
W tym artykule wymieniono i objaśniono niektóre z najlepszych bibliotek Pythona dla naukowców zajmujących się danymi i zespołu uczenia maszynowego.
Python jest idealnym językiem używanym w tych dwóch dziedzinach, głównie w przypadku bibliotek, które oferuje.
Wynika to z aplikacji bibliotek Pythona, takich jak wejście/wyjście danych we/wy i analiza danych, a także innych operacji manipulacji danymi, których używają analitycy danych i eksperci ds. uczenia maszynowego do obsługi i eksploracji danych.
Spis treści:
Biblioteki Pythona, czym one są?
Biblioteka Pythona to obszerna kolekcja wbudowanych modułów zawierających wstępnie skompilowany kod, w tym klasy i metody, eliminując potrzebę implementacji kodu od zera przez programistę.
Znaczenie Pythona w nauce o danych i uczeniu maszynowym
Python ma najlepsze biblioteki do użytku przez ekspertów od uczenia maszynowego i nauki o danych.
Jego składnia jest łatwa, dzięki czemu można efektywnie wdrażać złożone algorytmy uczenia maszynowego. Co więcej, prosta składnia skraca krzywą uczenia się i ułatwia zrozumienie.
Python obsługuje również szybkie tworzenie prototypów i płynne testowanie aplikacji.
Duża społeczność Pythona jest przydatna dla naukowców zajmujących się danymi, aby w razie potrzeby łatwo szukać rozwiązań swoich zapytań.
Jak przydatne są biblioteki Pythona?
Biblioteki Pythona odgrywają kluczową rolę w tworzeniu aplikacji i modeli w uczeniu maszynowym i nauce o danych.
Te biblioteki znacznie ułatwiają programistom ponowne wykorzystanie kodu. Dlatego możesz zaimportować odpowiednią bibliotekę, która implementuje określoną funkcję w twoim programie, inną niż wymyślanie koła na nowo.
Biblioteki Pythona używane w uczeniu maszynowym i nauce o danych
Eksperci Data Science polecają różne biblioteki Pythona, które muszą znać entuzjaści nauki o danych. W zależności od ich znaczenia w aplikacji, eksperci ds. uczenia maszynowego i Data Science stosują różne biblioteki Pythona podzielone na biblioteki do wdrażania modeli, wydobywania i scrapingu danych, przetwarzania danych i wizualizacji danych.
W tym artykule opisano niektóre powszechnie używane biblioteki języka Python w nauce danych i uczeniu maszynowym.
Przyjrzyjmy się im teraz.
Numpy
Biblioteka Numpy Python, również w całości Numerical Python Code, jest zbudowana z dobrze zoptymalizowanego kodu C. Data Scientists preferują go ze względu na głębokie obliczenia matematyczne i obliczenia naukowe.
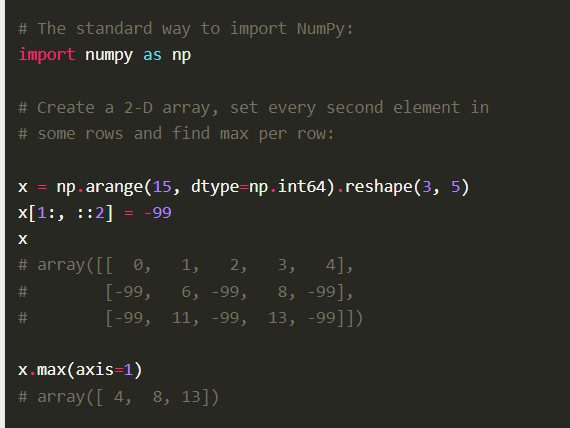
Cechy
Numpy zawiera inne wszechstronne funkcje, takie jak wektoryzacja operacji matematycznych, indeksowanie i kluczowe koncepcje w implementacji tablic i macierzy.
Pandy
Pandas to słynna biblioteka w uczeniu maszynowym, która zapewnia struktury danych wysokiego poziomu i liczne narzędzia do bezproblemowej i efektywnej analizy ogromnych zbiorów danych. Przy bardzo niewielu poleceniach ta biblioteka może tłumaczyć złożone operacje na danych.
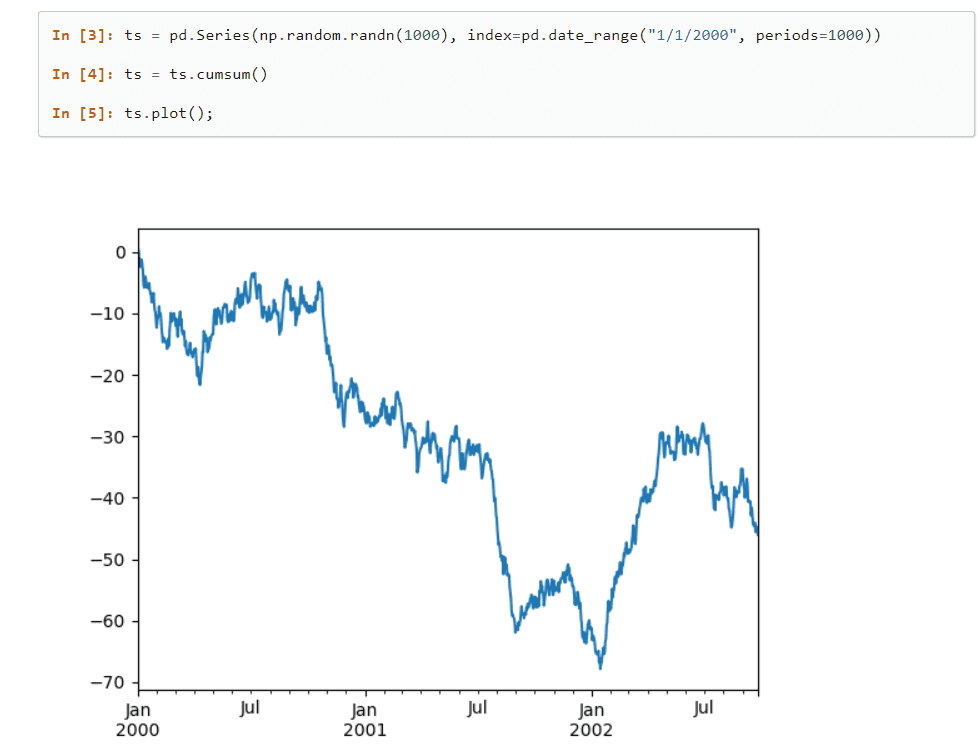
Liczne wbudowane metody, które mogą grupować, indeksować, pobierać, dzielić, restrukturyzować dane i filtrować zestawy przed wstawieniem ich do tabel jedno- i wielowymiarowych; tworzy tę bibliotekę.
Główne cechy biblioteki Pandy
Jest bardzo wydajny ze względu na dobrą funkcjonalność analizy danych i dużą elastyczność.
Biblioteka map
Graficzna biblioteka Pythona 2D Matplotlib może z łatwością obsługiwać dane z wielu źródeł. Tworzone wizualizacje są statyczne, animowane i interaktywne, które użytkownik może powiększać, dzięki czemu są wydajne w przypadku wizualizacji i tworzenia wykresów. Umożliwia również dostosowanie układu i stylu wizualnego.
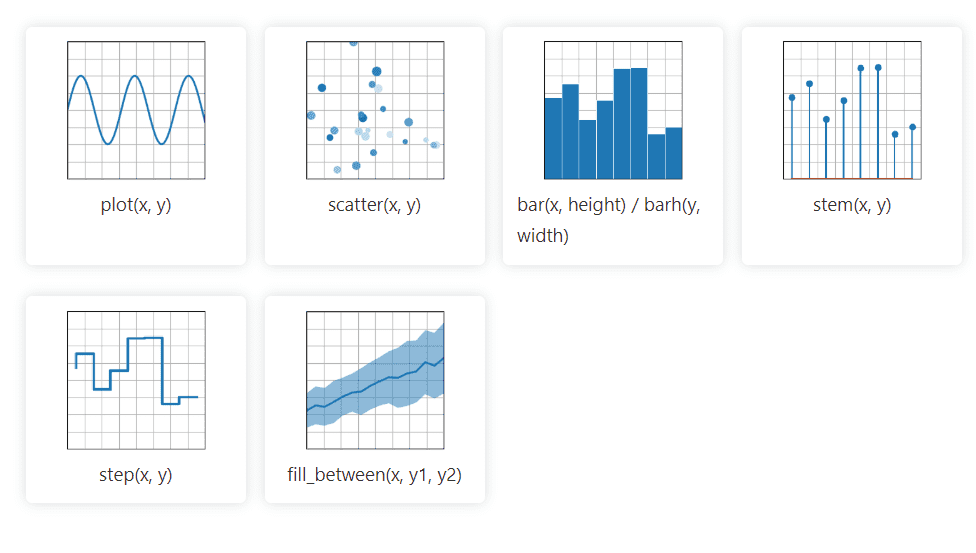
Jego dokumentacja jest open source i oferuje bogaty zbiór narzędzi wymaganych do wdrożenia.
Matplotlib importuje klasy pomocnicze w celu zaimplementowania roku, miesiąca, dnia i tygodnia, co usprawnia manipulowanie danymi szeregów czasowych.
Nauka scikitu
Jeśli zastanawiasz się nad biblioteką, która pomoże Ci pracować ze złożonymi danymi, Scikit-learn powinna być idealną biblioteką. Eksperci w dziedzinie uczenia maszynowego szeroko korzystają ze nauki scikit. Biblioteka jest powiązana z innymi bibliotekami, takimi jak NumPy, SciPy i matplotlib. Oferuje zarówno nadzorowane, jak i nienadzorowane algorytmy uczenia, które można wykorzystać w aplikacjach produkcyjnych.

Cechy biblioteki Pythona uczonej przez Scikit
Biblioteka scikit-learn jest wydajna w ekstrakcji cech z zestawów danych tekstowych i graficznych. Ponadto możliwe jest sprawdzenie dokładności nadzorowanych modeli na niewidocznych danych. Jego liczne dostępne algorytmy umożliwiają eksplorację danych i inne zadania uczenia maszynowego.
SciPy
SciPy (Scientific Python Code) to biblioteka uczenia maszynowego, która zapewnia moduły stosowane do funkcji matematycznych i algorytmów, które mają szerokie zastosowanie. Jego algorytmy rozwiązują równania algebraiczne, interpolację, optymalizację, statystykę i całkowanie.
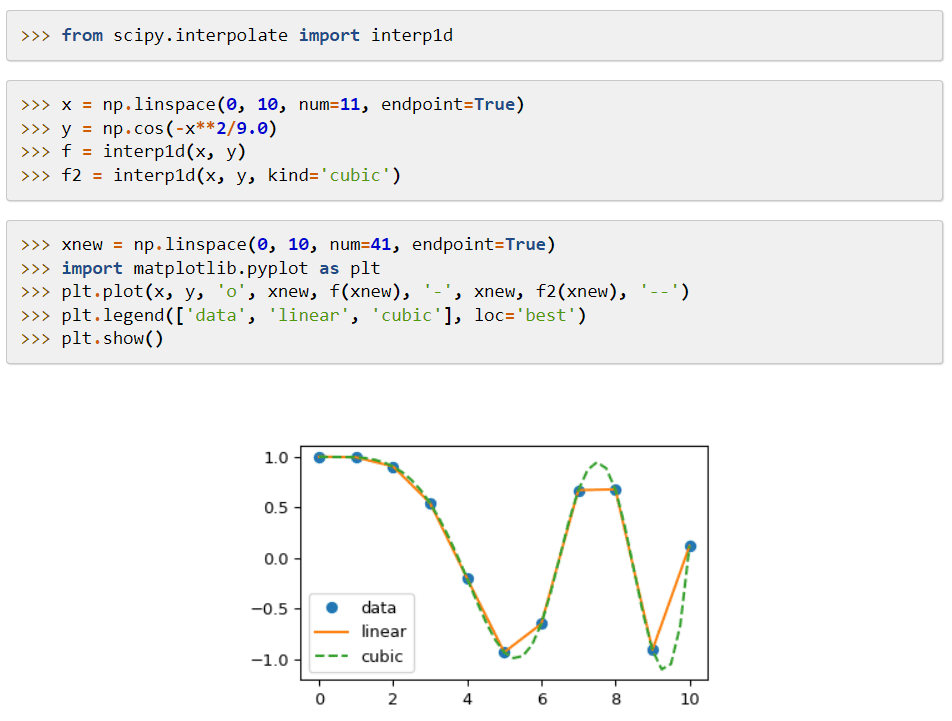
Jego główną cechą jest rozszerzenie do NumPy, które dodaje narzędzia do rozwiązywania funkcji matematycznych i zapewnia struktury danych, takie jak rzadkie macierze.
SciPy używa poleceń i klas wysokiego poziomu do manipulowania i wizualizacji danych. Jego przetwarzanie danych i systemy prototypowe sprawiają, że jest to jeszcze bardziej efektywne narzędzie.
Co więcej, wysokopoziomowa składnia SciPy ułatwia korzystanie z niej programistom na dowolnym poziomie doświadczenia.
Jedyną wadą SciPy jest skupienie się wyłącznie na obiektach numerycznych i algorytmach; dlatego nie może zaoferować żadnej funkcji kreślenia.
PyTorch
Ta zróżnicowana biblioteka uczenia maszynowego skutecznie implementuje obliczenia tensorowe z akceleracją GPU, tworząc dynamiczne wykresy obliczeniowe i automatyczne obliczenia gradientów. Biblioteka Torch, biblioteka uczenia maszynowego typu open source opracowana w języku C, tworzy bibliotekę PyTorch.

Najważniejsze cechy to:
Możesz używać PyTorch do tworzenia aplikacji NLP.
Keras
Keras to biblioteka Python typu open source do uczenia maszynowego, używana do eksperymentowania z głębokimi sieciami neuronowymi.
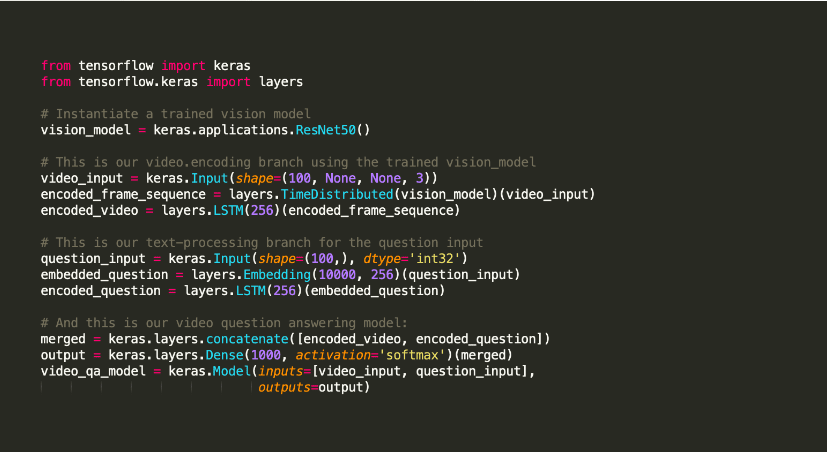
Słynie z oferowania narzędzi, które wspierają między innymi takie zadania jak kompilowanie modeli i wizualizacje wykresów. Wykorzystuje Tensorflow do swojego zaplecza. Alternatywnie możesz użyć Theano lub sieci neuronowych, takich jak CNTK w zapleczu. Ta infrastruktura zaplecza pomaga w tworzeniu wykresów obliczeniowych używanych do implementacji operacji.
Kluczowe cechy biblioteki
Zastosowania Keras obejmują elementy składowe sieci neuronowych, takie jak warstwy i cele, a także inne narzędzia ułatwiające pracę z obrazami i danymi tekstowymi.
Zrodzony z morza
Seaborn to kolejne cenne narzędzie w wizualizacji danych statystycznych.
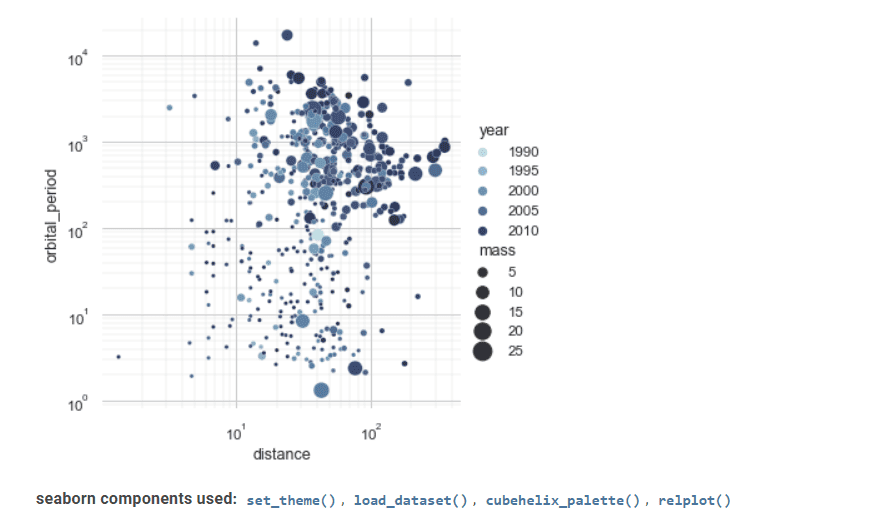
Zaawansowany interfejs umożliwia implementację atrakcyjnych i pouczających rysunków statystycznych, graficznych.
Działka
Plotly to internetowe narzędzie do wizualizacji 3D oparte na bibliotece Plotly JS. Ma szerokie wsparcie dla różnych typów wykresów, takich jak wykresy liniowe, wykresy punktowe i wykresy typu box.
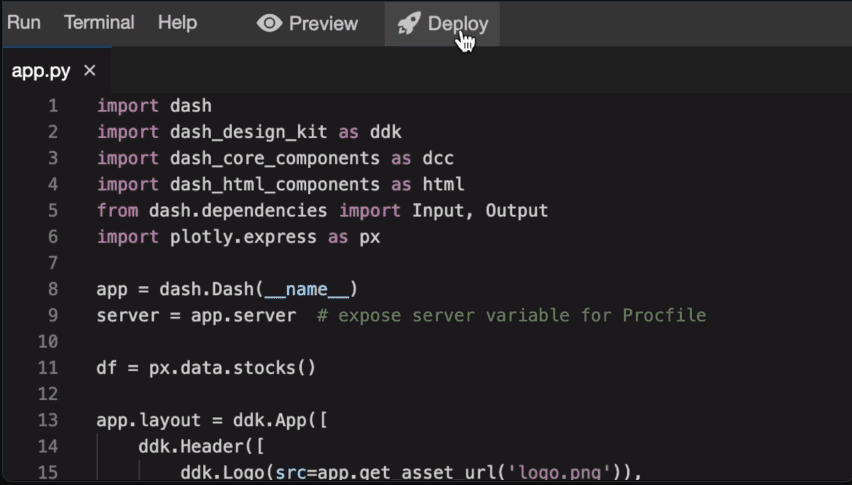
Jego zastosowanie obejmuje tworzenie internetowych wizualizacji danych w notatnikach Jupyter.
Plotly nadaje się do wizualizacji, ponieważ może wskazać wartości odstające lub nieprawidłowości na wykresie za pomocą narzędzia najechania kursorem. Możesz także dostosować wykresy do swoich preferencji.
Wadą Plotly jest to, że jego dokumentacja jest nieaktualna; dlatego używanie go jako przewodnika może być trudne dla użytkownika. Ponadto posiada wiele narzędzi, których użytkownik powinien się nauczyć. Śledzenie ich wszystkich może być trudne.
Funkcje biblioteki Plotly Python
ProstyITK
SimpleITK to biblioteka do analizy obrazów, która oferuje interfejs do Insight Toolkit (ITK). Opiera się na C++ i jest open-source.
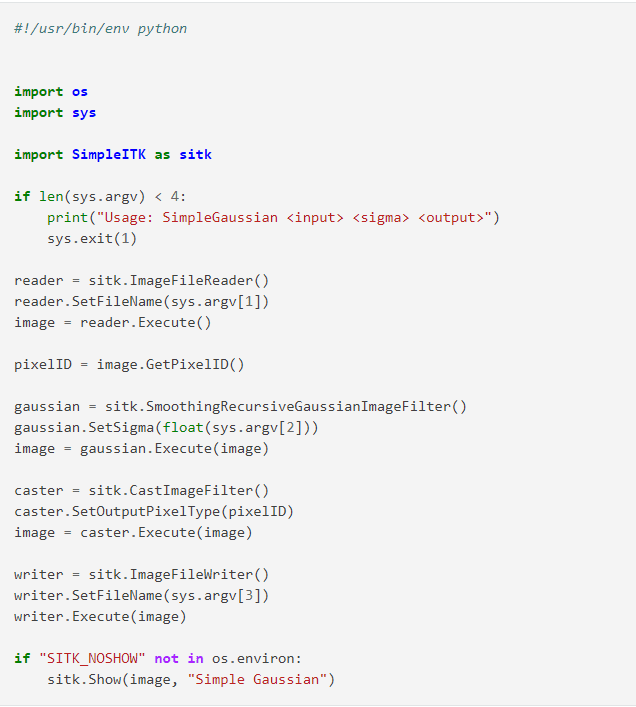
Funkcje biblioteki SimpleITK
Jego uproszczony interfejs jest dostępny w różnych językach programowania, takich jak R, C#, C++, Java i Python.
Model statystyk
Statsmodel szacuje modele statystyczne, implementuje testy statystyczne i eksploruje dane statystyczne za pomocą klas i funkcji.
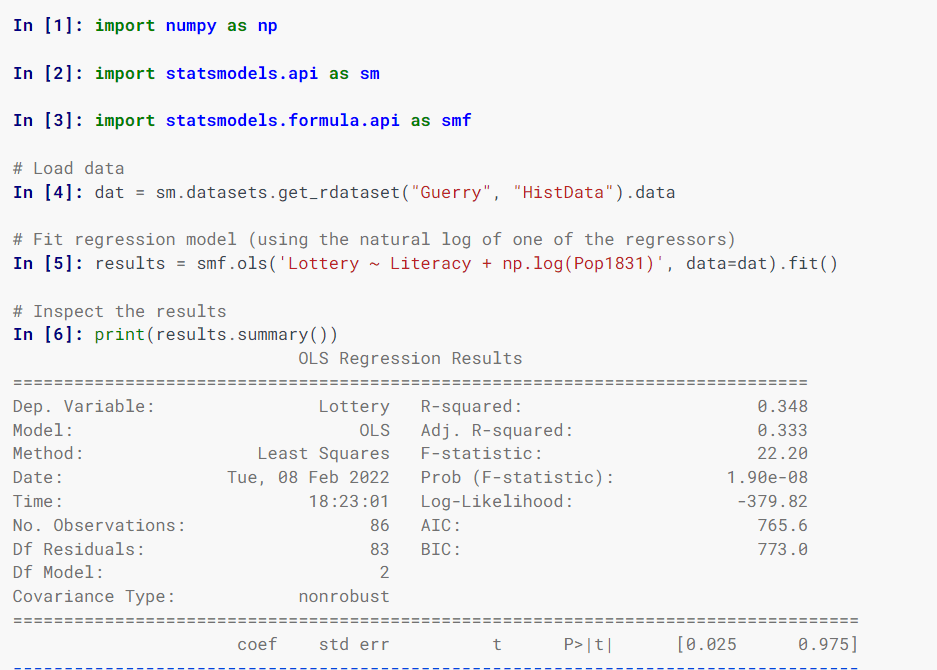
Określanie modeli używa formuł w stylu R, tablic NumPy i ramek danych Pandy.
Złośliwy
Ten pakiet o otwartym kodzie źródłowym jest preferowanym narzędziem do pobierania (skrobywania) i indeksowania danych ze strony internetowej. Jest asynchroniczny, a zatem stosunkowo szybki. Scrapy ma architekturę i funkcje, które sprawiają, że jest wydajny.
Z drugiej strony jego instalacja różni się dla różnych systemów operacyjnych. Ponadto nie można go używać na stronach internetowych zbudowanych na JS. Ponadto może działać tylko z Pythonem 2.7 lub nowszymi wersjami.
Eksperci Data Science stosują ją w eksploracji danych i testowaniu automatycznym.
Cechy
Poduszka
Pillow to biblioteka obrazowania Pythona, która manipuluje i przetwarza obrazy.
Dodaje funkcje przetwarzania obrazu interpretera Pythona, obsługuje różne formaty plików i oferuje doskonałą reprezentację wewnętrzną.
Dzięki Pillow można łatwo uzyskać dostęp do danych przechowywanych w podstawowych formatach plików.
Zawijanie💃
To podsumowuje naszą eksplorację jednych z najlepszych bibliotek Pythona dla naukowców zajmujących się danymi i ekspertów od uczenia maszynowego.
Jak pokazuje ten artykuł, Python ma bardziej przydatne pakiety do uczenia maszynowego i nauki o danych. Python ma inne biblioteki, które możesz zastosować w innych obszarach.
Możesz chcieć poznać jedne z najlepszych notatników do nauki danych.
Miłej nauki!