
Apache Parquet zapewnia szereg korzyści w zakresie przechowywania i wyszukiwania danych w porównaniu z tradycyjnymi metodami, takimi jak CSV.
Format parkietu jest przeznaczony do szybszego przetwarzania danych złożonych typów. W tym artykule mówimy o tym, jak format Parquet jest odpowiedni dla dzisiejszych, stale rosnących potrzeb w zakresie danych.
Zanim zagłębimy się w szczegóły formatu Parquet, zrozummy, czym są dane CSV i jakie wyzwania stawiają przed przechowywaniem danych.
Spis treści:
Co to jest przechowywanie plików CSV?
Wszyscy dużo słyszeliśmy o CSV (wartości oddzielone przecinkami) – jednym z najczęstszych sposobów organizowania i formatowania danych. Przechowywanie danych CSV jest oparte na wierszach. Pliki CSV są przechowywane z rozszerzeniem .csv. Możemy przechowywać i otwierać dane CSV za pomocą Excela, Arkuszy Google lub dowolnego edytora tekstu. Dane są łatwo widoczne po otwarciu pliku.
Cóż, to nie jest dobre – zdecydowanie nie dla formatu bazy danych.
Co więcej, wraz ze wzrostem ilości danych, wykonywanie zapytań, zarządzanie i pobieranie staje się trudne.
Oto przykład danych przechowywanych w pliku .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Jeśli spojrzymy na to w Excelu, możemy zobaczyć strukturę wiersz-kolumna, jak poniżej:
Wyzwania związane z przechowywaniem plików CSV
Magazyny oparte na wierszach, takie jak CSV, nadają się do operacji tworzenia, aktualizacji i usuwania.
A co z Read w CRUD?
Wyobraź sobie milion wierszy w powyższym pliku .csv. Otwarcie pliku i wyszukanie danych, których szukasz, zajęłoby rozsądną ilość czasu. Nie tak fajnie. Większość dostawców usług w chmurze, takich jak AWS, pobiera opłaty od firm na podstawie ilości skanowanych lub przechowywanych danych – ponownie pliki CSV zajmują dużo miejsca.
Magazyn CSV nie ma wyłącznej opcji przechowywania metadanych, co sprawia, że skanowanie danych jest żmudnym zadaniem.
Więc jakie jest opłacalne i optymalne rozwiązanie do wykonywania wszystkich operacji CRUD? Zbadajmy.
Co to jest przechowywanie danych Parkiet?
Parkiet to format pamięci masowej typu open source do przechowywania danych. Jest szeroko stosowany w ekosystemach Hadoop i Spark. Pliki parkietów są przechowywane z rozszerzeniem .parquet.
Parkiet to format o wysokiej strukturze. Może być również używany do optymalizacji złożonych surowych danych obecnych w dużych ilościach w jeziorach danych. Może to znacznie skrócić czas zapytania.
Parquet sprawia, że przechowywanie danych jest wydajne i szybsze, dzięki połączeniu formatów przechowywania opartych na wierszach i kolumnach (hybrydowych). W tym formacie dane są podzielone na partycje zarówno poziomo, jak i pionowo. Format parkietu w dużym stopniu eliminuje również narzuty związane z analizowaniem.
Format ogranicza ogólną liczbę operacji we/wy i ostatecznie koszt.
Parquet przechowuje również metadane, które przechowują informacje o danych, takie jak schemat danych, liczba wartości, lokalizacja kolumn, wartość minimalna, maksymalna liczba grup wierszy, rodzaj kodowania itp. Metadane są przechowywane na różnych poziomach w pliku , przyspieszając dostęp do danych.
W dostępie opartym na wierszach, takim jak CSV, pobieranie danych zajmuje trochę czasu, ponieważ zapytanie musi przejść przez każdy wiersz i uzyskać określone wartości kolumn. Dzięki schowkowi na parkiet wszystkie wymagane kolumny są dostępne od razu.
W podsumowaniu,
- Parkiet oparty jest na konstrukcji kolumnowej do przechowywania danych
- Jest to zoptymalizowany format danych do zbiorczego przechowywania złożonych danych w systemach pamięci masowej
- Format parkietu obejmuje różne metody kompresji i kodowania danych
- Znacznie skraca czas skanowania danych i czas wykonywania zapytań oraz zajmuje mniej miejsca na dysku w porównaniu z innymi formatami przechowywania, takimi jak CSV
- Minimalizuje liczbę operacji IO, obniżając koszt przechowywania i wykonywania zapytań
- Zawiera metadane, które ułatwiają wyszukiwanie danych
- Zapewnia wsparcie open source
Format danych parkietu
Zanim przejdziemy do przykładu, przyjrzyjmy się bardziej szczegółowo, jak dane są przechowywane w formacie Parquet:
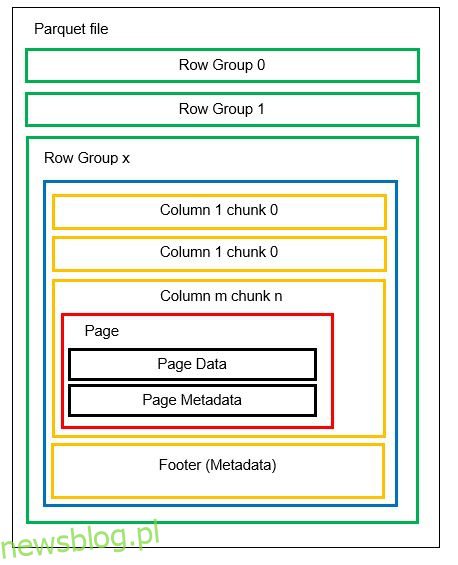
W jednym pliku możemy mieć wiele partycji poziomych zwanych grupami wierszy. W każdej grupie wierszy stosowane jest partycjonowanie pionowe. Kolumny są podzielone na kilka fragmentów kolumn. Dane są przechowywane jako strony wewnątrz fragmentów kolumn. Każda strona zawiera zakodowane wartości danych i metadane. Jak wspomnieliśmy wcześniej, metadane całego pliku są również przechowywane w stopce pliku na poziomie grupy wierszy.
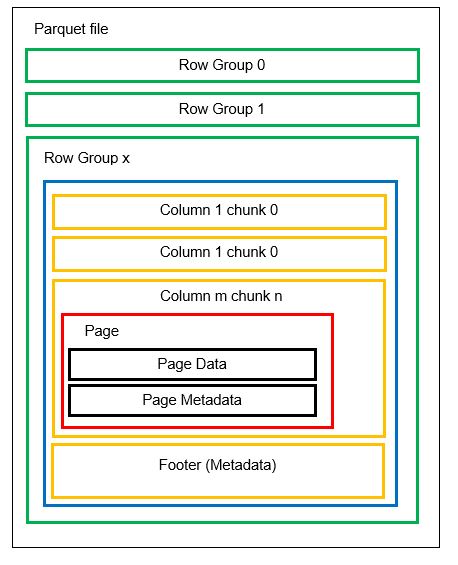
Ponieważ dane są dzielone na porcje kolumn, dodawanie nowych danych przez zakodowanie nowych wartości w nowej porcji i pliku jest również łatwe. Metadane są następnie aktualizowane dla plików i grup wierszy, których dotyczy problem. Można więc powiedzieć, że Parkiet jest formatem elastycznym.
Parquet natywnie obsługuje kompresję danych przy użyciu technik kompresji stron i kodowania słownika. Zobaczmy prosty przykład kompresji słownika:
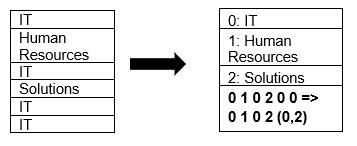
Zauważ, że w powyższym przykładzie widzimy podział IT 4 razy. Tak więc podczas przechowywania w słowniku format koduje dane z inną łatwą do przechowywania wartością (0,1,2…) wraz z liczbą powtórzeń w sposób ciągły – IT, IT zmienia się na 0,2, aby zapisać więcej przestrzeni. Zapytanie o dane skompresowane zajmuje mniej czasu.
Bezpośrednie porównanie
Teraz, gdy mamy już dobre wyobrażenie o tym, jak wyglądają formaty CSV i Parquet, czas na statystyki, aby porównać oba formaty:
CSV
Parkiet
Format przechowywania oparty na wierszach.
Hybryda formatów przechowywania opartych na wierszach i kolumnach.
Zużywa dużo miejsca, ponieważ nie jest dostępna domyślna opcja kompresji. Na przykład plik o pojemności 1 TB zajmie to samo miejsce, gdy jest przechowywany w Amazon S3 lub dowolnej innej chmurze.
Kompresuje dane podczas przechowywania, dzięki czemu zajmuje mniej miejsca. Plik o pojemności 1 TB zapisany w formacie Parquet zajmie tylko 130 GB miejsca.
Czas wykonywania zapytania jest powolny z powodu wyszukiwania opartego na wierszach. Dla każdej kolumny należy pobrać każdy wiersz danych.
Czas zapytania jest około 34 razy szybszy ze względu na przechowywanie oparte na kolumnach i obecność metadanych.
Więcej danych musi zostać zeskanowanych na zapytanie.
Około 99% mniej danych jest skanowanych w celu wykonania zapytania, optymalizując w ten sposób wydajność.
Większość urządzeń pamięci masowej pobiera opłaty na podstawie dostępnej przestrzeni, więc format CSV oznacza wysoki koszt przechowywania.
Mniejsze koszty przechowywania, ponieważ dane są przechowywane w skompresowanym, zakodowanym formacie.
Schemat pliku musi być albo wywnioskowany (prowadzący do błędów) albo dostarczony (nudny).
Schemat pliku jest przechowywany w metadanych.
Format jest odpowiedni dla prostych typów danych.
Parkiet nadaje się nawet do złożonych typów, takich jak zagnieżdżone schematy, tablice, słowniki.
Wniosek 👩💻
Widzieliśmy na przykładach, że Parquet jest bardziej wydajny niż CSV pod względem kosztów, elastyczności i wydajności. Jest to skuteczny mechanizm przechowywania i pobierania danych, zwłaszcza gdy cały świat zmierza w kierunku przechowywania w chmurze i optymalizacji przestrzeni. Wszystkie główne platformy, takie jak Azure, AWS i BigQuery, obsługują format Parquet.