
Dane są siłą napędową każdego biznesu. To klucz do sukcesu i jest niezbędny do zbierania danych wywiadowczych, podejmowania decyzji i usprawniania operacji.
Firma każdego dnia polega na swoich danych i aplikacjach. Ale co się dzieje, gdy jedna z ich baz danych lub systemów ulegnie awarii?
Wszystkie krytyczne informacje i dane biznesowe mogą być zagrożone.
Na szczęście istnieją sposoby, aby temu zapobiec. Jedną z najskuteczniejszych metod ochrony danych biznesowych jest replikacja bazy danych. Jest to coś, do czego każda mała, średnia i duża firma musi się dostosować, aby przetrwać w konkurencji.
W tym artykule omówię, czym jest replikacja danych, jak działa i omówię inne ważne aspekty.
Więc zacznijmy!
Spis treści:
Co to jest replikacja bazy danych?
Transfer danych ze źródłowej bazy danych do jednej lub kilku docelowych baz danych jest znany jako replikacja bazy danych. Często wiąże się to z kopiowaniem lub przesyłaniem strumieniowym danych z jednej bazy danych do drugiej, tak aby wszyscy użytkownicy mieli dostęp do zsynchronizowanych danych bez względu na to, jakiego systemu używają do ich przeglądania.
Jeśli dane ulegną zmianie, narzędzie do replikacji danych zadba o to, aby zmiany zostały zaimplementowane również w docelowej bazie danych. W rezultacie tworzona jest rozproszona sieć przechowywania danych o większej dostępności w wielu lokalizacjach, umożliwiając wszystkim szybki dostęp do ważnych i istotnych danych.
Korzystając z rozwiązania do replikacji danych, prawdopodobnie zauważysz poprawę spójności danych w każdym węźle, zmniejszoną nadmiarowość danych, większą niezawodność danych i ostatecznie wzrost wydajności.
Replikacja bazy danych może odbywać się w czasie rzeczywistym, gdy dane są tworzone, edytowane i niszczone w źródłowej bazie danych lub w ramach operacji wsadowej.
Jak działa replikacja danych?
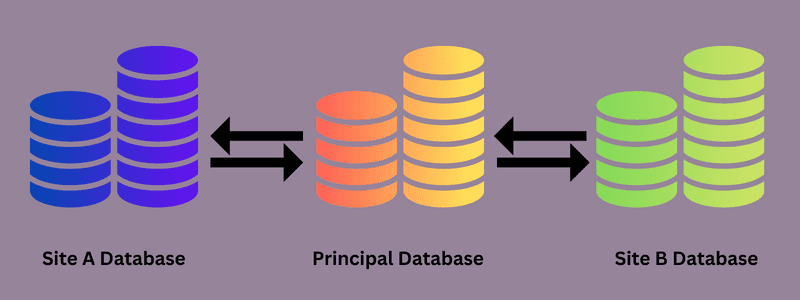
Replikację bazy danych można przeprowadzić jednorazowo lub jako proces ciągły. Obejmuje wszystkie źródła danych organizacji, a system zarządzania rozproszoną bazą danych (DDBMS) służy do przesyłania lub dystrybucji danych do wszystkich źródeł.
Wszelkie zmiany, uzupełnienia i usunięcia dokonane w źródłowej bazie danych są automatycznie synchronizowane z innymi docelowymi bazami danych, jeśli te zmiany są wymagane. Zgodnie z konwencjonalnym paradygmatem oprogramowania wydawca-subskrybent, w proces replikacji danych zaangażowanych jest co najmniej jeden „wydawca” i „subskrybent”.
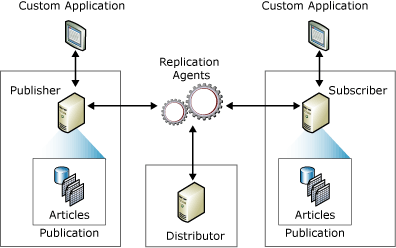 Źródło obrazu: Microsoft
Źródło obrazu: Microsoft
„Wydawca” to system lub źródłowa baza danych, w której dokonywane są zmiany, a „subskrybent” to system, w którym zmiany są replikowane.
Wszelkie modyfikacje dokonane w systemie „wydawcy” są następnie replikowane do baz danych „subskrybentów”. Użytkownicy mogą również dokonywać zmian w bazach subskrybentów, które następnie są replikowane w bazie danych wydawcy. Powoduje to dystrybucję zmian do wszystkich innych abonentów w sieci, jeśli system jest dwukierunkowy.
Co więcej, większość subskrybentów ma stałe łącze z wydawcą, co pozwala na automatyczne wprowadzanie zmian lub aktualizacji bez ręcznej interwencji. Te aktualizacje mogą odbywać się partiami w regularnych odstępach czasu lub mogą być wyzwalane i stosowane w czasie rzeczywistym.
Typy replikacji baz danych
Niektóre typy replikacji bazy danych to:
# 1. Replikacja pełnego stołu
Replikacja pełnej tabeli tworzy kopię całej źródłowej bazy danych w docelowym magazynie. Przenosi wiersze od wydawcy do subskrybenta, w tym wiersze nowe, zmodyfikowane i istniejące.
Jednak takie podejście do replikacji wiąże się z wysokimi kosztami utrzymania ze względu na moc obliczeniową i wymagania dotyczące przepustowości sieci wymagane do skopiowania wszystkiego. To obciąża sieć i może powodować opóźnienia replikacji, zwłaszcza gdy ilość danych jest większa.
#2. Replikacja migawki
Migawka źródłowej bazy danych jest używana w tej replikacji bazy danych do replikacji danych w docelowej docelowej bazie danych. Nie uwzględnia zmian danych, takich jak nowe, zaktualizowane lub usunięte; zamiast tego tworzy kopię tego, co zbiera w tym czasie.
Gdy zmiany danych są bardzo nieliczne, preferowana jest ta technika replikacji. Jest znacznie szybsza niż replikacja pełnej tabeli, ale nie śledzi trwale usuniętych danych.

#3. Scal replikację
Replikacja scalająca to proces, który przenosi i dystrybuuje obiekty i dane bazy danych z jednej bazy danych do drugiej z synchronizacją bazy danych. Jest złożony, ponieważ proces ten umożliwia subskrybentom i wydawcom zmianę bazy danych, co powoduje częste konflikty danych związane z wersjami.
Agenci scalania wdrożeni na serwerach synchronizują wszystkie zmiany i wykonują predefiniowany proces rozwiązywania konfliktów w celu rozwiązania wszelkich konfliktów danych.
#4. Replikacja przyrostowa oparta na kluczach
Replikacja przyrostowa oparta na kluczach sprawdza klucze lub indeksy w bazie danych w poszukiwaniu zmian, takich jak usunięcie, nowe i zaktualizowane. Mechanizm replikacji kopiuje wtedy tylko wymagane klucze replikacji do bazy danych repliki, aby odzwierciedlić zmiany od ostatniej aktualizacji. Te klucze to zazwyczaj znacznik czasu, data lub liczba całkowita.
Ponieważ tylko wskazane zmiany są replikowane do bazy danych repliki, proces jest szybszy. Niestety ta metoda nie umożliwia trwałego usunięcia, ponieważ wartość krytyczna jest usuwana przez wymazanie rekordu podstawowej bazy danych.
#5. Replikacja przyrostowa oparta na logach
Ten typ replikacji bazy danych duplikuje dane zgodnie z binarnym plikiem dziennika bazy danych. Po sprawdzeniu binarnego pliku dziennika dostarczy on informacji o zmianach dokonanych w podstawowej bazie danych, na przykład aktualizacjach, wstawkach lub usunięciach. Następnie te same modyfikacje lub aktualizacje są wykonywane w docelowej bazie danych.
Jest to jedna z najczęściej stosowanych metod replikacji danych, ponieważ jest wydajna, szczególnie w przypadku statycznych baz danych. Ponadto obsługuje go większość dostawców baz danych, w tym Oracle, MongoDB, MySQL i PostgreSQL.
#6. Replikacja transakcyjna
Gdy w danych źródłowych pojawia się nowy element, replikacja transakcyjna przenosi wszystkie istniejące dane ze źródłowej bazy danych do lokalizacji docelowej. Następnie wykonuje tę samą transakcję w replikach.
Chociaż jest to wydajna metoda replikacji, modele znajdują zastosowanie głównie w działaniach związanych z odczytem i mogą nie pozwalać na tworzenie, usuwanie lub aktualizowanie operacji.
Dlaczego replikacja bazy danych jest ważna?

Replikacja bazy danych jest ważna z następujących powodów:
Wiarygodność i dostępność danych
Replikacja danych zwiększa dostępność danych. Odgrywa ważną rolę w przypadku awarii serwera w nietypowych okolicznościach, zapewniając kopie zapasowe bazy danych. W ten sposób możesz zaoszczędzić dzień, ponieważ dane są dostępne w innych lokalizacjach. Zwiększa również niezawodność danych, bezpiecznie przechowując odpowiednie, najnowsze dane na wielu serwerach.
Odzyskiwanie po awarii
Replikacja bazy danych jest pomocna w scenariuszu awarii serwera. Jest to wspaniała technika zarządzania kryzysowego i odzyskiwania, ponieważ replikuje i przechowuje dane oraz ostatnie zmiany w innych lokalizacjach serwerów, zamiast polegać na jednym serwerze.
Wydajność serwera
Dostęp do danych jest znacznie szybszy, gdy dane są przetwarzane i obsługiwane na kilku serwerach. Co więcej, administratorzy mogą zwolnić cykle przetwarzania na oryginalnym serwerze, aby umożliwić operacje zapisu wymagające większej ilości zasobów, kierując wszystkie operacje odczytu danych do repliki.
Lepsza wydajność sieci
Przechowywanie wielu kopii tych samych danych w różnych lokalizacjach może skrócić czas oczekiwania na dostęp do danych, ponieważ możesz pobrać odpowiednie dane z miejsca, w którym wykonywana jest transakcja.
Na przykład użytkownicy w krajach europejskich mogą odczuwać problemy z opóźnieniami podczas uzyskiwania dostępu do danych z australijskich centrów danych. Dlatego umieszczenie repliki tych danych blisko użytkownika może skrócić czas dostępu, jednocześnie równoważąc obciążenie sieci.
Poprawiona wydajność systemu testowego

Replikacja bazy danych usprawnia dystrybucję i synchronizację danych w systemach testowych, które wymagają szybkiego dostępu w celu szybszego podejmowania decyzji.
Kopia zapasowa bazy danych a replikacja bazy danych
Zarówno kopia zapasowa bazy danych, jak i replikacja bazy danych różnią się na kilka sposobów. Niektóre z nich są następujące:
- Kopie zapasowe bazy danych muszą zostać zrekonstruowane i przywrócone, zanim będzie można ich użyć. W przeciwieństwie do kopii zapasowych baz danych, replikacja danych nie wymaga rekonstrukcji i może być użyta natychmiast.
- Kopie zapasowe bazy danych składają się z plików lub folderów, plików danych bazy danych i plików aplikacji, w zależności od protokołów organizacyjnych przywracania kopii zapasowych. Natomiast replikacja bazy danych jest często używana do duplikowania całych woluminów lub systemów plików, baz danych i aplikacji.
- Kopia zapasowa i replikacja to środki ochrony danych. Pierwsza dotyczy obniżenia docelowych punktów odzyskiwania (RPO) i zapobiegania utracie danych. Podczas gdy ten ostatni ma na celu skrócenie docelowych czasów odzyskiwania (RTO), zapewnienie ciągłości biznesowej i zminimalizowanie przestojów.
- Kopia zapasowa bazy danych jest tanią metodą uniknięcia całkowitej utraty danych. Jest to niezbędne do zachowania zgodności i nie gwarantuje ciągłości działania. Wręcz przeciwnie, replikacja gwarantuje, że aplikacje i procesy biznesowe są zawsze dostępne, nawet po przerwie w dostawie prądu.
- Kopia zapasowa bazy danych dotyczy zgodności i szczegółowego odzyskiwania, takiego jak długoterminowe przechowywanie dokumentacji firmy. Z drugiej strony replikacja i odzyskiwanie bazy danych koncentruje się na odtwarzaniu po awarii, czyli szybkim i łatwym wznowieniu operacji po awarii lub uszkodzeniu.
- Kopia zapasowa bazy danych jest powszechnie stosowana w miejscu pracy do wszystkiego, od serwerów produkcyjnych po komputery stacjonarne. Wręcz przeciwnie, replikacja bazy danych jest często używana w przypadku aplikacji o znaczeniu krytycznym, które muszą być zawsze dostępne.
Techniki replikacji baz danych

Organizacje mogą replikować dane, stosując precyzyjną technikę przenoszenia danych. Strategie te różnią się od typów replikacji opisanych powyżej.
# 1. Pełna replikacja bazy danych
Pełna replikacja bazy danych replikuje całą bazę danych do użytku na różnych hostach. Zapewnia to najbardziej znaczącą ilość nadmiarowości i dostępności danych. W przypadku globalnych przedsiębiorstw umożliwia to użytkownikom w Azji dostęp do tych samych danych, co ich odpowiednikom w Ameryce Północnej z tą samą szybkością. Jeśli serwer azjatycki ulegnie awarii, użytkownicy mogą wykorzystać swoje serwery europejskie lub północnoamerykańskie jako kopię zapasową.
Wadą tej techniki jest jednak powolna procedura aktualizacji. Trudno jest również zachować spójność lokalizacji każdego pliku, co jest istotne w przypadku ciągłych zmian danych.
#2. Częściowa replikacja bazy danych
Częściowa replikacja bazy danych to proces, w ramach którego dane w bazie danych są dzielone na części i zapisywane w różnych lokalizacjach, w zależności od istotności każdej witryny.
Likwidatorzy ubezpieczeniowi, doradcy finansowi i specjaliści ds. sprzedaży czerpią korzyści z częściowej replikacji. Pracownicy ci mogą przenosić częściowe bazy danych na inne urządzenia lub laptopy i rutynowo synchronizować je z centralnym serwerem.
Dla analityków bardziej ekonomiczne może być przechowywanie danych europejskich w Europie, danych australijskich w Australii itp. Oznacza to przechowywanie danych blisko konsumentów, przy jednoczesnym przechowywaniu kompleksowego zestawu danych w centrali do analizy na wysokim poziomie.
Wady replikacji bazy danych

Chociaż replikacja danych może wnieść znaczną wartość do Twojej pracy i firmy, ma również następujące wady:
Wyższe koszty
Kiedy dane są replikowane i przechowywane w wielu lokalizacjach, wymaga to więcej przestrzeni dyskowej i zasobów obliczeniowych. To zwiększone zapotrzebowanie na sprzęt i zasoby obliczeniowe może prowadzić do wyższych kosztów, w tym zakupu i utrzymania dodatkowych urządzeń pamięci masowej, serwerów i infrastruktury sieciowej.
Ograniczenia czasowe
Replikacja danych to złożony proces, który obejmuje kopiowanie danych z jednej lokalizacji do wielu innych lokalizacji i utrzymywanie spójności we wszystkich kopiach. Ten proces może zająć dużo czasu, zwłaszcza w przypadku organizacji, które muszą replikować duże ilości danych.
Przepustowość łącza
Wraz ze wzrostem ilości replikowanych danych rosną również wymagania dotyczące przepustowości, co może nadwyrężyć zasoby sieciowe.
Niespójne dane
Podczas replikowania danych w środowisku rozproszonym istnieje ryzyko utraty synchronizacji danych, jeśli aktualizacje nie są przeprowadzane spójnie we wszystkich replikach. Może to spowodować niespójność danych, a rozwiązanie problemu może wymagać dodatkowego wysiłku.
Przypadki użycia replikacji bazy danych

Istnieje wiele przypadków, w których można zastosować replikację danych, na przykład:
Równoważenie obciążenia
Dzięki replikacji danych na wiele serwerów obciążenie jest rozkładane na te serwery w celu poprawy ich wydajności. W ten sposób równoważenie obciążenia gwarantuje, że pojedynczy serwer nie zostanie przytłoczony zbyt dużą liczbą żądań, a system pozostanie dostępny i responsywny nawet w okresach dużego ruchu.
Magazyn danych
Hurtownia danych to scentralizowane repozytorium do przechowywania dużych ilości danych z wielu źródeł. Replikacja danych z tych źródeł do hurtowni danych umożliwia organizacjom analizowanie i raportowanie danych w sposób scentralizowany i zorganizowany.
Wdrożenie międzyregionalne
Replikowanie danych do wielu regionów umożliwia organizacjom poprawę dostępności i nadmiarowości danych. Jeśli w regionie wystąpi awaria, dostęp do danych będzie nadal możliwy z innego regionu. Ponadto posiadanie danych w wielu regionach może pomóc zwiększyć szybkość dostępu dla użytkowników w różnych częściach świata.
Kopie zapasowe i archiwizacja
Replikacja danych do dodatkowej pamięci masowej pomaga organizacjom zachować długoterminowe kopie danych. Pozwala im to na łatwy dostęp do danych i gwarantuje, że nie zostaną one utracone nawet w przypadku awarii pamięci podstawowej.
Synchronizacja danych
Replikacja danych między wieloma systemami pomaga zapewnić synchronizację, spójność i aktualność danych w każdym miejscu. Jest to ważne w przypadku aplikacji takich jak e-commerce, gdzie te same dane muszą być dostępne z wielu systemów.
Współpraca wielu lokalizacji
Replikacja danych między wieloma lokalizacjami umożliwia organizacjom udostępnianie danych w czasie rzeczywistym, co umożliwia współpracę i zwiększa produktywność. Jest to szczególnie przydatne w organizacjach z zespołami w wielu lokalizacjach lub firmach, które muszą udostępniać dane partnerom lub klientom.
Zasoby edukacyjne
Oto kilka zasobów edukacyjnych, które pomogą Ci lepiej zrozumieć temat:
# 1. Replikacja bazy danych autorstwa Bettiny Kemme
Ta książka pomoże ci zrozumieć różne mechanizmy kontroli współbieżności i replikacji oraz kwestie z tym związane.
#2. Replikacja bazy danych: kompletny przewodnik:
Ta książka przygotuje Cię do stawienia czoła wyzwaniom związanym z replikacją bazy danych, wyjaśniając i odpowiadając na pytania.
Wniosek
Replikacja danych jest niedocenianą strategią w dzisiejszym szybko rozwijającym się świecie opartym na danych. Tak więc, jeśli jesteś właścicielem firmy, byłbyś zaskoczony jego zaletami.
Jednak wraz ze wzrostem liczby źródeł i miejsc docelowych firmy muszą być przygotowane na wyzwania, które się z tym wiążą. Dlatego przydatna może być niezawodna, skalowalna strategia replikacji danych.
Możesz także zapoznać się z przydatnym oprogramowaniem do monitorowania bazy danych w celu analizy wydajności.