
W dzisiejszym świecie opartym na danych tradycyjna metoda ręcznego zbierania danych jest przestarzała. Komputer z łączem internetowym na każdym biurku sprawił, że sieć stała się ogromnym źródłem danych. Dlatego bardziej wydajną i oszczędzającą czas nowoczesną metodą zbierania danych jest web scraping. A jeśli chodzi o skrobanie sieci, Python ma narzędzie o nazwie Beautiful Soup. W tym poście przeprowadzę Cię przez etapy instalacji Beautiful Soup, aby rozpocząć skrobanie sieci.
Przed zainstalowaniem i rozpoczęciem pracy z Beautiful Soup dowiedzmy się, dlaczego warto to zrobić.
Spis treści:
Co to jest piękna zupa?
Załóżmy, że badasz „Wpływ COVID na zdrowie ludzi” i znalazłeś kilka stron internetowych zawierających odpowiednie dane. Ale co, jeśli nie oferują opcji pobierania jednym kliknięciem, aby pożyczyć swoje dane? Do gry wkracza Piękna Zupa.
Beautiful Soup jest jednym z indeksów bibliotek Pythona służących do pobierania danych z docelowych witryn. Wygodniej jest pobierać dane ze stron HTML lub XML.
Leonard Richardson przedstawił pomysł Pięknej Zupy do zeskrobywania sieci w 2004 roku. Ale jego wkład w projekt trwa do dziś. Z dumą aktualizuje każdą nową wersję Beautiful Soup na swoim koncie na Twitterze.
Chociaż Beautiful Soup do web scrapingu został opracowany przy użyciu Pythona 3.8, działa doskonale zarówno z Pythonem 3, jak i Pythonem 2.4.
Często strony internetowe używają ochrony captcha, aby ratować swoje dane przed narzędziami sztucznej inteligencji. W takim przypadku kilka zmian w nagłówku „user-agent” w Beautiful Soup lub użycie API do rozwiązywania captcha może naśladować niezawodną przeglądarkę i oszukać narzędzie do wykrywania.
Jeśli jednak nie masz czasu na odkrywanie Beautiful Soup lub chcesz, aby skrobanie odbywało się wydajnie i swobodnie, nie powinieneś przegapić tego interfejsu API do skrobania stron internetowych, w którym możesz po prostu podać adres URL i pobrać dane Twoje ręce.
Jeśli jesteś już programistą, użycie Beautiful Soup do skrobania nie będzie zniechęcające ze względu na jego prostą składnię w poruszaniu się po stronach internetowych i wydobywaniu pożądanych danych na podstawie analizy warunkowej. Jednocześnie jest również przyjazny dla początkujących.
Chociaż Beautiful Soup nie służy do zaawansowanego skrobania, najlepiej sprawdza się zeskrobywanie danych z plików zapisanych w językach znaczników.
Przejrzysta i szczegółowa dokumentacja to kolejny punkt, który zdobyła Beautiful Soup.
Znajdźmy łatwy sposób na uzyskanie pięknej zupy w Twojej maszynie.
Jak zainstalować Beautiful Soup do skrobania stron internetowych?
Pip – bezproblemowy menedżer pakietów Pythona opracowany w 2008 roku jest obecnie standardowym narzędziem wśród programistów do instalowania dowolnych bibliotek lub zależności Pythona.
Pip jest domyślnie instalowany z najnowszymi wersjami Pythona. Tak więc, jeśli masz zainstalowane jakieś najnowsze wersje Pythona w swoim systemie, możesz zacząć.
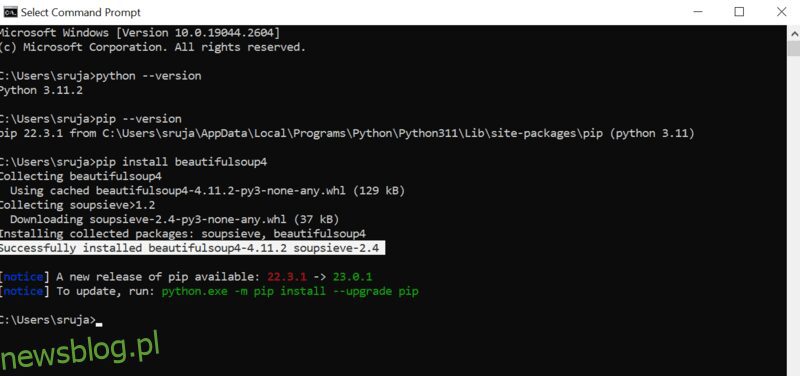
Otwórz wiersz polecenia i wpisz następujące polecenie pip, aby natychmiast zainstalować piękną zupę.
pip install beautifulsoup4
Na ekranie zobaczysz coś podobnego do poniższego zrzutu ekranu.
Upewnij się, że instalator PIP został zaktualizowany do najnowszej wersji, aby uniknąć typowych błędów.
Polecenie aktualizacji instalatora pip do najnowszej wersji to:
pip install --upgrade pip
W tym poście z powodzeniem omówiliśmy połowę terenu.
Teraz masz zainstalowaną piękną zupę na swoim komputerze, więc przyjrzyjmy się, jak używać jej do skrobania sieci.
Jak importować i pracować z piękną zupą do skrobania stron internetowych?
Wpisz następujące polecenie w IDE Pythona, aby zaimportować piękną Soup do bieżącego skryptu Pythona.
from bs4 import BeautifulSoup
Teraz Beautiful Soup jest w twoim pliku Pythona do użycia do skrobania.
Spójrzmy na przykład kodu, aby dowiedzieć się, jak wyodrębnić żądane dane za pomocą pięknej Soup.
Możemy powiedzieć pięknej Soup, aby wyszukała określone tagi HTML w witrynie źródłowej i zeskrobała dane obecne w tych tagach.
W tym artykule będę korzystał z marketwatch.com, który aktualizuje ceny akcji różnych firm w czasie rzeczywistym. Wyciągnijmy trochę danych z tej witryny, aby zapoznać się z biblioteką Pięknej Zupy.
Zaimportuj pakiet „requests”, który pozwoli nam odbierać i odpowiadać na żądania HTTP oraz „urllib”, aby załadować stronę internetową z jej adresu URL.
from urllib.request import urlopen import requests
Zapisz link do strony internetowej w zmiennej, aby mieć do niego łatwy dostęp później.
url="https://www.marketwatch.com/investing/stock/amzn"
Kolejnym byłoby użycie metody „urlopen” z biblioteki „urllib” do przechowywania strony HTML w zmiennej. Przekaż adres URL do funkcji „urlopen” i zapisz wynik w zmiennej.
page = urlopen(url)
Utwórz obiekt Beautiful Soup i przeanalizuj żądaną stronę internetową za pomocą „html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Teraz cały skrypt HTML docelowej strony internetowej jest przechowywany w zmiennej „soup_obj”.
Zanim przejdziemy dalej, spójrzmy na kod źródłowy docelowej strony, aby dowiedzieć się więcej o skrypcie HTML i tagach.
Kliknij prawym przyciskiem myszy dowolne miejsce na stronie internetowej za pomocą myszy. Następnie znajdziesz opcję sprawdzania, jak pokazano poniżej.
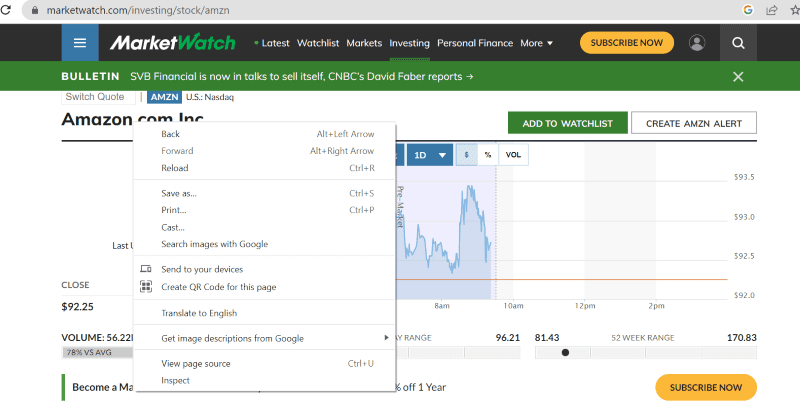
Kliknij sprawdź, aby wyświetlić kod źródłowy.
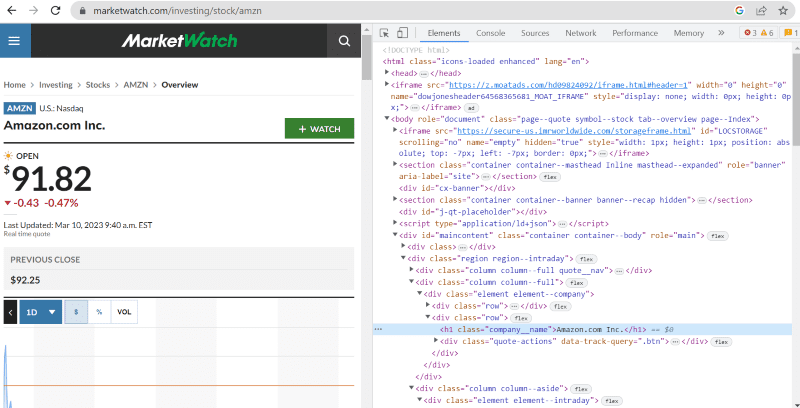
W powyższym kodzie źródłowym można znaleźć tagi, klasy oraz bardziej szczegółowe informacje o każdym elemencie widocznym w interfejsie serwisu.
Metoda „znajdź” w beautiful Soup pozwala nam wyszukiwać żądane tagi HTML i pobierać dane. W tym celu nadajemy nazwę klasy i znaczniki metodzie, która wyodrębnia określone dane.
Na przykład „Amazon.com Inc.” pokazana na stronie internetowej ma nazwę klasy: „company__name” oznaczoną jako „h1”. Możemy wprowadzić te informacje do metody „znajdź”, aby wyodrębnić odpowiedni fragment kodu HTML do zmiennej.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Wypiszmy skrypt HTML przechowywany w zmiennej „nazwa” i wymagany tekst na ekranie.
print(name) print(name.text)

Możesz być świadkiem wydrukowania wyodrębnionych danych na ekranie.
Web Zeskrobać witrynę IMDb
Wielu z nas szuka ocen filmów na stronie IMBb przed obejrzeniem filmu. Ta demonstracja da ci listę najwyżej ocenianych filmów i pomoże ci przyzwyczaić się do pięknej zupy do skrobania sieci.
Krok 1: Zaimportuj piękne biblioteki Soup i żądań.
from bs4 import BeautifulSoup import requests
Krok 2: Przypiszmy adres URL, który chcemy zeskrobać, do zmiennej o nazwie „url”, aby ułatwić dostęp w kodzie.
Pakiet „requests” służy do pobierania strony HTML z adresu URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Krok 3: W poniższym fragmencie kodu przeanalizujemy stronę HTML bieżącego adresu URL, aby utworzyć obiekt pięknej zupy.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Zmienna „soup_obj” zawiera teraz cały skrypt HTML żądanej strony internetowej, jak na poniższym obrazku.
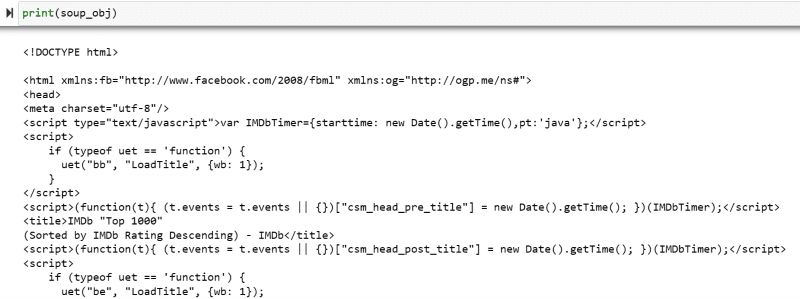
Sprawdźmy kod źródłowy strony internetowej, aby znaleźć skrypt HTML danych, które chcemy zeskrobać.
Najedź kursorem na element strony internetowej, który chcesz wyodrębnić. Następnie kliknij go prawym przyciskiem myszy i przejdź do opcji sprawdzania, aby wyświetlić kod źródłowy tego konkretnego elementu. Poniższe wizualizacje poprowadzą Cię lepiej.
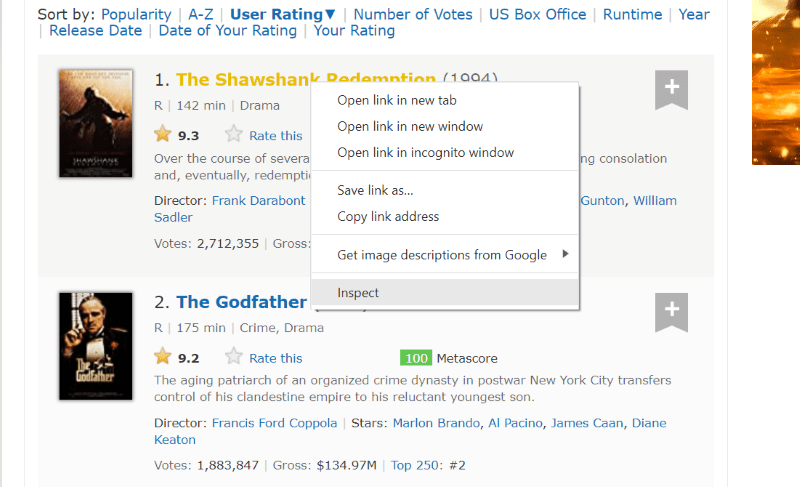
Klasa „lister-list” zawiera wszystkie najwyżej oceniane dane związane z filmami jako podpodziały w kolejnych znacznikach div.
W skrypcie HTML każdej karty filmu, w klasie „lister-item mode-advanced” znajduje się znacznik „h3”, który przechowuje nazwę filmu, rangę i rok wydania, jak pokazano na poniższym obrazku.
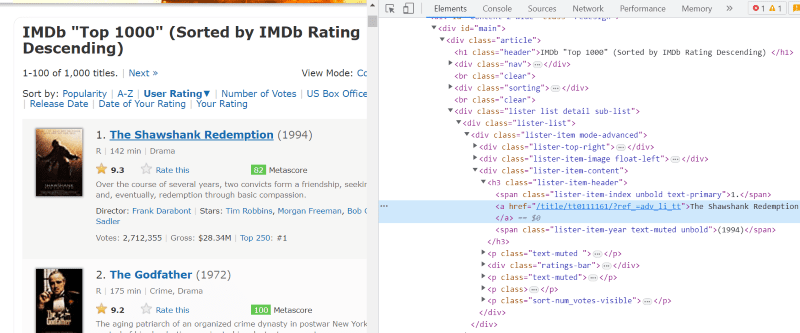
Uwaga: Metoda „znajdź” w pięknym Soup wyszukuje pierwszy znacznik pasujący do nadanej mu nazwy wejściowej. W przeciwieństwie do „find”, metoda „find_all” szuka wszystkich tagów pasujących do podanego wejścia.
Krok 4: Możesz użyć metod „find” i „find_all”, aby zapisać skrypt HTML zawierający nazwę, rangę i rok każdego filmu w zmiennej listy.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
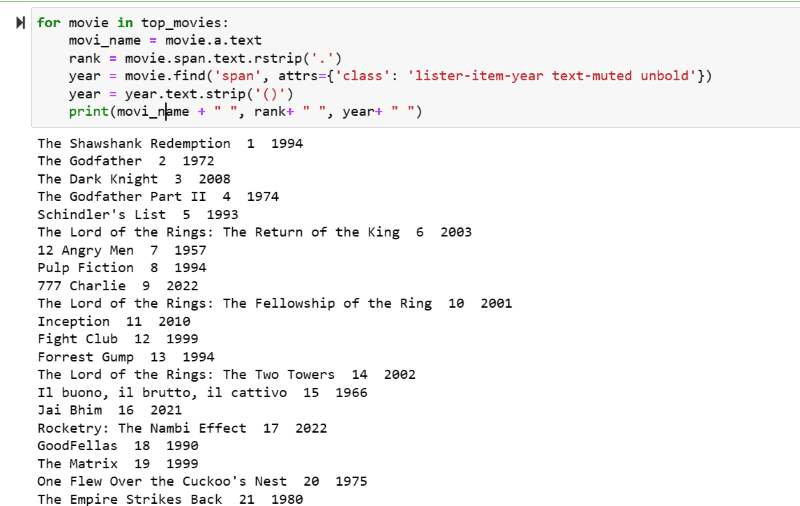
Krok 5: Przejrzyj listę filmów przechowywanych w zmiennej: „top_movies” i wyodrębnij nazwę, rangę i rok każdego filmu w formacie tekstowym ze skryptu HTML, używając poniższego kodu.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Na zrzucie ekranu wyjściowego możesz zobaczyć listę filmów z ich nazwą, rangą i rokiem wydania.
Możesz bez wysiłku przenieść wydrukowane dane do arkusza programu Excel z kodem Pythona i użyć go do analizy.
Ostatnie słowa
Ten post poprowadzi Cię przez instalację pięknej zupy do skrobania stron internetowych. Ponadto przykłady skrobania, które pokazałem, powinny pomóc Ci rozpocząć pracę z piękną zupą.
Ponieważ jesteś zainteresowany tym, jak zainstalować Beautiful Soup do web scrapingu, gorąco polecam zapoznanie się z tym zrozumiałym przewodnikiem, aby dowiedzieć się więcej o web scrapingu za pomocą Pythona.