Data Lake a hurtownia danych: jakie są różnice?
Współczesne przedsiębiorstwa w swojej działalności w dużej mierze opierają się na danych. Poszukują efektywnych metod pozyskiwania, analizy informacji z rozmaitych źródeł, aby podnosić przychody i rentowność.
Rodzi się jednak pytanie, gdzie najlepiej przechowywać i łączyć dane z wielu miejsc, a następnie optymalnie je wykorzystywać?
Zarówno jeziora danych, jak i hurtownie danych to popularne podejścia do zarządzania ogromnymi wolumenami informacji. Różnice między nimi wynikają ze sposobu, w jaki organizacje pobierają, archiwizują i używają danych. Zapraszamy do lektury, aby dowiedzieć się więcej.
Czym jest jezioro danych?
Jezioro danych to scentralizowane repozytorium, w którym dane z różnych źródeł, w dowolnym formacie – strukturalnym lub nieustrukturalnym – są przechowywane w oryginalnej formie. Można je porównać do zbioru surowych danych, których przeznaczenie nie jest jeszcze określone. Firmy zazwyczaj przechowują w jeziorze danych te informacje, które potencjalnie mogą być przydatne w przyszłych analizach.
Najważniejsze cechy jeziora danych:
- Zawiera zarówno cenne, jak i nieprzydatne dane, stąd potrzeba dużej przestrzeni dyskowej.
- Archiwizuje dane w czasie rzeczywistym i dane wsadowe – przykładowo, można przechowywać dane na bieżąco z urządzeń IoT, mediów społecznościowych lub aplikacji w chmurze, jak również dane wsadowe z baz danych czy plików.
- Ma płaską architekturę.
- Ze względu na to, że dane nie są przetwarzane, dopóki nie staną się potrzebne do analizy, wymagają starannego zarządzania i utrzymania; w przeciwnym razie mogą przekształcić się w bagno danych.
W jaki sposób szybko odzyskać dane z tak rozległego i pozornie chaotycznego repozytorium? Jezioro danych wykorzystuje do tego metadane oraz identyfikatory.
Czym jest hurtownia danych?
Hurtownia danych to bardziej uporządkowane i zorganizowane repozytorium, w którym dane są przygotowane do analizy. Ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturalizowane dane z wielu źródeł są pobierane, integrowane, oczyszczane, sortowane, przekształcane i dostosowywane do konkretnego zastosowania.
Hurtownia danych przechowuje obszerne ilości danych historycznych i bieżących. Najczęściej dane są przetwarzane pod kątem konkretnego problemu biznesowego, na potrzeby analizy. Takie informacje są wykorzystywane przez systemy Business Intelligence (BI) do analiz, raportowania i uzyskiwania wglądów.
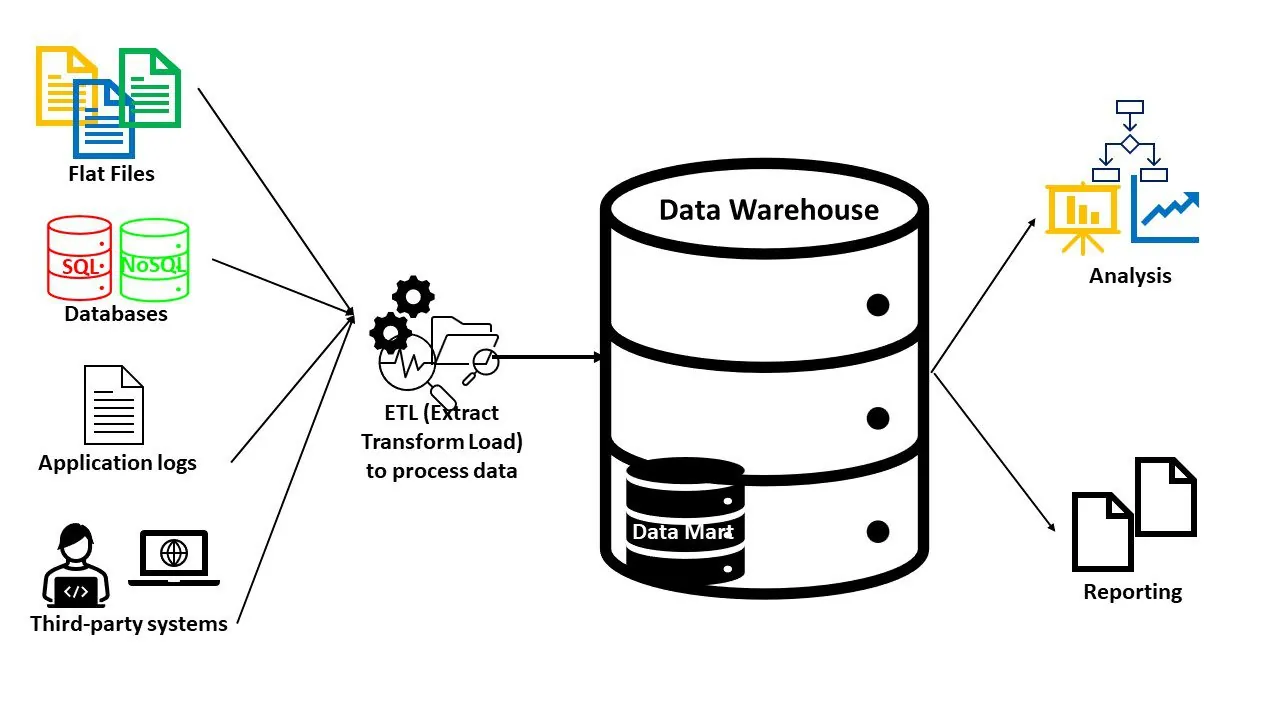
Hurtownie danych zazwyczaj składają się z następujących elementów:
- Baza danych (SQL lub NoSQL) do przechowywania danych i zarządzania nimi
- Narzędzia do transformacji i analizy danych w celu przygotowania danych
- Narzędzia BI do eksploracji danych, analizy statystycznej, raportowania i wizualizacji
Ponieważ hurtownie danych służą konkretnemu celowi, zawsze masz do dyspozycji odpowiednie informacje. Ponadto, można wykorzystywać zaawansowane narzędzia, takie jak sztuczna inteligencja czy funkcje przestrzenne. Hurtownie danych stworzone dla konkretnej dziedziny nazywane są data martami.
Podstawowe różnice między jeziorami danych a hurtowniami danych
Podsumowując, w jeziorze danych gromadzone są surowe dane, których cel nie został jeszcze określony, natomiast w hurtowni danych znajdują się dane gotowe do analizy i w optymalnej formie.
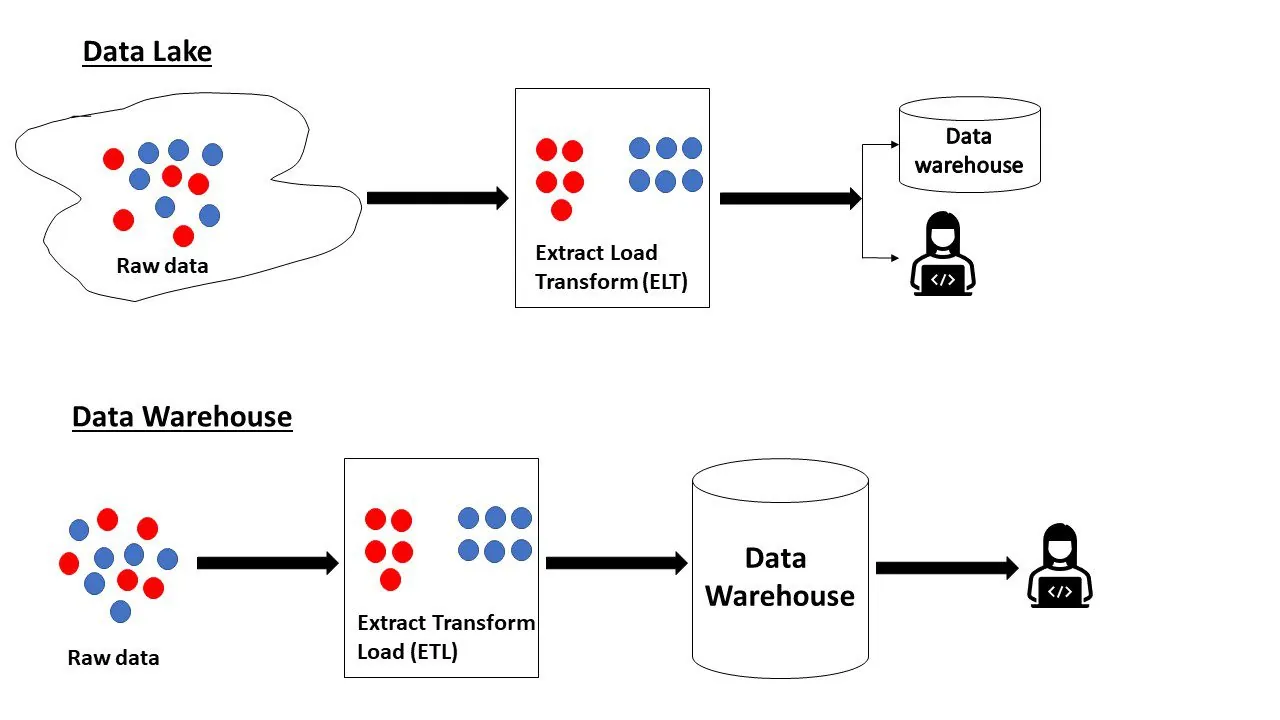 Jezioro danych a hurtownia danych
Jezioro danych a hurtownia danych
Poniżej przedstawiamy kilka istotnych różnic pomiędzy jeziorem danych a hurtownią danych:
Data Lake | Data Warehouse -------------------------------------------------------------------------- Pobierane są surowe lub przetworzone dane w dowolnym formacie z wielu źródeł | Dane pobierane są z wielu źródeł w celu analizy i raportowania. Mają strukturę Schemat tworzony jest na bieżąco, w miarę potrzeb (schema-on-read) | Predefiniowany schemat podczas zapisu do hurtowni (Schema-on-write) Łatwe dodawanie nowych danych | Dane są gotowe po przetworzeniu, a każda zmiana wymaga więcej czasu i wysiłku Dane wymagają regularnej aktualizacji i zarządzania, aby zachowały swoją wartość | Dane są w optymalnej formie, więc nie wymagają częstej konserwacji Składają się z ogromnych zbiorów danych (petabajty) | Zazwyczaj zawierają mniej danych niż jezioro danych (terabajty). Mogą zawierać dane operacyjne, analityczne lub istotne dla konkretnej domeny Wykorzystywane przez analityków danych do różnorodnych celów, m.in. analizy strumieniowej, sztucznej inteligencji, analityki predykcyjnej | Wykorzystywane przez analityków biznesowych do przetwarzania transakcji (OLTP), analizy operacyjnej (OLAP), raportowania, tworzenia wizualizacji Dane mogą być przechowywane i archiwizowane przez dłuższy czas na potrzeby przyszłej analizy | Dane powinny być często czyszczone, aby uwzględniać najnowsze informacje Przechowywanie danych jest niedrogie | Przechowywanie i przetwarzanie są kosztowne i czasochłonne, dlatego wymagają przemyślanego planowania Analitycy danych mogą szukać nowych problemów i rozwiązań, analizując dane | Zakres danych jest ograniczony do konkretnego problemu biznesowego Do przechowywania danych mogą być używane relacyjne bazy danych | Hurtownie danych zazwyczaj wykorzystują relacyjne bazy danych, ponieważ dane muszą mieć określony format.
Przykłady zastosowania jezior danych i hurtowni danych
Jezioro danych może wydawać się bardziej atrakcyjnym rozwiązaniem ze względu na skalowalność, elastyczność i oszczędność. Jednak hurtownia danych okazuje się nieoceniona, gdy potrzebne są trafne i uporządkowane dane do konkretnej analizy.
Oto kilka przykładów zastosowania jeziora danych:
#1. Łańcuch dostaw i zarządzanie
W jeziorach danych gromadzone są ogromne zbiory danych, które ułatwiają analizy predykcyjne w transporcie i logistyce. Dzięki wykorzystaniu danych historycznych i aktualnych firmy mogą płynnie planować operacje, monitorować stan zapasów w czasie rzeczywistym i optymalizować koszty.
#2. Opieka zdrowotna
Jezioro danych zawiera wszystkie informacje o pacjentach – zarówno historyczne, jak i aktualne. Ułatwia to prowadzenie badań, wykrywanie wzorców, zapewnienie lepszego i szybszego leczenia chorób, automatyzację diagnostyki i bieżącą analizę stanu zdrowia pacjenta.
#3. Strumieniowe przesyłanie danych i IoT
Jeziora danych mogą na bieżąco odbierać dane przesyłane strumieniowo do potoków analitycznych, co pozwala na ciągłe raportowanie i wykrywanie wszelkich nietypowych działań. Umożliwia to zdolność jeziora danych do gromadzenia danych niemal w czasie rzeczywistym.
Oto przykłady zastosowania hurtowni danych:
#1. Finanse
Informacje finansowe firmy często lepiej nadają się do przechowywania w hurtowni danych. Pracownicy mogą łatwo uzyskać dostęp do uporządkowanych danych w postaci wykresów i raportów, co ułatwia zarządzanie procesami finansowymi, ocenę ryzyka i podejmowanie strategicznych decyzji.
#2. Marketing i segmentacja klientów
Hurtownia danych stanowi jedno źródło wiarygodnych informacji o klientach, zebranych z różnych źródeł. Firmy mogą analizować te dane, aby lepiej zrozumieć zachowania klientów, oferować spersonalizowane rabaty, dzielić klientów na segmenty według preferencji i generować więcej leadów.
#3. Kokpit i raporty firmowe
Wiele firm korzysta z hurtowni danych CRM i ERP do pozyskiwania danych o klientach zewnętrznych i wewnętrznych. Dane są zawsze aktualne i mogą stanowić podstawę do tworzenia różnego rodzaju raportów i wizualizacji.
#4. Migracja danych ze starszych systemów
Wykorzystując możliwości ETL hurtowni danych, firmy mogą łatwo przekształcać dane ze starszych systemów w bardziej użyteczny format, który można analizować za pomocą nowych systemów. Ułatwia to firmom wgląd w historyczne trendy i podejmowanie trafnych decyzji biznesowych.
Przykłady narzędzi Data Lake
Niektórzy z wiodących dostawców usług Data Lake to:
- Microsoft Azure – Azure umożliwia przechowywanie i analizę petabajtów danych, a także łatwe debugowanie i optymalizację programów Big Data.
- Chmura Google – Oferuje ekonomiczne pozyskiwanie, przechowywanie i analizę ogromnych wolumenów big data dowolnego rodzaju, a także integrację z narzędziami analitycznymi, takimi jak Apache Spark czy BigQuery.
- Atlas MongoDB – To w pełni zarządzany magazyn danych. Umożliwia ekonomiczne przechowywanie danych na dużą skalę i wykonywanie zapytań o wysokiej wydajności, zużywając przy tym mniej mocy obliczeniowej, co pozwala oszczędzać czas i koszty.
- Amazon S3 – Chmura AWS udostępnia narzędzia do budowy elastycznego, bezpiecznego i ekonomicznego jeziora danych. Posiada interaktywną konsolę do zarządzania użytkownikami i kontroli dostępu.
Przykłady narzędzi hurtowni danych
Czołowi dostawcy rozwiązań hurtowni danych to:
- SAP – Hurtownia danych SAP umożliwia użytkownikom semantyczny dostęp do bogatych danych z wielu źródeł. Umożliwia bezpieczne udostępnianie spostrzeżeń i modeli, przyspiesza podejmowanie decyzji i łączenie danych zewnętrznych i wewnętrznych.
- ClicData – Inteligentna i zintegrowana hurtownia danych ClicData zapewnia integralność, jakość i łatwość raportowania. Oferuje zarówno systemy planowania, jak i interfejsy API czasu rzeczywistego, gwarantując dostęp do aktualnych danych.
- Amazon Redshift – Jedna z najpopularniejszych hurtowni danych, która wykorzystuje SQL do analizy danych z różnych baz, jezior danych i innych hurtowni. Oferuje równowagę między kosztami i wydajnością.
- Magazyn IBM Db2 – IBM oferuje rozwiązania wewnętrzne, chmurowe i zintegrowane w zakresie hurtowni danych, a także narzędzia uczenia maszynowego i sztucznej inteligencji do głębszej analizy. Udostępnia też wspólny silnik SQL do optymalizacji zapytań.
- Hurtownia danych Oracle Cloud – Wykorzystuje bazę danych w pamięci i oferuje funkcje graficzne, uczenie maszynowe i przestrzenne, które umożliwiają szybszą i bardziej zaawansowaną analizę danych.
Podsumowanie
Zarówno jeziora danych, jak i hurtownie danych mają swoje zalety i idealne zastosowania. Jeziora danych wyróżniają się skalowalnością i elastycznością, natomiast hurtownie danych zapewniają dostęp do wiarygodnych i ustrukturyzowanych danych. Wdrożenie jeziora danych to stosunkowo nowy trend, podczas gdy hurtownia danych to ugruntowane podejście, wykorzystywane przez wiele organizacji do efektywnego zarządzania danymi wewnętrznymi i zewnętrznymi.
