

MapReduce oferuje skuteczny, szybszy i ekonomiczny sposób tworzenia aplikacji.
Model ten wykorzystuje zaawansowane koncepcje, takie jak przetwarzanie równoległe, lokalizacja danych itp., aby zapewnić wiele korzyści programistom i organizacjom.
Ale na rynku dostępnych jest tak wiele modeli i frameworków programistycznych, że wybór staje się trudny.
A jeśli chodzi o Big Data, nie możesz po prostu wybrać czegokolwiek. Musisz wybrać takie technologie, które poradzą sobie z dużymi porcjami danych.
MapReduce to świetne rozwiązanie.
W tym artykule omówię, czym tak naprawdę jest MapReduce i jakie może przynieść korzyści.
Zaczynajmy!
Spis treści:
Co to jest MapReduce?
MapReduce to model programowania lub struktura oprogramowania w ramach platformy Apache Hadoop. Służy do tworzenia aplikacji zdolnych do równoległego przetwarzania ogromnych danych na tysiącach węzłów (zwanych klastrami lub siatkami) z odpornością na błędy i niezawodnością.
To przetwarzanie danych odbywa się w bazie danych lub systemie plików, w którym przechowywane są dane. MapReduce może współpracować z systemem plików Hadoop (HDFS), aby uzyskać dostęp do dużych ilości danych i zarządzać nimi.
Rama ta została wprowadzona w 2004 roku przez Google i jest spopularyzowana przez Apache Hadoop. Jest to warstwa przetwarzania lub silnik w Hadoop, na którym działają programy MapReduce opracowane w różnych językach, w tym Java, C++, Python i Ruby.
Programy MapReduce w chmurze obliczeniowej działają równolegle, dzięki czemu nadają się do wykonywania analiz danych na dużą skalę.
MapReduce ma na celu podzielenie zadania na mniejsze, wiele zadań za pomocą funkcji „mapa” i „redukuj”. Odwzoruje każde zadanie, a następnie zredukuje je do kilku równoważnych zadań, co spowoduje zmniejszenie mocy obliczeniowej i narzutu w sieci klastra.
Przykład: Załóżmy, że przygotowujesz posiłek dla domu pełnego gości. Jeśli więc spróbujesz przygotować wszystkie potrawy i wykonać wszystkie procesy samodzielnie, stanie się to gorączkowe i czasochłonne.
Załóżmy jednak, że angażujesz kilku znajomych lub współpracowników (nie gości), aby pomogli ci w przygotowaniu posiłku, przekazując różne procesy innej osobie, która może wykonywać zadania jednocześnie. W takim przypadku przygotujesz posiłek o wiele szybciej i łatwiej, gdy Twoi goście będą jeszcze w domu.
MapReduce działa w podobny sposób z zadaniami rozproszonymi i przetwarzaniem równoległym, aby umożliwić szybszy i łatwiejszy sposób wykonania danego zadania.
Apache Hadoop umożliwia programistom wykorzystanie MapReduce do wykonywania modeli na dużych rozproszonych zestawach danych oraz zaawansowanego uczenia maszynowego i technik statystycznych w celu znajdowania wzorców, przewidywania, korelacji punktowych i nie tylko.
Funkcje MapReduce
Niektóre z głównych funkcji MapReduce to:
- Interfejs użytkownika: Otrzymasz intuicyjny interfejs użytkownika, który zapewnia rozsądne szczegóły dotyczące każdego aspektu frameworka. Pomoże Ci bezproblemowo skonfigurować, zastosować i dostroić zadania.

- Ładunek: aplikacje wykorzystują interfejsy Mapper i Reducer, aby włączyć mapę i ograniczyć funkcje. Mapper mapuje wejściowe pary klucz-wartość na pośrednie pary klucz-wartość. Reduktor służy do redukowania pośrednich par klucz-wartość, które dzielą klucz z innymi mniejszymi wartościami. Pełni trzy funkcje – sortowanie, tasowanie i redukowanie.
- Partitioner: Kontroluje podział pośrednich kluczy wyjściowych mapy.
- Reporter: Jest to funkcja do zgłaszania postępów, aktualizowania liczników i ustawiania komunikatów o stanie.
- Liczniki: reprezentuje globalne liczniki zdefiniowane przez aplikację MapReduce.
- OutputCollector: Ta funkcja zbiera dane wyjściowe z programu Mapper lub Reducer zamiast danych wyjściowych pośrednich.
- RecordWriter: zapisuje dane wyjściowe lub pary klucz-wartość do pliku wyjściowego.
- DistributedCache: Wydajnie dystrybuuje większe pliki tylko do odczytu, które są specyficzne dla aplikacji.
- Kompresja danych: Program piszący aplikacje może kompresować zarówno dane wyjściowe zadania, jak i pośrednie dane wyjściowe map.
- Pomijanie złych rekordów: możesz pominąć kilka złych rekordów podczas przetwarzania danych wejściowych mapy. Ta funkcja może być kontrolowana przez klasę – SkipBadRecords.
- Debugowanie: Otrzymasz opcję uruchamiania skryptów zdefiniowanych przez użytkownika i włączania debugowania. Jeśli zadanie w MapReduce nie powiedzie się, możesz uruchomić skrypt debugowania i znaleźć problemy.
MapReduce Architecture
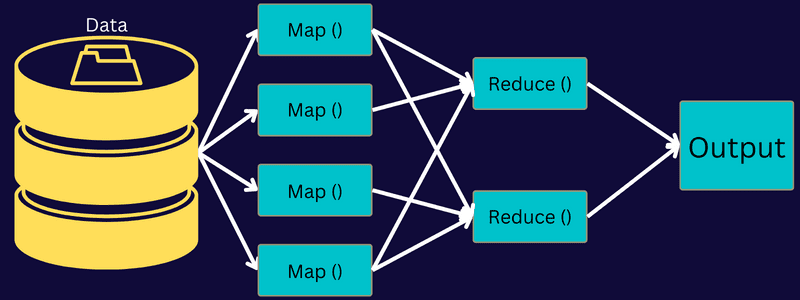
Przyjrzyjmy się architekturze MapReduce, zagłębiając się w jej składniki:
- Zadanie: zadanie w MapReduce to rzeczywiste zadanie, które klient MapReduce chce wykonać. Składa się z kilku mniejszych zadań, które łączą się, tworząc zadanie końcowe.
- Serwer historii zadań: jest to proces demona do przechowywania i zapisywania wszystkich danych historycznych dotyczących aplikacji lub zadania, takich jak dzienniki generowane po lub przed wykonaniem zadania.
- Klient: Klient (program lub interfejs API) przenosi zadanie do MapReduce w celu wykonania lub przetworzenia. W MapReduce jeden lub wielu klientów może stale wysyłać zadania do menedżera MapReduce w celu przetworzenia.
- MapReduce Master: MapReduce Master dzieli zadanie na kilka mniejszych części, zapewniając, że zadania postępują jednocześnie.
- Części zadań: zadania podrzędne lub części zadań są uzyskiwane przez podzielenie zadania podstawowego. Pracuje się nad nimi i łączy w końcu, aby stworzyć ostateczne zadanie.
- Dane wejściowe: to zestaw danych przekazywany do MapReduce w celu przetwarzania zadań.
- Dane wyjściowe: To końcowy wynik uzyskany po przetworzeniu zadania.
Tak więc to, co naprawdę dzieje się w tej architekturze, polega na tym, że klient przesyła zadanie do programu MapReduce Master, który dzieli je na mniejsze, równe części. Umożliwia to szybsze przetwarzanie zadania, ponieważ przetwarzanie mniejszych zadań zajmuje mniej czasu, a nie większych.
Upewnij się jednak, że zadania nie są podzielone na zbyt małe zadania, ponieważ jeśli to zrobisz, być może będziesz musiał zmierzyć się z większym obciążeniem związanym z zarządzaniem podziałami i zmarnować na to dużo czasu.
Następnie części pracy są udostępniane, aby kontynuować zadania Map i Zmniejsz. Ponadto zadania Map i Reduce mają odpowiedni program oparty na przypadku użycia, nad którym pracuje zespół. Programista opracowuje kod oparty na logice, aby spełnić wymagania.
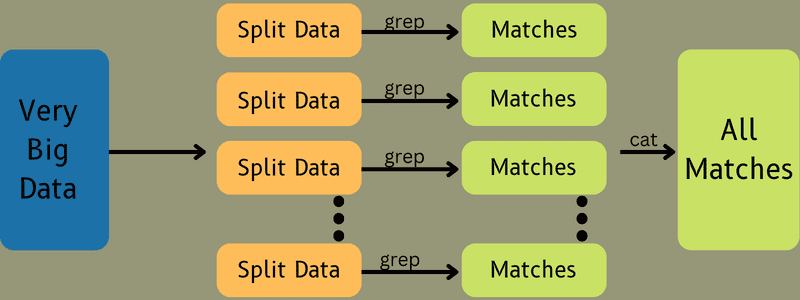
Następnie dane wejściowe są przekazywane do zadania mapy, dzięki czemu mapa może szybko wygenerować dane wyjściowe jako parę klucz-wartość. Zamiast przechowywać te dane w systemie HDFS, do przechowywania danych używany jest dysk lokalny, aby wyeliminować ryzyko replikacji.
Po zakończeniu zadania możesz wyrzucić dane wyjściowe. W związku z tym replikacja stanie się przesadą, gdy zapiszesz dane wyjściowe na HDFS. Dane wyjściowe każdego zadania mapy zostaną przekazane do zadania zmniejszenia, a dane wyjściowe mapy zostaną dostarczone do maszyny, która uruchomiła zadanie zmniejszenia.
Następnie dane wyjściowe zostaną scalone i przekazane do zdefiniowanej przez użytkownika funkcji zmniejszania. Wreszcie zmniejszona wydajność zostanie zapisana na HDFS.
Co więcej, proces może mieć kilka zadań mapowania i zmniejszania przetwarzania danych w zależności od celu końcowego. Algorytmy mapowania i zmniejszania są zoptymalizowane pod kątem minimalnej złożoności czasowej lub przestrzennej.
Ponieważ MapReduce obejmuje głównie zadania mapowania i zmniejszania, istotne jest, aby dowiedzieć się więcej na ich temat. Omówmy więc fazy MapReduce, aby uzyskać jasny obraz tych tematów.
Fazy MapReduce
Mapa
W tej fazie dane wejściowe są mapowane na dane wyjściowe lub pary klucz-wartość. Tutaj klucz może odnosić się do identyfikatora adresu, podczas gdy wartość może być rzeczywistą wartością tego adresu.
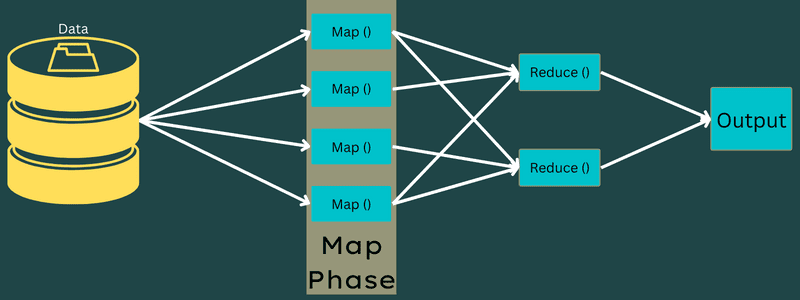
W tej fazie jest tylko jedno, ale dwa zadania – splity i mapowanie. Podziały oznaczają podczęści lub części zlecenia oddzielone od zlecenia głównego. Są to również nazywane podziałami wejściowymi. Tak więc podział danych wejściowych można nazwać porcją danych wejściowych zużywaną przez mapę.
Następnie ma miejsce zadanie mapowania. Jest uważana za pierwszą fazę podczas wykonywania programu do redukcji mapy. Tutaj dane zawarte w każdym podziale zostaną przekazane do funkcji mapy w celu przetworzenia i wygenerowania danych wyjściowych.
Funkcja – Map() jest wykonywana w repozytorium pamięci na wejściowych parach klucz-wartość, generując pośrednią parę klucz-wartość. Ta nowa para klucz-wartość będzie działać jako dane wejściowe, które zostaną przekazane do funkcji Reduce() lub Reducer.
Redukować
Pośrednie pary klucz-wartość uzyskane w fazie mapowania działają jako dane wejściowe dla funkcji Reduce lub Reducer. Podobnie jak w fazie mapowania, zaangażowane są dwa zadania – tasowanie i redukcja.
Tak więc uzyskane pary klucz-wartość są sortowane i tasowane w celu przekazania ich do Reduktora. Następnie Reduktor grupuje lub agreguje dane zgodnie z parą klucz-wartość na podstawie algorytmu reduktora napisanego przez programistę.
Tutaj wartości z fazy tasowania są łączone, aby zwrócić wartość wyjściową. Ta faza podsumowuje cały zestaw danych.
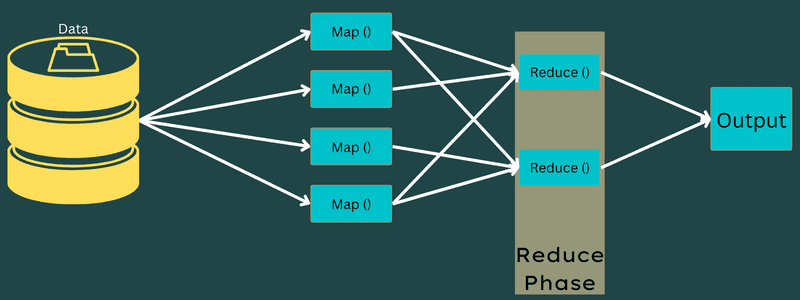
Teraz cały proces wykonywania zadań Map and Reduce jest kontrolowany przez niektóre encje. To są:
- Job Tracker: W prostych słowach, Job Tracker działa jak mistrz, który jest odpowiedzialny za całkowite wykonanie przesłanego zadania. Śledzenie zadań zarządza wszystkimi zadaniami i zasobami w klastrze. Ponadto moduł śledzenia zadań planuje każdą mapę dodaną do modułu śledzenia zadań, która działa w określonym węźle danych.
- Śledzenie wielu zadań: W prostych słowach, śledzenie wielu zadań działa jako niewolnicy, wykonując zadanie zgodnie z instrukcjami narzędzia do śledzenia zadań. Śledzenie zadań jest wdrażane na każdym węźle osobno w klastrze wykonującym zadania mapowania i zmniejszania.
Działa, ponieważ zadanie zostanie podzielone na kilka zadań, które będą uruchamiane na różnych węzłach danych z klastra. Job Tracker jest odpowiedzialny za koordynację zadania poprzez planowanie zadań i uruchamianie ich na wielu węzłach danych. Następnie Task Tracker znajdujący się na każdym węźle danych wykonuje części zadania i dba o każde zadanie.
Ponadto moduły śledzące zadania wysyłają raporty o postępach do modułu do śledzenia zadań. Ponadto, Task Tracker okresowo wysyła sygnał „bicia serca” do Job Tracker i powiadamia ich o stanie systemu. W przypadku jakiejkolwiek awarii, tracker zadań jest w stanie przełożyć zadanie na inny tracker zadań.
Faza wyjściowa: Po osiągnięciu tej fazy otrzymasz ostateczne pary klucz-wartość wygenerowane z Reduktora. Możesz użyć programu formatującego dane wyjściowe do przetłumaczenia par klucz-wartość i zapisania ich w pliku za pomocą programu do zapisywania rekordów.
Dlaczego warto korzystać z MapReduce?
Oto niektóre z zalet MapReduce, wyjaśniające powody, dla których należy go używać w aplikacjach Big Data:
Przetwarzanie równoległe
Możesz podzielić zadanie na różne węzły, w których każdy węzeł jednocześnie obsługuje część tego zadania w MapReduce. Tak więc dzielenie większych zadań na mniejsze zmniejsza złożoność. Ponadto, ponieważ różne zadania działają równolegle na różnych komputerach zamiast na jednej maszynie, przetwarzanie danych zajmuje znacznie mniej czasu.
Lokalizacja danych
W MapReduce możesz przenieść jednostkę przetwarzania do danych, a nie na odwrót.
W tradycyjny sposób dane były dostarczane do jednostki przetwarzającej w celu przetworzenia. Jednak wraz z szybkim przyrostem danych proces ten zaczął stwarzać wiele wyzwań. Niektóre z nich były droższe, bardziej czasochłonne, obciążające węzeł nadrzędny, częste awarie i obniżona wydajność sieci.
Jednak MapReduce pomaga rozwiązać te problemy, stosując odwrotne podejście — przenosząc jednostkę przetwarzania do danych. W ten sposób dane są rozdzielane między różne węzły, w których każdy węzeł może przetworzyć część przechowywanych danych.
W rezultacie oferuje opłacalność i skraca czas przetwarzania, ponieważ każdy węzeł pracuje równolegle z odpowiadającą mu częścią danych. Dodatkowo, ponieważ każdy węzeł przetwarza część tych danych, żaden węzeł nie zostanie przeciążony.
Bezpieczeństwo

Model MapReduce zapewnia większe bezpieczeństwo. Pomaga chronić aplikację przed nieautoryzowanymi danymi, jednocześnie zwiększając bezpieczeństwo klastra.
Skalowalność i elastyczność
MapReduce to wysoce skalowalna platforma. Pozwala uruchamiać aplikacje z kilku maszyn, wykorzystując dane o tysiącach terabajtów. Oferuje również elastyczność przetwarzania danych, które mogą być ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane oraz w dowolnym formacie i rozmiarze.
Prostota
Możesz pisać programy MapReduce w dowolnym języku programowania, takim jak Java, R, Perl, Python i nie tylko. Dlatego każdy może łatwo uczyć się i pisać programy, zapewniając jednocześnie spełnienie wymagań dotyczących przetwarzania danych.
Przypadki użycia MapReduce
- Indeksowanie pełnotekstowe: MapReduce służy do wykonywania indeksowania pełnotekstowego. Jego Mapper może odwzorować każde słowo lub frazę w jednym dokumencie. A Reduktor służy do zapisywania wszystkich zmapowanych elementów do indeksu.
- Obliczanie PageRank: Google używa MapReduce do obliczania PageRank.
- Analiza dziennika: MapReduce może analizować pliki dziennika. Może rozbić duży plik dziennika na różne części lub podzielić, podczas gdy program odwzorowujący szuka dostępnych stron internetowych.
Para klucz-wartość zostanie przekazana do reduktora, jeśli w dzienniku zostanie wykryta strona internetowa. Tutaj kluczem będzie strona internetowa, a indeks „1” to wartość. Po przekazaniu Reduktorowi pary klucz-wartość, różne strony internetowe zostaną zagregowane. Ostateczny wynik to całkowita liczba odwiedzin dla każdej strony internetowej.

- Reverse Web-Link Graph: Framework znajduje również zastosowanie w Reverse Web-Link Graph. W tym przypadku funkcja Map() zwraca cel adresu URL i źródło oraz pobiera dane wejściowe ze źródła lub strony internetowej.
Następnie Reduce() agreguje listę wszystkich źródłowych adresów URL powiązanych z docelowym adresem URL. Na koniec wyprowadza źródła i cel.
- Liczenie słów: MapReduce służy do liczenia, ile razy słowo pojawia się w danym dokumencie.
- Globalne ocieplenie: Organizacje, rządy i firmy mogą używać MapReduce do rozwiązywania problemów związanych z globalnym ociepleniem.
Na przykład możesz chcieć wiedzieć o podwyższonym poziomie temperatury oceanu z powodu globalnego ocieplenia. W tym celu możesz zebrać tysiące danych na całym świecie. Danymi mogą być wysoka temperatura, niska temperatura, szerokość i długość geograficzna, data, godzina itp. Zajmie to kilka map i zmniejszy liczbę zadań do obliczenia danych wyjściowych za pomocą MapReduce.
- Próby leków: Tradycyjnie naukowcy zajmujący się danymi i matematycy pracowali razem, aby opracować nowy lek, który może zwalczyć chorobę. Dzięki rozpowszechnianiu algorytmów i MapReduce działy IT w organizacjach mogą łatwo rozwiązywać problemy, które były obsługiwane tylko przez Superkomputery, dr. naukowcy itp. Teraz możesz sprawdzić skuteczność leku dla grupy pacjentów.
- Inne zastosowania: MapReduce może przetwarzać nawet dane o dużej skali, które inaczej nie zmieściłyby się w relacyjnej bazie danych. Wykorzystuje również narzędzia data science i pozwala na uruchamianie ich na różnych, rozproszonych zestawach danych, co wcześniej było możliwe tylko na jednym komputerze.
Dzięki solidności i prostocie MapReduce znajduje zastosowanie w wojsku, biznesie, nauce itp.
Wniosek
MapReduce może okazać się przełomem w technologii. To nie tylko szybszy i prostszy proces, ale także opłacalny i mniej czasochłonny. Biorąc pod uwagę jego zalety i rosnące wykorzystanie, prawdopodobnie będzie on częściej stosowany w różnych branżach i organizacjach.
Możesz także zapoznać się z najlepszymi zasobami do nauki Big Data i Hadoop.