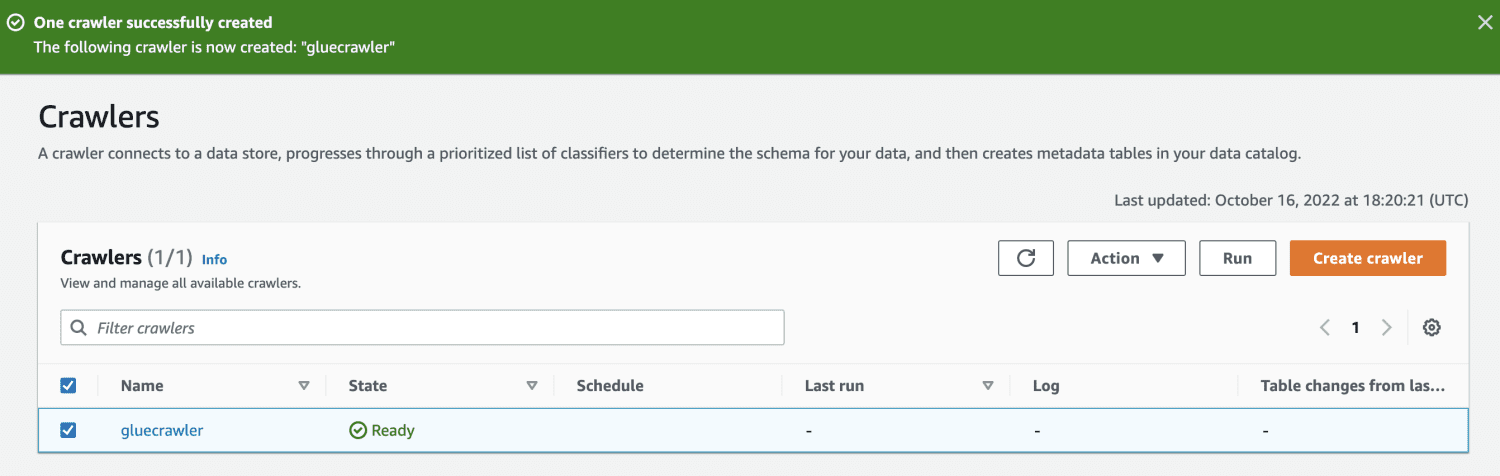
Po utworzeniu robota wybierz go i kliknij Uruchom. Po pewnym czasie otrzymasz status gotowy.
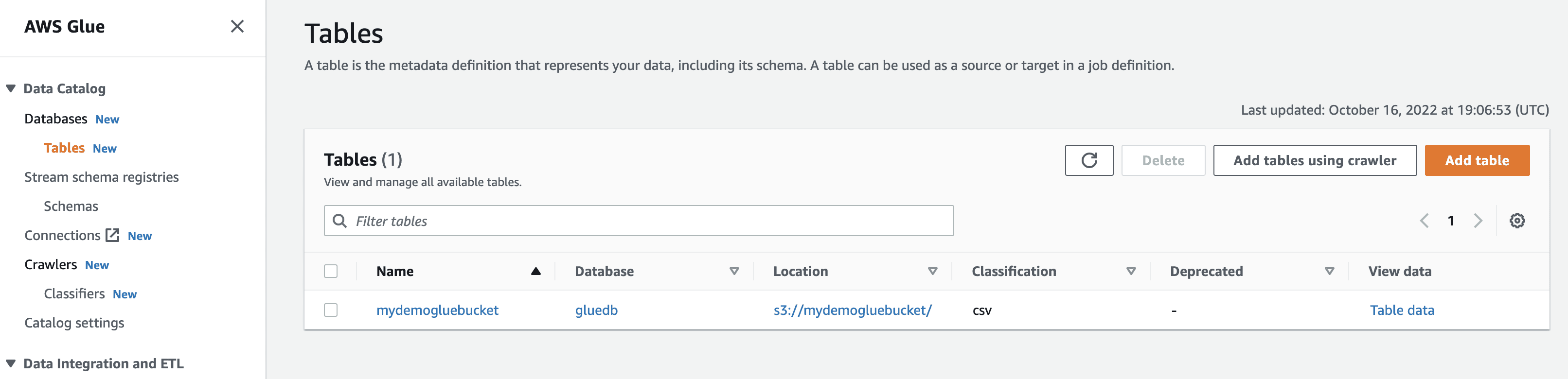
Po uruchomieniu przeszukiwacza baza danych otrzyma tabelę ze wszystkimi danymi z pliku CSV.
Po kliknięciu na wyświetl dane zostaniesz przeniesiony do Amazon Athena (edytor zapytań). Po uruchomieniu zapytania możesz zobaczyć dane tabeli.
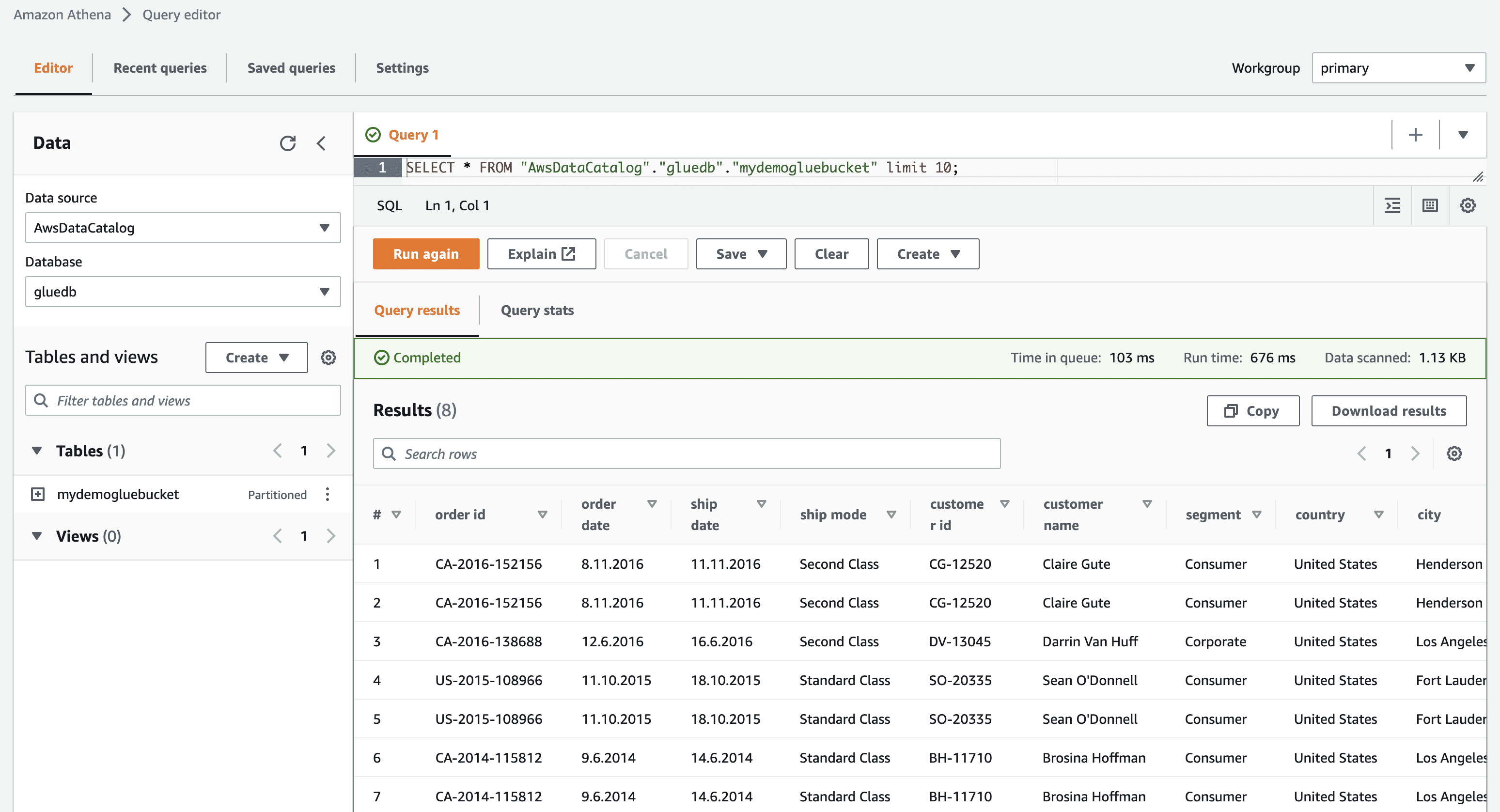
Teraz możesz z powodzeniem używać tego robota AWS Glue w dowolnym zadaniu ETL.
Co to jest AWS Glue Databrew?
AWS Glue DataBrew umożliwia użytkownikom normalizację i czyszczenie danych bez pisania kodu. DataBrew może skrócić czas potrzebny na przygotowanie danych do uczenia maszynowego i analizy nawet o 80 procent w porównaniu z przygotowaniem danych opracowanych na zamówienie.
Istnieje ponad 250 gotowych przekształceń danych, których można użyć do zautomatyzowania zadań związanych z przygotowywaniem danych, takich jak filtrowanie anomalii, korygowanie nieprawidłowych wartości i konwertowanie danych do standardowych formatów.
DataBrew ułatwia naukowcom danych, analitykom biznesowym i inżynierom współpracę przy wydobywaniu spostrzeżeń z nieprzetworzonych danych. DataBrew nie wymaga użycia serwera, więc nie musisz zarządzać infrastrukturą ani tworzyć klastrów, aby eksplorować i przekształcać nieprzetworzone dane o wartości terabajtów.
Funkcje DataBrew dla przedsiębiorstw
Przygotowanie wizualizacji danych
DataBrew to inny sposób przeglądania danych, które są zwykle wyświetlane w kolumnowych bazach danych jako liczby alfanumeryczne. DataBrew wizualizuje wszystkie załadowane źródła danych, aby pomóc Ci zrozumieć relacje i hierarchię danych.
250+ automatyzacji przygotowania danych
Od analityków danych oczekuje się, że w ramach swojej pracy będą śledzić różne powtarzalne, izolowane przepływy pracy. Te przepływy pracy i procesy zostały zamodelowane przez AWS jako moduły językowe i moduły niezależne od danych. Ta biblioteka zawiera akcje, z których mogą korzystać użytkownicy końcowi.
Pochodzenie danych
Podobnie jak w przypadku dzienników audytu, które są używane do śledzenia aktywności klientów w sieci informatycznej sieci informatycznej, pochodzenie danych umożliwia śledzenie działań związanych z transformacją danych w AWS DataBrew. Informacje te obejmują źródło danych, zastosowane przekształcenia oraz dane wyjściowe, w tym lokalizację docelową.
Mapowanie danych
Databrew pozwala znaleźć pasujące pola w dwóch źródłach danych. Po zidentyfikowaniu pasujących pól można je załadować do schematu.
AWS Glue DataBrew: Korzyści
Poniżej znajdują się cechy AWS Glue DataBrew:
- Niższa bariera wejścia w celu przygotowania danych
- Automatyczne generowanie profilu danych
- Zautomatyzuj 250+ procesów przygotowania danych
- Inteligentne sugestie nakazowe
Alternatywy dla kleju AWS
Przepływ powietrza
Airflow należy do sekcji Workflow Manager stosu technicznego. Jest to narzędzie typu open source, które obsługuje gwiazdki GitHub, widły GitHub i inne funkcje. Airflow umożliwia tworzenie przepływów pracy przy użyciu ukierunkowanych diagramów acyklicznych (DAG). Harmonogram przepływu powietrza wykonuje zadania przy użyciu szeregu pracowników i zgodnie z określonymi zależnościami.
Matillion

Matillion ETL, narzędzie ETL/ELT, zostało zaprojektowane specjalnie dla platform baz danych w chmurze, takich jak Amazon Redshift i Google BigQuery. Jest to nowoczesny interfejs użytkownika oparty na przeglądarce z potężnymi możliwościami push-down ETL/ELT. Dzięki szybkiej konfiguracji możesz zacząć działać w ciągu kilku minut.
Szew
Stitch to usługa ETL typu open source, która łączy wiele źródeł danych i replikuje dane do preferowanych miejsc docelowych. Jest bardzo łatwy w użyciu, ponieważ nie potrzebujesz żadnej wiedzy o kodowaniu, aby przenosić dane między źródłami i miejscami docelowymi w Stitch. Jest łatwy w użyciu, posiada przyjazny GUI i jest szybki.
Stitch nie pozwala wybrać gotowego pulpitu nawigacyjnego, w przeciwieństwie do innych narzędzi ETL. Zamiast tego należy zintegrować dane z otwartymi hurtowniami danych wybranymi jako miejsce docelowe. Nawigacja w zasobach może być trudna.
Alteryx

Alteryx to platforma do automatyzacji analiz, która pomaga w przygotowywaniu i łączeniu danych. Dane te można wykorzystać do przyspieszenia procesów i zapewnienia wglądu biznesowego. Ponieważ jest to narzędzie typu „przeciągnij i upuść”, nie potrzebujesz żadnej wiedzy programistycznej. Alteryx to świetne miejsce, w którym można uzyskać porady i odpowiedzi od profesjonalistów z branży.
Wniosek
Tak więc chodziło o AWS Glue, który jest rozwiązaniem opartym na chmurze, które umożliwia pracę z potokami ETL. Podsumowując, proces interakcji z użytkownikiem AWS Glue składa się z trzech faz. Aby utworzyć katalog danych, najpierw użyj przeszukiwaczy danych. Następnie tworzysz kod ETL wymagany przez potok danych AWS. Na koniec tworzony jest harmonogram ETL. Mam nadzieję, że ten blog dał ci dobry przegląd Amazon Glue.
Możesz również zapoznać się z najlepszymi wskazówkami dotyczącymi zabezpieczania pamięci masowej AWS S3.