10 najlepszych grafowych rozwiązań baz danych do wypróbowania
Bazy danych grafowe, idealne do przechowywania powiązanych ze sobą informacji, umożliwiają szybkie i efektywne przetwarzanie zapytań. Zastanawiasz się, kiedy i jaką bazę grafową wybrać? Zapraszamy do lektury, by rozwiać te wątpliwości.
Współczesne powiedzenie głosi, że „dane to nowy surowiec”. Sposób, w jaki organizacje gromadzą i wykorzystują dane, bezpośrednio wpływa na ich rozwój. Każdego dnia generujemy ogromne ilości danych – około 2,5 tryliona bajtów. W związku z tym potrzebujemy niezawodnych systemów i magazynów, które efektywnie przechowają i pomogą zarządzać tymi informacjami. W początkowych latach dominowały relacyjne bazy danych.
Z upływem czasu ilość i różnorodność danych uległy gwałtownym zmianom. Pojawiła się konieczność przechowywania plików wideo, audio, obrazów i innych formatów. To doprowadziło do rozwoju baz SQL, NoSQL, systemów Hadoop oraz baz grafowych. Każda z nich ma swoje specyficzne zastosowania i obsługuje odmienne formaty danych. Bazy grafowe powstały, aby uprościć operacje na danych i zapewnić ich efektywne przechowywanie.
Czym są bazy danych grafowe?
Graf to struktura danych przedstawiana jako zbiór węzłów połączonych krawędziami. Baza danych to z kolei zbiór tabel, w których przechowywane są dane i relacje między nimi. Baza danych grafowa przechowuje dane w węzłach, a powiązania między nimi jako krawędzie. Dzięki temu możliwe jest obsługiwanie zapytań w czasie rzeczywistym oraz efektywne zarządzanie relacjami typu wiele-do-wielu pomiędzy encjami.
Wśród popularnych modeli danych grafowych wyróżniamy wykresy właściwości i wykresy RDF. Wykresy właściwości najczęściej wykorzystuje się do analiz i zapytań, natomiast wykresy RDF służą integracji danych. Główna różnica między nimi polega na sposobie reprezentacji – wykresy RDF przedstawiane są w formie trójek: podmiot, orzecznik i obiekt.
Bazy grafowe magazynują dane w węzłach, a relacje pomiędzy nimi za pomocą krawędzi łączących te węzły. Krawędzie mogą być skierowane (jednokierunkowe) lub nieskierowane (dwukierunkowe).
Przetwarzanie zapytań w bazach grafowych odbywa się poprzez poruszanie się po grafie. Algorytmy przeszukiwania grafów pozwalają na znajdowanie ścieżek między węzłami, obliczanie odległości, wykrywanie wzorców i pętli oraz tworzenie klastrów. Wszystko to umożliwia szybkie i efektywne odpowiadanie na zapytania.
Zastosowania baz danych grafowych
Bazy grafowe znajdują zastosowanie między innymi w wykrywaniu oszustw. Węzłami mogą być dane osobowe, takie jak imiona, nazwiska, adresy, daty urodzenia, a także podejrzane adresy IP i numery urządzeń. Powiązania pomiędzy oszukańczymi a prawdziwymi węzłami są flagowane jako podejrzane.
Media społecznościowe wykorzystują bazy grafowe, aby rekomendować użytkownikom znajomych oraz treści, które mogą ich zainteresować. Jest to możliwe dzięki algorytmom przeszukującym sieć powiązań w bazie.
Bazy grafowe są również efektywnym narzędziem do mapowania sieci, zarządzania infrastrukturą i elementami konfiguracji.
Baza grafowa a relacyjna baza danych
W bazach grafowych tabele z wierszami i kolumnami zastępowane są węzłami i krawędziami, gdzie krawędzie przechowują relacje pomiędzy danymi.
Relacyjne bazy danych przechowują relacje między tabelami za pomocą kluczy obcych. Wyodrębnianie danych i wykonywanie zapytań jest prostsze w bazach grafowych i nie wymaga złożonych połączeń, czego nie można powiedzieć o relacyjnych bazach.
Relacyjne bazy danych są najbardziej odpowiednie w przypadku transakcji, podczas gdy bazy grafów najlepiej sprawdzają się w aplikacjach z dużą ilością relacji i danych.
Bazy grafowe obsługują dane ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane, podczas gdy relacyjne bazy danych wymagają ustalonego schematu.
Bazy grafowe lepiej radzą sobie z dynamicznymi wymaganiami, podczas gdy relacyjne bazy danych są często wykorzystywane do rozwiązywania znanych i statycznych problemów.
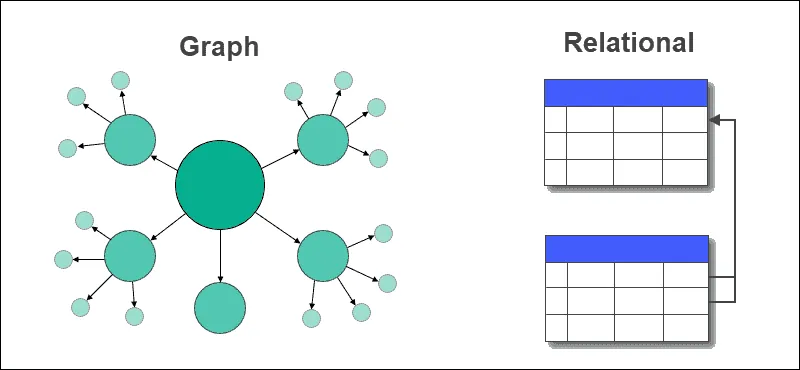 Porównanie baz grafowych i relacyjnych
Porównanie baz grafowych i relacyjnych
Przejdźmy teraz do przeglądu najlepszych rozwiązań baz danych grafowych.
Cayley
Cayley to baza grafowa o otwartym kodzie źródłowym, rozwijana w ramach licencji Apache 2.0. Została napisana w języku Go i przeznaczona jest do pracy z danymi powiązanymi. Cayley była wykorzystywana do budowy Freebase i wykresu wiedzy Google. Obsługuje wiele języków zapytań, takich jak MQL i JavaScript, a także obiekt grafowy bazujący na Gremlinie.

Jest łatwa w użyciu, szybka i modułowa. Integruje się z różnymi magazynami danych, takimi jak LevelDB, MongoDB i Bolt. Obsługuje API napisane w wielu językach, w tym Java, .NET, Rust, Haskell, Ruby, PHP, Javascript i Clojure. Można ją wdrożyć w Docker i Kubernetes. Cayley znajduje zastosowanie głównie w technologiach informacyjnych, oprogramowaniu komputerowym i usługach finansowych.
Amazon Neptune
Amazon Neptune jest ceniony za wydajność w pracy z wysoce połączonymi zbiorami danych. Jest niezawodny, bezpieczny, w pełni zarządzany i obsługuje otwarte API. Potrafi przechowywać miliardy powiązań i szybko przetwarzać zapytania z opóźnieniem rzędu kilku milisekund.
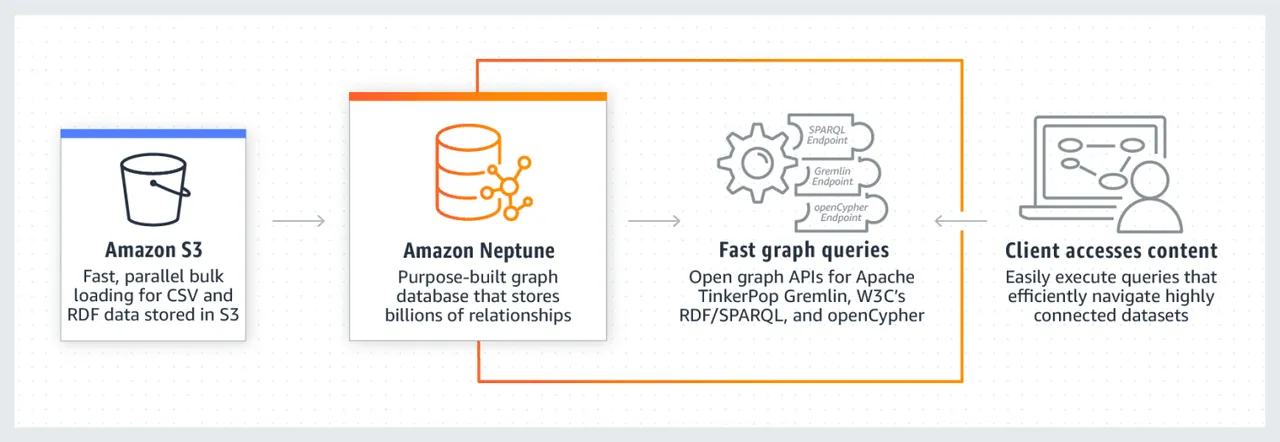
Model danych w Neptune składa się z czterech elementów: podmiotu (S), orzecznika (P), obiektu (O) i grafu (G). Elementy te służą do przechowywania informacji o węźle źródłowym, węźle docelowym, relacji między nimi oraz ich właściwościach.
Neptune wykorzystuje pamięć podręczną, co przyspiesza wykonywanie zapytań odczytowych. Dane są przechowywane w formie klastrów baz danych, gdzie każdy klaster składa się z instancji podstawowej i replik do odczytu. Neptune charakteryzuje się wysokim poziomem bezpieczeństwa, dzięki uwierzytelnianiu uprawnień, certyfikacji SSL i monitorowaniu logów. Migracja danych do Amazon Neptune jest również prosta. Platforma zapewnia odporność na awarie poprzez tworzenie replik i regularne kopie zapasowe. Do firm korzystających z Neptune należą Herren, Onedot, Juncture i Hi Platform.
Neo4j
Neo4j to skalowalna, bezpieczna, dostępna na żądanie i niezawodna baza danych grafów. Została napisana w Javie i używa języka zapytań Cypher. Komunikacja odbywa się za pomocą protokołu Bolt, a wszystkie transakcje są obsługiwane przez punkt końcowy HTTP. Neo4j jest znacznie szybszy w przetwarzaniu zapytań niż tradycyjne relacyjne bazy danych. Nie ma narzutu związanego ze złożonymi połączeniami, a jej optymalizacje działają efektywnie przy dużych i silnie połączonych zbiorach danych. Łączy zalety przechowywania grafów z właściwościami ACID relacyjnych baz danych.

Neo4j obsługuje wiele języków programowania, takich jak Java, .NET, Node.js, Ruby, Python, dzięki dostępnym sterownikom. Znajduje zastosowanie w przepływach pracy z danymi grafowymi, analizami i uczeniu maszynowym. Neo4j Aura DB to odporna na awarie, w pełni zarządzana baza danych w chmurze. Z Neo4j korzystają firmy takie jak Microsoft, Cisco, Adobe, eBay, IBM i Samsung.
ArangoDB
ArangoDB to wielomodelowa baza danych typu open source. Umożliwia użytkownikom tworzenie zapytań w dowolnym języku. Węzły i krawędzie w ArangoDB są reprezentowane jako dokumenty JSON. Każdy dokument ma unikalny identyfikator. Relacje między węzłami są definiowane za pomocą krawędzi, które przechowują unikalne identyfikatory węzłów. Dzięki indeksowi skrótu ArangoDB oferuje wysoką wydajność.

Zoptymalizowano w niej przeszukiwanie grafów, łączenie danych i wyszukiwanie. Ułatwia projektowanie, skalowanie i dostosowywanie się do różnych architektur. ArangoDB odgrywa ważną rolę w złożonych zadaniach analizy danych, takich jak wyodrębnianie cech i zaawansowane wyszukiwanie.
ArangoDB może działać w chmurze i jest kompatybilna z systemami Mac OS, Linux i Windows. Bezpieczeństwo bazy danych jest zapewnione przez uwierzytelnianie LDAP, maskowanie danych i algorytmy szyfrowania. ArangoDB jest wykorzystywana w zarządzaniu ryzykiem, IAM, wykrywaniu oszustw, infrastrukturze sieciowej i systemach rekomendacji. Do firm korzystających z niej należą Accenture, Cisco, Dish i VMware.
DataStax
DataStax to chmurowa baza danych NoSQL typu „usługa”, bazująca na Apache Cassandra. Jest wysoce skalowalna i wykorzystuje architekturę natywną dla chmury. Jest niezawodna i bezpieczna. Każdy dokument przechowywany w DataStax ma indeks, który ułatwia wyszukiwanie i szybkie pobieranie danych. Fragmenty są tworzone na danych zindeksowanych. Do budowy aplikacji można wykorzystać różne źródła danych za pomocą narzędzi Datastax Enterprise, Kafka i Docker.
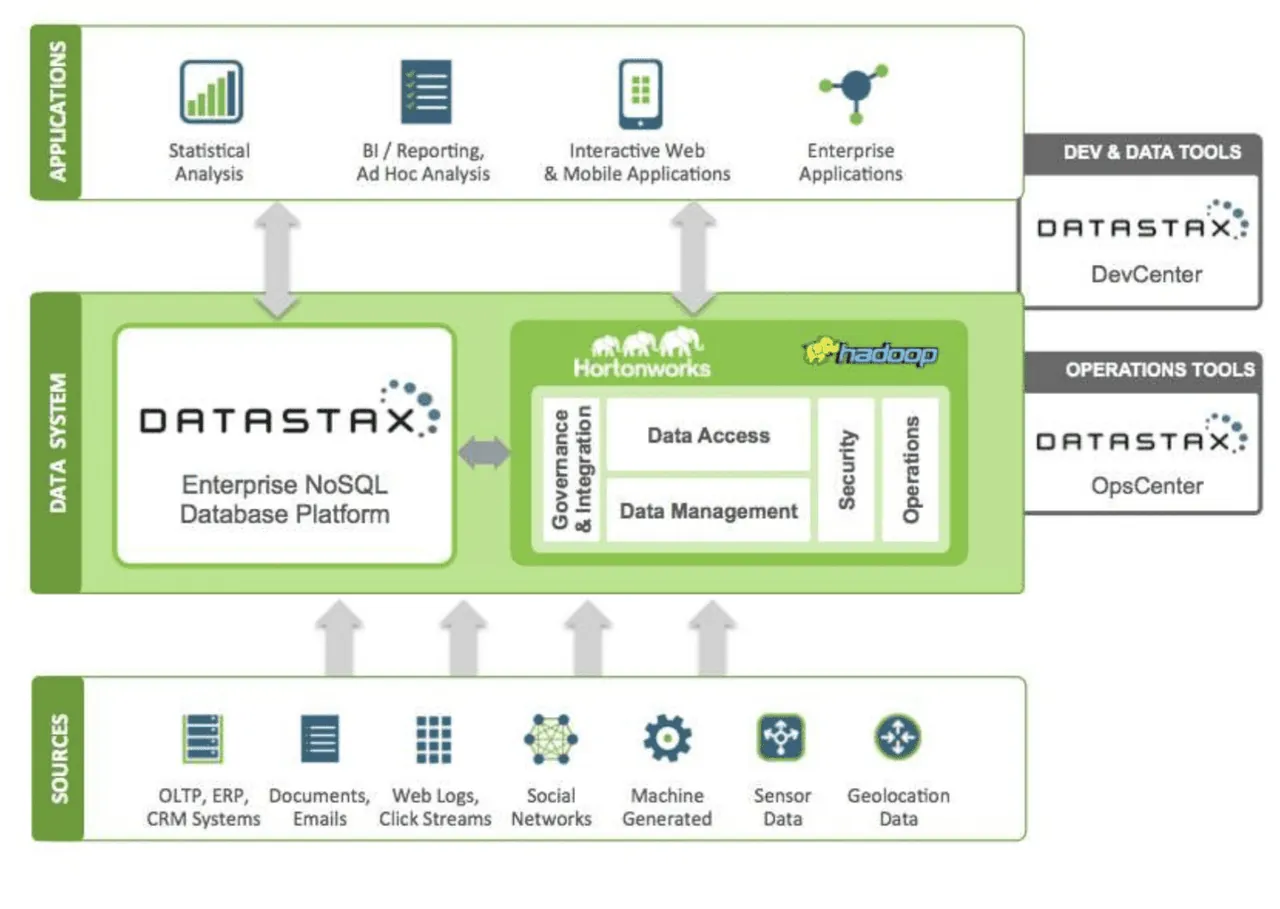
Dane ze źródeł są przesyłane do ekosystemu Hadoop i DataStax. Hadoop odpowiada za bezpieczeństwo, operacje, dostęp i zarządzanie danymi poprzez interakcję z DataStax. Dane są przetwarzane za pomocą narzędzi programistycznych i operacyjnych Datastax.
Analizowane informacje są następnie wykorzystywane do analizy statystycznej, aplikacji korporacyjnych i raportowania. Jako usługa w chmurze, DataStax oferuje model płatności za faktyczne zużycie zasobów, co sprawia, że jest to rozwiązanie opłacalne. DataStax jest używany przez firmy takie jak Verizon, CapitalOne, TMobile i Overstock.
OrientDB
OrientDB to baza danych grafów, która efektywnie zarządza danymi i pomaga w tworzeniu wizualnych reprezentacji. Jest to wielomodelowa baza danych grafowa, napisana w Javie. Przechowuje dane w postaci par klucz-wartość, dokumentów i modeli obiektów. Składa się z trzech kluczowych elementów: edytora grafów, studia zapytań i konsoli wiersza poleceń.
Edytor grafów służy do wizualizacji i interakcji z danymi. Interfejs Studio Zapytań służy do tworzenia zapytań i natychmiastowego generowania wyników w formie graficznej lub tabelarycznej. Konsola wiersza poleceń służy do odpytywania danych z OrientDB. Ma rozproszoną architekturę z wieloma serwerami, które mogą wykonywać operacje odczytu i zapisu. Serwery replik są przeznaczone do operacji odczytu i wykonywania zapytań. OrientDB obsługuje indeksowanie i jest zgodny z zasadami ACID. Do firm korzystających z OrientDB należą Comcast Corporation i Blackfriars Group.
Dgraph
Dgraph to chmurowa baza danych grafów, która obsługuje GraphQL. Została napisana w języku Go. Minimalizuje połączenia sieciowe i opóźnienia, maksymalizując równoczesne przetwarzanie zapytań. Integracja Dgraph z GraphQL ułatwia tworzenie aplikacji backendowych.

Mutacje GraphQL są przesyłane przez funkcję Lambda, która współdziała z bazą danych i potokiem danych. Upraszcza to proces przetwarzania zapytań. Dgraph jest skalowalny w poziomie, co oznacza, że zasoby rosną wraz z ilością zapytań i danych. Zapewnia funkcje takie jak autoryzacja JWT, wizualizacja danych, uwierzytelnianie w chmurze i kopie zapasowe danych. Dgraph jest wykorzystywany przez takie firmy jak Intuit, Intel i Factset.
Tigergraph
Tigergraph to baza danych grafów właściwości napisana w C++. Jest wysoce skalowalna i umożliwia zaawansowane analizy na połączonych danych. Wykorzystuje strukturę grafu do przechowywania danych i silnik do przetwarzania. Baza danych jest przechowywana na dysku i w pamięci, a dodatkowo korzysta z pamięci podręcznej procesora w celu przyspieszenia wyszukiwania. Tigergraph używa Map Reduce do równoległego przetwarzania danych.
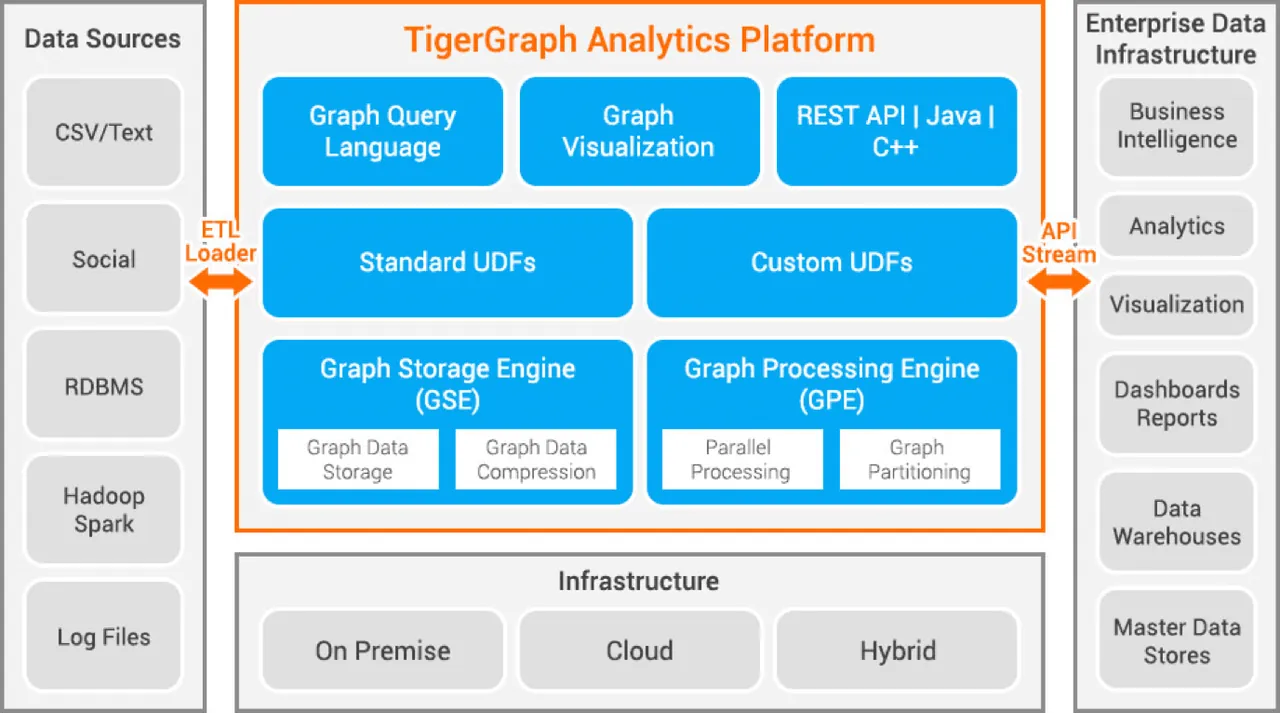
Jest wyjątkowo szybka i skalowalna. Umożliwia równoległe obliczenia i aktualizacje w czasie rzeczywistym. Stosuje techniki kompresji danych, zmniejszając ich rozmiar nawet 10-krotnie. Automatycznie dzieli dane między serwery, co oszczędza czas i wysiłek związany z ręcznym fragmentowaniem. Tigergraph jest wykorzystywany do wykrywania oszustw, zarządzania łańcuchem dostaw i poprawy jakości opieki zdrowotnej. JPMorgan Chase, Intuit i United Health Group to firmy, które korzystają z tego rozwiązania.
AllegroGraph
AllegroGraph wykorzystuje technologię grafu wiedzy do wykonywania analiz i podejmowania decyzji dotyczących złożonych i gęstych danych. Dane są przechowywane w formacie JSON i JSON-LD w węzłach grafu. Wykorzystuje architekturę protokołu REST. AllegroGraph radzi sobie z bardzo dużymi zbiorami danych, dzieląc je według określonych kryteriów i rozpraszając pomiędzy wieloma repozytoriami wiedzy.
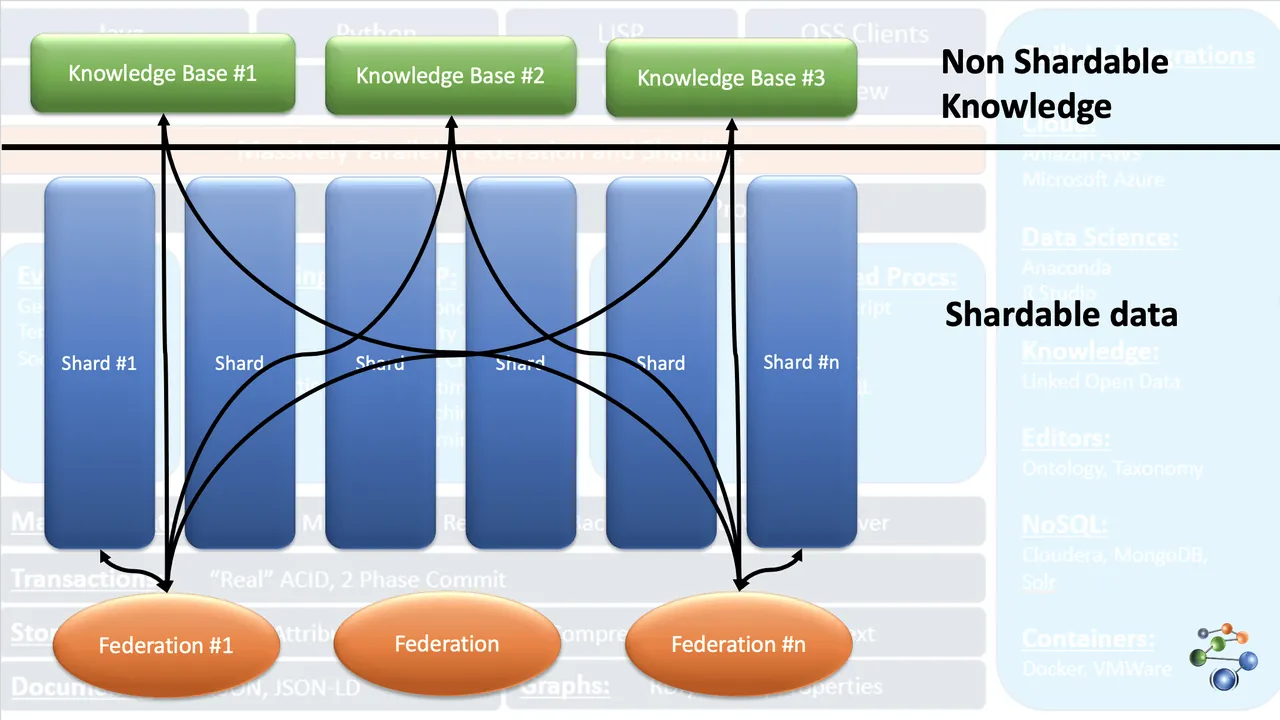
Dzięki funkcji FedShard, AllegroGraph realizuje zapytania poprzez połączenie federacji z repozytoriami wiedzy. Obsługuje typy schematów XML i wykorzystuje indeksy potrójne. Przechowuje dane geoprzestrzenne, takie jak szerokość i długość geograficzna, a także dane czasowe, takie jak data i znacznik czasu. Jest kompatybilny z systemami Windows, Mac i Linux. AllegroGraph znajduje zastosowanie w wykrywaniu oszustw, opiece zdrowotnej, identyfikacji podmiotów i przewidywaniu ryzyka.
Stardog
Stardog to baza danych grafów, która wirtualizuje dane grafowe i łączy je z hurtowni danych i jezior danych bez konieczności ich kopiowania. Stardog bazuje na otwartych standardach RDF. Obsługuje dane strukturalne, częściowo ustrukturyzowane i nieustrukturyzowane. Stardog łączy funkcjonalności grafów wiedzy i wirtualizacji danych.

Stardog wykorzystuje silnik wnioskowania oparty na sztucznej inteligencji, co pozwala na efektywne przetwarzanie i szybkie dostarczanie wyników zapytań. Jest to baza danych grafów zgodna z zasadami ACID. Obsługuje równoczesne odczyty i zapisy. Dzięki zaawansowanej architekturze łatwo radzi sobie ze złożonymi zapytaniami. Stardog jest stosowany w zarządzaniu zasobami IT, zarządzaniu danymi, analizie i zapewnia wysoką dostępność. Z Stardog korzystają między innymi Cisco, eBay, NASA i Finra.
Podsumowanie
Bazy danych grafów pomagają w łatwym wyszukiwaniu relacji wiele-do-wielu i efektywnym przechowywaniu danych. Są skalowalne, bezpieczne i integrują się z wieloma narzędziami, API i językami. W ostatnich latach zyskały na popularności dzięki integracji z chmurą i zapewniają najlepszą wydajność.
Upraszczają złożone połączenia w proste zapytania, co ułatwia pracę programistom. Bazy grafów są również wykorzystywane w zadaniach wymagających analizy dużych ilości danych, jak IoT i Big Data. Będą one nadal ewoluować i z pewnością znajdą kolejne zastosowania w przyszłości.
