Apache Hive vs Apache Impala: główne różnice
Analiza danych: Apache Hive kontra Apache Impala
W świecie analizy dużych danych, początkujący analitycy często napotykają mnogość narzędzi Apache. Ta obfitość opcji może być na początku dezorientująca, a nawet przytłaczająca.
Niniejszy artykuł ma na celu rozwianie tych wątpliwości, przedstawiając szczegółowe omówienie i porównanie dwóch popularnych rozwiązań: Apache Hive i Apache Impala.
Apache Hive: Platforma zapytań SQL dla Hadoop
Apache Hive to narzędzie, które umożliwia dostęp do danych za pomocą języka SQL w środowisku Apache Hadoop. Hive pozwala na wykonywanie zapytań, agregację i analizę danych przy wykorzystaniu składni SQL.
Wykorzystuje schemat "odczytu w momencie zapytania" dla danych przechowywanych w HDFS (Hadoop Distributed File System), co pozwala traktować dane jak tabele w relacyjnej bazie danych. Zapytania napisane w języku HiveQL są przekształcane w kod Java dla zadań MapReduce.
Język zapytań HiveQL, choć bazuje na SQL, nie oferuje pełnej zgodności ze standardem SQL-92.
Jednakże, HiveQL umożliwia programistom rozszerzanie funkcjonalności poprzez definiowanie własnych funkcji skalarnych (UDF), agregujących (UDAF) oraz tablicowych (UDTF), co jest szczególnie przydatne, gdy standardowe funkcje HiveQL są niewystarczające lub nieefektywne.
Jak działa Apache Hive?
Apache Hive przekształca zapytania HiveQL (języka zbliżonego do SQL) w jedno lub więcej zadań MapReduce, Apache Tez lub Apache Spark. Te trzy silniki wykonawcze mogą działać w środowisku Hadoop. Następnie, Apache Hive organizuje dane w formacie tabeli w HDFS, aby uruchomić zadania w klastrze i wygenerować wynik.
Tabele w Apache Hive przypominają te z relacyjnych baz danych, a dane są strukturyzowane od najbardziej ogólnych do najbardziej szczegółowych jednostek. Bazy danych składają się z tabel, które mogą być podzielone na partycje, a te z kolei na "kubełki".
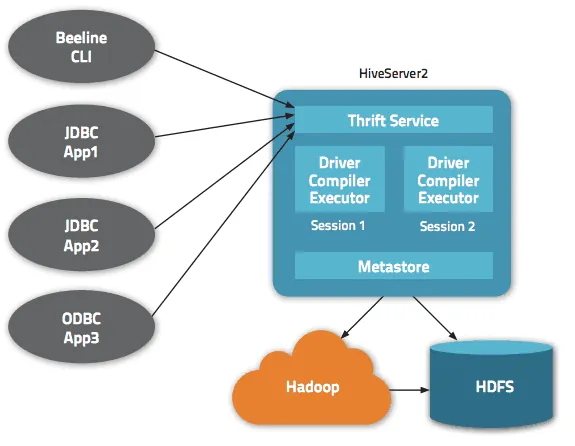
Dostęp do danych jest realizowany za pośrednictwem HiveQL. W ramach każdej bazy danych, dane są numerowane, a każda tabela odpowiada określonemu katalogowi w HDFS.
Architektura Apache Hive udostępnia różnorodne interfejsy, w tym interfejs webowy, CLI (Command Line Interface) oraz klientów zewnętrznych.
Serwer "Apache Hive Thrift" pozwala klientom zdalnym na przesyłanie poleceń i żądań do Apache Hive za pomocą różnych języków programowania. Centralnym elementem Apache Hive jest "metastore", czyli katalog przechowujący wszystkie informacje o danych.
Silnikiem napędzającym działanie Hive jest "sterownik" (driver), który zawiera kompilator i optymalizator odpowiedzialne za ustalenie najbardziej efektywnego planu wykonania zapytania.
W kwestii bezpieczeństwa, Apache Hive korzysta z mechanizmów Hadoop, opierając się na protokole Kerberos dla wzajemnego uwierzytelniania między klientem a serwerem. Uprawnienia do nowo tworzonych plików w Hive są zarządzane przez HDFS, co pozwala na precyzyjną kontrolę dostępu na poziomie użytkownika, grupy i innych parametrów.
Kluczowe cechy Hive'a
- Wsparcie dla silników obliczeniowych Hadoop i Spark.
- Wykorzystanie HDFS jako magazynu danych, pełniącego rolę hurtowni danych.
- Zastosowanie MapReduce i obsługa procesów ETL (Extract, Transform, Load).
- Odporność na awarie, dziedziczona z HDFS.
Apache Hive: Zalety
Apache Hive to doskonałe narzędzie do obsługi zapytań i analizy danych, umożliwiające uzyskanie cennych informacji, które mogą stanowić przewagę konkurencyjną i pomóc w szybkim reagowaniu na zmieniające się wymagania rynkowe.
Wśród najważniejszych zalet Apache Hive należy wymienić jego łatwość obsługi, wynikającą z użycia języka SQL. Ponadto, przyspiesza on wstępne przetwarzanie danych, ponieważ nie wymagają one odczytu i indeksowania z dysku w formacie wewnętrznej bazy danych.
Dzięki przechowywaniu danych w HDFS, Apache Hive może obsługiwać ogromne zbiory danych, nawet rzędu setek petabajtów. Rozwiązanie to charakteryzuje się znacznie lepszą skalowalnością w porównaniu do tradycyjnych baz danych. Jako usługa chmurowa, Apache Hive umożliwia użytkownikom szybkie tworzenie i uruchamianie serwerów wirtualnych w zależności od obciążenia.
Bezpieczeństwo jest kolejnym atutem Hive, oferującego możliwość replikacji obciążeń o krytycznym znaczeniu, co zapewnia ochronę przed potencjalnymi awariami. Wreszcie, wydajność pracy Hive jest na wysokim poziomie, pozwalając na obsługę do 100 000 żądań na godzinę.
Apache Impala: Silnik zapytań SQL o wysokiej wydajności
Apache Impala to silnik zapytań SQL, który umożliwia interaktywną analizę danych przechowywanych w Apache Hadoop. Został napisany w języku C++ i jest dostępny na licencji Apache 2.0.
Impala jest również określana jako silnik MPP (Massively Parallel Processing), rozproszony system zarządzania bazami danych (DBMS) lub baza danych SQL-on-Hadoop.

Impala działa w trybie rozproszonym, w którym procesy są wykonywane na różnych węzłach klastra, odbierając, planując i koordynując żądania od klientów. W ten sposób możliwe jest równoległe wykonywanie fragmentów zapytań SQL.
Klientami Impala są użytkownicy i aplikacje, które przesyłają zapytania SQL do danych przechowywanych w Apache Hadoop (HBase i HDFS) lub Amazon S3. Interakcja z Impala odbywa się za pośrednictwem interfejsu webowego HUE (Hadoop User Experience), sterowników ODBC i JDBC oraz wiersza poleceń Impala Shell.
Pod względem infrastruktury, Impala korzysta z metadanych przechowywanych w Apache Hive. W szczególności, Hive Metastore informuje Impala o dostępności i strukturze baz danych.
Podczas tworzenia, modyfikowania i usuwania obiektów schematu lub ładowania danych do tabel za pomocą instrukcji SQL, odpowiednie zmiany metadanych są automatycznie propagowane do wszystkich węzłów Impala za pośrednictwem dedykowanej usługi katalogowej.
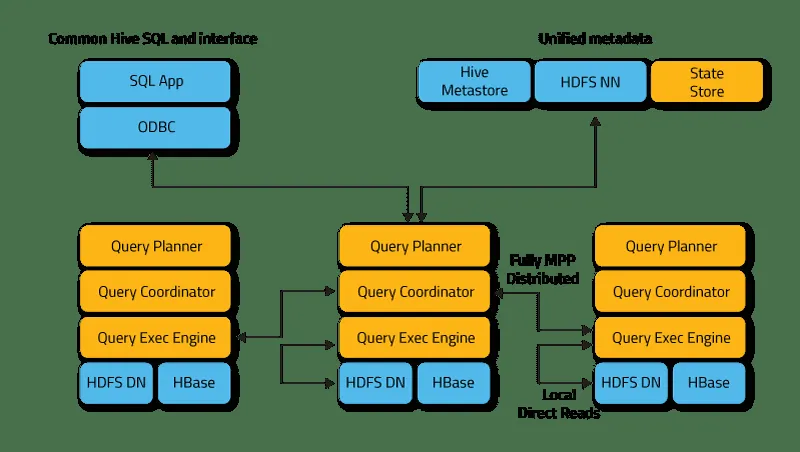
Kluczowe elementy architektury Impala obejmują następujące procesy:
- Demon Impalad to usługa systemowa, która zarządza wykonywaniem zapytań na danych w HDFS, HBase i Amazon S3. W każdym węźle klastra działa jeden proces impalad.
- Statestore to usługa, która monitoruje lokalizację i stan wszystkich instancji impalad w klastrze. Jedno wystąpienie tej usługi jest uruchamiane na każdym węźle i serwerze głównym (Nazwa węzła).
- Katalog to usługa koordynująca metadane. Propaguje zmiany z instrukcji Impala DDL i DML do wszystkich odpowiednich węzłów. Dzięki temu, nowe tabele lub świeżo załadowane dane są natychmiast widoczne w całym klastrze. Zaleca się, aby jedna instancja Katalogu działała na tym samym hoście klastra co demon Statestored.
Jak działa Apache Impala?
Impala, podobnie jak Apache Hive, używa języka zapytań opartego na HiveQL, który jest podzbiorem standardu SQL92.
Realizacja zapytania w Impala przebiega następująco:
Aplikacja kliencka wysyła zapytanie SQL, łącząc się z dowolną instancją impalad za pośrednictwem standardowych sterowników ODBC lub JDBC. Po nawiązaniu połączenia, dana instancja impalad przejmuje rolę koordynatora dla danego zapytania.
Zapytanie SQL jest analizowane w celu określenia zadań dla poszczególnych instancji impalad w klastrze. Na podstawie tej analizy budowany jest optymalny plan wykonania zapytania.
Impalad uzyskuje bezpośredni dostęp do HDFS i HBase, wykorzystując lokalne usługi systemowe, co pozwala na szybkie pobieranie danych. W przeciwieństwie do Apache Hive, ta bezpośrednia interakcja znacznie skraca czas wykonania zapytania, ponieważ wyniki pośrednie nie są zapisywane.
Na końcu, każdy demon zwraca dane do impalada pełniącego rolę koordynatora, który przesyła wyniki z powrotem do klienta.
Kluczowe cechy Impali
- Przetwarzanie danych w pamięci w czasie rzeczywistym.
- Język zapytań oparty na SQL.
- Wsparcie dla systemów przechowywania danych takich jak HDFS, Apache HBase i Amazon S3.
- Integracja z narzędziami BI (Business Intelligence), jak Pentaho i Tableau.
- Wykorzystanie składni HiveQL.
Apache Impala: Zalety
Impala eliminuje potencjalne opóźnienia związane z uruchamianiem, ponieważ wszystkie usługi systemowe działają bezpośrednio od momentu startu. To znacznie skraca czas wykonywania zapytań. Dodatkową przewagę w szybkości zapewnia bezpośredni dostęp do HDFS i HBase, bez konieczności zapisywania wyników pośrednich, jak to ma miejsce w Hive.
Co więcej, Impala generuje kod w czasie wykonywania, a nie podczas kompilacji, jak Hive. Jednakże, tak duża szybkość przetwarzania w Impala ma wpływ na niezawodność.
W przypadku awarii węzła danych, Impala uruchomi się ponownie, natomiast Hive utrzyma połączenie ze źródłem danych, oferując lepszą ochronę przed błędami.
Innymi zaletami Impali jest wbudowana obsługa bezpiecznego protokołu uwierzytelniania Kerberos, ustalanie priorytetów, zarządzanie kolejką żądań oraz obsługa popularnych formatów Big Data, takich jak LZO, Avro, RCFile, Parquet i Sequence.
Hive kontra Impala: Podobieństwa
Zarówno Hive, jak i Impala są dostępne na licencji Apache Software Foundation i są wykorzystywane do przetwarzania danych w klastrach Hadoop. Oba rozwiązania wykorzystują rozproszony system plików HDFS.
Impala i Hive służą do różnych zadań w obszarze przetwarzania SQL dużych zbiorów danych przechowywanych w klastrze Apache Hadoop. Impala udostępnia interfejs SQL, który umożliwia odczyt i zapis danych z tabel Hive, co ułatwia wymianę informacji między tymi dwoma narzędziami.
Impala sprawia, że operacje SQL na Hadoop są szybkie i wydajne, co pozwala na wykorzystanie tego DBMS w projektach badawczych związanych z analizą Big Data. Impala działa w oparciu o infrastrukturę Apache Hive, która jest wykorzystywana do wykonywania długotrwałych zapytań wsadowych SQL.
Dodatkowo, definicje tabel w Impala są przechowywane w metastore, czyli w tradycyjnej bazie danych MySQL lub PostgreSQL, czyli w tym samym miejscu, co w przypadku Hive. Pozwala to Impali na dostęp do tabel Hive, o ile wszystkie kolumny wykorzystują formaty danych, plików i kodeków kompresji obsługiwane przez Impala.
Hive kontra Impala: Różnice

Język programowania
Hive jest napisany w języku Java, natomiast Impala w C++. Należy jednak zaznaczyć, że Impala również korzysta z niektórych funkcji UDF napisanych w Javie.
Przykłady zastosowań
Inżynierowie danych wykorzystują Hive w procesach ETL (Extract, Transform, Load), takich jak długotrwałe zadania wsadowe na dużych zbiorach danych, np. w agregatorach podróży. Impala z kolei jest przeznaczona głównie dla analityków danych i data scientists, wykorzystywana np. w obszarze business intelligence.
Wydajność
Impala przetwarza zapytania SQL w czasie rzeczywistym, podczas gdy Hive charakteryzuje się wolniejszym tempem przetwarzania danych. W przypadku prostych zapytań SQL, Impala może działać od 6 do 69 razy szybciej niż Hive. Jednak Hive lepiej radzi sobie ze złożonymi zapytaniami.
Opóźnienie/Przepustowość
Przepustowość Hive jest wyższa niż Impala. Funkcja LLAP (Live Long and Process) zapewnia Hive dobrą wydajność na niskim poziomie, poprzez buforowanie zapytań w pamięci.
LLAP obejmuje usługi systemowe (demony), które umożliwiają bezpośrednią interakcję z węzłami danych HDFS i zastępują strukturę zapytań DAG (Directed Acyclic Graph), która jest wykorzystywana w obliczeniach Big Data.
Tolerancja błędów
Hive jest odporny na błędy i zachowuje wszystkie wyniki pośrednie. Wpływa to na skalowalność, ale prowadzi do zmniejszenia szybkości przetwarzania danych. Natomiast Impala jest mniej odporna na błędy, ponieważ jej działanie jest ograniczone dostępną pamięcią.
Konwersja kodu
Hive generuje wyrażenia zapytań w czasie kompilacji, natomiast Impala w czasie wykonywania. Hive może borykać się z problemem "zimnego startu", czyli wolniejszym uruchamianiem aplikacji, ze względu na potrzebę nawiązania połączenia ze źródłem danych.
Impala nie ma tego rodzaju kosztów początkowych. Niezbędne usługi systemowe są uruchamiane podczas startu systemu, co przyspiesza działanie.
Obsługa pamięci masowej
Impala obsługuje formaty LZO, Avro i Parquet, natomiast Hive współpracuje z Plain Text i ORC. Oba jednak obsługują formaty RCFIle i Sequence.
| Apache Hive | Apache Impala | |
|---|---|---|
| Język | Java | C++ |
| Przypadki użycia | Inżynieria danych | Analiza i analityka |
| Wydajność | Wysoka dla prostych zapytań | Stosunkowo niskie opóźnienie |
| Opóźnienie | Większe opóźnienie dzięki buforowaniu | Mniejsze tolerancja na błędy ukryte |
| Tolerancja na błędy | Większa tolerancja dzięki MapReduce | Mniejsza tolerancja dzięki MPP |
| Konwersja | Wolne dzięki zimnemu startowi | Szybsza konwersja |
| Obsługa pamięci masowej | Zwykły tekst i ORC | LZO, Avro, Parquet |
Podsumowanie
Hive i Impala nie są rywalami, ale raczej narzędziami, które wzajemnie się uzupełniają. Pomimo znacznych różnic, łączy je wiele cech wspólnych, a ostateczny wybór między nimi zależy od danych i specyficznych wymagań projektu.
Zachęcamy do zapoznania się również z porównaniem Hadoop i Spark.
.
