10 struktur danych w Pythonie [Explained With Examples]
Chcesz wzbogacić swój zestaw narzędzi programistycznych o zaawansowane struktury danych? Zacznij już dziś, eksplorując różnorodne struktury danych dostępne w Pythonie.
Podczas nauki nowego języka programowania kluczowe jest zrozumienie podstawowych typów danych oraz wbudowanych struktur, które ten język oferuje. W tym przewodniku po strukturach danych Pythona przeanalizujemy:
- korzyści płynące ze stosowania struktur danych,
- wbudowane struktury danych w Pythonie, takie jak listy, krotki, słowniki i zbiory,
- sposoby implementacji abstrakcyjnych typów danych, takich jak stosy i kolejki.
Zaczynamy naszą podróż!
Dlaczego znajomość struktur danych jest tak ważna?
Zanim przejdziemy do konkretnych struktur danych, warto przyjrzeć się, jak wykorzystanie struktur danych może być korzystne:
- Efektywna obróbka danych: Odpowiedni dobór struktury danych pozwala na bardziej efektywne przetwarzanie informacji. Na przykład, jeśli potrzebujesz przechowywać zbiór elementów tego samego typu, z szybkim dostępem i silnym powiązaniem, tablica może być idealnym wyborem.
- Optymalne zarządzanie pamięcią: W rozbudowanych projektach, dla tych samych danych, jedna struktura może okazać się bardziej oszczędna pamięciowo niż inna. W Pythonie, zarówno listy, jak i krotki mogą przechowywać kolekcje danych tego samego lub różnych typów. Jeżeli jednak wiesz, że kolekcja nie będzie modyfikowana, krotka zużyje mniej pamięci niż lista.
- Przejrzysty kod: Użycie właściwej struktury danych dla określonej funkcji sprawia, że kod jest bardziej zorganizowany. Programiści, którzy będą czytać Twój kod, będą oczekiwać, że użyjesz konkretnych struktur w zależności od wymaganego działania. Na przykład, jeśli potrzebujesz mapowania klucz-wartość z szybkim dostępem i wstawianiem, słownik będzie najlepszym rozwiązaniem.
Listy
Listy są podstawowymi strukturami danych w Pythonie, wykorzystywanymi do tworzenia dynamicznych tablic, od zadań rekrutacyjnych po standardowe zastosowania.
Listy w Pythonie są typami danych kontenerowych, które są zmienne i dynamiczne. Możesz łatwo dodawać i usuwać elementy z listy, bez potrzeby tworzenia jej kopii.
Kiedy pracujesz z listami w Pythonie:
- Dostęp do elementu o określonym indeksie jest realizowany w czasie stałym.
- Dodanie elementu na koniec listy odbywa się w czasie stałym.
- Wstawienie elementu w określonym miejscu w liście wymaga czasu liniowego.
Python oferuje zestaw metod listowych, które ułatwiają wykonywanie typowych operacji. Poniższy fragment kodu demonstruje, jak wykonywać operacje na przykładowej liście:
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Listy w Pythonie obsługują także wycinanie i sprawdzanie przynależności za pomocą operatora `in`:
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
Struktura danych listy jest nie tylko elastyczna i prosta, ale również umożliwia przechowywanie elementów różnego typu. Python posiada także dedykowaną strukturę tablicową, która pozwala na wydajniejsze przechowywanie elementów tego samego typu. O tym porozmawiamy w dalszej części przewodnika.
Krotki
Krotki są kolejną popularną wbudowaną strukturą danych w Pythonie. Działają podobnie do list, umożliwiając szybki dostęp do elementów za pomocą indeksowania i wycinania. Kluczową różnicą jest jednak to, że są one niezmienne, więc nie można ich modyfikować po utworzeniu. Poniższy przykład pokazuje te różnice:
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # To nie zadziała! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
Jeśli więc chcesz utworzyć niezmienną kolekcję, która będzie wydajnie przetwarzana, warto rozważyć użycie krotki. W sytuacji, gdy potrzebujesz modyfikowalnej kolekcji, lepiej sprawdzi się lista.
📋 Dowiedz się więcej na temat podobieństw i różnic pomiędzy listami i krotkami w Pythonie.
Tablice
Tablice są mniej znaną strukturą danych w Pythonie. Pod względem operacji, takich jak dostęp w czasie stałym i wstawianie elementu w określonym miejscu, przypominają listy.
Główną różnicą między listami a tablicami jest to, że tablice przechowują elementy tylko jednego typu. Z tego powodu są one ściślej powiązane i bardziej wydajne pod względem wykorzystania pamięci.
Aby utworzyć tablicę, używamy konstruktora `array()` z wbudowanego modułu `array`. Konstruktor `array()` pobiera jako argument ciąg znaków określający typ danych oraz elementy. W poniższym przykładzie tworzymy tablicę `nums_f` przechowującą liczby zmiennoprzecinkowe:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
Możemy uzyskać dostęp do elementów tablicy przy pomocy indeksowania (podobnie jak w listach):
>>> nums_f[0] 1.5
Tablice są zmienne, więc można je modyfikować:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Nie możemy jednak zmienić typu danych elementu:
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Łańcuchy znaków
W Pythonie łańcuchy znaków są niezmiennymi kolekcjami znaków Unicode. W przeciwieństwie do języków takich jak C, Python nie posiada dedykowanego typu danych znakowych. W Pythonie pojedynczy znak to łańcuch o długości jeden.
Jak wspomniano, łańcuchy znaków są niezmienne:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Łańcuchy znaków w Pythonie wspierają operacje wycinania oraz posiadają szereg metod formatowania. Oto kilka przykładów:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ Należy pamiętać, że wszystkie powyższe operacje zwracają kopię łańcucha i nie modyfikują oryginalnego łańcucha. Jeśli jesteś zainteresowany, zachęcamy do zapoznania się z przewodnikiem dotyczącym operacji na łańcuchach w Pythonie.
Zbiory
W Pythonie zbiory są kolekcjami unikalnych i haszowalnych elementów. Możemy na nich wykonywać typowe operacje zbiorowe, takie jak suma, przecięcie i różnica:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Zbiory domyślnie są zmienne, więc możemy dodawać i modyfikować ich elementy:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Przeczytaj więcej o zbiorach w Pythonie: kompletny przewodnik z przykładami kodu.
Frozen Zbiory
Jeśli potrzebujesz niezmiennego zbioru, możesz użyć `frozenset`. Możemy go stworzyć z istniejącego zbioru lub dowolnego iterowalnego obiektu.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
Ponieważ `frozenset_1` jest niezmiennym zbiorem, próba dodania elementów (lub innej modyfikacji) zakończy się błędem:
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Słowniki
Słowniki w Pythonie działają podobnie do map skrótów. Przechowują one pary klucz-wartość. Klucze słownika muszą być haszowalne, czyli ich wartość skrótu nie zmienia się w czasie życia obiektu.
Dostęp do wartości, wstawianie nowych elementów i usuwanie istniejących odbywa się w czasie stałym. Python udostępnia metody słownikowe do wykonywania tych operacji.
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Słowniki Pythona zapewniają mapowanie klucz-wartość, ale są z natury nieuporządkowane. Od wersji Pythona 3.7 kolejność wstawiania elementów jest zachowywana, ale aby podkreślić to zachowanie, można użyć `OrderedDict` z modułu `collections`.
Jak widać, `OrderedDict` zachowuje kolejność kluczy:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
Defaultdict
Podczas pracy ze słownikami w Pythonie, błędy związane z brakiem klucza są dość powszechne. Za każdym razem, gdy próbujesz uzyskać dostęp do klucza, który nie został jeszcze dodany do słownika, otrzymasz wyjątek `KeyError`.
Używając `defaultdict` z modułu `collections`, możemy obsłużyć takie sytuacje. Kiedy próbujemy uzyskać dostęp do klucza, którego nie ma w słowniku, klucz jest dodawany i inicjalizowany wartością domyślną, określoną przez domyślną fabrykę.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
Stosy
Stos to struktura danych, w której elementy są dodawane i usuwane w kolejności "ostatni na wejściu, pierwszy na wyjściu" (LIFO - Last-In-First-Out). Operacje na stosie to:
- Dodawanie elementów na wierzch stosu (push).
- Usuwanie elementów z wierzchu stosu (pop).
Poniższy schemat ilustruje operacje push i pop na stosie:
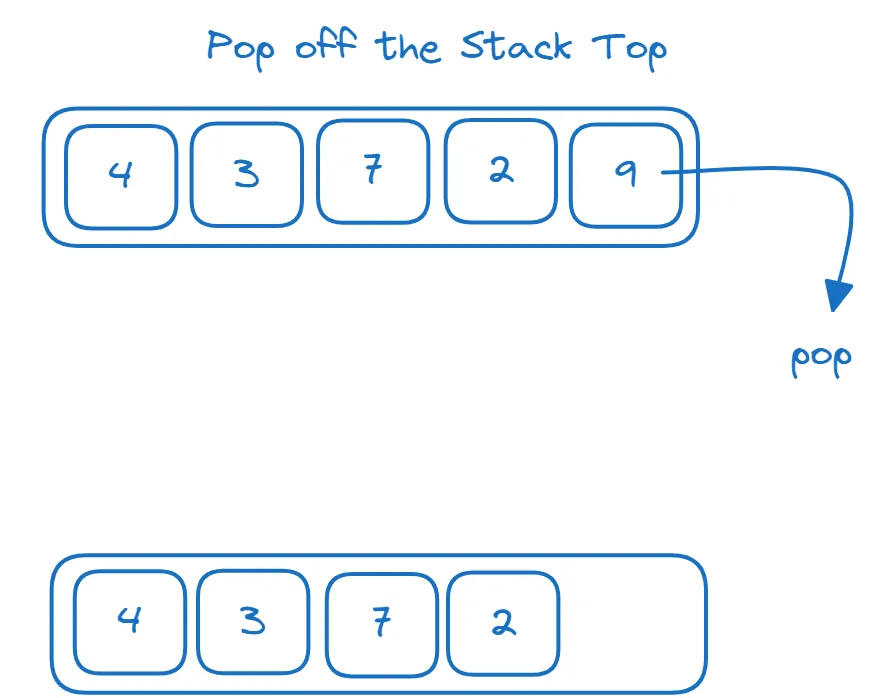
Implementacja stosu za pomocą listy
W Pythonie stos można zaimplementować za pomocą listy.
Operacje na stosie i ich odpowiedniki na liście:
Operacja stosu | Operacja na liście
Push na szczyt stosu | Dodawanie na koniec listy za pomocą `append()`
Pop ze szczytu stosu | Usuwanie i zwracanie ostatniego elementu za pomocą `pop()`
Poniższy przykład pokazuje, jak naśladować działanie stosu za pomocą listy Pythona:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Implementacja stosu za pomocą Deque
Stos można również zaimplementować za pomocą `deque` z modułu `collections`. `Deque` (dwustronna kolejka) obsługuje dodawanie i usuwanie elementów z obu końców.
Aby stworzyć stos za pomocą `deque`, możemy:
- Dodawać elementy na końcu deque używając `append()`
- Pobierać ostatnio dodany element używając `pop()`
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2, 9]) >>> stk.pop() 9
Kolejki
Kolejka to struktura danych, w której elementy są dodawane na końcu i usuwane z początku, zgodnie z zasadą "pierwszy na wejściu, pierwszy na wyjściu" (FIFO - First-In-First-Out). Poniższy schemat ilustruje zasadę działania kolejki:
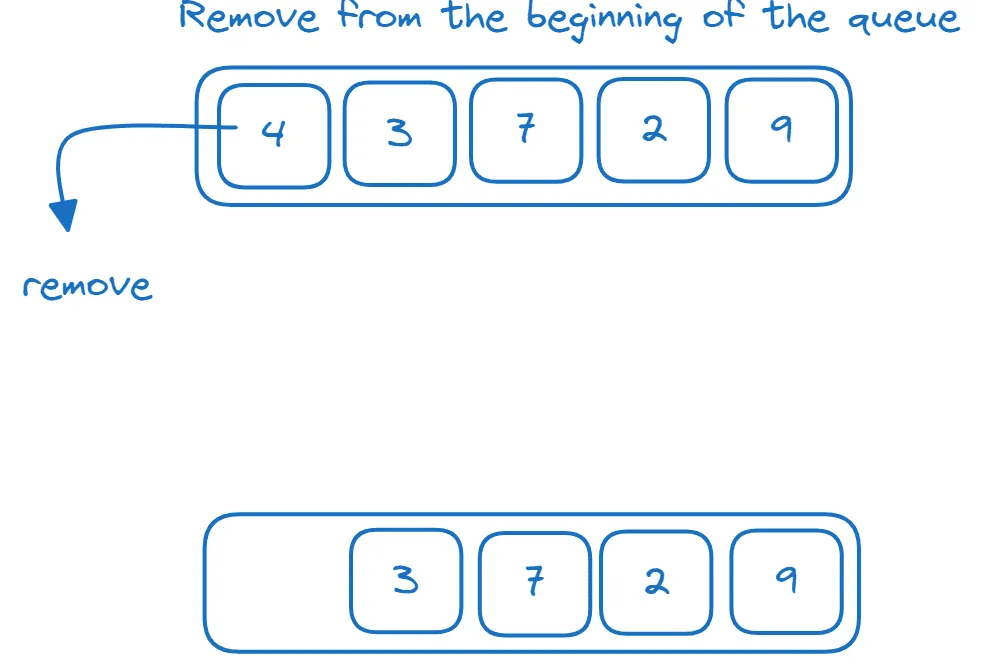
Kolejkę możemy zaimplementować za pomocą `deque`:
- Dodajemy elementy na koniec kolejki za pomocą `append()`.
- Usuwamy element z początku kolejki za pomocą `popleft()`.
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Stosy binarne (Heap)
W tej części omówimy sterty binarne, skupiając się na stertach typu min-heap.
Sterta typu min-heap to kompletne drzewo binarne, gdzie każdy węzeł jest mniejszy od swoich potomków. Wyjaśnijmy, co znaczy "kompletne drzewo binarne":
- Drzewo binarne to struktura danych, gdzie każdy węzeł ma co najwyżej dwa węzły potomne.
- "Kompletne" oznacza, że drzewo jest całkowicie wypełnione, być może z wyjątkiem ostatniego poziomu. Jeśli ostatni poziom jest częściowo wypełniony, wypełniany jest od lewej do prawej.
Z powodu tej własności, korzeń drzewa min-heap jest zawsze najmniejszym elementem.
Poniżej przykład drzewa min-heap:
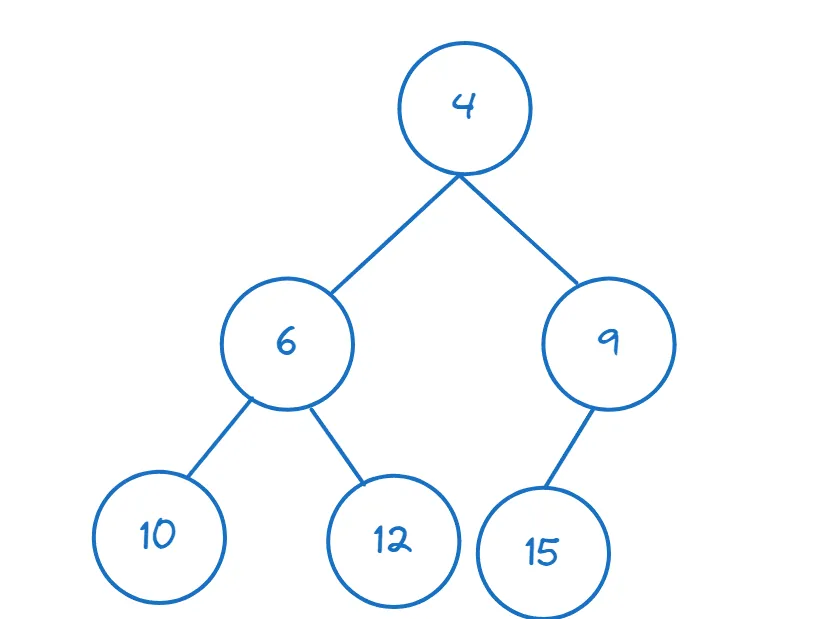
W Pythonie, moduł `heapq` pomaga konstruować sterty i operować na nich. Zaimportujmy wymagane funkcje z `heapq`:
>>> from heapq import heapify, heappush, heappop
Jeśli mamy listę lub inny iterowalny obiekt, możemy zbudować z niego stertę używając `heapify()`:
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
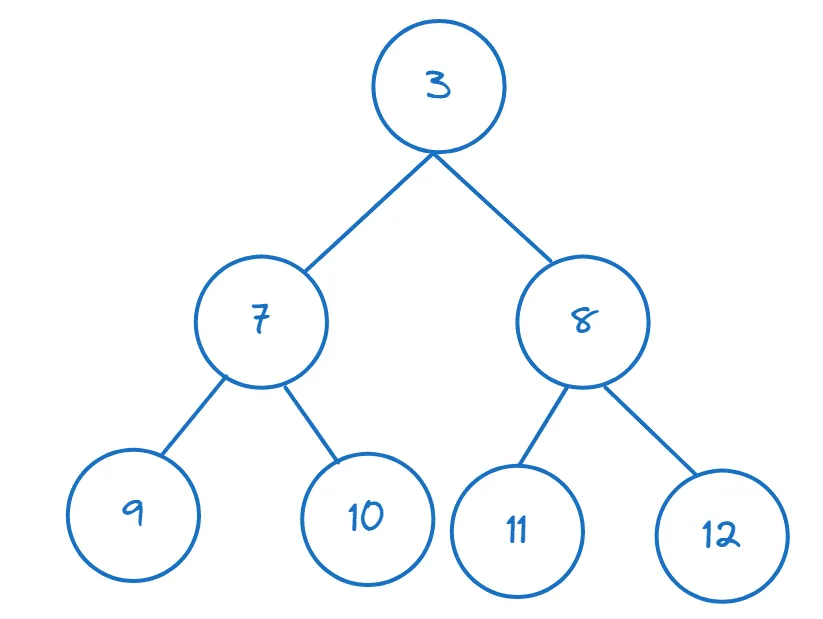
Możemy sprawdzić, czy pierwszy element jest rzeczywiście najmniejszy, uzyskując dostęp do niego za pomocą indeksowania:
>>> nums[0] 3
Po dodaniu nowego elementu do sterty, węzły są automatycznie przestawiane, aby zachować własność min-heap.
>>> heappush(nums,1)
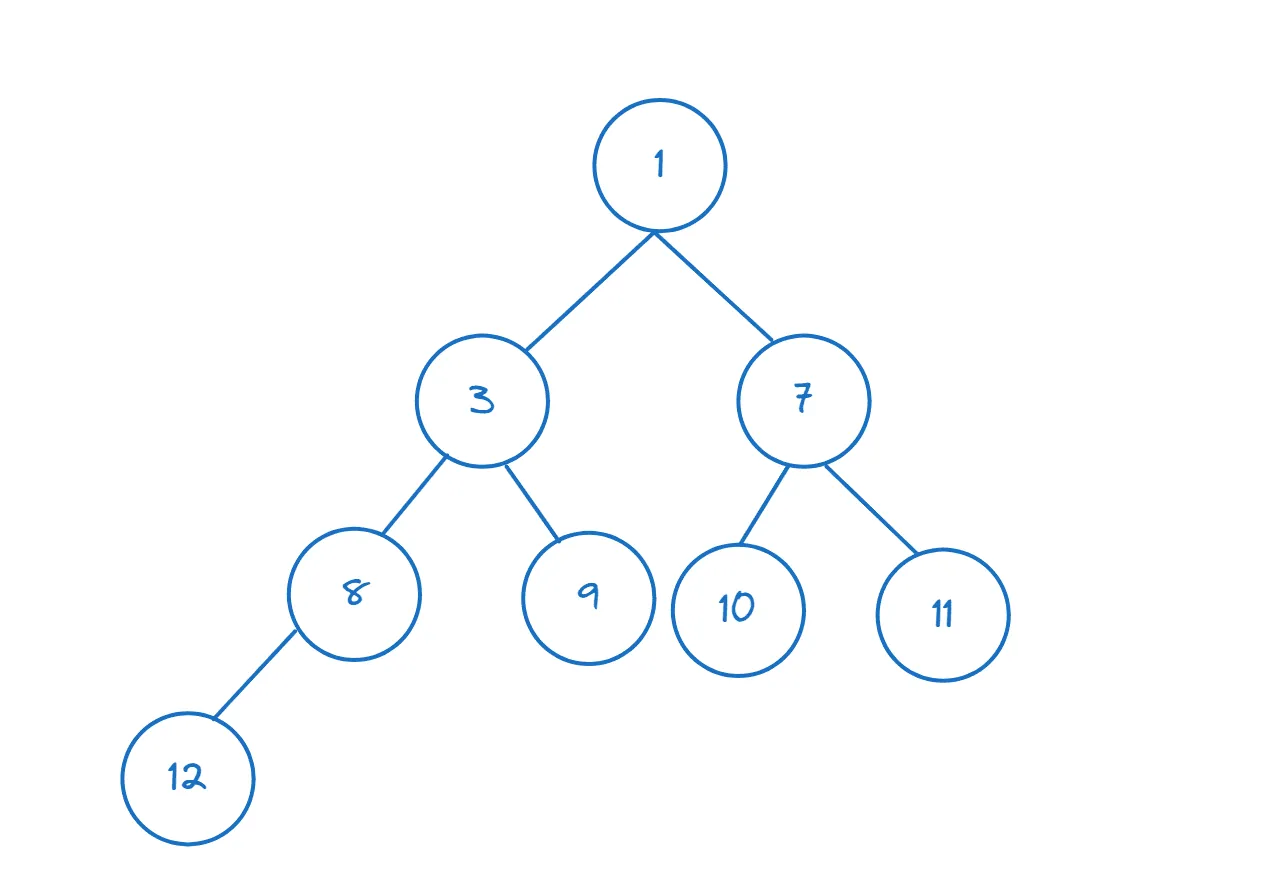
Ponieważ 1 jest mniejsze niż 3, `nums[0]` teraz zwraca 1, który jest najmniejszym elementem (i węzłem głównym).
>>> nums[0] 1
Elementy ze sterty min-heap usuwamy za pomocą funkcji `heappop()`:
>>> while nums: ... print(heappop(nums)) ...
# Output 1 3 7 8 9 10 11 12
Sterty maksymalne (Max Heap) w Pythonie
Skoro wiemy już, czym są sterty minimalne, możemy z łatwością zaimplementować stertę maksymalną. Aby to zrobić, musimy jedynie pomnożyć każdą liczbę przez -1. W ten sposób, liczby ułożone w kopiec min, stają się równoważne liczbom ułożonym w stercie max.
W Pythonie możemy pomnożyć elementy przez -1 podczas dodawania elementu do sterty za pomocą `heappush()`:
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Węzeł główny – pomnożony przez -1 – będzie maksymalnym elementem.
>>> -1*maxHeap[0] 7
Usuwając elementy ze sterty, korzystamy z `heappop()`, a następnie mnożymy wartość przez -1, aby odzyskać pierwotną wartość:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Kolejki priorytetowe
Na koniec omówimy strukturę danych kolejki priorytetowej w Pythonie.
W standardowej kolejce elementy są usuwane w kolejności, w jakiej zostały dodane. Kolejka priorytetowa, obsługuje elementy według przypisanego im priorytetu. Jest to bardzo przydatne w zastosowaniach takich jak planowanie. W każdej chwili zwracany jest element o najwyższym priorytecie.
Do określenia priorytetu możemy wykorzystać klucze. W naszym przykładzie użyjemy wartości liczbowych dla kluczy.
Implementacja kolejki priorytetowej za pomocą heapq
Poniżej znajduje się implementacja kolejki priorytetowej z wykorzystaniem biblioteki heapq:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
Podczas usuwania elementów, kolejka wybiera najpierw element o najwyższym priorytecie (1, 'read'), następnie (2, 'write'), i na końcu (3, 'code').
# Output (1, 'read') (2, 'write') (3, 'code')
Implementacja kolejki priorytetowej za pomocą PriorityQueue
Do implementacji kolejki priorytetowej można także użyć klasy `PriorityQueue` z modułu `queue`. Wewnętrznie wykorzystuje ona strukturę sterty.
Poniżej znajduje się implementacja kolejki priorytetowej przy pomocy `PriorityQueue`:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'read') (2, 'write') (3, 'code')
Podsumowanie
W tym artykule omówiliśmy różne wbudowane struktury danych w Pythonie, przedstawiając operacje, które można na nich wykonywać oraz metody do tego służące.
Przyjrzeliśmy się także innym strukturom, takim jak stosy, kolejki i kolejki priorytetowe, oraz sposobom ich implementacji w Pythonie przy użyciu funkcjonalności modułu `collections`.
Na zakończenie, zachęcamy do zapoznania się z listą projektów Pythona przyjaznych dla początkujących programistów.
