
Dowiedz się wszystkiego, co musisz wiedzieć o eksploracyjnej analizie danych, krytycznym procesie używanym do odkrywania trendów i wzorców oraz podsumowywania zestawów danych za pomocą podsumowań statystycznych i reprezentacji graficznych.
Jak każdy projekt, projekt analizy danych to długi proces, który wymaga czasu, dobrej organizacji i skrupulatnego szacunku dla kilku kroków. Eksploracyjna analiza danych (EDA) jest jednym z najważniejszych etapów tego procesu.
Dlatego w tym artykule pokrótce przyjrzymy się, czym jest eksploracyjna analiza danych i jak można ją przeprowadzić za pomocą R!
Spis treści:
Co to jest eksploracyjna analiza danych?
Eksploracyjna analiza danych bada i bada cechy zestawu danych przed przesłaniem go do aplikacji, czy to wyłącznie biznesowej, statystycznej czy uczącej się maszynowo.
Takie podsumowanie charakteru informacji i ich głównych cech jest zwykle dokonywane za pomocą metod wizualnych, takich jak reprezentacje graficzne i tabele. Praktyka jest przeprowadzana z wyprzedzeniem właśnie w celu oceny potencjału tych danych, które w przyszłości zostaną poddane bardziej złożonemu leczeniu.
Dlatego EDA zezwala na:
- Sformułuj hipotezy dotyczące wykorzystania tych informacji;
- Przeglądaj ukryte szczegóły w strukturze danych;
- Zidentyfikuj brakujące wartości, wartości odstające lub nieprawidłowe zachowania;
- Odkryj trendy i odpowiednie zmienne jako całość;
- Odrzuć nieistotne zmienne lub zmienne skorelowane z innymi;
- Określ modelowanie formalne, które ma zostać użyte.
Jaka jest różnica między opisową a eksploracyjną analizą danych?
Istnieją dwa rodzaje analizy danych, analiza opisowa i eksploracyjna analiza danych, które idą ze sobą w parze, pomimo różnych celów.
Podczas gdy pierwsza koncentruje się na opisie zachowania zmiennych, na przykład średniej, mediany, trybu itp.
Analiza eksploracyjna ma na celu zidentyfikowanie relacji między zmiennymi, wyodrębnienie wstępnych spostrzeżeń i skierowanie modelowania do najczęstszych paradygmatów uczenia maszynowego: klasyfikacji, regresji i grupowania.
Wspólnie oba mogą zajmować się reprezentacją graficzną; jednak tylko analiza eksploracyjna ma na celu dostarczenie praktycznych spostrzeżeń, to znaczy spostrzeżeń, które prowokują do działania decydenta.
Wreszcie, podczas gdy eksploracyjna analiza danych ma na celu rozwiązywanie problemów i dostarczanie rozwiązań, które pokierują etapami modelowania, analiza opisowa, jak sugeruje jej nazwa, ma na celu jedynie stworzenie szczegółowego opisu danego zestawu danych.
Analiza opisowa Eksploracyjna analiza danychAnalizuje zachowanieAnaliza zachowania i relacjeZapewnia podsumowanie Prowadzi do specyfikacji i działańOrganizuje dane w tabelach i na wykresachPorządkuje dane w tabelach i na wykresachNie ma znaczącej mocy wyjaśniającejMa znaczącą moc wyjaśniającą
Kilka praktycznych zastosowań EDA
#1. Marketing cyfrowy
Marketing cyfrowy ewoluował od procesu kreatywnego do procesu opartego na danych. Organizacje marketingowe wykorzystują eksploracyjną analizę danych do określania wyników kampanii lub działań oraz do kierowania inwestycjami konsumentów i decyzjami dotyczącymi kierowania.
Badania demograficzne, segmentacja klientów i inne techniki pozwalają marketerom wykorzystywać duże ilości danych dotyczących zakupów konsumenckich, ankiet i paneli w celu zrozumienia i komunikowania strategii marketingowej.
Analityka eksploracyjna sieci pozwala marketerom zbierać informacje na poziomie sesji o interakcjach w witrynie. Google Analytics to przykład bezpłatnego i popularnego narzędzia analitycznego, z którego korzystają w tym celu marketerzy.
Techniki eksploracyjne często stosowane w marketingu obejmują modelowanie marketingu mix, analizy cen i promocji, optymalizację sprzedaży oraz eksploracyjną analizę klientów, np. segmentację.
#2. Eksploracyjna analiza portfela
Powszechnym zastosowaniem eksploracyjnej analizy danych jest eksploracyjna analiza portfelowa. Bank lub agencja pożyczkowa ma zbiór rachunków o różnej wartości i ryzyku.
Konta mogą się różnić w zależności od statusu społecznego posiadacza (bogaty, klasa średnia, biedny itp.), położenia geograficznego, wartości netto i wielu innych czynników. Pożyczkodawca musi zrównoważyć zwrot z pożyczki z ryzykiem niewykonania zobowiązania dla każdej pożyczki. Powstaje zatem pytanie, jak wycenić portfel jako całość.
Pożyczka o najniższym ryzyku może być dla osób bardzo zamożnych, ale liczba osób zamożnych jest bardzo ograniczona. Z drugiej strony wielu biednych ludzi może pożyczać, ale naraża się to na większe ryzyko.
Rozwiązanie do eksploracyjnej analizy danych może łączyć analizę szeregów czasowych z wieloma innymi problemami, aby zdecydować, kiedy pożyczyć pieniądze tym różnym segmentom pożyczkobiorców lub oprocentować pożyczkę. Od członków segmentu portfela naliczane są odsetki na pokrycie strat wśród członków tego segmentu.
#3. Eksploracyjna analiza ryzyka
Modele predykcyjne w bankowości są opracowywane w celu zapewnienia pewności co do oceny ryzyka dla klientów indywidualnych. Oceny kredytowe mają na celu przewidzenie przestępczego zachowania danej osoby i są szeroko stosowane do oceny zdolności kredytowej każdego wnioskodawcy.
Ponadto w świecie nauki i branży ubezpieczeniowej przeprowadzana jest analiza ryzyka. Jest również szeroko stosowany w instytucjach finansowych, takich jak firmy obsługujące płatności online, do analizowania, czy transakcja jest oryginalna czy oszukańcza.
W tym celu wykorzystują historię transakcji klienta. Jest częściej używany przy zakupach kartą kredytową; w przypadku nagłego wzrostu wolumenu transakcji klienta, klient otrzymuje połączenie z potwierdzeniem, czy zainicjował transakcję. Pomaga również zmniejszyć straty spowodowane takimi okolicznościami.
Eksploracyjna analiza danych z R
Pierwszą rzeczą, którą musisz wykonać EDA z R, jest pobranie R base i R Studio (IDE), a następnie zainstalowanie i załadowanie następujących pakietów:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
W tym samouczku użyjemy zestawu danych ekonomicznych, który jest wbudowany w R i dostarcza rocznych wskaźników ekonomicznych dotyczących gospodarki USA, a dla uproszczenia zmienimy jego nazwę na econ:
econ <- ggplot2::economics
Do wykonania analizy opisowej posłużymy się pakietem skimr, który w prosty i dobrze przedstawiony sposób oblicza te statystyki:
#Descriptive Analysis skimr::skim(econ)

Możesz również użyć funkcji podsumowującej do analizy opisowej:
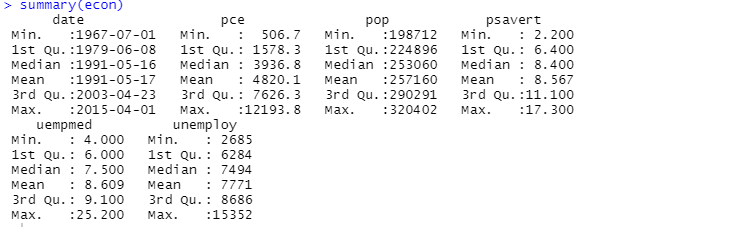
Tutaj analiza opisowa pokazuje 547 wierszy i 6 kolumn w zestawie danych. Minimalna wartość to 1967-07-01, a maksymalna to 2015-04-01. Podobnie pokazuje również wartość średnią i odchylenie standardowe.
Teraz masz podstawowe pojęcie o tym, co znajduje się w zbiorze danych econ. Narysujmy histogram zmiennej, aby lepiej przyjrzeć się danym:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
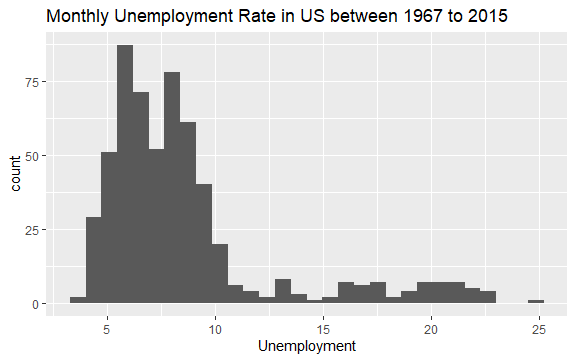
Rozkład histogramu pokazuje, że ma wydłużony ogon po prawej stronie; oznacza to, że prawdopodobnie istnieje kilka obserwacji tej zmiennej o bardziej „ekstremalnych” wartościach. Powstaje pytanie: w jakim okresie miały miejsce te wartości i jaki jest trend zmiennej?
Najbardziej bezpośrednim sposobem identyfikacji trendu zmiennej jest wykres liniowy. Poniżej generujemy wykres liniowy i dodajemy linię wygładzającą:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
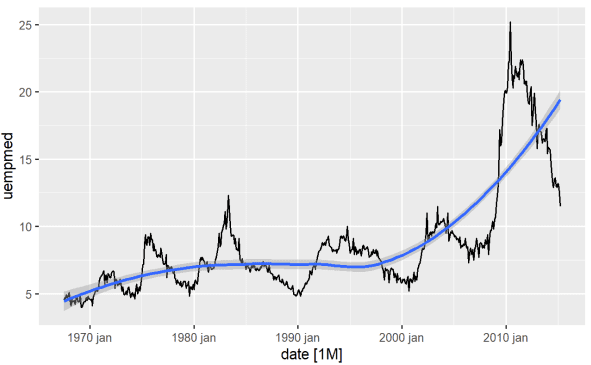
Korzystając z tego wykresu, możemy stwierdzić, że w ostatnim okresie, w ostatnich obserwacjach z 2010 roku, istnieje tendencja do wzrostu bezrobocia, przewyższająca historię obserwowaną w poprzednich dekadach.
Innym ważnym punktem, zwłaszcza w kontekstach modelowania ekonometrycznego, jest stacjonarność serii; czyli czy średnia i wariancja są stałe w czasie?
Gdy te założenia nie są prawdziwe dla zmiennej, mówimy, że szereg ma pierwiastek jednostkowy (niestacjonarny), aby szoki, na które cierpi zmienna, generowały trwały efekt.
Wydaje się, że tak było w przypadku omawianej zmiennej – czasu pozostawania bez pracy. Widzieliśmy, że wahania zmiennej znacznie się zmieniły, co ma silne implikacje związane z teoriami ekonomicznymi dotyczącymi cykli. Ale odchodząc od teorii, jak praktycznie sprawdzić, czy zmienna jest stacjonarna?
Pakiet prognozy posiada doskonałą funkcję pozwalającą na zastosowanie testów, takich jak ADF, KPSS i innych, które już zwracają liczbę różnic niezbędną do stacjonarności szeregu:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Tutaj wartość p większa niż 0,05 pokazuje, że dane są niestacjonarne.
Kolejną ważną kwestią w szeregach czasowych jest identyfikacja możliwych korelacji (zależność liniowa) między opóźnionymi wartościami szeregu. W jego identyfikacji pomagają korelogramy ACF i PACF.
Ponieważ szereg nie ma sezonowości, ale ma pewien trend, początkowe autokorelacje są zwykle duże i dodatnie, ponieważ obserwacje bliskie w czasie mają również zbliżoną wartość.
W związku z tym funkcja autokorelacji (ACF) trendowanych szeregów czasowych ma zwykle wartości dodatnie, które powoli maleją wraz ze wzrostem opóźnień.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
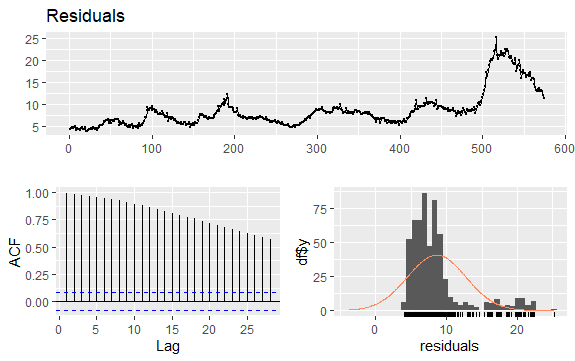
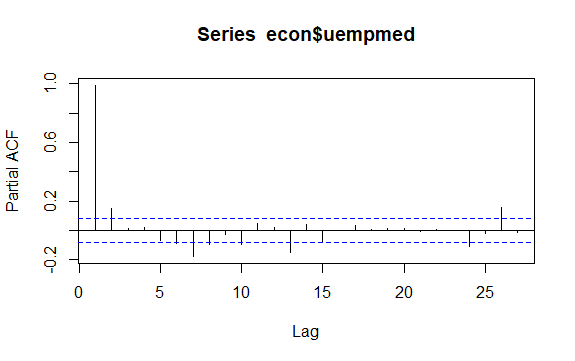
Wniosek
Kiedy dostajemy w swoje ręce dane, które są mniej lub bardziej czyste, to znaczy już oczyszczone, od razu pojawia się pokusa, by zagłębić się w etap budowy modelu, aby wyciągnąć pierwsze wyniki. Musisz oprzeć się tej pokusie i zacząć przeprowadzać eksploracyjną analizę danych, która jest prosta, a jednocześnie pomaga nam uzyskać w danych potężny wgląd.
Możesz również zapoznać się z najlepszymi zasobami, aby poznać statystyki dotyczące nauki o danych.