
Dzisiejsze firmy są zorientowane na dane. Firmy znajdują sposoby na efektywne wydobywanie i analizowanie danych z różnych źródeł oraz zwiększanie przychodów i zysków biznesowych.
Ale jakie jest najbezpieczniejsze miejsce do przechowywania i integracji danych z wielu źródeł i jak najlepszego ich wykorzystania?
Zarówno jeziora danych, jak i hurtownie danych to popularne sposoby zarządzania ogromnymi ilościami dużych zbiorów danych. Różnice między nimi polegają na tym, jak organizacje pozyskują, przechowują i wykorzystują dane. Czytaj dalej, aby dowiedzieć się więcej.
Spis treści:
Co to jest jezioro danych?
Data Lake odnosi się do centralnego repozytorium pamięci masowej, w którym dane pozyskiwane z wielu źródeł — w dowolnym formacie (strukturalnym lub niestrukturalnym) — są przechowywane w postaci otrzymanej. Jest jak pula surowych danych, których cel nie jest jeszcze znany. Firmy zazwyczaj przechowują dane, które mogą być potencjalnie przydatne do przyszłych analiz w jeziorze danych.
Najważniejsze cechy jeziora danych:
- Zawiera mieszankę przydatnych i nieprzydatnych danych, dlatego potrzebuje dużo miejsca do przechowywania.
- Przechowuje zarówno dane w czasie rzeczywistym, jak i dane wsadowe — na przykład możesz przechowywać dane w czasie rzeczywistym z urządzeń IoT, mediów społecznościowych lub aplikacji w chmurze oraz dane wsadowe z baz danych lub plików danych.
- Ma płaską architekturę.
- Ponieważ dane nie są przetwarzane, dopóki nie są potrzebne do analizy, muszą być dobrze zarządzane i utrzymywane; w przeciwnym razie może przekształcić się w bagna danych.
Jak więc możemy szybko odzyskać dane z tak ogromnego i pozornie niechlujnego repozytorium pamięci masowej? Cóż, jezioro danych używa do tego celu tagów metadanych i identyfikatorów!
Co to jest hurtownia danych?
Bardziej zorganizowane i ustrukturyzowane repozytorium – hurtownia danych zawiera dane gotowe do analizy. Ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane dane z wielu źródeł są pozyskiwane, integrowane, oczyszczane, sortowane, przekształcane i dostosowywane do użytku.
Hurtownia danych zawiera duże ilości danych przeszłych i bieżących. Zazwyczaj dane są przetwarzane pod konkretny problem biznesowy (analiza). Takie informacje są przeszukiwane przez systemy Business Intelligence (BI) w celu analizy, raportowania i wglądu.
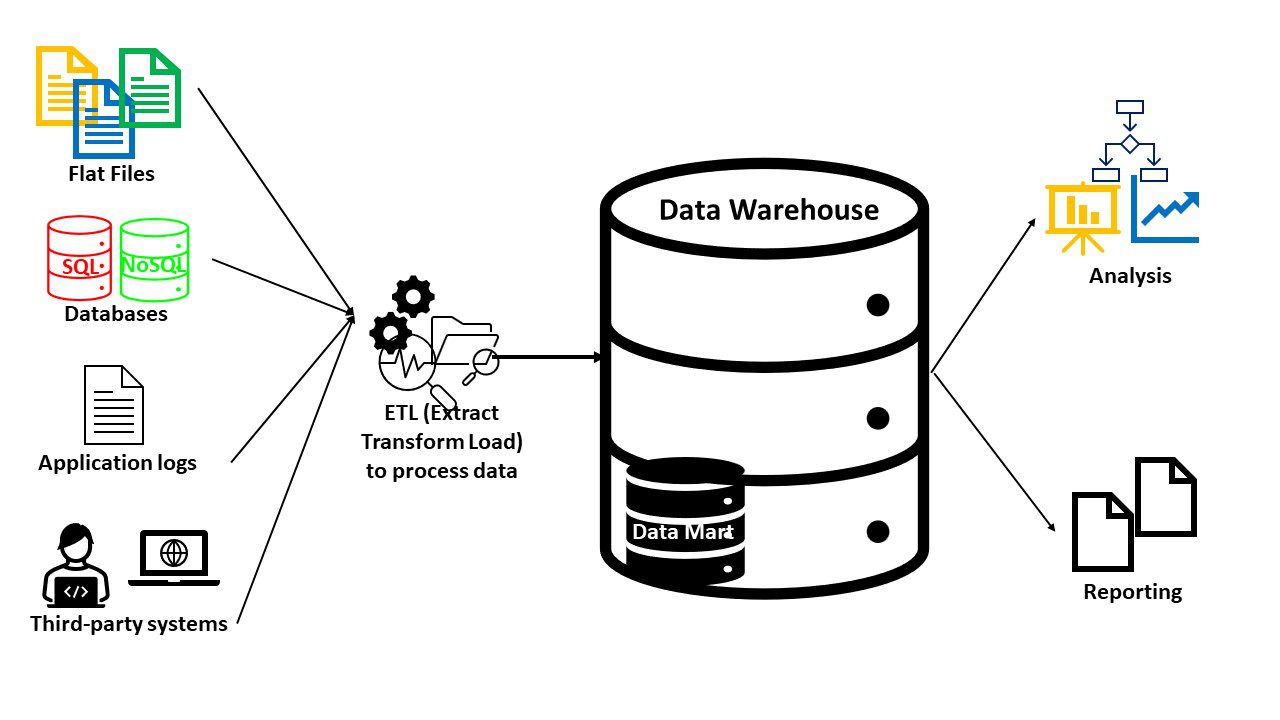
Hurtownie danych zazwyczaj składają się z następujących elementów:
- Baza danych (SQL lub NoSQL) do przechowywania danych i zarządzania nimi
- Narzędzia do transformacji i analizy danych do przygotowania danych
- Narzędzia BI do eksploracji danych, analizy statystycznej, raportowania i wizualizacji
Ponieważ hurtownie danych służą określonemu celowi, zawsze będziesz mieć odpowiednie dane. Możesz również użyć dodatkowych narzędzi w hurtowniach danych, aby zaspokoić zaawansowane możliwości, takie jak sztuczna inteligencja i funkcje przestrzenne lub wykresy. Hurtownie danych utworzone dla określonej domeny nazywane są data martami.
Kluczowe różnice między jeziorami danych a hurtowniami danych
Powtarzając to, co przeczytaliśmy powyżej, jezioro danych zawiera surowe dane, których cel nie został zdefiniowany. Natomiast hurtownia danych zawiera dane gotowe do analizy i już w najlepszej formie.
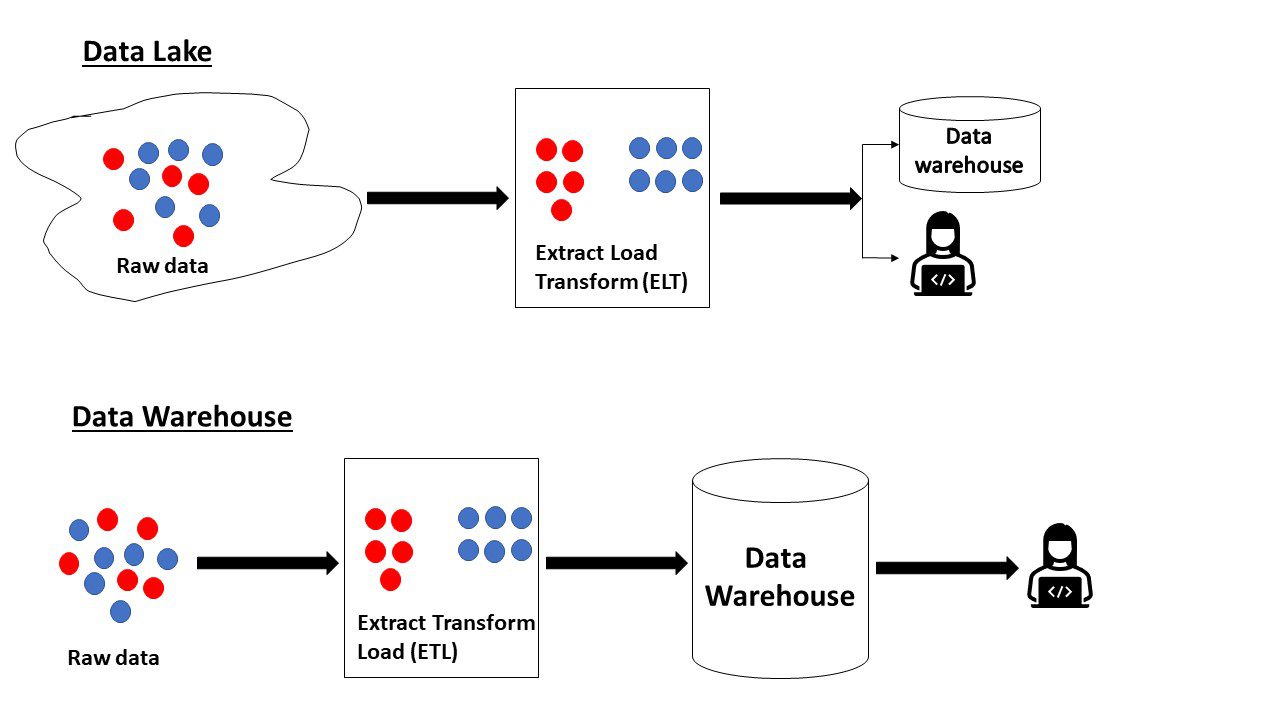 Jezioro danych a hurtownia danych
Jezioro danych a hurtownia danych
Niektóre różnice między jeziorem danych a hurtownią danych to:
Data LakeData WarehouseSurowe lub przetworzone dane w dowolnym formacie są pozyskiwane z wielu źródełDane są uzyskiwane z wielu źródeł w celu analizy i raportowania. Jest ustrukturyzowanySchemat jest tworzony w locie zgodnie z wymaganiami (schema-on-read)Predefiniowany schemat podczas zapisu do hurtowni (Schema-on-write)Łatwe dodawanie nowych danychDane są gotowe po przetworzeniu, więc każda nowa zmiana wymaga więcej czasu i wysiłek.Dane muszą być aktualizowane i zarządzane, aby były istotneDane są już w najlepszej formie, więc nie wymagają szczególnej konserwacji Składają się z ogromnych ilości dużych zbiorów danych (petabajty)Dane są zwykle mniejsze niż w jeziorze danych (terabajty). Hurtownia danych może zawierać dane operacyjne całej organizacji, dane analityczne lub dane istotne dla określonej domenyWykorzystywane przez analityków danych do różnych celów, takich jak analiza strumieniowa, sztuczna inteligencja, analityka predykcyjna i wiele przypadków użycia.Wykorzystywane przez analityków biznesowych do przetwarzania transakcji ( OLTP), analityka operacyjna (OLAP), raportowanie, tworzenie wizualizacjiDane mogą być przechowywane i archiwizowane przez dłuższy czas w celu analizy w dowolnym momencie.Dane muszą być często czyszczone, aby uwzględnić najnowsze dane.Przechowywanie jest niedrogie.Przechowywanie i przetwarzanie są drogie i czasochłonne -konsumpcyjne, stąd należy je planować rozważnie. Naukowcy zajmujący się danymi mogą wypracowywać nowe problemy i rozwiązania patrząc na dane. Zakres danych jest ograniczony do konkretnego problemu biznesowego. relacyjne bazy danych mogą być używane do przechowywania danych. Hurtownie danych zwykle używają relacyjnych baz danych, ponieważ dane muszą być format.
Przypadki użycia dla Data Lake i Data Warehouse
Łatwo jest myśleć o jeziorze danych jako wygodniejszym wyborze, ponieważ jest on bardziej skalowalny, elastyczny i przyjazny dla kieszeni. Jednak hurtownia danych może być świetnym pomysłem, gdy potrzebujesz bardziej trafnych i uporządkowanych danych do konkretnej analizy.
Niektóre przypadki użycia jeziora danych są następujące:
#1. Łańcuch dostaw i zarządzanie
Ogromna ilość dużych zbiorów danych w jeziorach danych pomaga w analizach predykcyjnych dla transportu i logistyki. Korzystając z danych historycznych i bieżących, firmy mogą płynnie planować codzienne operacje, kontrolować ruch zapasów w czasie rzeczywistym i optymalizować koszty.
#2. Opieka zdrowotna
Jezioro danych zawiera wszystkie przeszłe i aktualne informacje o pacjentach. Jest to pomocne w badaniach, znajdowaniu wzorców, zapewnianiu lepszego i wyprzedzającego leczenia chorób, automatyzacji diagnostyki i uzyskiwaniu najbardziej aktualnych informacji o stanie zdrowia pacjenta.
#3. Strumieniowe przesyłanie danych i IoT
Jeziora danych mogą stale odbierać dane przesyłane strumieniowo do potoków analitycznych w celu ciągłego raportowania i wykrywania wszelkich nietypowych działań i ruchów. Jest to możliwe dzięki zdolności Data Lake do zbierania (prawie) danych w czasie rzeczywistym.
Niektóre przypadki użycia hurtowni danych to:
#1. Finanse
Informacje finansowe firmy mogą być bardziej odpowiednie dla hurtowni danych. Pracownicy mogą łatwo uzyskać dostęp do uporządkowanych i ustrukturyzowanych informacji w postaci wykresów i raportów, aby zarządzać procesami finansowymi, radzić sobie z ryzykiem i podejmować strategiczne decyzje.
#2. Marketing i segmentacja klientów
Hurtownia danych tworzy jedno źródło „prawdy” lub poprawnych danych o klientach zebranych z wielu źródeł. Firmy mogą analizować te dane, aby zrozumieć zachowania klientów, oferować dostosowane rabaty, segmentować klientów na podstawie ich preferencji i generować więcej leadów.
#3. Kokpit i raporty firmowe
Wiele firm korzysta z hurtowni danych CRM i ERP do pobierania danych o klientach zewnętrznych i wewnętrznych. Dane są zawsze aktualne i można im zaufać przy tworzeniu wszelkiego rodzaju raportów i wizualizacji.
#4. Migracja danych ze starszych systemów
Korzystając z możliwości ETL hurtowni danych, firmy mogą łatwo przekształcać dane ze starszych systemów w bardziej użyteczny format, który mogą być analizowane przez nowe systemy. Pomoże to organizacjom uzyskać wgląd w trendy historyczne i podejmować trafne decyzje biznesowe.
Przykłady narzędzi Data Lake
Niektórzy najlepsi dostawcy usług Data Lake to:
- Microsoft Azure – Azure może przechowywać i analizować petabajty danych. Platforma Azure ułatwia łatwe debugowanie i optymalizację programów Big Data.
- Chmura Google – Chmura Google oferuje opłacalne pozyskiwanie, przechowywanie i analizę ogromnych wolumenów big data dowolnego typu. Integruje się również z narzędziami analitycznymi, takimi jak Apache Spark, BigQuery i innymi akceleratorami analitycznymi.
- Atlas MongoDB – Atlas Data Lake to w pełni zarządzany magazyn danych. Zapewnia opłacalne sposoby przechowywania danych na dużą skalę i może uruchamiać zapytania o wysokiej wydajności, które zużywają mniej mocy obliczeniowej, oszczędzając w ten sposób czas i koszty.
- Amazonka S3 – Chmura AWS zapewnia niezbędne narzędzia do zbudowania elastycznego, bezpiecznego i ekonomicznego jeziora danych. Posiada interaktywną konsolę do zarządzania użytkownikami jeziora danych i kontroli dostępu do użytkowników.
Przykłady narzędzi hurtowni danych
Niektórzy z czołowych dostawców rozwiązań hurtowni danych to:
- SOK ROŚLINNY – Hurtownia danych SAP umożliwia użytkownikom semantyczny dostęp do bogatych danych z wielu źródeł. Firmy mogą bezpiecznie udostępniać spostrzeżenia i modele, przyspieszać podejmowanie decyzji i bezpiecznie łączyć dane zewnętrzne i wewnętrzne.
- Dane Clic – Inteligentna i zintegrowana hurtownia danych ClicData zapewnia integralność danych, jakość i łatwość raportowania. ClicData oferuje zarówno systemy planowania, jak i interfejsy API czasu rzeczywistego, dzięki czemu możesz zawsze otrzymywać aktualne dane.
- Amazon Redshift – Jedna z najczęściej używanych hurtowni danych, Redshift używa SQL do analizy wszystkich typów danych obecnych w różnych bazach danych, jeziorach lub innych hurtowniach. Oferuje doskonałą równowagę kosztów i wydajności.
- Magazyn IBM Db2 – IBM dostarcza rozwiązania wewnętrzne, chmurowe i zintegrowane w zakresie hurtowni danych. Integruje również uczenie maszynowe i narzędzia sztucznej inteligencji w celu głębszej analizy danych oraz udostępnia wspólny silnik SQL w celu usprawnienia zapytań.
- Hurtownia danych Oracle Cloud Oracle korzysta z bazy danych w pamięci i oferuje funkcje graficzne, uczenie maszynowe i przestrzenne, aby zagłębić się w dane w celu szybszej, ale bogatszej analizy danych.
Ostatnie słowa
Zarówno jeziora danych, jak i hurtownie danych mają swoje zalety i idealne przypadki użycia. Podczas gdy jeziora danych są bardziej skalowalne i elastyczne, hurtownie danych zawsze zawierają niezawodne i ustrukturyzowane informacje. Implementacja Data Lake jest stosunkowo nowa, podczas gdy hurtownia danych jest ugruntowaną koncepcją stosowaną przez wiele organizacji do efektywnego zarządzania danymi wewnętrznymi i zewnętrznymi.