
Jeśli nauczyłeś się kilku języków programowania komputerowego, być może słyszałeś termin parsowanie tekstu. Służy do uproszczenia złożonych wartości danych w pliku. Artykuł pomaga ci wiedzieć, jak analizować tekst za pomocą języka. Oprócz tego, jeśli napotkałeś błąd w parsowaniu tekstu x, będziesz wiedział, jak naprawić błąd parsowania w artykule.

Spis treści:
Jak analizować tekst
W tym artykule pokazaliśmy pełny przewodnik po parsowaniu tekstu na różne sposoby, a także pokrótce przedstawiliśmy wprowadzenie do parsowania tekstu.
Co to jest parsowanie tekstu?
Przed zagłębieniem się w koncepcje parsowania tekstu za pomocą dowolnego kodu. Ważne jest, aby znać podstawy języka i kodowania.
NLP lub przetwarzanie języka naturalnego
Do analizy tekstu wykorzystuje się przetwarzanie języka naturalnego lub NLP, które jest poddziedziną domeny sztucznej inteligencji. Język Python, który jest jednym z języków należących do kategorii, służy do parsowania tekstu.
Kody NLP umożliwiają komputerom rozumienie i przetwarzanie ludzkich języków w celu dostosowania ich do różnych zastosowań. Aby zastosować techniki uczenia maszynowego lub uczenia maszynowego do języka, nieustrukturyzowane dane tekstowe muszą zostać przekonwertowane na ustrukturyzowane dane tabelaryczne. Aby ukończyć czynność parsowania, język Python służy do zmiany kodów programu.
Co to jest parsowanie tekstu?
Parsowanie tekstu oznacza po prostu konwersję danych z jednego formatu na inny. Format, w którym zapisany jest plik, powinien zostać przeanalizowany lub przekonwertowany na plik w innym formacie, aby umożliwić użytkownikowi korzystanie z niego w różnych aplikacjach.
- Innymi słowy, proces oznacza analizę ciągu lub tekstu i konwersję na komponenty logiczne poprzez zmianę formatu pliku.
- Niektóre reguły języka Python są wykorzystywane do wykonania tego wspólnego zadania programistycznego. Podczas analizowania tekstu dana seria tekstu jest rozbijana na mniejsze elementy.
Jakie są powody analizowania tekstu?
Powody, dla których tekst musi być parsowany, są podane w tej sekcji i jest to wiedza wymagana przed poznaniem sposobu parsowania tekstu.
- Wszystkie skomputeryzowane dane nie będą miały tego samego formatu i mogą się różnić w zależności od różnych zastosowań.
- Formaty danych różnią się w zależności od aplikacji, a niekompatybilny kod może prowadzić do tego błędu.
- Nie ma indywidualnego uniwersalnego programu komputerowego do selekcji danych we wszystkich formatach danych.
Metoda 1: Poprzez klasę DataFrame
Klasa DataFrame języka Python posiada wszystkie wymagane funkcje do parsowania tekstu. Ta wbudowana biblioteka zawiera niezbędne kody do przetwarzania danych z dowolnego formatu na inny format.
Krótkie wprowadzenie do klasy DataFrame
DataFrame Class to bogata w funkcje struktura danych, która służy jako narzędzie do analizy danych. Jest to potężne narzędzie do analizy danych, które można wykorzystać do analizy danych przy minimalnym wysiłku.
- Kod jest wczytywany do DataFrame pandy w celu przeprowadzenia analizy w języku Python.
- Klasa zawiera liczne pakiety dostarczane przez pandy, które są używane przez analityków danych Pythona.
- Cechą tej klasy jest abstrakcja, kod, w którym wewnętrzna funkcjonalność funkcji jest ukryta przed użytkownikami biblioteki NumPy. Biblioteka NumPy to biblioteka Pythona, która zawiera polecenia i funkcje do pracy z tablicami.
- Klasa DataFrame może służyć do renderowania dwuwymiarowej tablicy z wieloma indeksami wierszy i kolumn. Indeksy te pomagają w przechowywaniu danych wielowymiarowych, dlatego nazywane są MultiIndex. Muszą one zostać zmienione, aby wiedzieć, jak naprawić błąd analizy.
Pandy języka Python pomagają w wykonywaniu operacji w stylu SQL lub bazy danych z najwyższą perfekcją, aby uniknąć błędów w tekście analizy x. Zawiera również kilka narzędzi IO, które pomagają w analizie plików CSV, MS Excel, JSON, HDF5 i innych formatach danych.
Proces parsowania tekstu przy użyciu klasy DataFrame
Aby wiedzieć, jak parsować tekst, możesz użyć standardowego procesu przy użyciu klasy DataFrame podanej w tej sekcji.
- Odszyfruj format danych wejściowych.
- Określ dane wyjściowe danych, takie jak CSV lub wartość oddzielona przecinkami.
- Napisz w kodzie prymitywny typ danych, taki jak lista lub dykt.
Uwaga: Pisanie kodu w pustej ramce DataFrame może być żmudne i skomplikowane. Pandy pozwalają na tworzenie danych w klasie DataFrame z tych typów danych. W związku z tym dane w pierwotnym typie danych można łatwo przeanalizować do wymaganego formatu danych.
- Przeanalizuj dane za pomocą narzędzia do analizy danych pandas DataFrame i wydrukuj wynik.
Opcja I: Format standardowy
Poniżej wyjaśniono standardową metodę formatowania dowolnego pliku w określonym formacie danych, takim jak CSV.
- Zapisz plik z wartościami danych lokalnie na swoim komputerze. Na przykład możesz nazwać plik data.txt.
- Zaimportuj plik w pandach o określonej nazwie i zaimportuj dane do innej zmiennej. Na przykład pandy języka są importowane do nazwy pd w podanym kodzie.
- Import powinien mieć pełny kod ze szczegółami nazwy pliku wejściowego, funkcji i formatu pliku wejściowego.
Uwaga: W tym przypadku zmienna o nazwie res służy do wykonania funkcji odczytu danych w pliku data.txt przy użyciu pand zaimportowanych do pd. Format danych tekstu wejściowego jest określony w formacie CSV.
- Wywołaj nazwany typ pliku i przeanalizuj przeanalizowany tekst na wydrukowanym wyniku. Na przykład polecenie res po wykonaniu wiersza poleceń pomoże w wydrukowaniu przeanalizowanego tekstu.
Przykładowy kod dla procesu wyjaśnionego powyżej znajduje się poniżej i pomoże zrozumieć, jak parsować tekst.
import pandas as pd res = pd.read_csv(‘data.txt’) res
W takim przypadku, jeśli wprowadzisz wartości danych w pliku data.txt, takie jak [1,2,3]zostanie przeanalizowany i wyświetlony jako 1 2 3.
Opcja II: Metoda ciągów
Jeśli tekst podany w kodzie zawiera tylko ciągi znaków lub znaki alfanumeryczne, do oddzielenia i przeanalizowania tekstu można użyć znaków specjalnych w ciągu, takich jak przecinki, spacja itp. Proces jest podobny do typowych wewnętrznych operacji na ciągach. Aby dowiedzieć się, jak naprawić błąd parsowania, musisz postępować zgodnie z procesem parsowania tekstu za pomocą tej opcji, który jest wyjaśniony poniżej.
- Dane są wyodrębniane z ciągu i zapisywane są wszystkie znaki specjalne oddzielające tekst.
Na przykład w kodzie podanym poniżej identyfikowane są znaki specjalne w ciągu my_string, którymi są „,” i „:”. Ten proces musi być wykonany ostrożnie, aby uniknąć błędu w parsowaniu tekstu x.
- Tekst w ciągu jest dzielony indywidualnie na podstawie wartości i położenia znaków specjalnych.
Na przykład ciąg jest dzielony na wartości danych tekstowych na podstawie znaków specjalnych zidentyfikowanych za pomocą polecenia split.
- Wartości danych w łańcuchu są drukowane jako przeanalizowany tekst. Tutaj instrukcja print służy do drukowania przeanalizowanej wartości danych tekstu.
Przykładowy kod dla opisanego powyżej procesu znajduje się poniżej.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
W takim przypadku wynik przeanalizowanego ciągu zostanie wyświetlony, jak pokazano poniżej.
Names: [‘Tech’, ‘computer’]
Aby uzyskać lepszą przejrzystość i wiedzieć, jak analizować tekst podczas używania tekstu ciągu, używana jest pętla for, a kod jest modyfikowany w następujący sposób.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
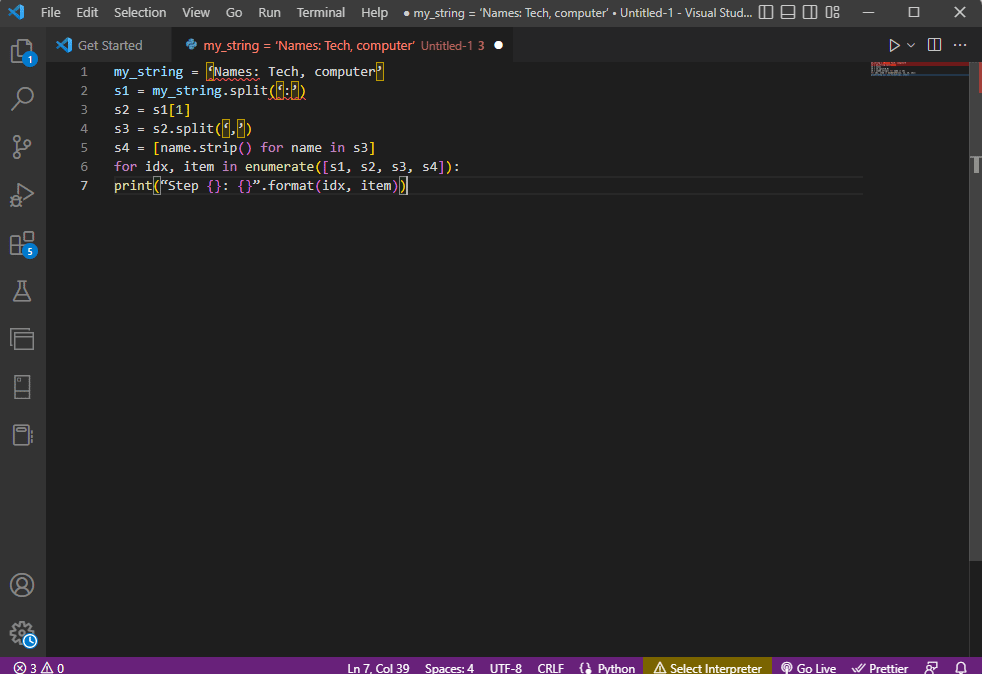
Wynik przeanalizowanego tekstu dla każdego z tych kroków jest wyświetlany, jak podano poniżej. Można zauważyć, że w kroku 0 ciąg jest rozdzielany na podstawie znaku specjalnego : a wartości danych tekstowych są rozdzielane na podstawie znaku w dalszych krokach.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Opcja III: parsowanie złożonego pliku
W większości przypadków dane pliku, które należy przeanalizować, zawierają różne typy danych i wartości danych. W takim przypadku przeanalizowanie pliku przy użyciu metod wyjaśnionych wcześniej może być trudne.
Funkcje parsowania złożonych danych w pliku mają na celu wyświetlenie wartości danych w formacie tabelarycznym.
- Tytuł lub Metadane wartości są drukowane na górze pliku,
- Zmienne i pola są drukowane na wyjściu w formie tabelarycznej i
- Wartości danych tworzą klucz złożony.
Zanim zagłębimy się w naukę parsowania tekstu tą metodą, konieczne jest poznanie kilku podstawowych pojęć. Parsowanie wartości danych odbywa się na podstawie wyrażeń regularnych lub Regex.
Wzory wyrażeń regularnych
Aby wiedzieć, jak naprawić błąd parsowania, musisz upewnić się, że wzorce regex w wyrażeniach są prawidłowe. Kod do analizowania wartości danych ciągów obejmuje typowe wzorce Regex wymienione poniżej w tej sekcji.
-
'd’ : dopasowuje cyfrę dziesiętną w ciągu,
-
's’ : dopasowuje znak odstępu,
-
'w’: pasuje do znaku alfanumerycznego,
-
'+’ lub '*’ : wykonuje zachłanne dopasowanie, dopasowując jeden lub więcej znaków w ciągach,
-
'a-z’ : dopasowuje grupy małych liter w wartościach danych tekstowych,
-
'A-Z’ lub 'a-z’ : dopasowuje wielkie i małe grupy ciągu oraz
-
'0-9′ : dopasowuje wartości liczbowe.
Wyrażenia regularne
Moduły wyrażeń regularnych są główną częścią pakietu pandas w języku Python, a błędny re może prowadzić do błędu w parsowaniu tekstu x. Jest to mały język osadzony w Pythonie do wyszukiwania wzorca ciągu w wyrażeniu. Wyrażenia regularne lub Regex to ciągi o specjalnej składni. Pozwala użytkownikowi dopasować wzorce w innych ciągach na podstawie wartości w ciągach.
Regex jest tworzony na podstawie typu danych i wymagania wyrażenia w ciągu, np. „String = (.*)n. Wyrażenie regularne jest używane przed wzorcem w każdym wyrażeniu. Symbole używane w wyrażeniach regularnych są wymienione poniżej i pomagają w nauce parsowania tekstu.
-
. : aby pobrać dowolny znak z danych,
-
* : użyj zero lub więcej danych z poprzedniego wyrażenia,
-
(.*) : aby zgrupować część wyrażenia regularnego w nawiasach,
-
n : Utwórz nowy znak linii na końcu linii w kodzie,
-
d : utwórz krótką wartość całkowitą w zakresie od 0 do 9,
-
+ : użyj jednego lub więcej danych z poprzedniego wyrażenia i
-
| : utwórz logiczne oświadczenie; używane dla lub wyrażeń.
Obiekty Regex
RegexObject jest wartością zwracaną dla funkcji kompilacji i służy do zwracania MatchObject, jeśli wyrażenie jest zgodne z wartością dopasowania.
1. Dopasuj obiekt
Ponieważ wartość logiczna MatchObject jest zawsze True, można użyć instrukcji if do zidentyfikowania pozytywnych dopasowań w obiekcie. W przypadku użycia instrukcji if, grupa, do której odwołuje się indeks, służy do znalezienia dopasowania obiektu w wyrażeniu.
-
group() zwraca jedną lub więcej podgrup dopasowania,
-
group(0) zwraca całe dopasowanie,
-
group(1) zwraca pierwszą podgrupę w nawiasach, a
- Odnosząc się do wielu grup, powinniśmy użyć rozszerzenia specyficznego dla Pythona. To rozszerzenie służy do określenia nazwy grupy, w której ma znaleźć się dopasowanie. Konkretne rozszerzenie znajduje się w grupie w nawiasach. Na przykład wyrażenie (?P
regex1) odwołuje się do określonej grupy o nazwie group1 i sprawdza dopasowanie w wyrażeniu regularnym regex1. Aby dowiedzieć się, jak naprawić błąd parsowania, musisz sprawdzić, czy grupa jest poprawnie wskazana.
2. Metody MatchObject
Podczas szukania sposobu parsowania tekstu ważne jest, aby wiedzieć, że MatchObject ma dwie podstawowe metody wymienione poniżej. Jeśli MatchObject zostanie znaleziony w określonym wyrażeniu, zwróci jego wystąpienie, w przeciwnym razie zwróci None.
- Metoda match(string) służy do znajdowania dopasowań ciągu na początku wyrażenia regularnego, a
- Metoda search(string) służy do przeglądania ciągu w celu znalezienia lokalizacji dopasowania w wyrażeniu regularnym.
Funkcje wyrażeń regularnych
Funkcje Regex to linie kodu, które są używane do wykonywania określonej funkcji określonej przez użytkownika z zestawu uzyskanych wartości danych.
Uwaga: Aby napisać funkcje, w wyrażeniach regularnych używane są nieprzetworzone ciągi, aby uniknąć błędów w przetwarzaniu tekstu x. Odbywa się to poprzez dodanie indeksu dolnego r przed każdym wzorcem w wyrażeniu.
Poniżej wyjaśniono typowe funkcje używane w wyrażeniach.
1. re.findall()
Ta funkcja zwraca wszystkie wzorce w ciągu, jeśli zostanie znalezione dopasowanie i zwraca pustą listę, jeśli nie zostanie znalezione dopasowanie. Na przykład funkcja string = re.findall('[aeiou]’, regex_filename) służy do znalezienia wystąpienia samogłoski w nazwie pliku.
2. odn.split()
Ta funkcja służy do dzielenia ciągu w przypadku znalezienia dopasowania z określonym znakiem, takim jak spacja. W przypadku braku dopasowania zwraca pusty ciąg.
3. re.sub()
Funkcja zastępuje dopasowany tekst zawartością podanej zmiennej replace. W przeciwieństwie do innych funkcji, jeśli nie zostanie znaleziony żaden wzorzec, zwracany jest oryginalny ciąg.
4. re.szukaj()
Jedną z podstawowych funkcji pomagających w nauce parsowania tekstu jest funkcja wyszukiwania. Pomaga w wyszukiwaniu wzorca w łańcuchu i zwracaniu obiektu dopasowania. Jeśli wyszukiwanie nie powiedzie się w identyfikacji dopasowania, nie zostanie zwrócona żadna wartość.
5. rekompilacja (wzór)
Ta funkcja służy do kompilowania wzorców wyrażeń regularnych do obiektu RegexObject, który został omówiony wcześniej.
Inne wymagania
Wymienione wymagania to dodatkowa funkcja wykorzystywana przez zaawansowanych programistów w analizie danych.
- Do wizualizacji wyrażenia regularnego używane jest wyrażenie regularne i
- Do testowania wyrażenia regularnego używane jest regex101.
Proces parsowania tekstu
Sposób parsowania tekstu w tej złożonej opcji jest opisany poniżej.
- Najważniejszym krokiem jest zrozumienie formatu wejściowego poprzez odczytanie zawartości pliku. Na przykład funkcje with open i read() służą do otwierania i odczytywania zawartości pliku o nazwie sample. Przykładowy plik zawiera zawartość z pliku file.txt; aby dowiedzieć się, jak naprawić błąd parsowania, plik musi być odczytany w całości.
- Zawartość pliku jest drukowana w celu ręcznej analizy danych w celu znalezienia metadanych wartości. Tutaj funkcja print() służy do drukowania zawartości przykładowego pliku.
- Wymagane pakiety danych do przeanalizowania tekstu są importowane do kodu i nadawana jest klasie nazwa do dalszego kodowania. Tutaj importowane są wyrażenia regularne i pandy.
- Wyrażenia regularne wymagane dla kodu są zdefiniowane w pliku poprzez dołączenie wzorca regex i funkcji regex. Pozwala to obiektowi tekstowemu lub korpusowi pobrać kod do analizy danych.
- Aby dowiedzieć się, jak parsować tekst, możesz odwołać się do przykładowego kodu podanego tutaj. Funkcja compile() służy do kompilacji łańcucha z grupy stringname1 w pliku nazwapliku. Funkcja sprawdzania dopasowań w wyrażeniu regularnym jest używana przez polecenie ief_parse_line(line),
- Parser linii dla kodu jest napisany przy użyciu def_parse_file(ścieżka pliku), w którym zdefiniowana funkcja sprawdza wszystkie dopasowania regex w określonej funkcji. W tym przypadku metoda regex search() wyszukuje klucz rx w nazwie pliku i zwraca klucz i dopasowanie pierwszego pasującego wyrażenia regularnego. Każdy problem z krokiem może prowadzić do błędu w analizie tekstu x.
- Następnym krokiem jest napisanie parsera plików za pomocą funkcji parsera plików, którą jest def_parse_file(ścieżka pliku). Tworzona jest pusta lista do zbierania danych kodu, ponieważ data = []dopasowanie jest sprawdzane w każdym wierszu przez match = _parse_line(line), a dokładne dane wartości są zwracane na podstawie typu danych.
- Aby wyodrębnić numer i wartość z tabeli, używana jest komenda line.strip().split(’,’). Polecenie row{} służy do tworzenia słownika z wierszem danych. Polecenie data.append(row) służy do zrozumienia danych i przetworzenia ich do formatu tabelarycznego.
Polecenie data = pd.DataFrame(data) służy do tworzenia pandy DataFrame z wartości dict. Alternatywnie możesz użyć następujących poleceń w odpowiednim celu, jak podano poniżej.
-
data.set_index([‘string’, ‘integer’]inplace=True), aby ustawić indeks tabeli.
-
data = data.groupby(level=data.index.names).first(), aby skonsolidować i usunąć nans.
-
data = data.apply(pd.to_numeric, error=’ignore’), aby uaktualnić wynik z liczby zmiennoprzecinkowej do wartości całkowitej.
Ostatnim krokiem, aby dowiedzieć się, jak parsować tekst, jest przetestowanie parsera przy użyciu instrukcji if, przypisując wartości do zmiennej data i drukując ją za pomocą polecenia print(data).
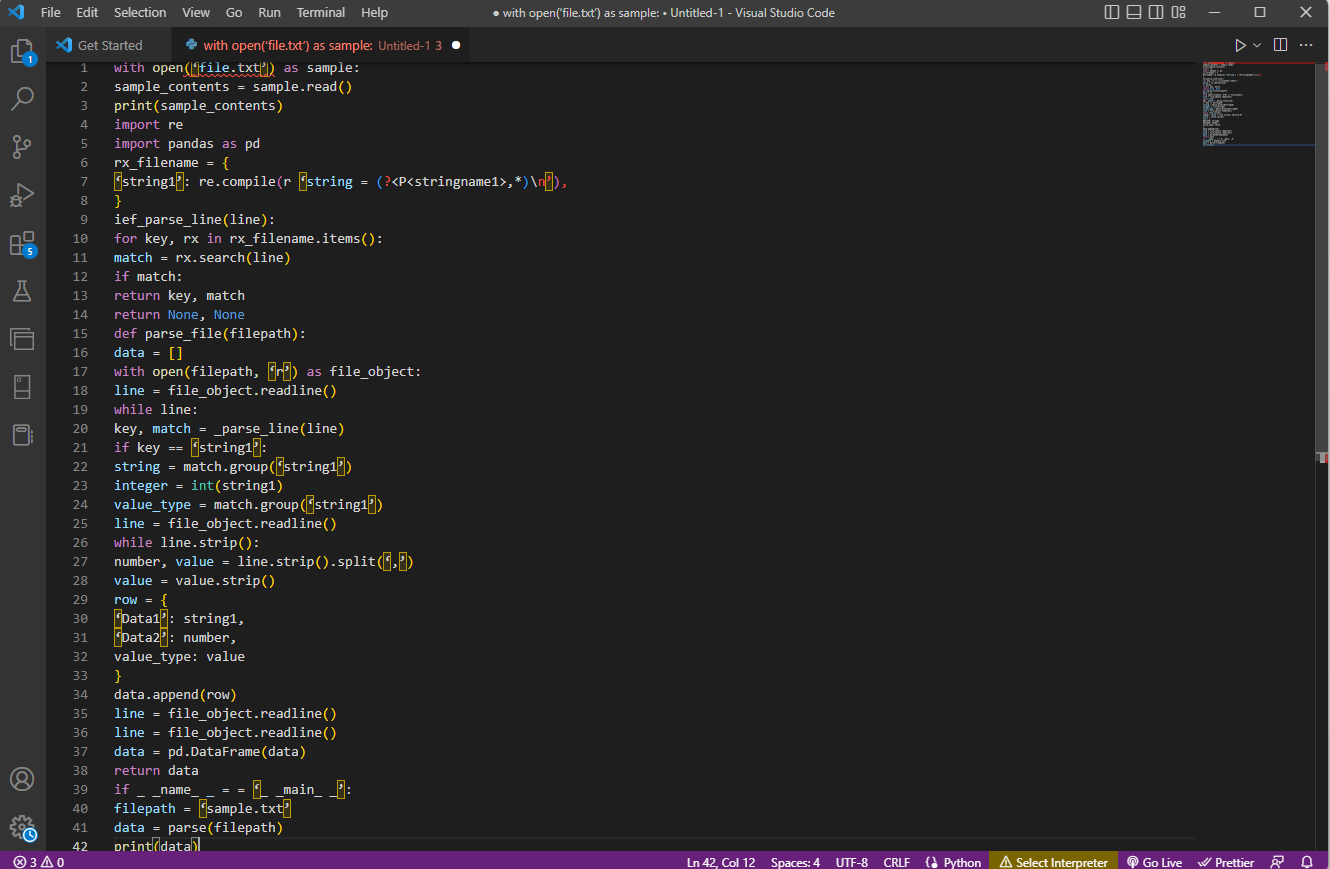
Przykładowy kod dla powyższego wyjaśnienia znajduje się tutaj.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metoda 2: Poprzez tokenizację słowa
Proces przekształcania tekstu lub korpusu na żetony lub mniejsze kawałki w oparciu o określone zasady nazywa się Tokenizacją. Aby dowiedzieć się, jak naprawić błąd parsowania, ważne jest, aby przeanalizować polecenia tokenizacji słów w kodzie. Podobnie jak w przypadku wyrażenia regularnego, w tej metodzie można tworzyć własne reguły, które pomagają w zadaniach wstępnego przetwarzania tekstu, takich jak mapowanie części mowy. W tej metodzie wykonywane są również działania, takie jak znajdowanie i dopasowywanie typowych słów, czyszczenie tekstu i przygotowywanie danych do zaawansowanych technik analizy tekstu, takich jak analiza sentymentu. Jeśli tokenizacja jest nieprawidłowa, może wystąpić błąd w parsowaniu tekstu x.
Biblioteka Ntlk
Proces ten wykorzystuje popularną bibliotekę narzędzi językowych o nazwie nltk, która ma bogaty zestaw funkcji do wykonywania wielu zadań NLP. Można je pobrać za pośrednictwem pakietów instalacyjnych Pip lub Pip. Aby wiedzieć, jak parsować tekst, możesz użyć pakietu podstawowego dystrybucji Anaconda, który domyślnie zawiera bibliotekę.
Formy tokenizacji
Powszechnymi formami tej metody są tokenizacja słów i tokenizacja zdań. Dzięki tokenowi na poziomie słowa, pierwszy drukuje jedno słowo tylko raz, podczas gdy drugi drukuje słowo na poziomie zdania.
Proces parsowania tekstu
- Biblioteka zestawu narzędzi ntlk jest importowana, a formularze tokenizacji są importowane z biblioteki.
- Podany jest łańcuch i podane są polecenia do wykonania tokenizacji.
- Gdy łańcuch jest wypisywany, wyjściem będzie komputer to słowo.
- W przypadku tokenizacji słowa lub word_tokenize(), każde słowo w zdaniu jest drukowane osobno w ”” i jest oddzielone przecinkiem. Dane wyjściowe polecenia to „komputer”, „jest”, „to”, „słowo”, „.”
- W przypadku tokenizacji zdania lub sent_tokenize(), poszczególne zdania są umieszczane w ”, a powtarzanie słów jest dozwolone. Wynikiem polecenia byłoby „komputer to słowo”.
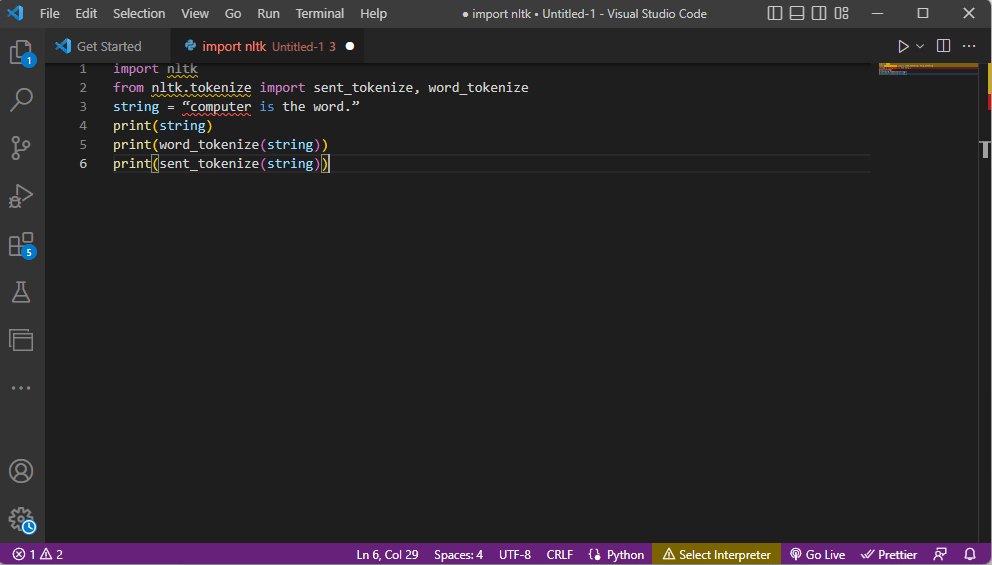
Kod wyjaśniający powyższe kroki tokenizacji znajduje się tutaj.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metoda 3: Poprzez klasę DocParser
Podobnie do klasy DataFrame, klasa DocParser może służyć do analizowania tekstu w kodzie. Klasa umożliwia wywołanie funkcji parse ze ścieżką do pliku.
Proces parsowania tekstu
Aby dowiedzieć się, jak parsować tekst za pomocą klasy DocParser, postępuj zgodnie z instrukcjami podanymi poniżej.
- Funkcja get_format(filename) służy do wyodrębnienia rozszerzenia pliku, zwrócenia go do zmiennej set dla funkcji i przekazania go do następnej funkcji. Na przykład p1 = get_format(nazwapliku) wyodrębni rozszerzenie pliku z nazwy pliku, ustawi je na zmienną p1 i przekaże do następnej funkcji.
- Struktura logiczna z innymi funkcjami jest tworzona przy użyciu instrukcji i funkcji if-elif-else.
- Jeśli rozszerzenie pliku jest poprawne, a struktura jest logiczna, funkcja get_parser służy do analizowania danych w ścieżce pliku i zwracania obiektu ciągu do użytkownika.
Uwaga: Aby wiedzieć, jak naprawić błąd parsowania, ta funkcja musi być poprawnie zaimplementowana.
- Analiza wartości danych odbywa się z rozszerzeniem pliku. Konkretna implementacja klasy, którą są parse_txt lub parse_docx, służy do generowania obiektów ciągu z części danego typu pliku.
- Parsowanie można wykonać dla plików o innych czytelnych rozszerzeniach, takich jak parse_pdf, parse_html i parse_pptx.
- Wartości danych i interfejs można importować do aplikacji za pomocą instrukcji import i tworzyć instancję obiektu DocParser. Można to zrobić poprzez parsowanie plików w języku Python, takich jak parse_file.py. Ta operacja musi być wykonana ostrożnie, aby uniknąć błędu w parsowaniu tekstu x.
Metoda 4: Za pomocą narzędzia do analizy tekstu
Narzędzie Parse text służy do wyodrębniania określonych danych ze zmiennych i mapowania ich na inne zmienne. Jest to niezależne od wszelkich innych narzędzi używanych w zadaniu, a narzędzie Platformy BPA służy do wykorzystywania i wyprowadzania zmiennych. Użyj linku podanego tutaj, aby uzyskać dostęp do Parse Text Tool online i skorzystaj z odpowiedzi podanych wcześniej, jak parsować tekst.
Metoda 5: za pośrednictwem TextFieldParser (Visual Basic)
TextFieldParser wykorzystywał obiekty do analizowania i przetwarzania bardzo dużych plików, które są ustrukturyzowane i rozdzielane. W tej metodzie można użyć szerokości i kolumny tekstu, takiego jak pliki dziennika lub informacje o starszej bazie danych. Metoda parsowania jest podobna do iteracji kodu po pliku tekstowym i służy głównie do wyodrębniania pól tekstu, podobnie jak metody manipulacji ciągami. Odbywa się to w celu tokenizacji oddzielonych ciągów i pól o różnych szerokościach przy użyciu zdefiniowanego ogranicznika, takiego jak przecinek lub spacja tabulacji.
Funkcje do analizowania tekstu
Poniższe funkcje mogą służyć do analizowania tekstu w tej metodzie.
- Do zdefiniowania ogranicznika używa się SetDelimiters. Na przykład polecenie testReader.SetDelimiters (vbTab) służy do ustawienia spacji tabulacji jako ogranicznika.
- Aby ustawić szerokość pola na dodatnią wartość całkowitą na stałą szerokość pola plików tekstowych, można użyć polecenia testReader.SetFieldWidths (integer).
- Aby przetestować typ pola tekstu, możesz użyć następującego polecenia testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Metody znajdowania MatchObject
Istnieją dwie podstawowe metody znajdowania MatchObject w kodzie lub przeanalizowanym tekście.
- Pierwsza metoda polega na zdefiniowaniu formatu i pętli pliku przy użyciu metody ReadFields. Ta metoda pomogłaby w przetwarzaniu każdego wiersza kodu.
- Metoda PeekChars służy do indywidualnego sprawdzania każdego pola przed jego odczytaniem, definiowania wielu formatów i reagowania.
W obu przypadkach, jeśli pole nie jest zgodne z określonym formatem podczas wykonywania analizowania lub znajdowania sposobu analizowania tekstu, zwracany jest wyjątek MalformedLineException.
Pro Tip: Jak analizować tekst za pomocą MS Excel
Jako ostateczną i prostą metodę analizowania tekstu możesz użyć MS Excel aplikacja jako parser do tworzenia plików rozdzielanych tabulatorami i rozdzielanych przecinkami. Pomogłoby to w sprawdzeniu krzyżowym z przeanalizowanym wynikiem i pomogłoby w znalezieniu sposobu naprawienia błędu parsowania.
1. Wybierz wartości danych w pliku źródłowym i naciśnij jednocześnie klawisze Ctrl + C, aby skopiować plik.
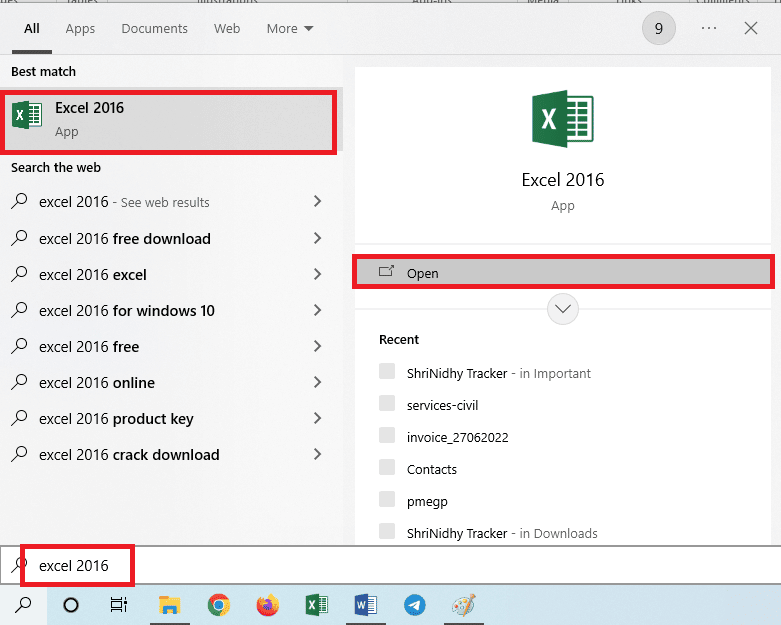
2. Otwórz aplikację Excel za pomocą paska wyszukiwania systemu Windows.
3. Kliknij komórkę A1 i naciśnij jednocześnie klawisze Ctrl + V, aby wkleić skopiowany tekst.
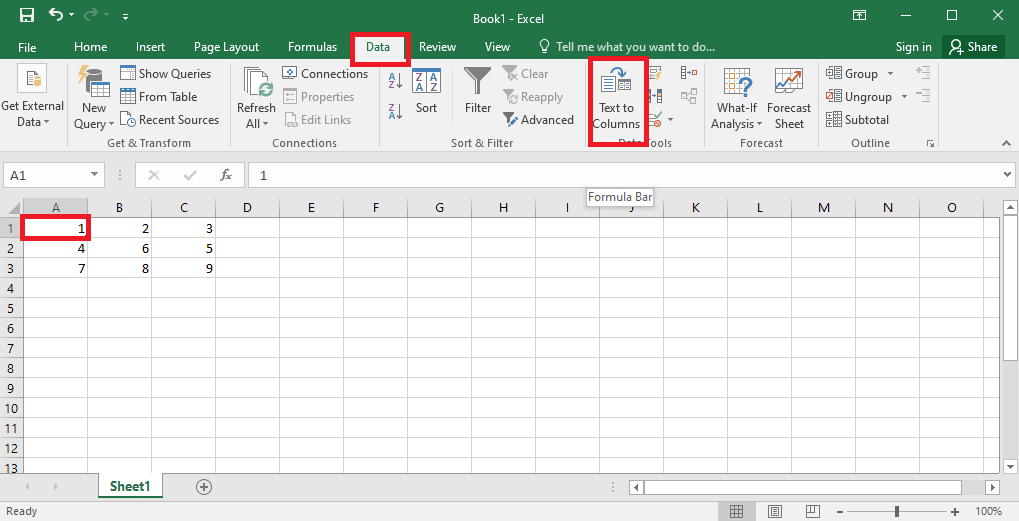
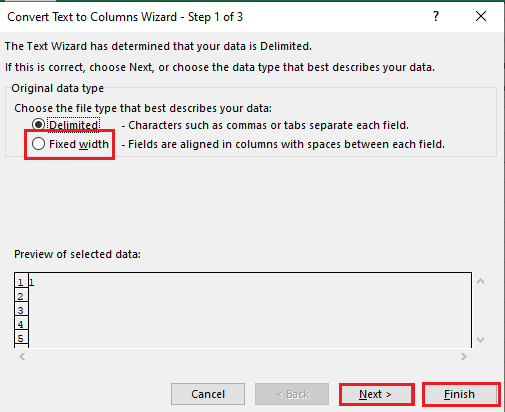
4. Wybierz komórkę A1, przejdź do karty Dane i kliknij opcję Tekst do kolumn w sekcji Narzędzia danych.
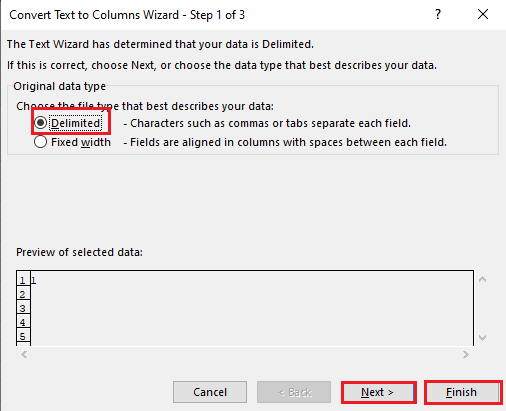
5A. Wybierz opcję Rozdzielone, jeśli jako separatora jest używany przecinek lub spacja, a następnie kliknij przyciski Dalej i Zakończ.
5B. Wybierz opcję Stała szerokość, przypisz wartość separatora i kliknij przyciski Dalej i Zakończ.
Jak naprawić błąd analizy?
Błąd w parsowaniu tekstu x może wystąpić na urządzeniach z Androidem, ponieważ Parse Error: Wystąpił problem z analizowaniem pakietu. Zwykle dzieje się tak, gdy nie można zainstalować aplikacji ze Sklepu Google Play lub podczas uruchamiania aplikacji innej firmy.
Tekst błędu x może wystąpić, jeśli lista wektorów znaków jest zapętlona, a inne funkcje tworzą model liniowy do obliczania wartości danych. Komunikat o błędzie to Błąd w analizie (text = x, keep.source = FALSE):
Możesz przeczytać artykuł o tym, jak naprawić błąd analizy w systemie Android, aby poznać przyczyny i metody naprawy błędu.
Oprócz rozwiązań w przewodniku możesz wypróbować następujące poprawki.
- Ponowne pobranie pliku .apk lub przywrócenie nazwy pliku.
- Przywracanie zmian w pliku Androidmanifest.xml, jeśli masz umiejętności programowania na poziomie eksperta.
***
Artykuł pomaga w nauce parsowania tekstu i naprawiania błędów parsowania. Daj nam znać, która metoda pomogła naprawić błąd w parsowaniu tekstu x i która metoda parsowania jest preferowana. Podziel się swoimi sugestiami i pytaniami w sekcji komentarzy poniżej.