

Web scraping to pomysł na wyodrębnienie informacji ze strony internetowej i wykorzystanie ich do określonego przypadku użycia.
Załóżmy, że próbujesz wyodrębnić tabelę ze strony internetowej, przekonwertować ją na plik JSON i użyć pliku JSON do zbudowania niektórych wewnętrznych narzędzi. Za pomocą skrobania stron internetowych możesz wyodrębnić żądane dane, kierując reklamy na określone elementy na stronie internetowej. Skrobanie sieci za pomocą Pythona jest bardzo popularnym wyborem, ponieważ Python udostępnia wiele bibliotek, takich jak BeautifulSoup lub Scrapy, aby skutecznie wyodrębniać dane.
Posiadanie umiejętności efektywnego wydobywania danych jest również bardzo ważne jako programista lub data science. Ten artykuł pomoże ci zrozumieć, jak skutecznie zeskrobać stronę internetową i uzyskać niezbędną treść, aby manipulować nią zgodnie z potrzebami. W tym samouczku użyjemy pakietu BeautifulSoup. Jest to modny pakiet do scrapingu danych w Pythonie.
Spis treści:
Dlaczego warto używać Pythona do Web Scrapingu?
Python jest pierwszym wyborem dla wielu programistów podczas tworzenia skrobaków internetowych. Istnieje wiele powodów, dla których Python jest pierwszym wyborem, ale w tym artykule omówmy trzy główne powody, dla których Python jest używany do zbierania danych.
Wsparcie biblioteki i społeczności: Istnieje kilka świetnych bibliotek, takich jak BeautifulSoup, Scrapy, Selenium itp., które zapewniają świetne funkcje do efektywnego skrobania stron internetowych. Zbudował doskonały ekosystem do skrobania stron internetowych, a ponieważ wielu programistów na całym świecie korzysta już z Pythona, możesz szybko uzyskać pomoc, gdy utkniesz.
Automatyzacja: Python słynie z możliwości automatyzacji. Jeśli próbujesz stworzyć złożone narzędzie, które opiera się na skrobaniu, wymagane jest coś więcej niż tylko skrobanie sieci. Na przykład, jeśli chcesz zbudować narzędzie, które śledzi ceny artykułów w sklepie internetowym, musisz dodać pewną możliwość automatyzacji, aby mogło codziennie śledzić stawki i dodawać je do bazy danych. Python daje możliwość łatwej automatyzacji takich procesów.
Wizualizacja danych: Web scraping jest często używany przez naukowców zajmujących się danymi. Analitycy danych często muszą wydobywać dane ze stron internetowych. Dzięki bibliotekom takim jak Pandas Python upraszcza wizualizację danych z surowych danych.
Biblioteki do skrobania stron internetowych w Pythonie
W Pythonie dostępnych jest kilka bibliotek, które upraszczają przeglądanie stron internetowych. Omówmy tutaj trzy najpopularniejsze biblioteki.
# 1. PięknaZupa
Jedna z najpopularniejszych bibliotek do skrobania stron internetowych. BeautifulSoup pomaga programistom przeglądać strony internetowe od 2004 roku. Zapewnia proste metody nawigacji, wyszukiwania i modyfikowania drzewa analizy. Sama Beautifulsoup również koduje dane przychodzące i wychodzące. Jest dobrze utrzymany i ma świetną społeczność.
#2. Zeskrobać
Kolejny popularny framework do ekstrakcji danych. Scrapy ma ponad 43000 gwiazdek na GitHub. Może być również używany do zbierania danych z interfejsów API. Ma również kilka interesujących wbudowanych funkcji wsparcia, takich jak wysyłanie wiadomości e-mail.
#3. Selen
Selenium to nie tylko biblioteka do skrobania stron internetowych. Zamiast tego jest to pakiet automatyzacji przeglądarki. Ale możemy łatwo rozszerzyć jego funkcjonalność o skrobanie stron internetowych. Wykorzystuje protokół WebDriver do kontrolowania różnych przeglądarek. Selen jest obecny na rynku od prawie 20 lat. Ale za pomocą Selenium możesz łatwo zautomatyzować i zeskrobać dane ze stron internetowych.
Wyzwania związane ze skrobaniem sieci w języku Python
Próbując zebrać dane ze stron internetowych, można napotkać wiele wyzwań. Występują problemy, takie jak wolne sieci, narzędzia zapobiegające skrobaniu, blokowanie oparte na adresach IP, blokowanie captcha itp. Te problemy mogą powodować ogromne problemy podczas próby zeskrobania strony internetowej.
Ale możesz skutecznie ominąć wyzwania, stosując kilka sposobów. Na przykład w większości przypadków adres IP jest blokowany przez witrynę internetową, gdy w określonym przedziale czasu wysyłanych jest więcej niż określona liczba żądań. Aby uniknąć blokowania adresów IP, musisz zakodować skrobak, aby ostygł po wysłaniu żądań.

Deweloperzy mają również tendencję do umieszczania pułapek na miód na skrobaki. Pułapki te są zwykle niewidoczne dla gołego ludzkiego oka, ale można je przeczołgać za pomocą skrobaka. Jeśli zeskrobujesz witrynę, która zastawia pułapkę typu honeypot, musisz odpowiednio zakodować swój skrobak.
Captcha to kolejny poważny problem ze skrobakami. Większość witryn internetowych używa obecnie captcha do ochrony dostępu botów do swoich stron. W takim przypadku może być konieczne użycie rozwiązania captcha.
Skrobanie strony internetowej za pomocą Pythona
Jak omówiliśmy, będziemy używać BeautifulSoup do złomowania strony internetowej. W tym samouczku zeskrobujemy historyczne dane Ethereum z Coingecko i zapiszemy dane tabeli jako plik JSON. Przejdźmy do budowy skrobaka.
Pierwszym krokiem jest instalacja BeautifulSoup i Requests. W tym samouczku użyję Pipenv. Pipenv to menedżer środowiska wirtualnego dla Pythona. Możesz także użyć Venv, jeśli chcesz, ale wolę Pipenv. Omówienie Pipenv wykracza poza zakres tego samouczka. Ale jeśli chcesz dowiedzieć się, jak można używać Pipenv, postępuj zgodnie z tym przewodnikiem. Lub, jeśli chcesz zrozumieć środowiska wirtualne Pythona, postępuj zgodnie z tym przewodnikiem.
Uruchom powłokę Pipenv w katalogu projektu, uruchamiając polecenie pipenv shell. Uruchomi podpowłokę w twoim środowisku wirtualnym. Teraz, aby zainstalować BeautifulSoup, uruchom następujące polecenie:
pipenv install beautifulsoup4
Aby zainstalować żądania, uruchom polecenie podobne do powyższego:
pipenv install requests
Po zakończeniu instalacji zaimportuj niezbędne pakiety do głównego pliku. Utwórz plik o nazwie main.py i zaimportuj pakiety, jak poniżej:
from bs4 import BeautifulSoup import requests import json
Następnym krokiem jest pobranie zawartości strony z danymi historycznymi i przeanalizowanie ich za pomocą parsera HTML dostępnego w BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
W powyższym kodzie dostęp do strony uzyskuje się za pomocą metody get dostępnej w bibliotece requestów. Przeanalizowana zawartość jest następnie przechowywana w zmiennej o nazwie zupa.
Oryginalna część zgarniania zaczyna się teraz. Najpierw musisz poprawnie zidentyfikować tabelę w DOM. Jeśli otworzysz tę stronę i sprawdzisz ją za pomocą narzędzi programistycznych dostępnych w przeglądarce, zobaczysz, że tabela zawiera następujące klasy table table-striped text-sm text-lg-normal.
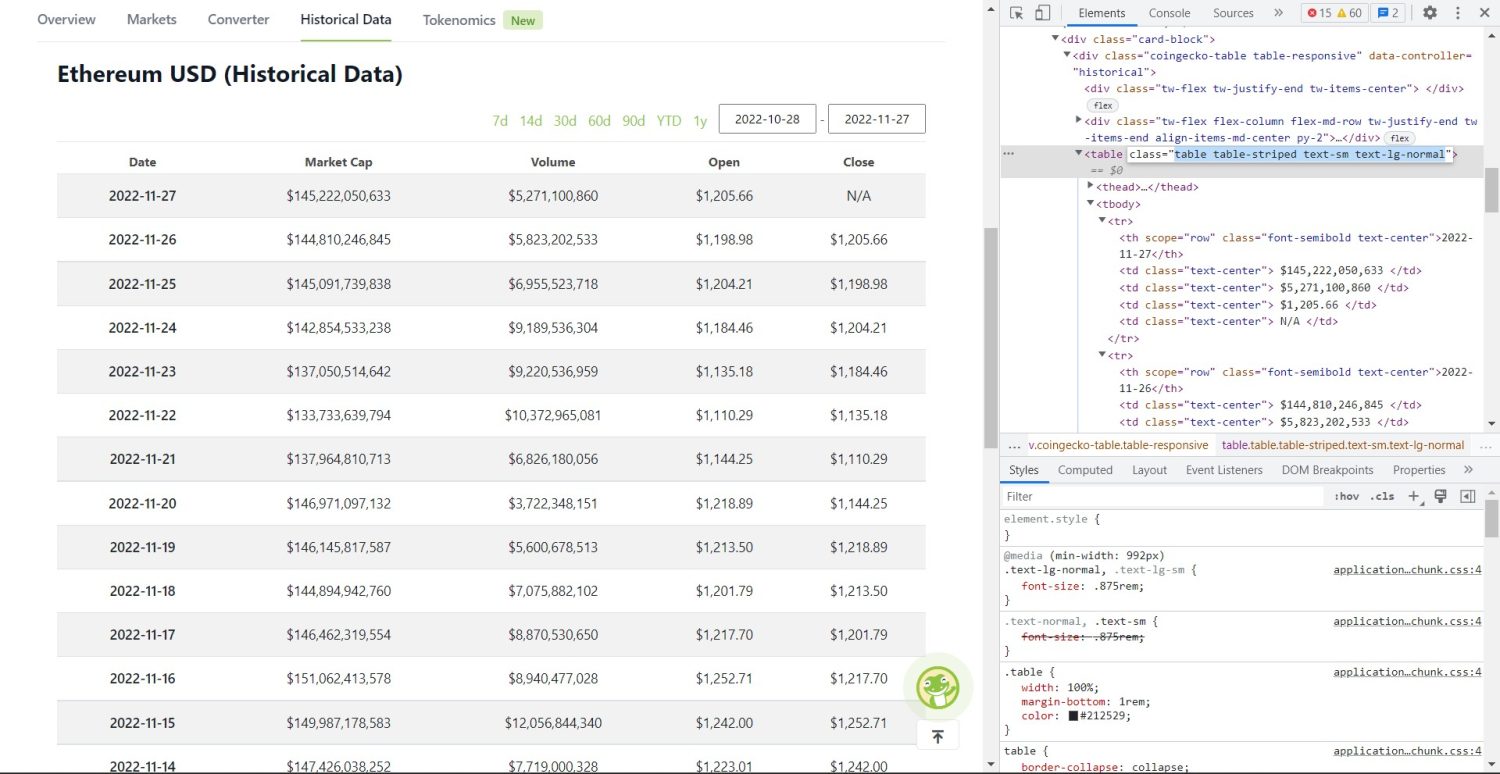 Tabela danych historycznych Coingecko Ethereum
Tabela danych historycznych Coingecko Ethereum
Aby poprawnie kierować tę tabelę, możesz użyć metody find.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
W powyższym kodzie najpierw tabela zostaje znaleziona metodą soup.find, a następnie metodą find_all przeszukane są wszystkie elementy tr wewnątrz tabeli. Te elementy tr są przechowywane w zmiennej o nazwie table_data. Tabela zawiera kilka elementów tytułu. Nowa zmienna o nazwie table_headings jest inicjowana w celu przechowywania tytułów na liście.
Następnie uruchamiana jest pętla for dla pierwszego wiersza tabeli. W tym wierszu wyszukiwane są wszystkie elementy z th, a ich wartość tekstowa jest dodawana do listy table_headings. Tekst jest wyodrębniany przy użyciu metody tekstowej. Jeśli teraz wydrukujesz zmienną table_headings, zobaczysz następujące dane wyjściowe:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Następnym krokiem jest zeskrobanie pozostałych elementów, wygenerowanie słownika dla każdego wiersza, a następnie dodanie wierszy do listy.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
To jest zasadnicza część kodu. Dla każdego tr w zmiennej table_data najpierw przeszukiwane są elementy th. Elementem th jest data pokazana w tabeli. Te elementy th są przechowywane wewnątrz zmiennej th. Podobnie wszystkie elementy td są przechowywane w zmiennej td.
Puste dane słownika są inicjowane. Po inicjalizacji przechodzimy przez zakres elementów td. Dla każdego wiersza najpierw aktualizujemy pierwsze pole słownika o pierwszy element th. Kod table_headings[0]: cz[0].text przypisuje parę klucz-wartość data i pierwszy element.
Po zainicjowaniu pierwszego elementu pozostałe elementy są przypisywane za pomocą data.update({table_headings[i+1]: td[i].text.replace(’n’, )}). Tutaj tekst elementów td jest najpierw wyodrębniany przy użyciu metody text, a następnie wszystkie n są zastępowane przy użyciu metody zamiany. Wartość jest następnie przypisywana do i+1 elementu listy table_headings, ponieważ i-ty element jest już przypisany.
Następnie, jeśli długość słownika danych przekracza zero, dołączamy słownik do listy table_details. Możesz wydrukować listę table_details, aby sprawdzić. Ale będziemy zapisywać wartości w pliku JSON. Rzućmy okiem na ten kod,
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Używamy tutaj metody json.dump, aby zapisać wartości do pliku JSON o nazwie table.json. Po zakończeniu pisania drukujemy Dane zapisane do pliku json… do konsoli.
Teraz uruchom plik za pomocą następującego polecenia,
python run main.py
Po pewnym czasie w konsoli pojawi się tekst Dane zapisane do pliku JSON…. Zobaczysz także nowy plik o nazwie table.json w roboczym katalogu plików. Plik będzie wyglądał podobnie do następującego pliku JSON:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Pomyślnie zaimplementowałeś narzędzie do skrobania stron internetowych przy użyciu języka Python. Aby wyświetlić pełny kod, możesz odwiedzić to repozytorium GitHub.
Wniosek
W tym artykule omówiono, jak można zaimplementować proste skrobanie w języku Python. Omówiliśmy, w jaki sposób można wykorzystać BeautifulSoup do szybkiego zgarniania danych ze strony internetowej. Omówiliśmy również inne dostępne biblioteki i dlaczego Python jest pierwszym wyborem dla wielu programistów do skrobania stron internetowych.
Możesz także spojrzeć na te frameworki do skrobania stron internetowych.