W dobie, gdy dane stanowią fundament naszego cyfrowego świata, kluczowe staje się zagwarantowanie ich bezpiecznego przetwarzania.
Jako programiści, mierzymy się z nie lada wyzwaniem – zarządzaniem rozbudowanymi, podatnymi na błędy systemami, jednocześnie przekładając ludzkie oczekiwania na interfejsy użytkownika i działanie backendu. Do tego dochodzi jeszcze jeden, zasadniczy aspekt: ochrona danych. Nie bez powodu! Klienci są zrozpaczeni, gdy ich informacje są wykorzystywane w nieodpowiedni sposób, a rządy i organizacje wymagają przestrzegania zasad bezpieczeństwa. Zapewnienie użytkownikom bezpiecznej i komfortowej interakcji z systemem to nasz priorytet.
Bezpieczeństwo danych jako wspólna odpowiedzialność
Złożoność bezpieczeństwa wynika z jego wielowarstwowej struktury, co sprawia, że staje się ono kwestią, za którą każdy ponosi częściową odpowiedzialność, a jednocześnie nikt nie jest w pełni odpowiedzialny. W nowoczesnym środowisku chmurowym, wiele zespołów kontroluje przepływ danych: programiści, administratorzy baz danych, administratorzy systemów (DevOps), uprzywilejowani użytkownicy backendu. Każda z tych grup ma swoje własne priorytety, przez co ochrona danych może być postrzegana jako problem innych. Administrator bazy danych nie jest w stanie kontrolować bezpieczeństwa aplikacji, a osoba odpowiedzialna za DevOps nie ma wpływu na dostęp do backendu.
Rola programistów w ochronie danych
Niemniej jednak, to programiści mają najszerszy zakres dostępu do danych. Tworzą każdą część aplikacji, łączą się z różnymi usługami backendu, przesyłają tokeny dostępu, mają nieograniczony dostęp do baz danych, a ich aplikacje mają pełne uprawnienia w systemie. Przykładowo, produkcyjna aplikacja Django może usuwać całe kolekcje S3. Z tego powodu, to na poziomie kodu źródłowego najczęściej dochodzi do błędów lub zaniedbań w zakresie bezpieczeństwa, za które bezpośrednio odpowiadają programiści.

Bezpieczeństwo danych to temat rzeka, którego nie da się wyczerpać w jednym artykule. Chciałbym jednak przybliżyć podstawowe terminy, które każdy programista powinien znać, aby skutecznie chronić swoje aplikacje. Potraktuj to jako wprowadzenie do bezpieczeństwa danych aplikacji.
Zaczynajmy!
Haszowanie
Szczegółowa definicja haszowania znajduje się na Wikipedii, ale najprościej mówiąc, jest to proces przekształcania danych w nieczytelną formę. Na przykład, stosując popularne (i bardzo niebezpieczne) kodowanie base64, fraza „Czy mój sekret jest u ciebie bezpieczny?” może zostać przekształcona w „SXMgbXkgc2VjcmV0IHNhZmUgd2l0aCB5b3U/”. Gdybyś zaczął pisać swój dziennik w Base64, Twoja rodzina nie mogłaby go odczytać (chyba że wiedzieliby, jak zdekodować Base64)!
Ta metoda „szyfrowania” danych jest wykorzystywana do przechowywania haseł, numerów kart kredytowych itp. w aplikacjach internetowych (i powinna być stosowana we wszystkich rodzajach aplikacji). Chodzi o to, aby w przypadku wycieku danych, haker nie mógł wykorzystać haseł, numerów kart kredytowych i innych danych do wyrządzenia realnej szkody. Do haszowania stosowane są zaawansowane i niezawodne algorytmy; użycie Base64 byłoby nieporozumieniem, ponieważ każdy haker złamałby ten kod w mgnieniu oka.
Haszowanie haseł wykorzystuje technikę kryptograficzną, znaną jako haszowanie jednokierunkowe. Oznacza to, że dane można zaszyfrować, ale nie można ich odszyfrować. Jak więc aplikacja wie, że wprowadzone hasło jest prawidłowe? Otóż, aplikacja wykorzystuje ten sam algorytm i porównuje zaszyfrowaną formę wprowadzonego hasła z zaszyfrowaną formą zapisaną w bazie danych. Jeżeli są identyczne, użytkownik może się zalogować.
Przy okazji, w kontekście haszowania warto wspomnieć o interesującej rzeczy. Jeżeli kiedykolwiek pobierałeś oprogramowanie lub pliki z internetu, mogłeś zostać poproszony o zweryfikowanie plików przed ich użyciem. Na przykład, pobierając obraz ISO systemu Ubuntu Linux, na stronie pobierania znajdziesz opcję weryfikacji pobranego pliku. Po kliknięciu, otworzy się okno:
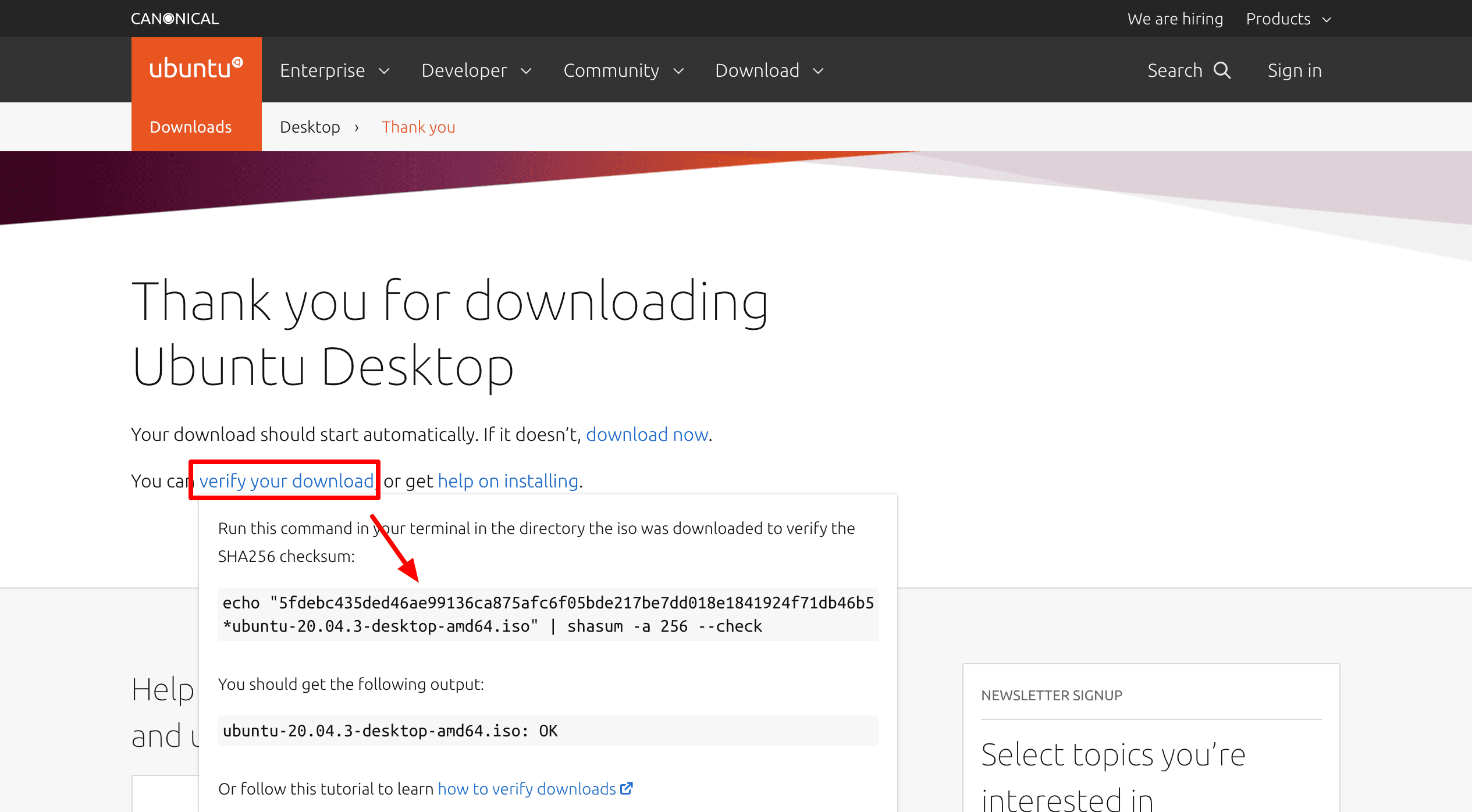
W oknie znajduje się polecenie, które zaszyfruje pobrany plik i porówna wynik z ciągiem hash widocznym na stronie: 5fdebc435ded46ae99136ca875afc6f05bde217be7dd018e1841924f71db46b5. To przekształcenie jest wykonywane za pomocą algorytmu SHA256, o którym wspomina końcowa część polecenia: shasum -a 256 –check.
Jeżeli hash wygenerowany podczas sprawdzania nie zgadza się z hash-em na stronie, oznacza to, że pobrany plik został zmodyfikowany i zamiast oryginalnego, został dostarczony zainfekowany plik.
Popularne algorytmy haszowania to MD5 (uznawany za niebezpieczny i nieużywany), SHA-1 oraz SHA-2 (rodzina algorytmów, do której należy SHA-256 i SHA-512), SCRYPT, BCRYPT i inne.
Solenie
Bezpieczeństwo jest nieustanną grą w kotka i myszkę. Hakerzy analizują istniejące zabezpieczenia i znajdują nowe luki, a twórcy systemów bezpieczeństwa ulepszają swoje metody ochrony. Kryptografia nie jest wyjątkiem. Chociaż odwrócenie haszowania na hasło jest niemożliwe, hakerzy z czasem opracowali zaawansowane techniki, które łączą logiczne zgadywanie z mocą obliczeniową, dzięki czemu w wielu przypadkach są w stanie odgadnąć hasło na podstawie samego hasha.
 „Pan. Rumpelstiltskin, jak mniemam?!”
„Pan. Rumpelstiltskin, jak mniemam?!”
W odpowiedzi na te zagrożenia, opracowano technikę „solenia”. Polega ona na tym, że haszowanie hasła (lub innych danych) odbywa się na podstawie kombinacji dwóch elementów: samej informacji i losowego ciągu, którego haker nie jest w stanie przewidzieć. W praktyce, chcąc zaszyfrować hasło superman009, na początku generujemy losowy ciąg, na przykład bCQC6Z2LlbAsqj77, i następnie haszujemy kombinację superman009-bCQC6Z2LlbAsqj77. Hash wynikowy będzie różnił się od standardowych hash-y generowanych przez dany algorytm, co znacznie ogranicza możliwości inteligentnego inżynierowania wstecznego lub zgadywania haseł.
Zarówno haszowanie, jak i solenie są bardzo złożonymi tematami i ciągle ewoluują. Jako twórcy aplikacji, nie powinniśmy bezpośrednio wnikać w ich szczegóły, ale znajomość tych zagadnień pozwala na podejmowanie lepszych decyzji. Jeżeli w starym frameworku PHP używane są hashe MD5 do haseł, to znak, że należy jak najszybciej wdrożyć nową bibliotekę haseł w procesie tworzenia konta użytkownika.
Klucze
Termin „klucze” jest często używany w kontekście szyfrowania. Dotychczas mówiliśmy o haszowaniu haseł, czyli szyfrowaniu jednokierunkowym, gdzie dane są nieodwracalnie zmieniane i tracą swoją pierwotną formę. W praktyce, nie jest to wygodne rozwiązanie – dokument napisany i wysłany mailem tak bezpiecznie, że nie można go odczytać, nie jest użyteczny. Dlatego, chcemy móc zaszyfrować dane w taki sposób, aby informacje były dostępne dla nadawcy i odbiorcy, ale nieczytelne podczas przesyłania lub przechowywania.
W kryptografii istnieje koncepcja „klucza”. Jest to po prostu klucz do zamka. Właściciel danych szyfruje je przy pomocy sekretnego klucza. Jeżeli odbiorca/haker nie ma dostępu do tego klucza, nie jest w stanie odszyfrować danych, nawet dysponując zaawansowanymi algorytmami.
Rotacja kluczy
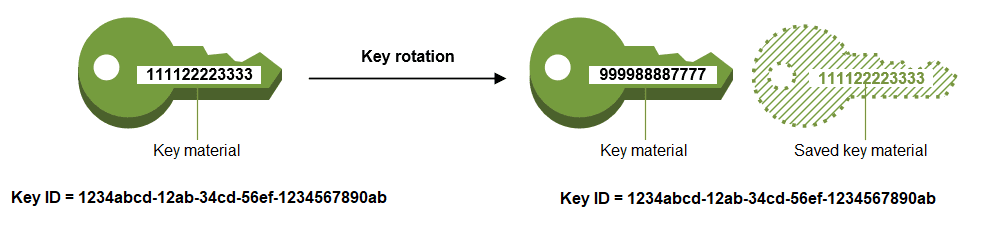
Klucze, pomimo że są niezbędne w procesie szyfrowania, nie są wolne od ryzyka, podobnie jak hasła. Jeżeli ktoś zdobędzie klucz, gra się kończy. Wyobraźmy sobie sytuację, w której haker włamuje się do serwisu typu GitHub i ma dostęp do kodu sprzed 20 lat, w którym znajdują się klucze kryptograficzne wykorzystywane do szyfrowania danych firmy (niestety zdarza się to bardzo często). Jeżeli firma nie zmienia regularnie swoich kluczy, haker może wykorzystać je do wyrządzenia szkód.
W odpowiedzi na to zagrożenie, wprowadzono praktykę częstej zmiany kluczy, znaną jako rotacja kluczy. Szanujący się dostawcy usług PaaS w chmurze, powinni oferować usługę automatycznej rotacji kluczy.
 Źródło obrazu: AWS
Źródło obrazu: AWS
Przykładowo, AWS oferuje usługę AWS Key Management Service (KMS), która automatyzuje proces zmiany i dystrybucji kluczy pomiędzy serwerami, co jest niezbędne w przypadku dużych wdrożeń.
Kryptografia klucza publicznego
Jeżeli omawiane wcześniej zagadnienia związane z szyfrowaniem wydają się skomplikowane, to masz rację. Bezpieczne przechowywanie kluczy i przekazywanie ich w sposób, który zapewnia dostęp do danych tylko odbiorcy, to spore wyzwanie logistyczne. Dzięki kryptografii klucza publicznego, bezpieczna komunikacja i zakupy online są możliwe.
Ten rodzaj kryptografii był przełomem w dziedzinie matematyki i to dzięki niemu, internet działa w sposób bezpieczny. Szczegóły algorytmu są bardzo skomplikowane, więc pozwolę sobie je tutaj wyjaśnić jedynie w sposób koncepcyjny.
 Źródło obrazu: The Electronic Frontier Foundation
Źródło obrazu: The Electronic Frontier Foundation
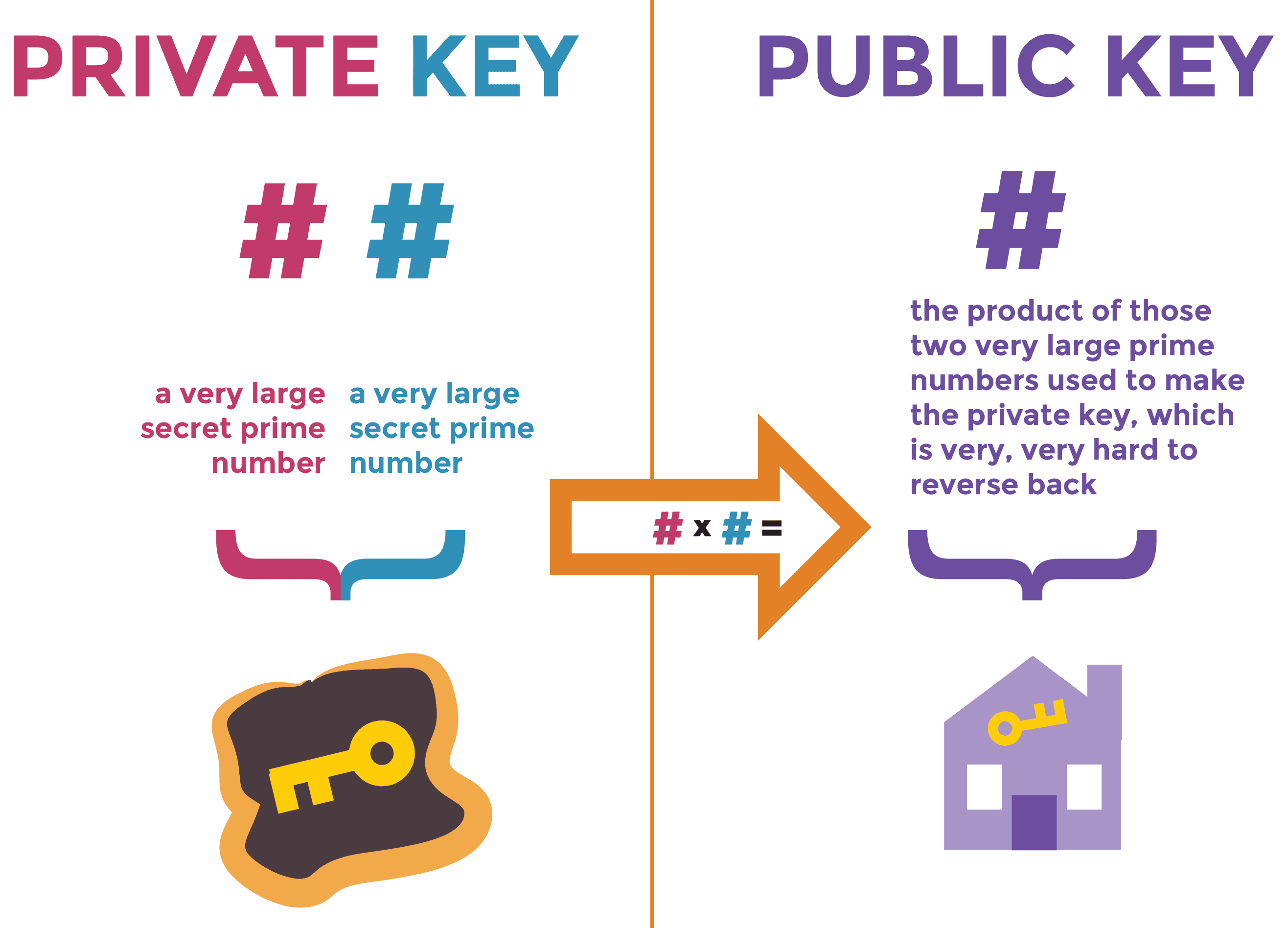
Kryptografia klucza publicznego opiera się na wykorzystaniu dwóch kluczy do przetwarzania informacji. Pierwszy, to klucz prywatny, który powinien pozostać tylko do Twojej wiadomości. Drugi to klucz publiczny, który może być udostępniony każdemu. Jeżeli wysyłam do Ciebie dane, potrzebuję Twojego klucza publicznego, za pomocą którego zaszyfruję dane i wyślę je Tobie. Ty, za pomocą kombinacji klucza prywatnego i publicznego, jesteś w stanie odszyfrować dane. Dopóki nie ujawnisz swojego klucza prywatnego, mogę Ci przesyłać zaszyfrowane dane, do których tylko Ty będziesz miał dostęp.
Zaletą tego systemu jest to, że nie muszę znać Twojego klucza prywatnego, a każdy kto przechwyci wiadomość nie będzie mógł jej odczytać, nawet posiadając Twój klucz publiczny. Jeżeli zastanawiasz się, jak to jest możliwe, najprostsza odpowiedź to właściwość mnożenia liczb pierwszych:
Komputery mają trudność z rozkładaniem dużych liczb pierwszych na czynniki pierwsze. Jeżeli klucz jest wystarczająco długi, to masz pewność, że wiadomości nie będzie można odczytać nawet za setki lat.
Zabezpieczenia warstwy transportowej (TLS)
Teraz już wiesz, jak działa kryptografia klucza publicznego. To właśnie ten mechanizm (znajomość klucza publicznego odbiorcy i wysyłanie mu zaszyfrowanych danych) jest podstawą popularności protokołu HTTPS, przez co Chrome wyświetla informację „Ta witryna jest bezpieczna”. Dzieje się tak dlatego, że serwer i przeglądarka szyfrują ruch HTTP (pamiętaj, że strony internetowe to długi ciąg tekstu, który jest interpretowany przez przeglądarki) przy pomocy kluczy publicznych, co w efekcie daje bezpieczny protokół HTTP (HTTPS).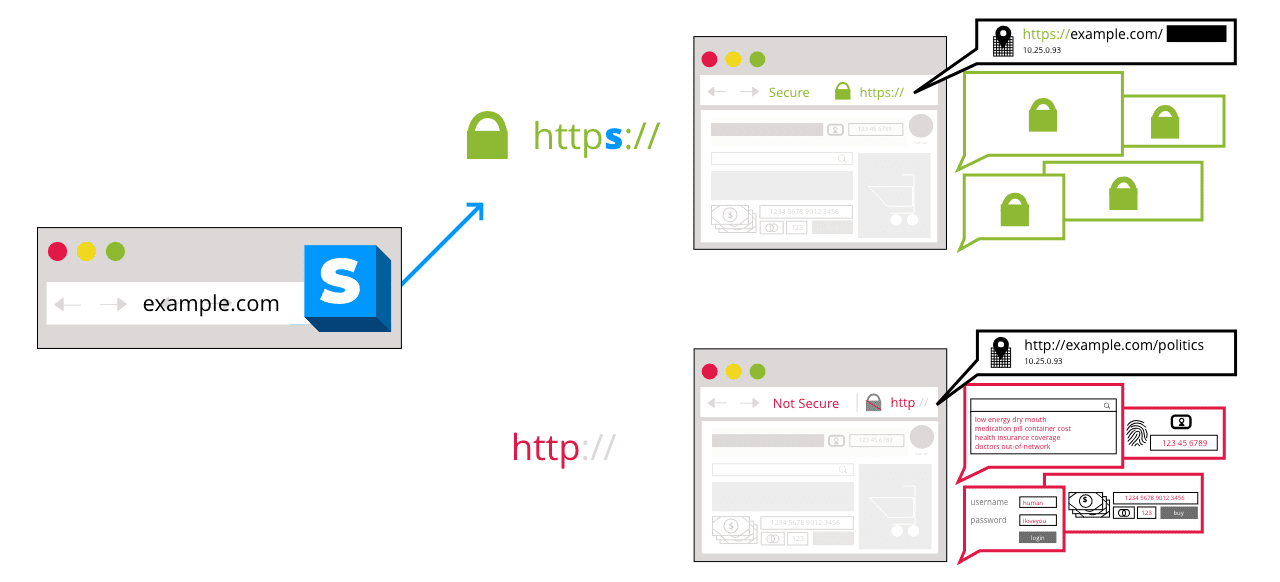
Źródło zdjęcia: Mozilla. Warto zaznaczyć, że szyfrowanie nie odbywa się bezpośrednio w warstwie transportowej. Model OSI nie wspomina nic na temat szyfrowania danych. Po prostu, dane są szyfrowane przez aplikację (w tym przypadku przeglądarkę) przed przesłaniem ich do warstwy transportowej, która następnie kieruje je do celu, gdzie zostają rozszyfrowane. Jednak proces ten obejmuje warstwę transportową, dlatego potocznie używa się terminu „bezpieczeństwo warstwy transportowej”.
Możesz także spotkać się z terminem Secure Socket Layer (SSL). Jest to to samo co TLS, ale SSL powstał wcześniej i został zastąpiony przez TLS.
Pełne szyfrowanie dysku
Czasami, wymagania bezpieczeństwa są tak wysokie, że nie można pozostawić nic przypadkowi. Przykładowo, serwery rządowe, które przechowują dane biometryczne obywateli, nie mogą działać w taki sam sposób jak standardowe serwery aplikacji, z uwagi na zbyt wysokie ryzyko. W takich sytuacjach, nie wystarczy szyfrowanie danych tylko podczas przesyłania; dane muszą być zaszyfrowane także podczas przechowywania. W tym celu stosuje się pełne szyfrowanie dysku, co chroni dane nawet w przypadku fizycznego naruszenia.

Pełne szyfrowanie dysku musi być realizowane na poziomie sprzętowym. Wynika to z tego, że jeżeli cały dysk jest zaszyfrowany, to także system operacyjny jest zaszyfrowany i nie może uruchomić się podczas włączania komputera. Zatem, sprzęt musi wiedzieć, że dysk jest zaszyfrowany i musi deszyfrować dane w locie podczas przesyłania bloków dysku do systemu operacyjnego. Z uwagi na dodatkową pracę, szyfrowanie całego dysku powoduje wolniejszy odczyt i zapis danych, o czym muszą pamiętać twórcy takich systemów.
Szyfrowanie end-to-end
W związku z ciągłymi problemami z prywatnością i bezpieczeństwem w mediach społecznościowych, coraz więcej osób jest świadomych terminu „szyfrowanie end-to-end”, nawet jeżeli nie mają nic wspólnego z tworzeniem aplikacji.
Widzieliśmy już, że pełne szyfrowanie dysku to najlepsza forma ochrony, ale dla zwykłego użytkownika nie jest to wygodne. Wyobraź sobie, że Facebook chciałby chronić dane generowane i przechowywane w telefonie, ale nie może szyfrować całego telefonu i blokować wszystkiego w tym procesie.
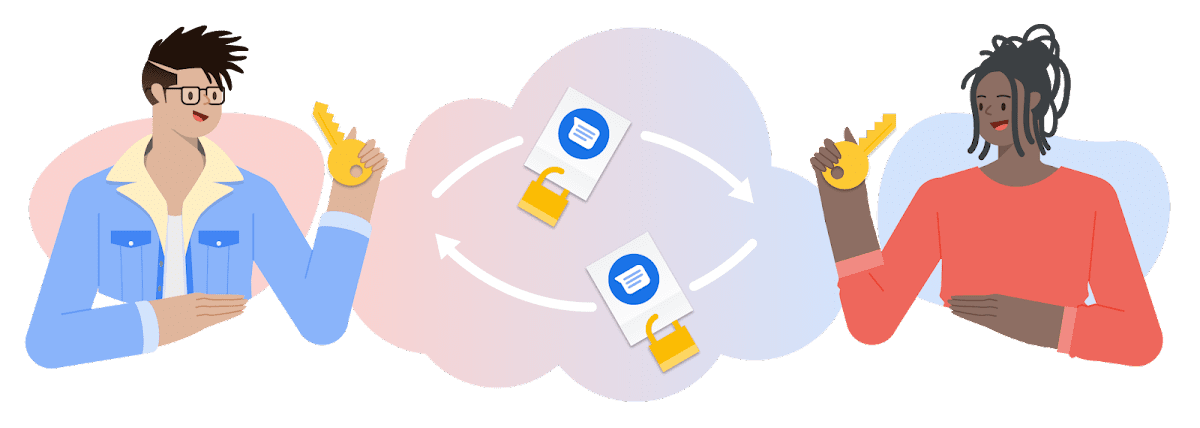
Dlatego firmy te zaczęły stosować kompleksowe szyfrowanie (end-to-end), w którym dane są szyfrowane podczas tworzenia, przechowywania i przesyłania przy użyciu aplikacji. Innymi słowy, dane są w pełni zaszyfrowane nawet po dotarciu do odbiorcy i dostępne tylko na jego telefonie.
 Źródło obrazu: Google
Źródło obrazu: Google
Warto podkreślić, że szyfrowanie end-to-end nie daje żadnych matematycznych gwarancji, jak w przypadku kryptografii klucza publicznego. Jest to po prostu standardowe szyfrowanie, gdzie klucz jest przechowywany przez firmę, a Twoje wiadomości są tak bezpieczne, jak to ustali firma.
Podsumowanie 👩🏫
Prawdopodobnie słyszałeś już o większości z tych terminów, a może o wszystkich. W takim przypadku, zachęcam do ponownego przemyślenia swojej wiedzy o tych zagadnieniach i zastanowienia się nad tym, jak poważnie je traktujesz. Pamiętaj, że ochrona danych aplikacji to ciągła walka, którą musisz wygrać za każdym razem. Nawet jedno naruszenie wystarczy, aby zniszczyć całe branże, kariery, a nawet ludzkie życie!
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.