

Uczenie się zespołowe może pomóc w podejmowaniu lepszych decyzji i rozwiązywaniu wielu rzeczywistych problemów poprzez łączenie decyzji z kilku modeli.
Uczenie maszynowe (ML) rozwija swoje skrzydła w wielu sektorach i branżach, niezależnie od tego, czy chodzi o finanse, medycynę, tworzenie aplikacji czy bezpieczeństwo.
Właściwe szkolenie modeli ML pomoże Ci osiągnąć większy sukces w Twojej firmie lub roli zawodowej, a istnieją różne metody, aby to osiągnąć.
W tym artykule omówię uczenie się zespołowe, jego znaczenie, przypadki użycia i techniki.
Czekać na dalsze informacje!
Spis treści:
Czym jest nauka zespołowa?
W uczeniu maszynowym i statystyce „zespół” odnosi się do metod generujących różne hipotezy przy użyciu wspólnego podstawowego ucznia.
A uczenie zespołowe to podejście do uczenia maszynowego, w którym wiele modeli (takich jak eksperci lub klasyfikatory) jest tworzonych strategicznie i łączonych w celu rozwiązania problemu obliczeniowego lub dokonania lepszych prognoz.
Podejście to ma na celu poprawę wydajności przewidywania, aproksymacji funkcji, klasyfikacji itp. danego modelu. Jest to również stosowane w celu wyeliminowania możliwości wybrania przez Ciebie kiepskiego lub mniej wartościowego modelu spośród wielu. Aby osiągnąć lepszą wydajność predykcyjną, stosuje się kilka algorytmów uczenia się.
Znaczenie uczenia się zespołowego w ML
W modelach uczenia maszynowego istnieją pewne źródła, takie jak odchylenie, wariancja i szum, które mogą powodować błędy. Uczenie zespołowe może pomóc zredukować te źródła błędów i zapewnić stabilność i dokładność algorytmów uczenia maszynowego.
Oto dlaczego uczenie się zespołowe jest wykorzystywane w różnych scenariuszach:
Wybór właściwego klasyfikatora
Uczenie zespołowe pomaga wybrać lepszy model lub klasyfikator, jednocześnie zmniejszając ryzyko, które może wynikać z niewłaściwego wyboru modelu.

Istnieją różne typy klasyfikatorów używanych do różnych problemów, takie jak maszyny wektorów nośnych (SVM), perceptron wielowarstwowy (MLP), naiwne klasyfikatory Bayesa, drzewa decyzyjne itp. Ponadto istnieją różne realizacje algorytmów klasyfikacji, które należy wybrać . Wydajność różnych danych treningowych może być również różna.
Ale zamiast wybierać tylko jeden model, jeśli użyjesz zespołu wszystkich tych modeli i połączysz ich indywidualne wyniki, możesz uniknąć wyboru gorszych modeli.
Wolumen danych
Wiele metod i modeli ML nie jest tak skutecznych w swoich wynikach, jeśli dostarczasz im nieodpowiednich danych lub dużej ilości danych.
Z drugiej strony uczenie zespołowe może działać w obu scenariuszach, nawet jeśli ilość danych jest za mała lub za duża.
- Jeśli dane są niewystarczające, możesz użyć ładowania początkowego do trenowania różnych klasyfikatorów za pomocą różnych próbek danych ładowania początkowego.
- Jeśli istnieje duża ilość danych, która może utrudnić uczenie pojedynczego klasyfikatora, można strategicznie podzielić dane na mniejsze podzbiory.
Złożoność

Pojedynczy klasyfikator może nie być w stanie rozwiązać niektórych bardzo złożonych problemów. Ich granice decyzyjne oddzielające dane różnych klas mogą być bardzo złożone. Tak więc, jeśli zastosujesz liniowy klasyfikator do nieliniowej, złożonej granicy, nie będzie on w stanie się go nauczyć.
Jednak po odpowiednim połączeniu zespołu odpowiednich, liniowych klasyfikatorów można sprawić, by nauczył się on danej nieliniowej granicy. Klasyfikator podzieli dane na wiele łatwych do nauczenia się i mniejszych partycji, a każdy klasyfikator nauczy się tylko jednej prostszej partycji. Następnie różne klasyfikatory zostaną połączone w celu uzyskania ok. granica decyzyjna.
Szacowanie ufności
W uczeniu się zespołowym wotum zaufania jest przypisywane decyzji podjętej przez system. Załóżmy, że masz zespół różnych klasyfikatorów przeszkolonych w zakresie danego problemu. Jeśli większość klasyfikatorów zgadza się z podjętą decyzją, jej wynik można traktować jako zespół z decyzją o wysokim stopniu pewności.
Z drugiej strony, jeśli połowa klasyfikatorów nie zgadza się z podjętą decyzją, mówi się, że jest to zespół z niską pewnością decyzji.
Jednak niska lub wysoka pewność nie zawsze jest właściwą decyzją. Istnieje jednak duże prawdopodobieństwo, że podjęta z dużą pewnością decyzja będzie słuszna, jeśli zespół jest odpowiednio wyszkolony.
Dokładność dzięki Data Fusion
Dane zebrane z wielu źródeł, połączone strategicznie, mogą poprawić dokładność decyzji klasyfikacyjnych. Dokładność ta jest wyższa niż uzyskana przy pomocy jednego źródła danych.
Jak działa nauka zespołowa?
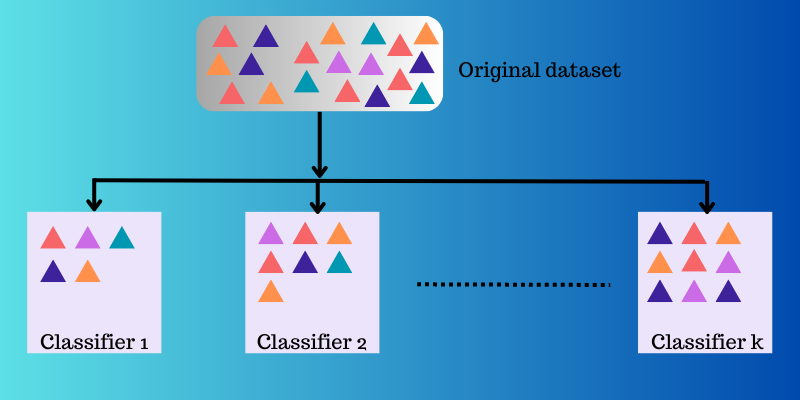
Uczenie zespołowe wykorzystuje wiele funkcji mapowania, których nauczyły się różne klasyfikatory, a następnie łączy je w celu utworzenia jednej funkcji mapowania.
Oto przykład, jak działa uczenie się zespołowe.
Przykład: Tworzysz aplikację opartą na żywności dla użytkowników końcowych. Aby zapewnić użytkownikom wysoką jakość, chcesz zebrać ich opinie na temat problemów, z którymi się borykają, widocznych luk, błędów, błędów itp.
W tym celu możesz zasięgnąć opinii swojej rodziny, przyjaciół, współpracowników i innych osób, z którymi często się komunikujesz, na temat ich wyborów żywieniowych i ich doświadczeń związanych z zamawianiem jedzenia przez Internet. Możesz także udostępnić swoją aplikację w wersji beta, aby zbierać opinie w czasie rzeczywistym bez uprzedzeń i szumów.
Tak więc to, co tak naprawdę tutaj robisz, polega na rozważeniu wielu pomysłów i opinii różnych osób, aby poprawić wrażenia użytkownika.
Uczenie się zespołowe i jego modele działają w podobny sposób. Wykorzystuje zestaw modeli i łączy je w celu uzyskania ostatecznego wyniku w celu poprawy dokładności i wydajności przewidywania.
Podstawowe techniki uczenia się w grupie
# 1. Tryb
„Tryb” to wartość pojawiająca się w zbiorze danych. W uczeniu się zespołowym specjaliści ML używają wielu modeli do tworzenia prognoz dotyczących każdego punktu danych. Prognozy te są traktowane jako indywidualne głosy, a prognozy dokonane przez większość modeli są uważane za prognozy ostateczne. Jest używany głównie w problemach z klasyfikacją.
Przykład: Cztery osoby oceniły twoją aplikację na 4, podczas gdy jedna z nich oceniła ją na 3, wtedy tryb byłby równy 4, ponieważ większość głosowała na 4.
#2. Średnia/Średnia
Korzystając z tej techniki, profesjonaliści biorą pod uwagę wszystkie prognozy modelu i obliczają ich średnią, aby uzyskać ostateczną prognozę. Jest używany głównie do przewidywania problemów z regresją, obliczania prawdopodobieństw w problemach z klasyfikacją i nie tylko.
Przykład: w powyższym przykładzie, w którym cztery osoby oceniły Twoją aplikację na 4, a jedna na 3, średnia wyniosłaby (4+4+4+4+3)/5=3,8
#3. Średnia ważona
W tej metodzie uczenia się zespołowego profesjonaliści przydzielają różne wagi różnym modelom w celu dokonania prognozy. W tym przypadku przypisana waga opisuje istotność każdego modelu.
Przykład: Załóżmy, że 5 osób przekazało opinię na temat Twojej aplikacji. Spośród nich 3 to programiści aplikacji, a 2 nie ma żadnego doświadczenia w tworzeniu aplikacji. Tak więc opinie tych 3 osób będą miały większą wagę niż pozostałe 2 osoby.
Zaawansowane techniki uczenia się zespołowego
# 1. Parcianka
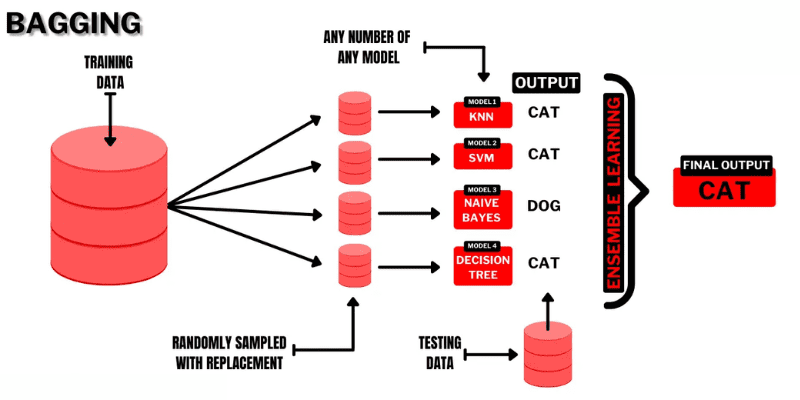
Bagging (Bootstrap AGGregatING) to wysoce intuicyjna i prosta technika uczenia się zespołowego z dobrymi wynikami. Jak sama nazwa wskazuje, powstaje z połączenia dwóch terminów „Bootstrap” i „agregacja”.
Bootstrapping to kolejna metoda próbkowania, w której będziesz musiał utworzyć podzbiory kilku obserwacji pobranych z oryginalnego zestawu danych z zamianą. Tutaj rozmiar podzbioru będzie taki sam jak rozmiar oryginalnego zestawu danych.
 Źródło: programista Buggy
Źródło: programista Buggy
Tak więc w workowaniu podzbiory lub torby są używane do zrozumienia dystrybucji pełnego zestawu. Jednak podzbiory mogą być mniejsze niż oryginalny zestaw danych w workach. Ta metoda obejmuje pojedynczy algorytm ML. Celem połączenia wyników różnych modeli jest uzyskanie uogólnionego wyniku.
Oto jak działa pakowanie:
- Z oryginalnego zestawu generowanych jest kilka podzbiorów, a obserwacje są wybierane z zamianami. Podzbiory są używane w szkoleniu modeli lub drzew decyzyjnych.
- Dla każdego podzbioru tworzony jest słaby lub podstawowy model. Modele będą od siebie niezależne i będą działać równolegle.
- Ostateczna prognoza zostanie sporządzona poprzez połączenie każdej prognozy z każdego modelu przy użyciu statystyk, takich jak uśrednianie, głosowanie itp.
Popularne algorytmy stosowane w tej technice zespołowej to:
- Przypadkowy las
- Spakowane drzewa decyzyjne
Zaletą tej metody jest to, że pomaga ograniczyć do minimum błędy wariancji w drzewach decyzyjnych.
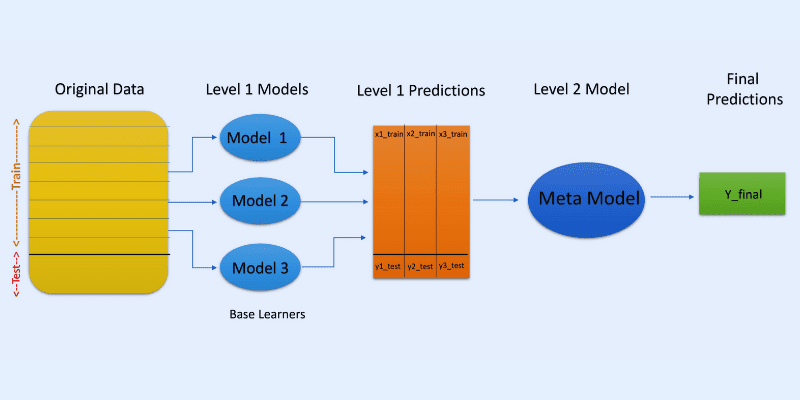
#2. Układanie
 Źródło obrazu: OpenGenus IQ
Źródło obrazu: OpenGenus IQ
W układaniu w stosy lub w uogólnianiu skumulowanym prognozy z różnych modeli, takich jak drzewo decyzyjne, są wykorzystywane do tworzenia nowego modelu do przewidywania tego zestawu testów.
Układanie obejmuje tworzenie ładowanych podzbiorów danych dla modeli szkoleniowych, podobnie jak w przypadku pakowania. Ale tutaj dane wyjściowe modeli są traktowane jako dane wejściowe do innego klasyfikatora, znanego jako meta-klasyfikator do ostatecznej prognozy próbek.
Powodem, dla którego używane są dwie warstwy klasyfikatora, jest określenie, czy uczące zestawy danych są odpowiednio uczone. Chociaż podejście dwuwarstwowe jest powszechne, można również zastosować więcej warstw.
Na przykład możesz użyć 3-5 modeli w pierwszej warstwie lub poziomie 1 i jednego modelu w warstwie 2 lub poziomie 2. Ten ostatni połączy prognozy uzyskane na poziomie 1, aby stworzyć ostateczną prognozę.
Ponadto możesz użyć dowolnego modelu uczenia się ML do agregowania prognoz; model liniowy, taki jak regresja liniowa, regresja logistyczna itp., jest powszechny.
Popularne algorytmy ML używane w układaniu to:
- Mieszanie
- Super zespół
- Ułożone modele
Uwaga: Mieszanie używa zestawu sprawdzania poprawności lub wstrzymania z zestawu danych szkoleniowych do tworzenia predykcji. W przeciwieństwie do układania w stosy, mieszanie obejmuje przewidywania, które należy wykonać tylko na podstawie wstrzymania.
#3. Wzmocnienie
Boosting to iteracyjna metoda uczenia zespołowego, która dostosowuje wagę określonej obserwacji w zależności od jej ostatniej lub poprzedniej klasyfikacji. Oznacza to, że każdy kolejny model ma na celu poprawienie błędów znalezionych w poprzednim modelu.
Jeśli obserwacja nie zostanie poprawnie sklasyfikowana, to wzmocnienie zwiększa wagę obserwacji.
Podczas boostingu profesjonaliści trenują pierwszy algorytm boostingu na pełnym zbiorze danych. Następnie budują kolejne algorytmy ML, wykorzystując reszty wyodrębnione z poprzedniego algorytmu wzmacniającego. W związku z tym większą wagę przywiązuje się do błędnych obserwacji przewidywanych przez poprzedni model.
Oto jak to działa krok po kroku:
- Podzbiór zostanie wygenerowany z oryginalnego zestawu danych. Każdy punkt danych będzie miał początkowo taką samą wagę.
- Tworzenie modelu bazowego odbywa się na podzbiorze.
- Prognoza zostanie wykonana na pełnym zbiorze danych.
- Na podstawie rzeczywistych i przewidywanych wartości zostaną obliczone błędy.
- Nieprawidłowo przewidywanym obserwacjom zostaną nadane większe wagi
- Zostanie utworzony nowy model i na tym zbiorze danych zostanie dokonana ostateczna predykcja, podczas gdy model będzie próbował poprawić wcześniej popełnione błędy. Wiele modeli zostanie utworzonych w podobny sposób, a każdy poprawi poprzednie błędy
- Ostateczna prognoza zostanie wykonana na podstawie ostatecznego modelu, który jest średnią ważoną wszystkich modeli.
Popularne algorytmy wzmacniające to:
- CatBoost
- Lekki GBM
- AdaBoost
Zaletą wzmacniania jest to, że generuje lepsze prognozy i zmniejsza błędy spowodowane stronniczością.
Inne techniki zespołowe

Mieszanka Ekspertów: jest używana do trenowania wielu klasyfikatorów, a ich wyniki są grupowane z ogólną zasadą liniową. Tutaj wagi nadawane kombinacjom są określane przez model, który można wyszkolić.
Głosowanie większościowe: polega na wybraniu nieparzystego klasyfikatora, a prognozy są obliczane dla każdej próbki. Klasa otrzymująca maksymalną klasę z puli klasyfikatorów będzie przewidywaną klasą zespołu. Służy do rozwiązywania problemów, takich jak klasyfikacja binarna.
Reguła Maxa: wykorzystuje rozkłady prawdopodobieństwa każdego klasyfikatora i wykorzystuje zaufanie do przewidywania. Jest używany do problemów z klasyfikacją wieloklasową.
Prawdziwe przypadki użycia uczenia się zespołowego
# 1. Wykrywanie twarzy i emocji
Uczenie zespołowe wykorzystuje techniki takie jak niezależna analiza komponentów (ICA) do wykrywania twarzy.
Co więcej, uczenie się zespołowe jest wykorzystywane do wykrywania emocji osoby poprzez wykrywanie mowy. Ponadto jego możliwości pomagają użytkownikom w wykrywaniu emocji na twarzy.
#2. Bezpieczeństwo
Wykrywanie oszustw: uczenie zespołowe pomaga zwiększyć moc modelowania normalnego zachowania. Dlatego uważa się, że jest skuteczny w wykrywaniu oszukańczych działań, na przykład w systemach kart kredytowych i bankowych, oszustwach telekomunikacyjnych, praniu brudnych pieniędzy itp.

DDoS: Rozproszona odmowa usługi (DDoS) to śmiertelny atak na dostawcę usług internetowych. Klasyfikatory Ensemble mogą ograniczać wykrywanie błędów, a także odróżniać ataki od prawdziwego ruchu.
Wykrywanie włamań: Uczenie grupowe może być wykorzystywane w systemach monitorowania, takich jak narzędzia do wykrywania włamań do wykrywania kodów intruzów poprzez monitorowanie sieci lub systemów, wykrywanie anomalii i tak dalej.
Wykrywanie złośliwego oprogramowania: uczenie zespołowe jest dość skuteczne w wykrywaniu i klasyfikowaniu kodu złośliwego oprogramowania, takiego jak wirusy komputerowe i robaki, oprogramowanie ransomware, konie trojańskie, oprogramowanie szpiegujące itp. przy użyciu technik uczenia maszynowego.
#3. Nauka przyrostowa
W uczeniu przyrostowym algorytm ML uczy się z nowego zestawu danych, zachowując poprzednie nauki, ale bez dostępu do poprzednich danych, które widział. Systemy Ensemble są używane w uczeniu przyrostowym, zmuszając je do uczenia się dodawanego klasyfikatora dla każdego zbioru danych, gdy tylko staje się on dostępny.
#4. Medycyna
Klasyfikatory zespołowe są przydatne w dziedzinie diagnostyki medycznej, takiej jak wykrywanie zaburzeń neurokognitywnych (takich jak choroba Alzheimera). Wykonuje wykrywanie, pobierając zestawy danych MRI jako dane wejściowe i klasyfikując cytologię szyjki macicy. Poza tym ma zastosowanie w proteomice (badanie białek), neuronauce i innych dziedzinach.
#5. Zdalne wykrywanie
Wykrywanie zmian: Klasyfikatory zespołowe są używane do wykrywania zmian za pomocą metod takich jak średnia bayesowska i głosowanie większościowe.
Mapowanie pokrycia terenu: Zespołowe metody uczenia się, takie jak wzmacnianie, drzewa decyzyjne, analiza głównych składników jądra (KPCA) itp., są wykorzystywane do skutecznego wykrywania i mapowania pokrycia terenu.
#6. Finanse
Dokładność jest krytycznym aspektem finansów, niezależnie od tego, czy chodzi o obliczenia, czy prognozy. Ma duży wpływ na wyniki podejmowanych decyzji. Mogą one również analizować zmiany danych giełdowych, wykrywać manipulacje cenami akcji i nie tylko.
Dodatkowe zasoby szkoleniowe

# 1. Zespołowe metody uczenia maszynowego
Ta książka pomoże ci nauczyć się i wdrożyć od podstaw ważne metody uczenia się zespołowego.
#2. Metody zespołowe: podstawy i algorytmy
Ta książka zawiera podstawy uczenia się zespołowego i jego algorytmów. Przedstawia również, w jaki sposób jest używany w prawdziwym świecie.
#3. Nauka zespołowa
Oferuje wprowadzenie do ujednoliconej metody zespołowej, wyzwań, aplikacji itp.
#4. Ensemble Machine Learning: metody i zastosowania:
Zapewnia szeroki zakres zaawansowanych technik uczenia się zespołowego.
Wniosek
Mam nadzieję, że masz teraz jakieś pojęcie o uczeniu się zespołowym, jego metodach, przypadkach użycia i dlaczego korzystanie z niego może być korzystne dla twojego przypadku użycia. Ma potencjał, aby rozwiązać wiele rzeczywistych wyzwań, od dziedziny bezpieczeństwa i tworzenia aplikacji po finanse, medycynę i wiele innych. Jego zastosowania się rozszerzają, więc prawdopodobnie w najbliższej przyszłości nastąpi więcej ulepszeń w tej koncepcji.
Możesz także zapoznać się z niektórymi narzędziami do generowania danych syntetycznych w celu trenowania modeli uczenia maszynowego