

Polecenie Linux uniq przegląda pliki tekstowe w poszukiwaniu unikalnych lub zduplikowanych linii. W tym przewodniku omówimy jego wszechstronność i funkcje, a także sposób, w jaki można najlepiej wykorzystać to sprytne narzędzie.
Spis treści:
Znajdowanie pasujących wierszy tekstu w systemie Linux
Polecenie uniq to szybkie, elastyczne i świetne w tym, co robi. Jednak, podobnie jak wiele poleceń Linuksa, ma kilka dziwactw – co jest w porządku, o ile o nich wiesz. Jeśli podejmiesz taką decyzję bez odrobiny wewnętrznej wiedzy, możesz równie dobrze drapać się po głowie po wynikach. Po drodze zwrócimy uwagę na te dziwactwa.
Polecenie uniq jest idealne dla tych, którzy są jednomyślni i mają na celu zrobienie jednej rzeczy i zrobienie tego dobrze. Dlatego jest również szczególnie dobrze przystosowany do pracy z rurami i odgrywania swojej roli w potokach dowodzenia. Jeden z jego najczęściej współpracujący jest sortowane, ponieważ uniq musi mieć posortowane dane wejściowe, na których ma pracować.
Odpalmy to!
Uruchamianie uniq bez opcji
Mamy plik tekstowy zawierający teksty do Roberta Johnsona piosenka Wierzę, że odkurzę moją miotłę. Zobaczmy, co robi z tego uniq.
Napiszemy co następuje, aby potokować wyjście do less:
uniq dust-my-broom.txt | less

Otrzymujemy całą piosenkę, w tym zduplikowane linie, w mniej:
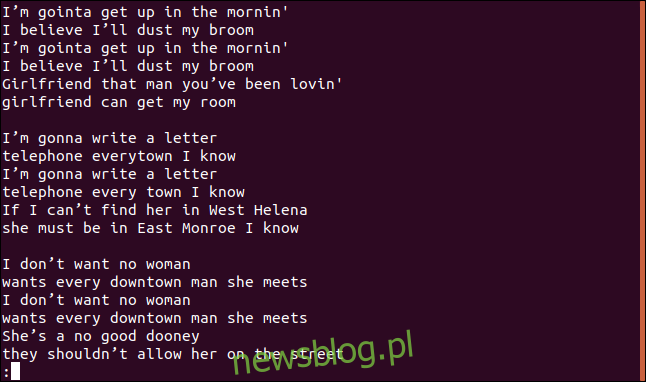
To nie wydają się być ani unikalnymi liniami, ani zduplikowanymi liniami.
Racja – ponieważ jest to pierwsze dziwactwo. Jeśli uruchomisz uniq bez opcji, zachowuje się tak, jakbyś użył opcji -u (unikalne linie). Mówi to uniq, by wypisał tylko unikalne linie z pliku. Powodem, dla którego widzisz zduplikowane linie, jest to, że aby uniq uznał linię za zduplikowaną, musi ona sąsiadować z jej duplikatem, i właśnie wtedy pojawia się sort.
Kiedy sortujemy plik, grupuje on zduplikowane linie, a uniq traktuje je jako duplikaty. Użyjemy sortowania na pliku, posortowane dane wyjściowe potokujemy do uniq, a następnie potokujemy potokiem do less.
Aby to zrobić, wpisujemy:
sort dust-my-broom.txt | uniq | less

Posortowana lista linii pojawia się w less.
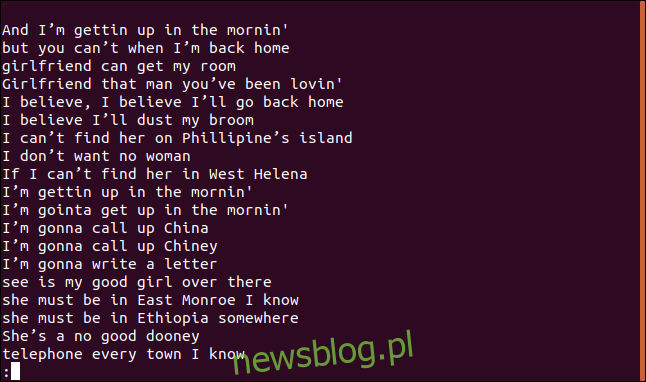
Wiersz „Wierzę, że odkurzę moją miotłę”, zdecydowanie pojawia się w piosence więcej niż raz. W rzeczywistości powtórzyło się to dwukrotnie w pierwszych czterech linijkach piosenki.
Dlaczego więc pojawia się na liście unikalnych linii? Ponieważ pierwsza linia pojawia się w pliku, jest unikalna; tylko kolejne wpisy są duplikatami. Można o tym myśleć jako o pierwszym wystąpieniu każdej unikalnej linii.
Użyjmy ponownie sortowania i przekierujmy wyjście do nowego pliku. W ten sposób nie musimy używać sortowania w każdym poleceniu.
Wpisujemy następujące polecenie:
sort dust-my-broom.txt > sorted.txt
 sort.txt ”w oknie terminala. ’ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
sort.txt ”w oknie terminala. ’ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
Teraz mamy wstępnie posortowany plik do pracy.
Liczenie duplikatów
Możesz użyć opcji -c (liczba), aby wydrukować, ile razy każda linia pojawia się w pliku.
Wpisz następujące polecenie:
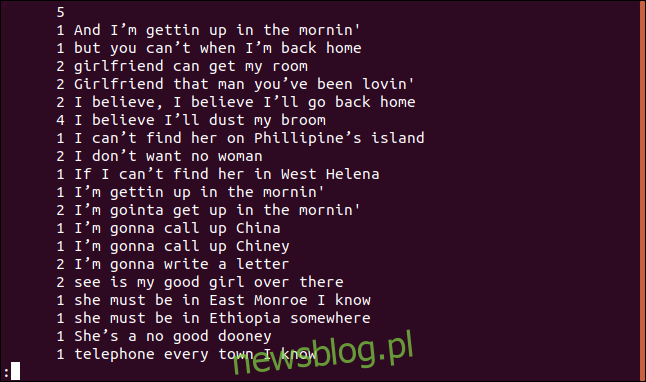
uniq -c sorted.txt | less

Każda linia zaczyna się od tego, ile razy ta linia pojawia się w pliku. Jednak zauważysz, że pierwsza linia jest pusta. Oznacza to, że plik zawiera pięć pustych wierszy.
Jeśli chcesz, aby dane wyjściowe były posortowane w porządku numerycznym, możesz je przesłać z uniq do sortowania. W naszym przykładzie użyjemy opcji -r (odwróć) i -n (sortowanie numeryczne) i potokujemy wyniki do less.
Wpisujemy:
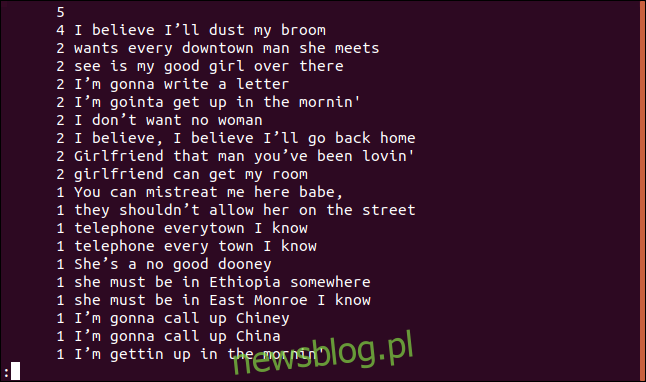
uniq -c sorted.txt | sort -rn | less

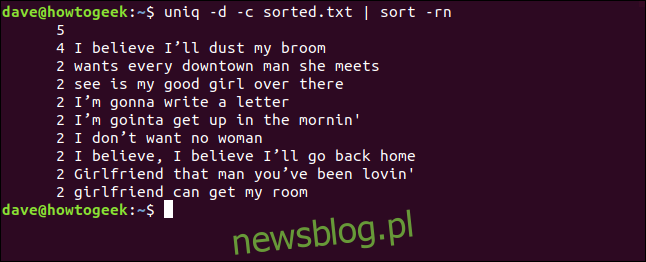
Lista jest posortowana malejąco na podstawie częstotliwości pojawiania się poszczególnych linii.
Wyświetlanie tylko zduplikowanych linii
Jeśli chcesz zobaczyć tylko te wiersze, które są powtarzane w pliku, możesz użyć opcji -d (powtarzane). Bez względu na to, ile razy linia jest powielana w pliku, jest wyświetlana tylko raz.
Aby skorzystać z tej opcji, wpisujemy:
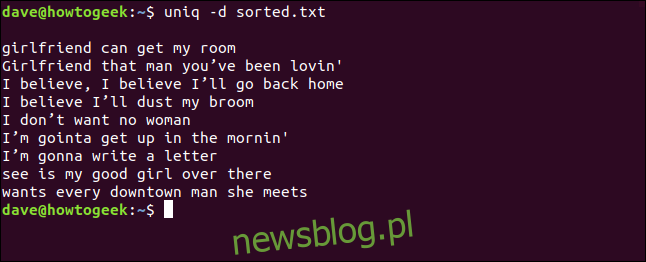
uniq -d sorted.txt

Powielone linie są wymienione dla nas. Zauważysz pustą linię u góry, co oznacza, że plik zawiera zduplikowane puste linie – nie jest to spacja pozostawiona przez uniq, aby kosmetycznie przesunąć listę.
Możemy również łączyć opcje -d (powtarzane) i -c (licznik) i potokować wyjście przez sort. To daje nam posortowaną listę linii, które pojawiają się co najmniej dwukrotnie.
Wpisz następujące informacje, aby użyć tej opcji:
uniq -d -c sorted.txt | sort -rn
Lista wszystkich zduplikowanych linii
Jeśli chcesz zobaczyć listę wszystkich zduplikowanych linii, a także wpis za każdym razem, gdy pojawia się linia w pliku, możesz użyć opcji -D (wszystkie zduplikowane linie).
Aby skorzystać z tej opcji, wpisz:
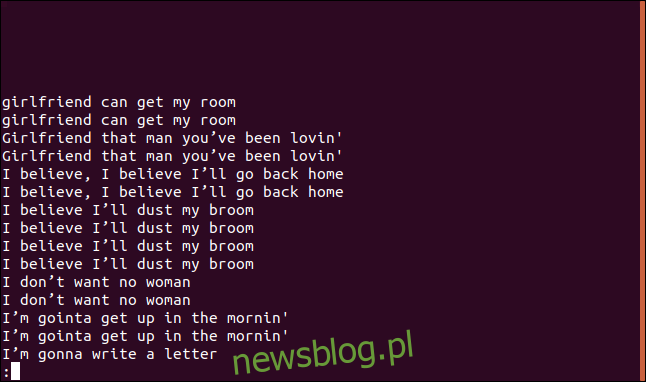
uniq -D sorted.txt | less

Lista zawiera wpis dla każdego zduplikowanego wiersza.
Jeśli użyjesz opcji –group, wypisze ona każdy zduplikowany wiersz z pustą linią przed (dołączanie na początku) lub po każdej grupie (dołączanie) lub zarówno przed, jak i po (obie) każdą grupę.
Używamy append jako naszego modyfikatora, więc wpisujemy:
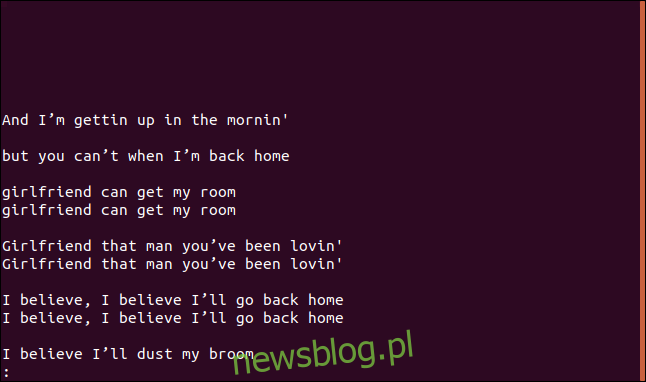
uniq --group=append sorted.txt | less

Grupy są oddzielone pustymi wierszami, aby ułatwić ich czytanie.
Sprawdzanie określonej liczby znaków
Domyślnie uniq sprawdza całą długość każdej linii. Jeśli jednak chcesz ograniczyć sprawdzanie do określonej liczby znaków, możesz użyć opcji -w (sprawdzanie znaków).
W tym przykładzie powtórzymy ostatnie polecenie, ale ograniczymy porównania do pierwszych trzech znaków. Aby to zrobić, wpisujemy następujące polecenie:
uniq -w 3 --group=append sorted.txt | less

Otrzymane wyniki i grupy są zupełnie inne.
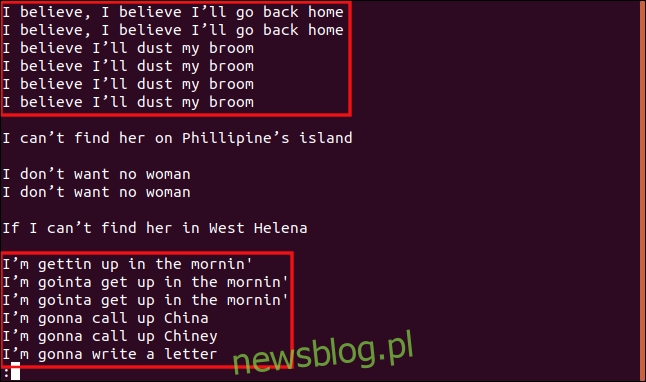
Wszystkie wiersze zaczynające się od „I b” są zgrupowane razem, ponieważ te fragmenty wierszy są identyczne, więc uważa się je za duplikaty.
Podobnie wszystkie wiersze zaczynające się od „Ja” są traktowane jako duplikaty, nawet jeśli reszta tekstu jest inna.
Ignorowanie określonej liczby znaków
W niektórych przypadkach korzystne może być pominięcie określonej liczby znaków na początku każdego wiersza, na przykład gdy wiersze w pliku są numerowane. Lub, powiedzmy, że potrzebujesz uniq, aby przeskoczyć znacznik czasu i zacząć sprawdzać linie od szóstego znaku zamiast od pierwszego znaku.
Poniżej znajduje się wersja naszego posortowanego pliku z ponumerowanymi wierszami.
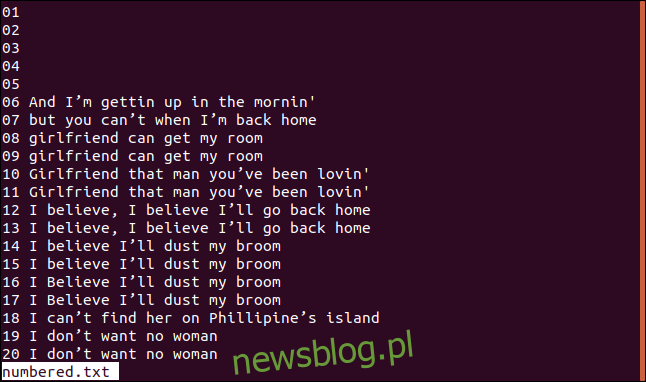
Jeśli chcemy, aby uniq rozpoczynał porównywanie od trzeciego znaku, możemy użyć opcji -s (pomiń znaki), wpisując:
uniq -s 3 -d -c numbered.txt
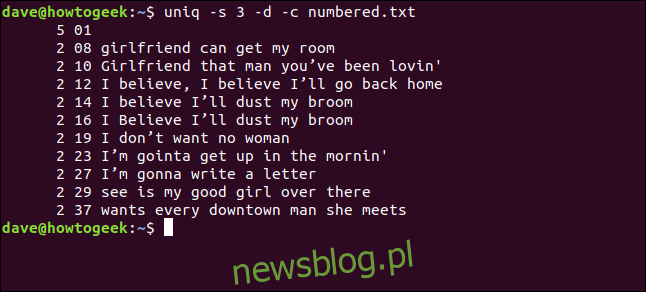
Linie są wykrywane jako duplikaty i poprawnie liczone. Zwróć uwagę, że wyświetlane numery wierszy są numerami pierwszego wystąpienia każdego duplikatu.
Możesz także pominąć pola (ciąg znaków i trochę spacji) zamiast znaków. Użyjemy opcji -f (pola), aby poinformować uniq, które pola mają ignorować.
Wpisujemy następujące polecenie, aby uniq ignorował pierwsze pole:
uniq -f 1 -d -c numbered.txt
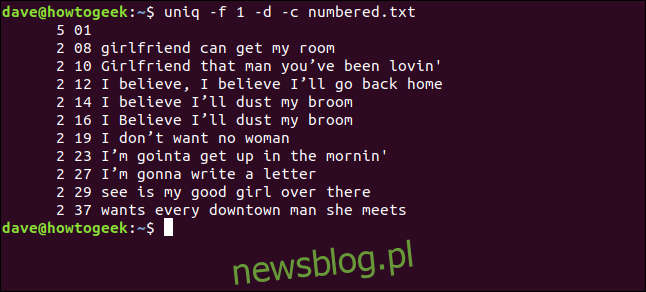
Otrzymujemy te same wyniki, które uzyskaliśmy, gdy powiedzieliśmy uniq, aby pominął trzy znaki na początku każdej linii.
Ignorowanie wielkości liter
Domyślnie uniq rozróżnia wielkość liter. Jeśli ta sama litera pojawia się z wielkimi i małymi literami, uniq uważa, że wiersze są różne.
Na przykład sprawdź dane wyjściowe za pomocą następującego polecenia:
uniq -d -c sorted.txt | sort -rn
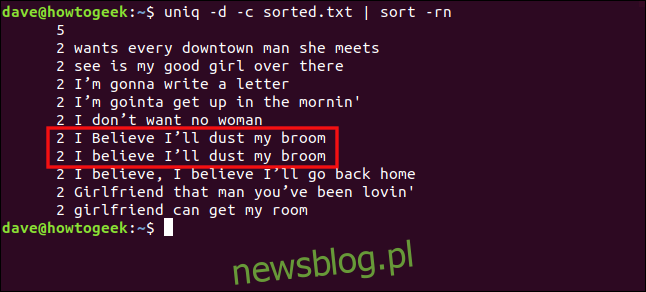
Wiersze „Wierzę, że odkurzę moją miotłę” i „Wierzę, że odkurzę miotłę” nie są traktowane jako duplikaty ze względu na różnicę w wielkości liter na „B” w „wierzyć”.
Jeśli jednak włączymy opcję -i (ignoruj wielkość liter), te wiersze będą traktowane jako duplikaty. Wpisujemy:
uniq -d -c -i sorted.txt | sort -rn
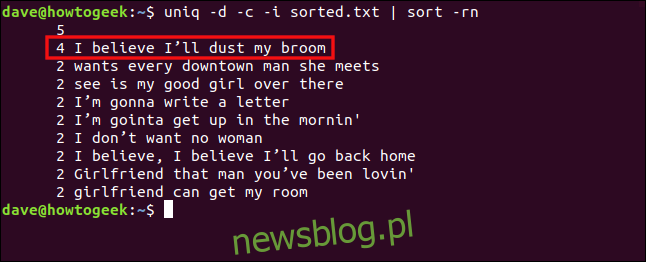
Linie są teraz traktowane jako duplikaty i grupowane razem.
Linux udostępnia Ci wiele specjalnych narzędzi. Podobnie jak wiele z nich, uniq nie jest narzędziem, którego będziesz używać na co dzień.
Dlatego duża część zdobywania biegłości w posługiwaniu się Linuksem polega na pamiętaniu, które narzędzie rozwiąże Twój obecny problem i gdzie możesz je znaleźć ponownie. Jeśli jednak będziesz ćwiczyć, będziesz na dobrej drodze.
Lub zawsze możesz po prostu przeszukać newsblog.pl – prawdopodobnie mamy na ten temat artykuł.