
Masz tajemniczy plik? Polecenie pliku w systemie Linux szybko powie ci, jaki to jest typ pliku. Jeśli jest to plik binarny, możesz dowiedzieć się o nim jeszcze więcej. plik ma całą masę kolegów w stajni, które pomogą ci go przeanalizować. Pokażemy Ci, jak korzystać z niektórych z tych narzędzi.
Spis treści:
Identyfikowanie typów plików
Pliki zwykle mają cechy, które pozwalają pakietom oprogramowania zidentyfikować typ pliku, a także jakie dane w nim reprezentują. Nie miałoby sensu otwieranie pliku PNG w odtwarzaczu MP3, więc jest zarówno przydatne, jak i pragmatyczne, aby plik zawierał jakąś formę identyfikatora.
Może to być kilka bajtów podpisu na samym początku pliku. Dzięki temu plik może wyraźnie określić jego format i zawartość. Czasami typ pliku jest wywnioskowany z charakterystycznego aspektu wewnętrznej organizacji samych danych, znanego jako architektura pliku.
Niektóre systemy operacyjne, takie jak Windows, całkowicie kierują się rozszerzeniem pliku. Możesz nazwać to łatwowiernym lub zaufanym, ale system Windows zakłada, że każdy plik z rozszerzeniem DOCX naprawdę jest plikiem edytora tekstu DOCX. Linux nie jest taki, jak wkrótce się przekonasz. Chce dowodu i zagląda do pliku, aby go znaleźć.
Opisane tutaj narzędzia zostały już zainstalowane w dystrybucjach Manjaro 20, Fedora 21 i Ubuntu 20.04, których użyliśmy do zbadania tego artykułu. Zacznijmy nasze dochodzenie od użycia polecenie pliku.
Korzystanie z pliku Command
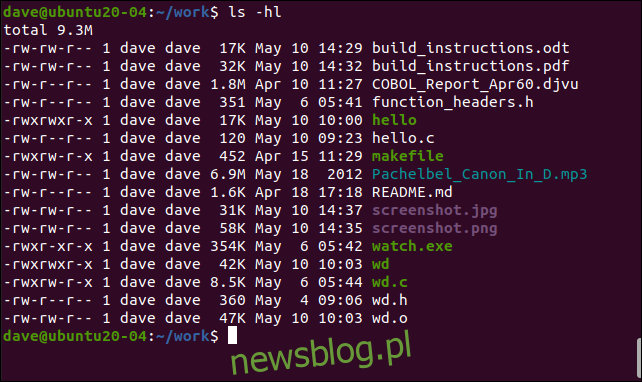
W naszym bieżącym katalogu mamy kolekcję różnych typów plików. Są połączeniem dokumentów, kodu źródłowego, plików wykonywalnych i plików tekstowych.
Polecenie ls pokaże nam, co jest w katalogu, a opcja -hl (rozmiary czytelne dla człowieka, długie listy) pokaże nam rozmiar każdego pliku:
ls -hl
Wypróbujmy kilka z nich i zobaczmy, co otrzymamy:
file build_instructions.odt
file build_instructions.pdf
file COBOL_Report_Apr60.djvu
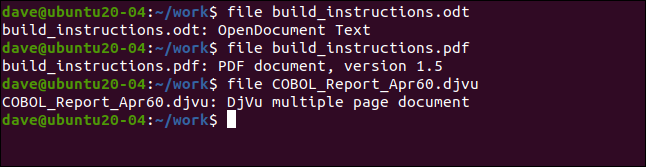
Trzy formaty plików są poprawnie zidentyfikowane. Tam, gdzie to możliwe, plik daje nam nieco więcej informacji. Zgłoszono, że plik PDF znajduje się w formacie w wersji 1.5.
Nawet jeśli zmienimy nazwę pliku ODT tak, aby miał rozszerzenie z dowolną wartością XYZ, plik jest nadal poprawnie identyfikowany, zarówno w przeglądarce plików, jak iw wierszu poleceń za pomocą pliku.
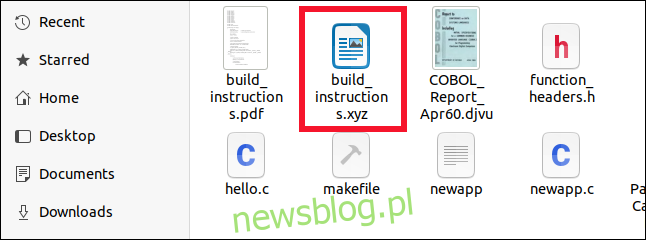
W przeglądarce plików ma odpowiednią ikonę. W wierszu poleceń plik ignoruje rozszerzenie i zagląda do pliku, aby określić jego typ:
file build_instructions.xyz

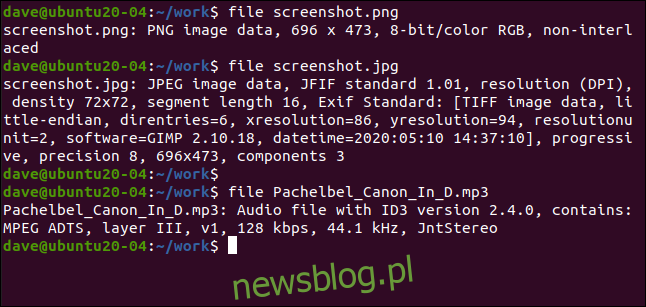
Korzystanie z plików na mediach, takich jak pliki graficzne i muzyczne, zwykle dostarcza informacji dotyczących ich formatu, kodowania, rozdzielczości itd .:
file screenshot.png
file screenshot.jpg
file Pachelbel_Canon_In_D.mp3
Co ciekawe, nawet w przypadku plików tekstowych plik nie ocenia pliku po jego rozszerzeniu. Na przykład, jeśli masz plik z rozszerzeniem „.c”, zawierający standardowy zwykły tekst, ale nie kod źródłowy, plik nie pomyli go z oryginalnym C plik kodu źródłowego:
file function+headers.h
file makefile
file hello.c
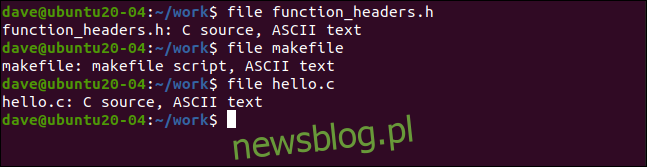
file poprawnie identyfikuje plik nagłówkowy („.h”) jako część zbioru plików z kodem źródłowym C i wie, że makefile jest skryptem.
Używanie pliku z plikami binarnymi
Pliki binarne są bardziej „czarną skrzynką” niż inne. Pliki graficzne można przeglądać, odtwarzać pliki dźwiękowe, a pliki dokumentów można otwierać za pomocą odpowiedniego pakietu oprogramowania. Jednak pliki binarne są większym wyzwaniem.
Na przykład pliki „hello” i „wd” to binarne pliki wykonywalne. To są programy. Plik o nazwie „wd.o” jest plikiem obiektowym. Gdy kod źródłowy jest kompilowany przez kompilator, tworzony jest jeden lub więcej plików obiektowych. Zawierają one kod maszynowy, który komputer ostatecznie wykona po uruchomieniu gotowego programu, wraz z informacjami dla konsolidatora. Konsolidator sprawdza każdy plik obiektowy pod kątem wywołań funkcji do bibliotek. Łączy je z dowolnymi bibliotekami używanymi przez program. Wynikiem tego procesu jest plik wykonywalny.
Plik „watch.exe” to binarny plik wykonywalny, który został skompilowany w celu uruchomienia w systemie Windows:
file wd
file wd.o
file hello
file watch.exe
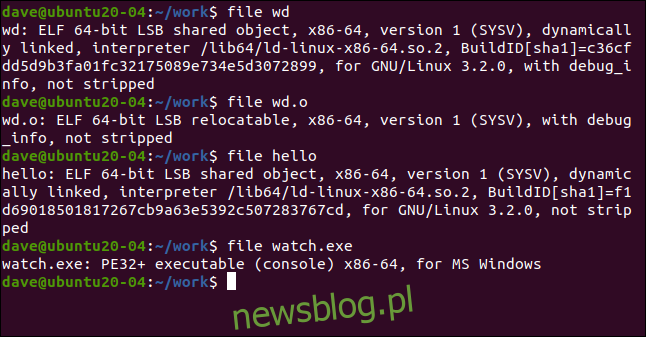
Rozpoczynając od ostatniego, plik mówi nam, że plik „watch.exe” to wykonywalny program konsoli PE32 + dla rodziny procesorów x86 w systemie Microsoft Windows. PE oznacza przenośny format wykonywalny, który ma wersje 32- i 64-bitowe. PE32 to wersja 32-bitowa, a PE32 + to wersja 64-bitowa.
Pozostałe trzy pliki są oznaczone jako Format wykonywalny i możliwy do połączenia (ELF). Jest to standard dla plików wykonywalnych i współdzielonych plików obiektów, takich jak biblioteki. Wkrótce przyjrzymy się formatowi nagłówka ELF.
To, co może przyciągnąć uwagę, to fakt, że te dwa pliki wykonywalne („wd” i „hello”) są identyfikowane jako Linux Standard Base (LSB), a plik obiektowy „wd.o” jest identyfikowany jako relokowalny LSB. Słowo wykonywalny jest oczywiste w przypadku jego braku.
Pliki obiektowe są relokowalne, co oznacza, że kod wewnątrz nich można załadować do pamięci w dowolnym miejscu. Pliki wykonywalne są wymienione jako obiekty współdzielone, ponieważ zostały utworzone przez konsolidator z plików obiektowych w taki sposób, że dziedziczą tę możliwość.
To pozwala Randomizacja układu przestrzeni adresowej (ASMR) do ładowania plików wykonywalnych do pamięci pod wybranymi przez siebie adresami. Standardowe pliki wykonywalne mają adres ładowania zakodowany w swoich nagłówkach, który określa, gdzie są ładowane do pamięci.
ASMR to technika bezpieczeństwa. Ładowanie plików wykonywalnych do pamięci pod przewidywalnymi adresami czyni je podatnymi na atak. Dzieje się tak, ponieważ ich punkty wejścia i lokalizacje ich funkcji będą zawsze znane atakującym. Pozycjonuj niezależne pliki wykonywalne (SROKA) umieszczony pod losowym adresem przezwycięża tę podatność.
Jeśli my skompiluj nasz program z kompilatorem gcc i podając opcję -no-pie, wygenerujemy konwencjonalny plik wykonywalny.
Opcja -o (plik wyjściowy) pozwala nam podać nazwę naszego pliku wykonywalnego:
gcc -o hello -no-pie hello.c
Użyjemy pliku na nowym pliku wykonywalnym i zobaczymy, co się zmieniło:
file hello
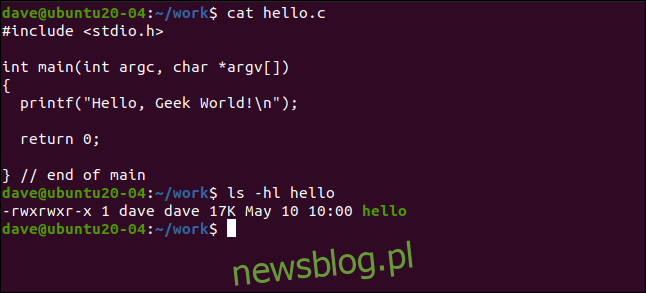
Rozmiar pliku wykonywalnego jest taki sam jak poprzednio (17 KB):
ls -hl hello
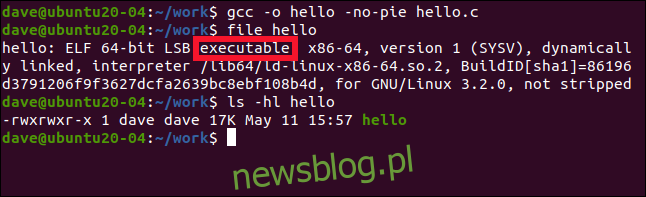
Plik binarny jest teraz identyfikowany jako standardowy plik wykonywalny. Robimy to tylko w celach demonstracyjnych. Jeśli będziesz kompilować aplikacje w ten sposób, stracisz wszystkie zalety ASMR.
Dlaczego plik wykonywalny jest tak duży?
Nasz przykładowy program hello ma 17 KB, więc trudno go nazwać dużym, ale wszystko jest względne. Kod źródłowy ma 120 bajtów:
cat hello.c
Co powoduje łączenie pliku binarnego, jeśli wszystko, co robi, to wypisuje jeden ciąg w oknie terminala? Wiemy, że istnieje nagłówek ELF, ale ma on tylko 64 bajty długości dla 64-bitowego pliku binarnego. Oczywiście musi to być coś innego:
ls -hl hello
Miejmy zeskanuj plik binarny za pomocą strings jako pierwszy krok do odkrycia, co jest w środku. Zrobimy to w mniej:
strings hello | less

W pliku binarnym znajduje się wiele ciągów, oprócz „Hello, Geek world!” z naszego kodu źródłowego. Większość z nich to etykiety regionów w pliku binarnym oraz nazwy i informacje łączące współdzielonych obiektów. Obejmują one biblioteki i funkcje w tych bibliotekach, od których zależy plik binarny.
Plik polecenie ldd pokazuje nam zależności obiektów współdzielonych pliku binarnego:
ldd hello
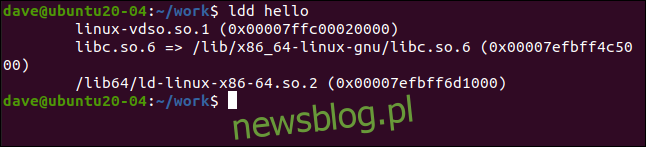
W danych wyjściowych znajdują się trzy wpisy, a dwa z nich zawierają ścieżkę do katalogu (pierwsza nie):
linux-vdso.so: Virtual Dynamic Shared Object (VDSO) jest mechanizmem jądra, który umożliwia dostęp do zestawu procedur w przestrzeni jądra przez plik binarny przestrzeni użytkownika. To unika narzutów związanych z przełączaniem kontekstu z trybu jądra użytkownika. Obiekty współdzielone VDSO są zgodne z formatem plików wykonywalnych i łączonych (ELF), co umożliwia ich dynamiczne łączenie z plikiem binarnym w czasie wykonywania. VDSO jest przydzielane dynamicznie i korzysta z ASMR. Standard zapewnia możliwość VDSO Biblioteka GNU C. jeśli jądro obsługuje schemat ASMR.
libc.so.6: plik Biblioteka GNU C. obiekt udostępniony.
/lib64/ld-linux-x86-64.so.2: jest to linker dynamiczny, którego chce użyć plik binarny. Dynamiczny linker bada plik binarny, aby odkryć, jakie ma zależności. Wprowadza te udostępnione obiekty do pamięci. Przygotowuje plik binarny do uruchomienia i możliwości znalezienia i uzyskania dostępu do zależności w pamięci. Następnie uruchamia program.
Nagłówek ELF
Możemy zbadać i zdekodować nagłówek ELF używając narzędzia readelf i opcji -h (nagłówek pliku):
readelf -h hello

Nagłówek jest interpretowany za nas.
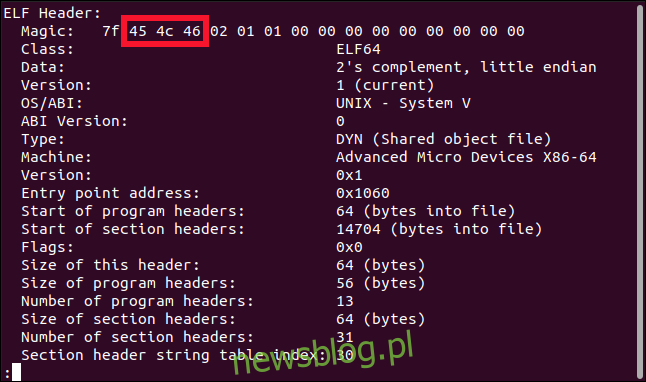
Pierwszy bajt wszystkich plików binarnych ELF jest ustawiany na wartość szesnastkową 0x7F. Następne trzy bajty są ustawiane na 0x45, 0x4C i 0x46. Pierwszy bajt to flaga identyfikująca plik jako plik binarny ELF. Aby było to przejrzyste, następne trzy bajty zawierają literę „ELF” ASCII:
Klasa: wskazuje, czy plik binarny jest 32- czy 64-bitowym plikiem wykonywalnym (1 = 32, 2 = 64).
Dane: wskazuje plik endianness w użyciu. Kodowanie endian definiuje sposób przechowywania liczb wielobajtowych. W kodowaniu big-endian liczba jest przechowywana z najważniejszymi bitami w pierwszej kolejności. W kodowaniu little-endian liczba jest przechowywana najpierw z najmniej znaczącymi bitami.
Wersja: wersja ELF (obecnie 1).
OS / ABI: reprezentuje typ interfejs binarny aplikacji w użyciu. Definiuje interfejs między dwoma modułami binarnymi, takimi jak program i biblioteka współdzielona.
Wersja ABI: wersja ABI.
Typ: typ pliku binarnego ELF. Typowe wartości to ET_REL dla relokowalnego zasobu (takiego jak plik obiektowy), ET_EXEC dla pliku wykonywalnego skompilowanego z flagą -no-pie i ET_DYN dla pliku wykonywalnego obsługującego ASMR.
Maszyna: architektura zestawu instrukcji. Wskazuje platformę docelową, dla której utworzono plik binarny.
Wersja: zawsze ustawiona na 1, dla tej wersji ELF.
Adres punktu wejścia: adres pamięci w pliku binarnym, w którym rozpoczyna się wykonywanie.
Pozostałe wpisy to rozmiary i liczby regionów i sekcji w pliku binarnym, aby można było obliczyć ich lokalizacje.
Szybki podgląd pierwszych ośmiu bajtów pliku binarnego z zrzutem hexdump pokaże bajt podpisu i ciąg „ELF” w pierwszych czterech bajtach pliku. Opcja -C (canonical) daje nam reprezentację bajtów w ASCII wraz z ich wartościami szesnastkowymi, a opcja -n (liczba) pozwala nam określić, ile bajtów chcemy zobaczyć:
hexdump -C -n 8 hello

objdump i Granular View
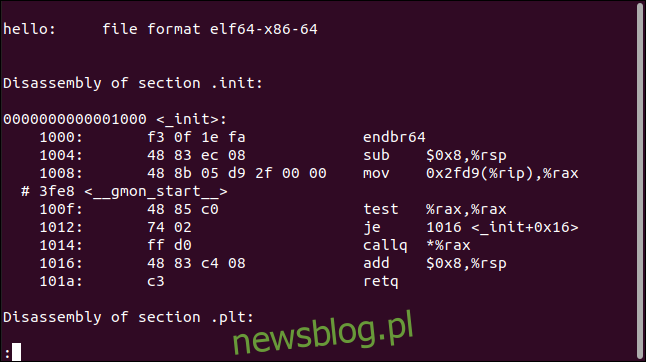
Jeśli chcesz zobaczyć szczegóły, możesz użyć objdumpcommand z opcją -d (disassemble):
objdump -d hello | less

Spowoduje to dezasemblację wykonywalnego kodu maszynowego i wyświetlenie go w bajtach szesnastkowych obok odpowiednika w asemblerze. Lokalizacja adresu pierwszego bye w każdym wierszu jest pokazana po lewej stronie.
Jest to przydatne tylko wtedy, gdy umiesz czytać język asemblera lub jesteś ciekawy, co dzieje się za kurtyną. Jest dużo wyjścia, więc umieściliśmy go w mniej.
Kompilacja i łączenie
Istnieje wiele sposobów kompilacji pliku binarnego. Na przykład deweloper decyduje, czy dołączyć informacje o debugowaniu. Sposób, w jaki plik binarny jest połączony, ma również wpływ na jego zawartość i rozmiar. Jeśli odwołania binarne współużytkują obiekty jako zależności zewnętrzne, będą mniejsze niż te, z którymi zależności łączą się statycznie.
Większość programistów zna już polecenia, które tutaj omówiliśmy. Dla innych jednak oferują łatwe sposoby przeszukiwania i zobaczenia, co znajduje się w binarnej czarnej skrzynce.