Tworzenie WIDOKÓW SQL: objaśnienie krok po kroku
Czym są widoki SQL i jak z nich korzystać?
W interakcji z relacyjnymi bazami danych wykorzystujemy SQL, czyli Structured Query Language, który umożliwia również tworzenie tzw. widoków SQL.
Ale czym właściwie są te widoki? To nic innego jak wirtualne tabele, które łączą i przechowują dane pochodzące z faktycznych tabel bazy danych. Te tabele są tworzone przez użytkownika. Dzięki widokom zyskujemy bezpieczny i prostszy dostęp do danych, a jednocześnie ukrywamy szczegóły implementacyjne i strukturę bazowych tabel.
Jak to działa? Wiemy już, że do kreowania widoków SQL służą zapytania SQL. W momencie tworzenia widoku, zapytanie SQL, które go definiuje, jest zapisywane. Kiedy wysyłamy zapytanie do bazy danych, które operuje na wielu tabelach, zapytanie jest wykonywane, a dane pobierane z odpowiednich tabel. Analogicznie, gdy kierujemy zapytanie do utworzonego widoku, najpierw pobierane jest zapisane zapytanie, a następnie jest ono realizowane.
Jakie korzyści niesie tworzenie widoków SQL?
Widoki SQL, dzięki temu, że opierają się na zapisanych zapytaniach SQL, podnoszą bezpieczeństwo bazy danych. Upraszczają one również skomplikowane zapytania i przyspieszają ich działanie, a to tylko niektóre z zalet. Przeanalizujmy, w jaki sposób tworzenie widoków SQL może wspomóc Twoją bazę danych i aplikacje:
# 1. Bezpieczeństwo danych
Widoki SQL, działając jak wirtualne tabele, maskują strukturę prawdziwych tabel bazy danych. Obserwując jedynie widok, nie da się stwierdzić, ile tabel istnieje i jakie są w nich kolumny. Co więcej, można wprowadzić ograniczenia dostępu, dzięki którym użytkownik będzie mógł kierować zapytania tylko do widoku, a nie bezpośrednio do tabel.
#2. Prostota złożonych zapytań
Często zapytania SQL operują na wielu tabelach i zawierają złożone warunki łączenia. Jeśli często korzystasz z tego typu zapytań, widoki SQL będą idealnym rozwiązaniem. Możesz umieścić skomplikowane zapytanie w widoku, dzięki czemu w przyszłości będziesz mógł po prostu zapytać widok, zamiast uruchamiać całe złożone zapytanie.
#3. Ochrona przed zmianami schematu
Jeśli struktura bazowych tabel ulegnie zmianie, np. przez dodanie lub usunięcie kolumn, widoki pozostaną nienaruszone. Jeżeli w zapytaniach korzystasz z widoków SQL, nie musisz obawiać się zmian w schemacie. Widoki SQL, jako tabele wirtualne, nadal będą działać bez zakłóceń.
#4. Zwiększenie wydajności zapytań
W momencie tworzenia widoków SQL, system bazodanowy optymalizuje zapisywane zapytania. Zapisane zapytania działają szybciej, niż gdyby były wykonywane bezpośrednio. Zatem wykorzystanie widoków SQL w zapytaniach o dane, przekłada się na lepszą wydajność i krótszy czas uzyskiwania wyników.
Jak tworzyć widoki SQL?
Do tworzenia widoków SQL służy polecenie `CREATE VIEW`. Widok zawiera instrukcję `SELECT`, która definiuje zapytanie, które zostanie w nim zapisane. Ogólna składnia wygląda tak:
CREATE VIEW nazwa_widoku AS SELECT kolumna_1, kolumna_2, kolumna_3... FROM nazwa_tabeli_1, nazwa_tabeli_2 WHERE warunek
Zilustrujmy to na konkretnym przykładzie. Załóżmy, że stworzyliśmy dwie tabele: `dział` i `pracownik`. Tabela `dział` przechowuje nazwę działu oraz jego identyfikator. Tabela `pracownik` zawiera imię i nazwisko pracownika oraz jego identyfikator, a także identyfikator działu, do którego należy. Wykorzystamy te dwie tabele, aby utworzyć widok SQL.
Tworzenie tabel bazy danych
id_działu | nazwa_działu
1 | Finanse
2 | Technologia
3 | Biznes
Tabela 1: dział
W środowisku MySQL tabelę można utworzyć za pomocą takiego zapytania:
CREATE TABLE `department` ( `department_id` int, `department_name` varchar(255), PRIMARY KEY (`department_id`) );
Dane do tabeli wprowadzimy za pomocą następujących komend SQL:
INSERT INTO department VALUES (1, 'Finanse'); INSERT INTO department VALUES (2, 'Technologia'); INSERT INTO department VALUES (3, 'Biznes');
id_pracownika | imię_pracownika | id_działu
100 | Jan | 3
101 | Maria | 1
102 | Natalia | 3
103 | Bruce | 2
Tabela 2: pracownik
Mając przygotowaną tabelę `dział`, możemy utworzyć tabelę `pracownik` za pomocą poniższego zapytania MySQL:
CREATE TABLE `employee` ( `employee_id` INT, `employee_name` VARCHAR(255), `department_id` INT, FOREIGN KEY (`department_id`) REFERENCES department(department_id) );
Teraz dodamy dane do tabeli `pracownik`. Pamiętajmy, że kolumna `id_działu` jest kluczem obcym, który odnosi się do tabeli `dział`, dlatego nie możemy wstawić identyfikatora działu, który nie istnieje w drugiej tabeli.
INSERT INTO employee VALUES (100, 'Jan', 3); INSERT INTO employee VALUES (101, 'Maria', 1); INSERT INTO employee VALUES (102, 'Natalia', 3); INSERT INTO employee VALUES (103, 'Bruce', 1);
Zapytania do tabel bazy danych
Wykorzystajmy teraz nasze tabele w zapytaniu do bazy danych. Załóżmy, że potrzebujemy uzyskać identyfikator pracownika, jego imię i nazwę działu dla wszystkich pracowników. W takiej sytuacji musimy użyć obu tabel i połączyć je na podstawie wspólnej kolumny, którą jest id_działu. Zapytanie wyglądałoby tak:
SELECT employee_id, employee_name, department_name FROM employee, department WHERE employee.department_id = department.department_id;
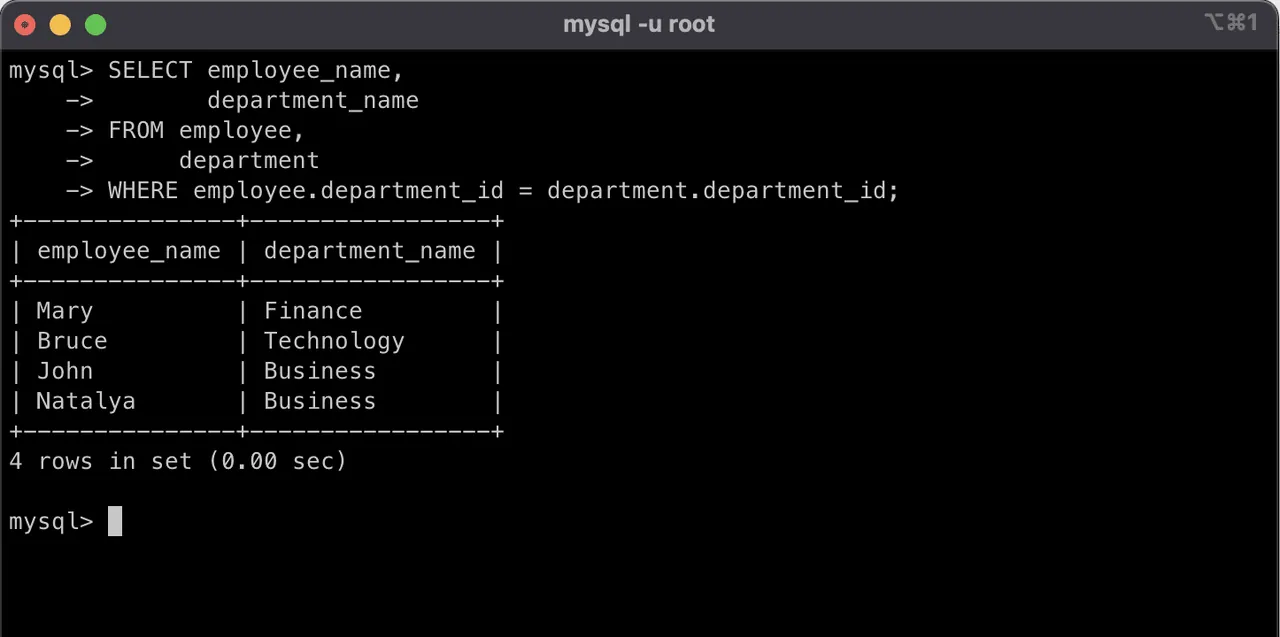
Tworzenie widoku SQL
Może się zdarzyć, że często potrzebujemy odczytywać te dane. Dodatkowo, w miarę jak w tabelach będzie przybywać rekordów, czas wykonywania tego zapytania będzie się wydłużał. W takim wypadku możemy stworzyć widok SQL, odpowiadający temu zapytaniu.
Użyjemy poniższego zapytania, aby stworzyć widok o nazwie `informacje_o_pracowniku`:
CREATE VIEW informacje_o_pracowniku AS SELECT employee_id, employee_name, department_name FROM employee, department WHERE employee.department_id = department.department_id;
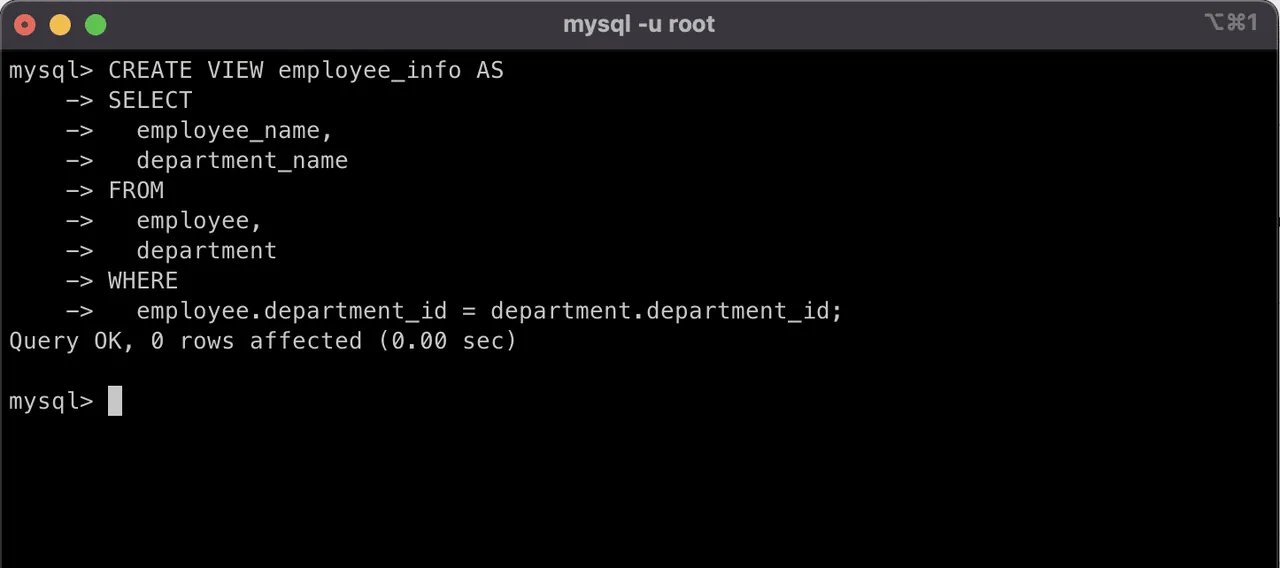
Mając już taki widok, możemy bezpośrednio do niego kierować zapytania. Nasze zapytanie uprości się do:
SELECT * FROM informacje_o_pracowniku;
Zapytanie do widoku SQL da taki sam rezultat, jak uruchomienie pierwotnego zapytania. Jednak nasze zapytanie jest teraz łatwiejsze w obsłudze. Widok ukrywa złożoność zapytania, nie wpływając na wynik czy wydajność.
Jak modyfikować widoki SQL?
Jeżeli mamy widok o określonej nazwie i chcemy go zmodyfikować lub zastąpić, użyjemy polecenia `CREATE OR REPLACE VIEW`. Dzięki niemu możemy zmienić instrukcję `SELECT`, która została użyta do utworzenia widoku. W rezultacie dane wyjściowe widoku zostaną zastąpione, ale jego nazwa pozostanie bez zmian. Co więcej, jeżeli widok nie istnieje, to zostanie on utworzony.
Składnia modyfikacji widoku jest następująca:
CREATE OR REPLACE VIEW nazwa_widoku AS SELECT nowa_kolumna_1, nowa_kolumna_2, nowa_kolumna_3 ... FROM nowa_nazwa_tabeli_1, nowa_nazwa_tabeli_2 ... WHERE nowy_warunek
Ułatwmy sobie zrozumienie tego na przykładzie. Mamy tabele `dział` i `pracownik`, na podstawie których stworzyliśmy widok SQL `informacje_o_pracowniku`, który zawiera kolumny id_pracownika, imię_pracownika i nazwa_działu.
Ze względu na bezpieczeństwo danych chcemy usunąć z tego widoku kolumnę id_pracownika. Chcemy też zmienić nazwy kolumn, aby ukryć faktyczne nazwy kolumn bazy danych. Możemy wprowadzić te zmiany w istniejącym widoku, używając poniższego zapytania SQL:
CREATE OR REPLACE VIEW informacje_o_pracowniku AS SELECT employee_name as name, department_name as department FROM employee, department WHERE employee.department_id = department.department_id;
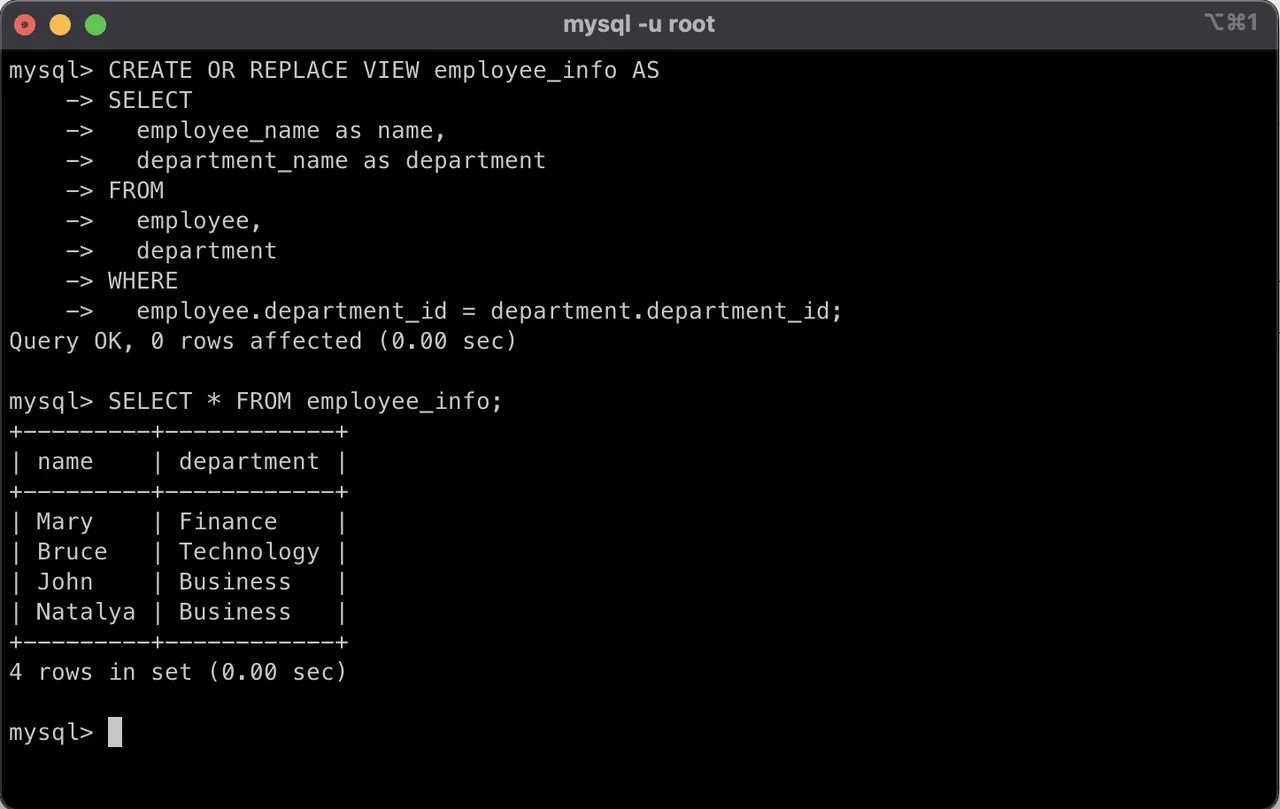
Po zastąpieniu widoku, zapytanie do niego da inny rezultat. Zauważymy, że jedna z kolumn została usunięta. Nazwy kolumn również zostały zmodyfikowane z `imię_pracownika` i `nazwa_działu` na odpowiednio `imię` i `dział`.
Wykorzystaj możliwości widoków SQL
Tworzenie widoków SQL nie tylko upraszcza zapytania i przyspiesza wyszukiwanie danych, ale też zwiększa bezpieczeństwo i chroni przed zmianami w schemacie. Samo tworzenie widoków jest bardzo proste. Możesz wziąć dowolne istniejące zapytanie i przekształcić je w widok SQL.
Skorzystaj z przedstawionego przewodnika krok po kroku, aby tworzyć widoki SQL i korzystać z ich zalet. Z widokami SQL, możesz usprawnić i zabezpieczyć swoje aplikacje bazodanowe, jednocześnie zwiększając ich wydajność.
Jeśli planujesz zarządzać własnym serwerem SQL, zapoznaj się z narzędziem SQL Server Management Studio (SSMS).
