
Sharding to proces dzielenia dużej skali zestawów danych na porcję mniejszych zestawów danych w wielu instancjach MongoDB w środowisku rozproszonym.
Spis treści:
Co to jest fragmentacja?
Sharding MongoDB zapewnia nam skalowalne rozwiązanie do przechowywania dużej ilości danych na wielu serwerach, zamiast przechowywania na jednym serwerze.
W praktyce nie jest możliwe przechowywanie rosnących wykładniczo danych na jednej maszynie. Wysyłanie zapytań do ogromnej ilości danych przechowywanych na jednym serwerze może prowadzić do wysokiego wykorzystania zasobów i może nie zapewniać zadowalającej przepustowości odczytu i zapisu.
Zasadniczo istnieją dwa rodzaje metod skalowania, które umożliwiają gromadzenie danych w systemie:
Skalowanie w pionie polega na zwiększeniu wydajności pojedynczego serwera przez dodanie mocniejszych procesorów, modernizację pamięci RAM lub zwiększenie ilości miejsca na dysku w systemie. Istnieją jednak możliwe implikacje zastosowania skalowania pionowego w praktycznych przypadkach użycia z istniejącą technologią i konfiguracjami sprzętowymi.
Skalowanie poziome polega na dodawaniu większej liczby serwerów i rozkładaniu obciążenia na wiele serwerów. Ponieważ każda maszyna będzie obsługiwać podzbiór całego zestawu danych, zapewnia to lepszą wydajność i opłacalne rozwiązanie zamiast wdrażania zaawansowanego sprzętu. Wymaga jednak dodatkowej konserwacji złożonej infrastruktury z dużą liczbą serwerów.
Sharding Mongo DB działa w oparciu o technikę skalowania poziomego.
Komponenty do shardingu
Aby osiągnąć sharding w MongoDB, wymagane są następujące komponenty:
Shard to instancja Mongo obsługująca podzbiór oryginalnych danych. Odłamki są wymagane do wdrożenia w zestawie replik.
Mongos jest instancją Mongo i działa jako interfejs między aplikacją kliencką a klastrem podzielonym na fragmenty. Działa jako router zapytań do fragmentów.
Config Server to instancja Mongo, która przechowuje informacje o metadanych oraz szczegóły konfiguracji klastra. MongoDB wymaga wdrożenia serwera konfiguracji jako zestawu replik.
Architektura shardingu
Klaster MongoDB składa się z kilku zestawów replik.
Każdy zestaw replik składa się z co najmniej 3 lub więcej instancji mongo. Klaster podzielonego na fragmenty może składać się z wielu wystąpień fragmentów mongo, a każde wystąpienie fragmentu działa w zestawie replik fragmentu. Aplikacja współpracuje z Mongosem, który z kolei komunikuje się z odłamkami. Dlatego w dzieleniu na fragmenty aplikacje nigdy nie wchodzą w bezpośrednią interakcję z węzłami fragmentów. Router zapytań rozdziela podzbiory danych między węzły fragmentów na podstawie klucza fragmentu.
Implementacja shardingu
Wykonaj poniższe kroki w celu shardingu
Krok 1
- Uruchom serwer konfiguracyjny w zestawie replik i włącz replikację między nimi.
mongod –configsvr –port 27019 –replSet rs0 –dbpath C:datadata1 –bind_ip localhost
mongod –configsvr –port 27018 –replSet rs0 –dbpath C:datadata2 –bind_ip localhost
mongod –configsvr –port 27017 –replSet rs0 –dbpath C:datadata3 –bind_ip localhost
Krok 2
- Zainicjuj zestaw replik na jednym z serwerów konfiguracyjnych.
rs.initiate( { _id : “rs0”, configsvr: true, członkowie: [ { _id: 0, host: “IP:27017” }, { _id: 1, host: “IP:27018” }, { _id: 2, host: “IP:27019” } ] })
rs.initiate( { _id : "rs0", configsvr: true, members: [ { _id: 0, host: "IP:27017" }, { _id: 1, host: "IP:27018" }, { _id: 2, host: "IP:27019" } ] })
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1593569257, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1593569257, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569257, 1)
}
Krok 3
- Rozpocznij dzielenie serwerów na fragmenty w zestawie replik i włącz replikację między nimi.
mongod –shardsvr –port 27020 –replSet rs1 –dbpath C:datadata4 –bind_ip localhost
mongod –shardsvr –port 27021 –replSet rs1 –dbpath C:datadata5 –bind_ip localhost
mongod –shardsvr –port 27022 –replSet rs1 –dbpath C:datadata6 –bind_ip localhost
MongoDB inicjuje pierwszy serwer shardingu jako podstawowy, aby przenieść użycie podstawowego serwera shardingu przenieśPrimary metoda.
Krok 4
- Zainicjuj zestaw replik na jednym z serwerów podzielonych na fragmenty.
rs.initiate( { _id : “rs0”, członkowie: [ { _id: 0, host: “IP:27020” }, { _id: 1, host: “IP:27021” }, { _id: 2, host: “IP:27022” } ] })
rs.initiate( { _id : "rs0", members: [ { _id: 0, host: "IP:27020" }, { _id: 1, host: "IP:27021" }, { _id: 2, host: "IP:27022" } ] })
{
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1593569748, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1593569748, 1)
}
Krok 5
- Uruchom mango dla rozdrobnionego klastra
mongos –port 40000 –configdb rs0/localhost:27019,localhost:27018,localhost:27017
Krok 6
- Połącz serwer trasy mongo
mongo – port 40000
- Teraz dodaj serwery shardingu.
sh.addShard( „rs1/hostlokalny:27020,hostlokalny:27021,hostlokalny:27022”)
sh.addShard( "rs1/localhost:27020,localhost:27021,localhost:27022")
{
"shardAdded" : "rs1",
"ok" : 1,
"operationTime" : Timestamp(1593570212, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570212, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Krok 7
- W powłoce mongo włącz sharding na DB i kolekcje.
- Włącz sharding w DB
sh.enableSharding(„geekFlareDB”)
sh.enableSharding("geekFlareDB")
{
"ok" : 1,
"operationTime" : Timestamp(1591630612, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1591630612, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Krok 8
- Aby dokonać fragmentacji, wymagany jest klucz fragmentu kolekcji (opisany w dalszej części tego artykułu).
Składnia: sh.shardCollection(“dbName.collectionName”, { “key” : 1 } )
sh.shardCollection("geekFlareDB.geekFlareCollection", { "key" : 1 } )
{
"collectionsharded" : "geekFlareDB.geekFlareCollection",
"collectionUUID" : UUID("0d024925-e46c-472a-bf1a-13a8967e97c1"),
"ok" : 1,
"operationTime" : Timestamp(1593570389, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570389, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Uwaga, jeśli kolekcja nie istnieje, utwórz w następujący sposób.
db.createCollection("geekFlareCollection")
{
"ok" : 1,
"operationTime" : Timestamp(1593570344, 4),
"$clusterTime" : {
"clusterTime" : Timestamp(1593570344, 5),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Krok 9
Wstaw dane do kolekcji. Dzienniki Mongo zaczną rosnąć, wskazując, że równoważnik jest w akcji i próbując zrównoważyć dane między odłamkami.
Krok 10
Ostatnim krokiem jest sprawdzenie stanu shardingu. Status można sprawdzić, uruchamiając poniższe polecenie w węźle trasy Mongos.
Stan fragmentowania
Sprawdź stan fragmentowania, uruchamiając poniższe polecenie w węźle trasy mongo.
sh.status()
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5ede66c22c3262378c706d21")
}
shards:
{ "_id" : "rs1", "host" : "rs1/localhost:27020,localhost:27021,localhost:27022", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs1
Time of Reported error: Tue Jun 09 2020 15:25:03 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs1 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs1", "partitioned" : true, "version" : { "uuid" : UUID("a770da01-1900-401e-9f34-35ce595a5d54"), "lastMod" : 1 } }
geekFlareDB.geekFlareCol
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
geekFlareDB.geekFlareCollection
shard key: { "product" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "product" : { "$minKey" : 1 } } -->> { "product" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs1", "partitioned" : false, "version" : { "uuid" : UUID("fbc00f03-b5b5-4d13-9d09-259d7fdb7289"), "lastMod" : 1 } }
mongos>
Dystrybucja danych
Router Mongos rozdziela obciążenie między fragmenty w oparciu o klucz fragmentu i równomiernie dystrybuuje dane; Balancer wchodzi do akcji.
Kluczowym komponentem do dystrybucji danych między shardami są
- Balancer odgrywa rolę w równoważeniu podzbioru danych między węzłami podzielonymi na fragmenty. Balancer uruchamia się, gdy serwer Mongos zaczyna dystrybuować obciążenia między shardami. Po uruchomieniu Balancer rozprowadzał dane bardziej równomiernie. Aby sprawdzić stan balancera uruchom sh.status() lub sh.getBalancerState() lub
sh.isBalancerRunning().
mongos> sh.isBalancerRunning() true mongos>
LUB
mongos> sh.getBalancerState() true mongos>
Po wstawieniu danych mogliśmy zauważyć pewną aktywność w demonie Mongos, mówiącą, że przenosi on niektóre porcje dla określonych fragmentów i tak dalej, tj. Balancer będzie działał, próbując zrównoważyć dane między fragmentami. Uruchamianie balansera może prowadzić do problemów z wydajnością; stąd sugerowane jest uruchomienie balansera w określonym czasie okno wyważarki.
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5efbeff98a8bbb2d27231674")
}
shards:
{ "_id" : "rs1", "host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022", "state" : 1 }
{ "_id" : "rs2", "host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025", "state" : 1 }
active mongoses:
"4.2.7" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: yes
Failed balancer rounds in last 5 attempts: 5
Last reported error: Could not find host matching read preference { mode: "primary" } for set rs2
Time of Reported error: Wed Jul 01 2020 14:39:59 GMT+0530 (India Standard Time)
Migration Results for the last 24 hours:
1024 : Success
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
rs2 1024
too many chunks to print, use verbose if you want to force print
{ "_id" : "geekFlareDB", "primary" : "rs2", "partitioned" : true, "version" : { "uuid" : UUID("a8b8dc5c-85b0-4481-bda1-00e53f6f35cd"), "lastMod" : 1 } }
geekFlareDB.geekFlareCollection
shard key: { "key" : 1 }
unique: false
balancing: true
chunks:
rs2 1
{ "key" : { "$minKey" : 1 } } -->> { "key" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0)
{ "_id" : "test", "primary" : "rs2", "partitioned" : false, "version" : { "uuid" : UUID("a28d7504-1596-460e-9e09-0bdc6450028f"), "lastMod" : 1 } }
mongos>
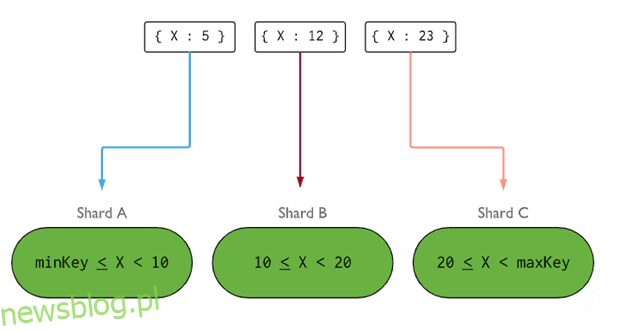
- Klucz fragmentu określa logikę dystrybucji dokumentów z kolekcji podzielonej na fragmenty między fragmentami. Klucz fragmentu może być polem indeksowanym lub indeksowanym polem złożonym, które musi być obecne we wszystkich dokumentach kolekcji, która ma zostać wstawiona. Dane zostaną podzielone na porcje, a każda porcja zostanie powiązana z kluczem fragmentu opartym na zakresie. Na podstawie zapytania o zakres router zdecyduje, który fragment będzie przechowywać porcję.
Klucz fragmentu można wybrać, biorąc pod uwagę pięć właściwości:
- Kardynalność
- Napisz dystrybucję
- Przeczytaj dystrybucję
- Przeczytaj kierowanie
- Przeczytaj miejscowość
Idealny klucz fragmentu sprawia, że MongoDB równomiernie rozkłada obciążenie na wszystkie fragmenty. Wybór dobrego klucza odłamkowego jest niezwykle ważny.
 Obraz: MongoDB
Obraz: MongoDB
Usuwanie węzła fragmentu
Przed usunięciem fragmentów z klastra użytkownik musi zapewnić bezpieczną migrację danych do pozostałych fragmentów. MongoDB dba o bezpieczne odprowadzanie danych do innych węzłów fragmentów przed usunięciem wymaganego węzła fragmentów.
Uruchom poniżej polecenie, aby usunąć wymagany fragment.
Krok 1
Najpierw musimy określić nazwę hosta fragmentu, który ma zostać usunięty. Poniższe polecenie wyświetli listę wszystkich fragmentów obecnych w klastrze wraz ze stanem fragmentu.
db.adminCommand( { listShards: 1 } )
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs1",
"host" : "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022",
"state" : 1
},
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593572866, 15),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572866, 15),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Krok 2
Wydaj poniższe polecenie, aby usunąć wymagany fragment z klastra. Po wydaniu balancer zajmuje się usuwaniem porcji z opróżniającego węzła shard, a następnie równoważy dystrybucję pozostałych porcji wśród pozostałych węzłów shards.
db.adminCommand( { removeShard: “shardedReplicaNodes” } )
mongos> db.adminCommand( { removeShard: "rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022" } )
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "rs1",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1,
"operationTime" : Timestamp(1593572385, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1593572385, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Krok 3
Aby sprawdzić stan opróżnianego fragmentu, wydaj ponownie to samo polecenie.
db.adminCommand( { removeShard: “rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022” } )
Musimy poczekać, aż drenaż danych zostanie zakończony. Pola msg i state pokażą, czy usuwanie danych zostało zakończone, czy nie, w następujący sposób
"msg" : "draining ongoing", "state" : "ongoing",
Status możemy też sprawdzić poleceniem sh.status(). Po usunięciu sharded node nie będzie odzwierciedlony w danych wyjściowych. Ale jeśli opróżnianie będzie trwało, węzeł podzielony na fragmenty otrzyma status opróżniania jako prawdziwy.
Krok 4
Kontynuuj sprawdzanie stanu opróżniania za pomocą tego samego powyższego polecenia, aż wymagany fragment zostanie całkowicie usunięty.
Po zakończeniu dane wyjściowe polecenia będą odzwierciedlać komunikat i stan jako zakończone.
"msg" : "removeshard completed successfully", "state" : "completed", "shard" : "rs1", "ok" : 1,
Krok 5
Na koniec musimy sprawdzić pozostałe fragmenty w klastrze. Aby sprawdzić stan, wpisz sh.status() lub db.adminCommand( { listShards: 1 } )
mongos> db.adminCommand( { listShards: 1 } )
{
"shards" : [
{
"_id" : "rs2",
"host" : "rs2/127.0.0.1:27023,127.0.0.1:27024,127.0.0.1:27025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1593575215, 3),
"$clusterTime" : {
"clusterTime" : Timestamp(1593575215, 3),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Tutaj widzimy, że usunięty fragment nie jest już obecny na liście fragmentów.
Korzyści z shardingu nad replikacją
- W przypadku replikacji węzeł podstawowy obsługuje wszystkie operacje zapisu, podczas gdy serwery pomocnicze są wymagane do utrzymywania kopii zapasowych lub obsługi operacji tylko do odczytu. Jednak w przypadku shardingu wraz z zestawami replik obciążenie rozkłada się na liczbę serwerów.
- Pojedynczy zestaw replik jest ograniczony do 12 węzłów, ale nie ma ograniczeń co do liczby fragmentów.
- Replikacja wymaga zaawansowanego sprzętu lub skalowania wertykalnego do obsługi dużych zestawów danych, co jest zbyt drogie w porównaniu z dodawaniem dodatkowych serwerów we shardingu.
- W replikacji wydajność odczytu można zwiększyć, dodając więcej serwerów podrzędnych/dodatkowych, podczas gdy w przypadku fragmentowania zarówno wydajność odczytu, jak i zapisu zostanie zwiększona przez dodanie większej liczby węzłów fragmentów.
Ograniczenie shardingu
- Klaster podzielonego na fragmenty nie obsługuje unikatowego indeksowania we fragmentach, dopóki unikatowy indeks nie zostanie poprzedzony pełnym kluczem fragmentu.
- Wszystkie operacje aktualizacji dla kolekcji podzielonej na fragmenty w jednym lub wielu dokumentach muszą zawierać klucz fragmentu lub pole _id w zapytaniu.
- Kolekcje można podzielić na fragmenty, jeśli ich rozmiar nie przekracza określonego progu. Ten próg można oszacować na podstawie średniego rozmiaru wszystkich kluczy fragmentów i skonfigurowanego rozmiaru fragmentów.
- Sharding obejmuje limity operacyjne dotyczące maksymalnego rozmiaru kolekcji lub liczby podziałów.
- Wybieranie niewłaściwych kluczy fragmentów, które mają wpływ na wydajność.
Wniosek
MongoDB oferuje wbudowane sharding do implementacji dużej bazy danych bez obniżania wydajności. Mam nadzieję, że powyższe informacje pomogą ci skonfigurować sharding MongoDB. Następnie możesz chcieć zapoznać się z niektórymi z powszechnie używanych poleceń MongoDB.