
Z biegiem lat wykorzystanie Pythona do analizy danych wzrosło niesamowicie i rośnie z każdym dniem.
Nauka o danych to rozległa dziedzina nauki z wieloma poddziedzinami, z których analiza danych jest bezsprzecznie jedną z najważniejszych ze wszystkich tych dziedzin, i niezależnie od poziomu umiejętności w nauce o danych coraz ważniejsze staje się zrozumienie lub mieć przynajmniej podstawową wiedzę na ten temat.
Spis treści:
Czym jest analiza danych?
Analiza danych to oczyszczanie i przekształcanie dużej ilości nieustrukturyzowanych lub niezorganizowanych danych w celu wygenerowania kluczowych spostrzeżeń i informacji o tych danych, które pomogłyby w podejmowaniu świadomych decyzji.
Istnieją różne narzędzia używane do analizy danych, Python, Microsoft Excel, Tableau, SaS itp., ale w tym artykule skupimy się na tym, jak odbywa się analiza danych w Pythonie. Dokładniej, jak to się robi z biblioteką Pythona o nazwie Pandy.
Co to są pandy?
Pandas to biblioteka Pythona o otwartym kodzie źródłowym, używana do manipulacji danymi i kłótni. Jest szybki i bardzo wydajny oraz posiada narzędzia do ładowania kilku rodzajów danych do pamięci. Może być używany do przekształcania, etykietowania fragmentów, indeksowania, a nawet grupowania kilku form danych.
Struktury danych w pandach
W Pandach są 3 struktury danych, a mianowicie;
Najlepszym sposobem na rozróżnienie trzech z nich jest zobaczenie, że jeden zawiera kilka stosów drugiego. Więc DataFrame to stos serii, a Panel to stos DataFrame.
Seria to jednowymiarowa tablica
Stos kilku serii tworzy dwuwymiarową ramkę danych
Stos kilku ramek danych tworzy trójwymiarowy panel
Struktura danych, z którą będziemy pracować najczęściej, to dwuwymiarowa ramka DataFrame, która może być również domyślnym sposobem reprezentacji niektórych zestawów danych, z którymi możemy się spotkać.
Analiza danych w pandach
Ten artykuł nie wymaga instalacji. Używalibyśmy narzędzia o nazwie współpracujący stworzony przez Google’a. Jest to środowisko Pythona online do analizy danych, uczenia maszynowego i sztucznej inteligencji. Jest to po prostu oparty na chmurze Jupyter Notebook, który jest preinstalowany z prawie każdym pakietem Pythona, którego potrzebujesz jako analityk danych.
Teraz kieruj się do https://colab.research.google.com/notebooks/intro.ipynb. Powinieneś zobaczyć poniższe.
W lewym górnym rogu nawigacji kliknij opcję pliku i kliknij opcję „nowy notatnik”. Zobaczysz nową stronę notatnika Jupyter załadowaną w przeglądarce. Pierwszą rzeczą, którą musimy zrobić, to zaimportować pandy do naszego środowiska pracy. Możemy to zrobić, uruchamiając następujący kod;
import pandas as pd
W tym artykule do analizy danych użylibyśmy zestawu danych o cenach mieszkań. Zestaw danych, którego byśmy używali, można znaleźć tutaj. Pierwszą rzeczą, którą chcielibyśmy zrobić, to załadować ten zestaw danych do naszego środowiska.
Możemy to zrobić za pomocą następującego kodu w nowej komórce;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
.read_csv jest używany, gdy chcemy odczytać plik CSV i przekazaliśmy właściwość sep, aby pokazać, że plik CSV jest rozdzielany przecinkami.
Należy również zauważyć, że nasz załadowany plik CSV jest przechowywany w zmiennej df .
Nie musimy używać funkcji print() w Jupyter Notebook. Możemy po prostu wpisać nazwę zmiennej w naszej komórce, a Jupyter Notebook wydrukuje ją dla nas.
Możemy to wypróbować, wpisując df w nowej komórce i uruchamiając ją, wydrukuje dla nas wszystkie dane w naszym zbiorze danych jako DataFrame.
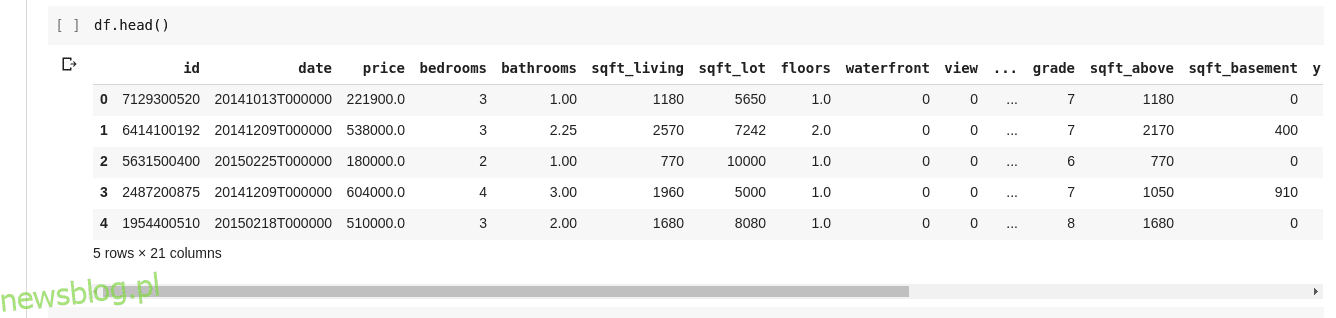
Ale nie zawsze chcemy zobaczyć wszystkie dane, czasami chcemy zobaczyć tylko kilka pierwszych danych i ich nazwy kolumn. Możemy użyć funkcji df.head() do wyświetlenia pierwszych pięciu kolumn i df.tail() do wyświetlenia ostatnich pięciu. Wynik jednego z tych dwóch wyglądałby tak;
Chcielibyśmy sprawdzić relacje między tymi kilkoma wierszami i kolumnami danych. Funkcja .describe() robi to za nas.
Uruchomienie df.describe() daje następujące dane wyjściowe;
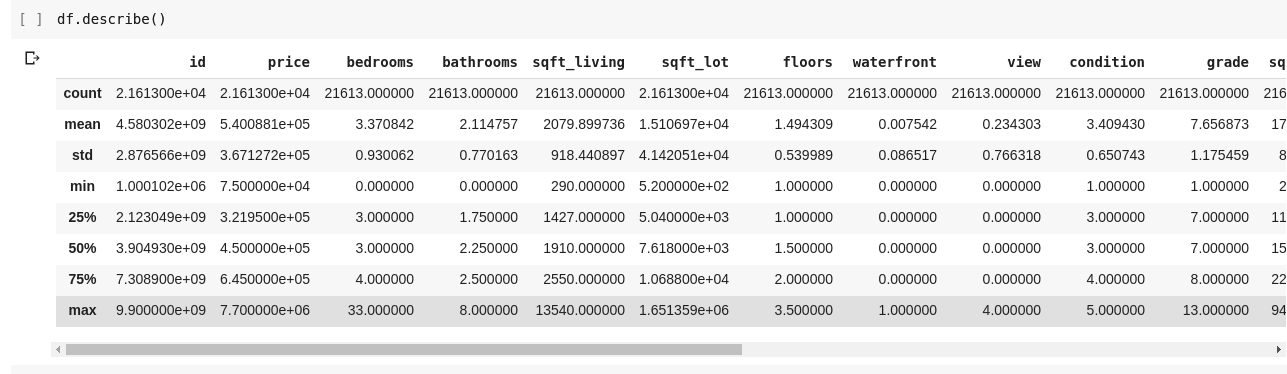
Od razu widać, że .describe() podaje średnią, odchylenie standardowe, wartości minimalne i maksymalne oraz percentyle każdej kolumny w DataFrame. Jest to szczególnie przydatne.
Możemy również sprawdzić kształt naszej ramki 2D DataFrame, aby dowiedzieć się, ile ma wierszy i kolumn. Możemy to zrobić za pomocą df.shape, który zwraca krotkę w formacie (wiersze, kolumny).
Możemy również sprawdzić nazwy wszystkich kolumn w naszej DataFrame za pomocą df.columns.
Co jeśli chcemy wybrać tylko jedną kolumnę i zwrócić w niej wszystkie dane? Odbywa się to w sposób podobny do krojenia słownika. Wpisz następujący kod w nowej komórce i uruchom go
df['price ']
Powyższy kod zwraca kolumnę ceny, możemy pójść dalej, zapisując ją jako taką w nowej zmiennej
price = df['price']
Teraz możemy wykonać każdą inną akcję, którą można wykonać na DataFrame na naszej zmiennej ceny, ponieważ jest to tylko podzbiór rzeczywistej DataFrame. Możemy robić rzeczy takie jak df.head(), df.shape itp.
Możemy również wybrać wiele kolumn, przekazując listę nazw kolumn do df jako takiej
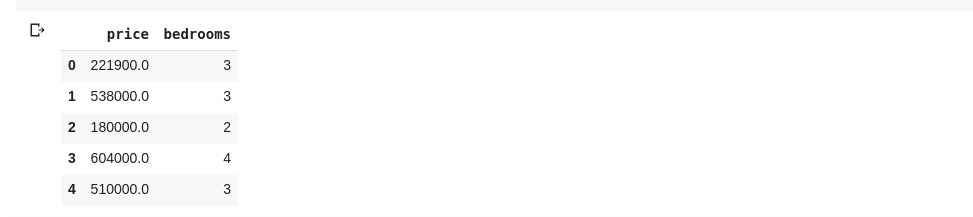
data = df[['price ', 'bedrooms']]
Powyższe wybiera kolumny o nazwach „cena” i „sypialnie”, jeśli wpiszemy data.head() do nowej komórki, otrzymamy następujące
Powyższy sposób krojenia kolumn zwraca wszystkie elementy wierszy w tej kolumnie, co jeśli chcemy zwrócić podzbiór wierszy i podzbiór kolumn z naszego zbioru danych? Można to zrobić za pomocą .iloc i jest indeksowane w sposób podobny do list Pythona. Więc możemy zrobić coś takiego
df.iloc[50: , 3]
Który zwraca trzecią kolumnę od 50. rzędu do końca. Jest całkiem schludny i tak samo jak krojenie list w pythonie.
Teraz zróbmy kilka naprawdę interesujących rzeczy, nasz zestaw danych o cenach mieszkań ma kolumnę, która mówi nam o cenie domu, a inna kolumna mówi nam o liczbie sypialni, które ma ten konkretny dom. Cena mieszkania jest wartością ciągłą, więc możliwe, że nie mamy dwóch domów o tej samej cenie. Ale liczba sypialni jest dość dyskretna, więc możemy mieć kilka domów z dwiema, trzema, czterema sypialniami itp.
Co jeśli chcemy uzyskać wszystkie domy z taką samą liczbą sypialni i znaleźć średnią cenę każdej oddzielnej sypialni? Jest to stosunkowo łatwe do zrobienia w pandach, można to zrobić jako takie;
df.groupby('bedrooms ')['price '].mean()
Powyższe najpierw grupuje DataFrame według zestawów danych z identycznym numerem sypialni za pomocą funkcji df.groupby() , następnie mówimy jej, aby dała nam tylko kolumnę sypialni i użyła funkcji .mean() do znalezienia średniej dla każdego domu w zbiorze danych .
Co jeśli chcemy zwizualizować powyższe? Chcielibyśmy móc sprawdzić, jak zmienia się średnia cena każdego odrębnego numeru sypialni? Musimy tylko połączyć poprzedni kod z funkcją .plot() jako taką;
df.groupby('bedrooms ')['price '].mean().plot()
Otrzymamy dane wyjściowe, które wyglądają tak;
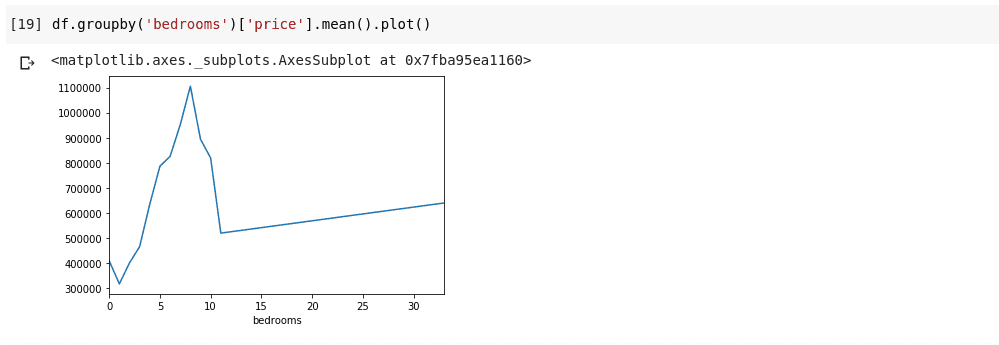
Powyższe pokazuje nam pewne trendy w danych. Na osi poziomej mamy wyraźną liczbę sypialni (Zauważ, że więcej niż jeden dom może mieć X sypialni), Na osi pionowej mamy średnią cen w odniesieniu do odpowiedniej liczby sypialni na poziomie oś. Od razu możemy zauważyć, że domy posiadające od 5 do 10 sypialni kosztują znacznie więcej niż domy z 3 sypialniami. Stanie się również oczywiste, że domy z około 7 lub 8 sypialniami kosztują znacznie więcej niż te z 15, 20 lub nawet 30 pokojami.
Informacje takie jak powyższe są powodem, dla którego analiza danych jest bardzo ważna, jesteśmy w stanie wydobyć z danych przydatny wgląd, który nie jest natychmiast lub całkowicie niemożliwy do zauważenia bez analizy.
Brakujące dane
Załóżmy, że przeprowadzam ankietę składającą się z serii pytań. Udostępniam link do ankiety tysiącom ludzi, aby mogli wyrazić swoją opinię. Moim ostatecznym celem jest przeprowadzenie analizy danych na tych danych, abym mógł uzyskać z nich kilka kluczowych spostrzeżeń.
Teraz wiele może pójść nie tak, niektórzy geodeci mogą czuć się niekomfortowo, odpowiadając na niektóre z moich pytań i zostawiając to pole puste. Wiele osób mogłoby zrobić to samo dla kilku części moich pytań ankietowych. Może to nie być uważane za problem, ale wyobraź sobie, że zbieram dane liczbowe w mojej ankiecie, a część analizy wymaga ode mnie uzyskania sumy, średniej lub innej operacji arytmetycznej. Kilka brakujących wartości doprowadziłoby do wielu nieścisłości w mojej analizie. Muszę znaleźć sposób na znalezienie i zastąpienie tych brakujących wartości pewnymi wartościami, które mogłyby być ich bliskim substytutem.
Pandy zapewniają nam funkcję znajdowania brakujących wartości w DataFrame o nazwie isnull().
Funkcja isnull() może być używana jako taka;
df.isnull()
To zwraca DataFrame z wartościami boolowskimi, które mówią nam, czy pierwotnie obecne tam dane były naprawdę brakujące, czy fałszywie brakujące. Wyjście wyglądałoby tak;
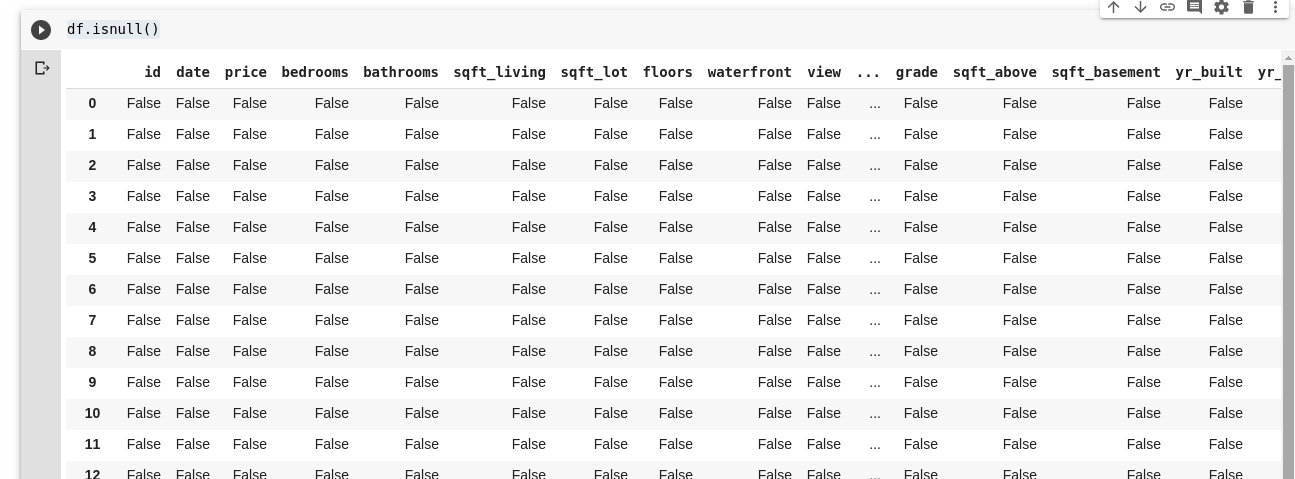
Potrzebujemy sposobu, aby móc zastąpić wszystkie te brakujące wartości, najczęściej wybór brakujących wartości można przyjąć jako zero. Czasami może być traktowana jako średnia wszystkich innych danych lub być może średnia danych wokół niej, w zależności od naukowca danych i przypadku użycia analizowanych danych.
Aby wypełnić wszystkie brakujące wartości w DataFrame, używamy funkcji .fillna() używanej jako taka;
df.fillna(0)
W powyższym wypełniamy wszystkie puste dane wartością zero. Równie dobrze może to być dowolna inna liczba, którą określimy.
Znaczenie danych nie może być przecenione, pomaga nam uzyskać odpowiedzi bezpośrednio z naszych danych!. Mówią, że analiza danych jest nową ropą naftową dla gospodarek cyfrowych.
Wszystkie przykłady w tym artykule można znaleźć tutaj.
Aby dowiedzieć się więcej, sprawdź Kurs online Analiza danych z Pythonem i Pandami.