11 najlepszych platform strumieniowego przesyłania danych do analizy i przetwarzania w czasie rzeczywistym
Współczesny świat działa w oparciu o dane. Uzyskanie dogłębnego i aktualnego wglądu w dane pozwala przedsiębiorstwom zdobyć znaczącą przewagę. Strumieniowanie danych umożliwia ciągłe gromadzenie i przetwarzanie informacji z różnorodnych źródeł, co podkreśla kluczową rolę solidnych platform strumieniowych.
Platformy do strumieniowania danych to systemy o wysokiej skalowalności, rozproszonej architekturze i dużej wydajności, które zapewniają niezawodne przetwarzanie strumieni danych. Umożliwiają agregację i analizę danych, a często oferują zunifikowany panel do wizualizacji.
Dostępny jest szeroki wybór platform i rozwiązań do strumieniowania danych – od w pełni zarządzanych systemów, takich jak Confluent Cloud i Amazon Kinesis, po rozwiązania open source, na przykład Arroyo i Fluvio.
Przykłady zastosowań strumieniowego przesyłania danych
Platformy strumieniowego przesyłania danych znajdują szerokie zastosowanie w różnych dziedzinach. Przyjrzyjmy się kilku z nich:
- Wykrywanie oszustw poprzez ciągłą analizę transakcji, zachowań użytkowników i identyfikowanie wzorców.
- Przechwytywanie danych z giełd papierów wartościowych przez systemy realizujące szybkie transakcje o wysokiej częstotliwości w oparciu o analizę rynkową.
- Dostarczanie spersonalizowanych analiz poprzez dane rynkowe w czasie rzeczywistym, co umożliwia firmom e-commerce kierowanie swoich produktów do odpowiednich grup odbiorców.
- Zastosowanie milionów czujników w różnorodnych systemach, które dostarczają dane w czasie rzeczywistym, umożliwiając prognozowanie informacji, na przykład prognoz pogody.
Poniżej przedstawiono najlepsze platformy do analizy i przetwarzania danych w czasie rzeczywistym, które mogą zaspokoić Twoje potrzeby.
Confluent Cloud

Confluent Cloud, w pełni chmurowa usługa oparta na Apache Kafka, oferuje wysoką odporność, skalowalność i wydajność. Wykorzystuje niestandardowy silnik Kora, zapewniający do dziesięciu razy lepszą wydajność niż w przypadku samodzielnego klastra Kafka. Do jego kluczowych funkcji należą:
- Bezserwerowe klastry, które zapewniają elastyczność i skalowalność. Pozwalają one natychmiast reagować na zmienne potrzeby związane z przesyłaniem strumieniowym danych dzięki automatycznemu skalowaniu na żądanie.
- Obsługa przechowywania danych dzięki nieograniczonej przestrzeni i zapewnieniu integralności danych. Bezproblemowe przechowywanie danych pozwala uczynić Confluent Cloud wiarygodnym źródłem informacji.
- Confluent Cloud gwarantuje dostępność na poziomie 99,99%, co jest jednym z najlepszych wyników w branży. W połączeniu z replikacją w wielu strefach, zapewnia ochronę przed uszkodzeniem lub utratą danych.
Projektant strumieni oferuje interfejs typu „przeciągnij i upuść” do wizualnego tworzenia potoków przetwarzania. Dodatkowo, gotowe złącza Kafka umożliwiają łączenie z dowolną aplikacją lub źródłem danych.
Confluent Cloud oferuje Stream Governance, jedyny w branży, w pełni zarządzany pakiet narzędzi do zarządzania danymi. Zapewnia bezpieczeństwo i zgodność klasy korporacyjnej, pozwalając chronić dane i kontrolować dostęp.
Confluent Cloud oferuje zróżnicowane opcje cenowe, a także bogate zasoby edukacyjne, które ułatwiają rozpoczęcie pracy.
Aiven

Aiven pomaga w realizacji potrzeb związanych ze strumieniowym przesyłaniem danych dzięki w pełni zarządzanej usłudze chmurowej Apache Kafka. Współpracuje ze wszystkimi głównymi dostawcami chmury, takimi jak AWS, Google Cloud, Microsoft Azure, Digital Ocean i UpCloud.
Usługę Kafka można skonfigurować w ciągu kilku minut za pomocą konsoli internetowej lub programowo, korzystając z API i CLI. Dodatkowo, istnieje możliwość uruchomienia jej w kontenerach.
W pełni zarządzana usługa w chmurze eliminuje kłopoty związane z zarządzaniem Kafką. Umożliwia szybką konfigurację potoków danych wraz z panelem monitorowania. Oto korzyści, które oferuje Aiven:
- Automatyczne aktualizacje klastra oraz łatwe zarządzanie wersjami i konserwacją za pomocą kilku kliknięć.
- Aiven gwarantuje 99,99% czasu pracy bez przestojów i z minimalnymi zakłóceniami.
- Skalowalność pamięci masowej na żądanie, możliwość dodawania węzłów Kafka i wdrażania w różnych regionach.
Miesięczne ceny Aiven zaczynają się od 200 USD i różnią się w zależności od lokalizacji i wybranego dostawcy usług chmurowych.
Arroyo
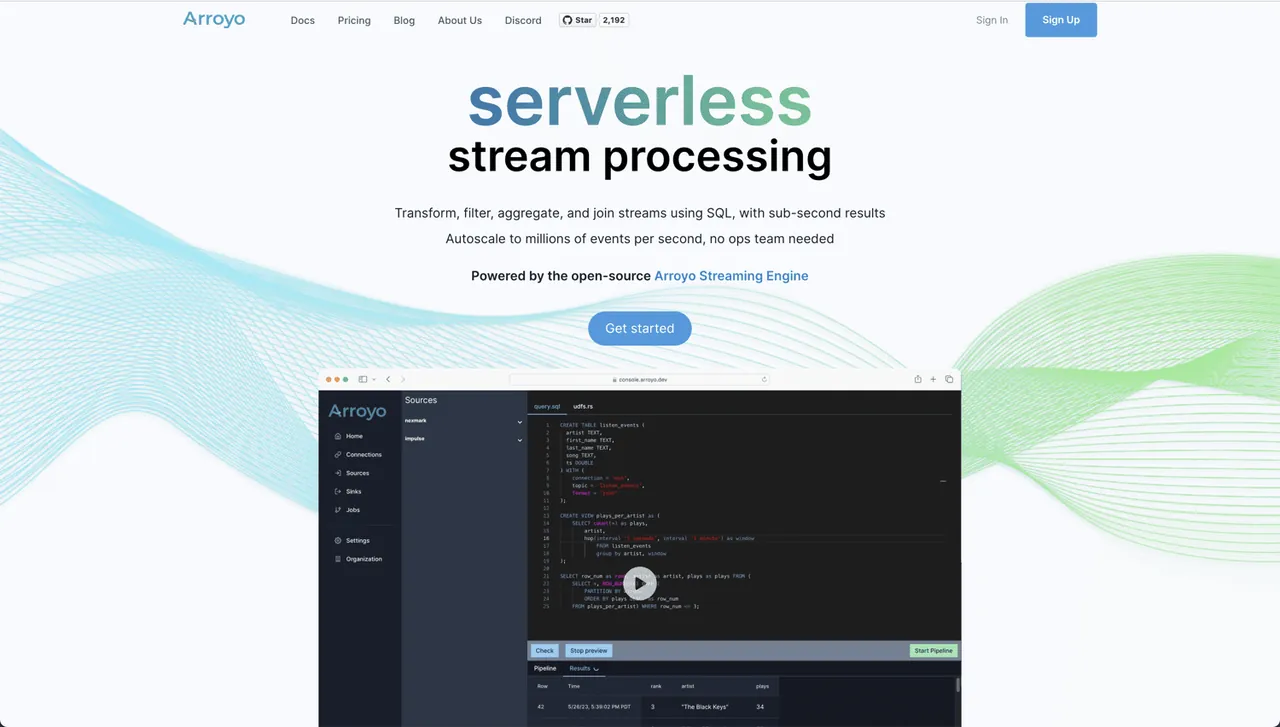
Jeśli poszukujesz prawdziwie chmurowego rozwiązania open source do analizy i przetwarzania danych w czasie rzeczywistym, Arroyo jest doskonałym wyborem. Wykorzystuje silnik Arroyo Streaming Engine – rozproszone rozwiązanie do przetwarzania strumieniowego, które wyróżnia się szybkością w zakresie wyszukiwania danych, zapewniając wyniki w czasie poniżej sekundy.
Arroyo zostało zaprojektowane tak, aby przetwarzanie w czasie rzeczywistym było tak proste, jak przetwarzanie wsadowe. Dzięki swojej intuicyjności, nie musisz być ekspertem, aby tworzyć własne potoki. Oto zalety korzystania z Arroyo:
- Wbudowane wsparcie dla różnych łączników, w tym Kafka, Pulsar, Redpanda, WebSockets i Server Sent Events.
- Możliwość zapisu przetworzonych danych w różnych systemach, takich jak Kafka, Amazon S3 i Postgres.
- Wydajny kompilator, który przetwarza zapytania SQL, aby zapewnić maksymalną wydajność.
- Możliwość skalowania przepływu danych w celu obsługi milionów zdarzeń na sekundę.
Możesz uruchomić samodzielnie hostowaną instancję Arroyo za darmo lub skorzystać z Arroyo Cloud, którego ceny zaczynają się od 200 USD miesięcznie. Warto jednak pamiętać, że Arroyo jest w fazie alfa i może nie posiadać wszystkich funkcji.
Amazon Kinesis

Amazon Kinesis Data Streams umożliwia gromadzenie i przetwarzanie dużych strumieni danych w celu szybkiego i ciągłego pozyskiwania. Charakteryzuje się wysoką skalowalnością, trwałością i niskimi kosztami. Przyjrzyjmy się kluczowym funkcjom, które oferuje:
- Amazon Kinesis działa w chmurze AWS w trybie bezserwerowym i na żądanie. Uruchomienie strumieni danych Kinesis jest możliwe za pomocą kilku kliknięć w konsoli zarządzania AWS.
- Kinesis może działać w maksymalnie trzech strefach dostępności (AZ) i oferuje 365 dni przechowywania danych.
- Strumienie danych Kinesis umożliwiają podłączenie do 20 odbiorców. Każdy z nich posiada dedykowaną przepustowość odczytu i może publikować dane w ciągu 70 milisekund od przetworzenia.
- Bezpieczeństwo danych dzięki szyfrowaniu po stronie serwera.
- Bezproblemowa integracja z innymi usługami AWS, takimi jak Cloudwatch, DynamoDB i AWS Lambda.
Płacisz tylko za rzeczywiste wykorzystanie Amazon Kinesis. Przy założeniu 1000 rekordów na sekundę po 3 KB każdy, dzienny koszt w trybie na żądanie wyniesie około 30,61 USD. Możesz użyć kalkulatora AWS, aby oszacować koszty w zależności od wykorzystania.
Databricks

Jeśli szukasz jednej platformy do przetwarzania wsadowego i strumieniowego, Platforma Databricks Lakehouse będzie doskonałym rozwiązaniem. Zapewnia również analitykę w czasie rzeczywistym, uczenie maszynowe i obsługę aplikacji w jednym miejscu.
Platforma Databricks Lakehouse posiada widok danych Delta Live Tables (DLT) z następującymi korzyściami:
- DLT pozwala na łatwe zdefiniowanie kompleksowego potoku danych.
- Automatyczne testowanie jakości danych i monitorowanie trendów jakości w czasie.
- Ulepszone automatyczne skalowanie DLT w przypadku nieprzewidywalnych obciążeń.
Platforma oferuje najlepsze środowisko do uruchamiania obciążeń Apache Spark, z technologią Spark Structured Streaming jako podstawową. W połączeniu z Delta Lake, jedyną platformą pamięci masowej open source, która obsługuje zarówno strumieniowe, jak i wsadowe przetwarzanie danych.
Databricks Lakehouse oferuje 14-dniowy bezpłatny okres próbny, po którym zostaniesz automatycznie zapisany do bieżącego planu.
Qlik Data Streaming (CDC)
CDC (Change Data Capture) to technologia powiadamiania innych systemów o wszelkich zmianach w danych. Qlik Data Streaming (CDC), proste i wszechstronne rozwiązanie, pozwala na łatwe przenoszenie danych ze źródła do miejsca docelowego w czasie rzeczywistym. Zarządzanie odbywa się za pomocą prostego interfejsu graficznego.
Qlik Data Streaming (CDC) zapewnia uproszczoną i zautomatyzowaną konfigurację, umożliwiając łatwe ustawianie, kontrolowanie i monitorowanie potoku danych w czasie rzeczywistym.
Platforma wspiera szeroką gamę źródeł, celów i platform, umożliwiając nie tylko pozyskiwanie różnorodnych danych, ale także synchronizację danych lokalnych, w chmurze i hybrydowych.
Qlik Enterprise Manager pełni rolę centralnego centrum dowodzenia, umożliwiając łatwe skalowanie i monitorowanie przepływu danych za pomocą alertów.
Istnieje elastyczna opcja wdrażania przy wyborze sposobu uruchomienia potoku CDC. W zależności od potrzeb możesz wybrać jedną z następujących opcji:
Możesz rozpocząć korzystanie z bezpłatnego okresu próbnego bez konieczności pobierania lub instalowania czegokolwiek.
Fluvio

Szukasz natywnego rozwiązania open source do przesyłania strumieniowego, które oferuje niskie opóźnienia i wysoką wydajność? Fluvio spełnia te kryteria. Umożliwia wykonywanie obliczeń inline za pomocą SmartModules, które zwiększają funkcjonalność platformy.
Fluvio oferuje rozproszone przetwarzanie strumieni z kontrolami, które zapobiegają utracie danych i przestojom. Dodatkowo, dostępne jest natywne wsparcie API dla popularnych języków programowania, takich jak Rust, Node.js, Python, Java i Go. Oto, co oferuje platforma:
- Możliwość łączenia obliczeń i przesyłania strumieniowego w ujednoliconym klastrze, co minimalizuje opóźnienia.
- Fluvio dynamicznie ładuje niestandardowe moduły, które rozszerzają możliwości obliczeniowe.
- Wysoka skalowalność, od małych urządzeń IoT po systemy wielordzeniowe.
- Możliwości automatycznego naprawiania przy użyciu zarządzania deklaratywnego, uzgadniania i replikacji.
- Potężny interfejs CLI stworzony z myślą o programistach, który zapewnia wysoką wydajność.
Fluvio można zainstalować na dowolnej platformie, niezależnie od tego, czy jest to laptop, firmowe centrum danych, czy wybrana chmura publiczna.
Jako rozwiązanie open source, korzystanie z Fluvio jest bezpłatne.
Cloudera Stream Processing (CSP)

Cloudera Stream Processing (CSP), oparty na Apache Flink i Apache Kafka, umożliwia analizę danych przesyłanych strumieniowo w celu uzyskania cennych wniosków. Zapewnia natywne wsparcie dla standardowych technologii, takich jak SQL i REST. Ponadto, oferuje kompletne rozwiązanie do zarządzania strumieniem, wraz z przetwarzaniem stanowym, przeznaczone dla przedsiębiorstw.
Cloudera Stream Processing odczytuje i analizuje duże ilości danych w czasie rzeczywistym, zapewniając wyniki z opóźnieniem poniżej sekundy. Oferuje wsparcie dla chmury wielochmurowej i hybrydowej wraz z narzędziami niezbędnymi do tworzenia zaawansowanych analiz opartych na danych. Do kluczowych funkcji i narzędzi należą:
- Obsługa milionów wiadomości na sekundę, pozwalająca sprostać zmiennym potrzebom dzięki wysoce skalowalnemu przesyłaniu strumieniowemu.
- Streams Messaging Manager oferuje kompleksowy wgląd w przepływ danych w potoku przetwarzania danych.
- Streams Replication Manager zapewnia replikację, dostępność i odzyskiwanie po awarii.
- Schema Registry pomaga uniknąć problemów z niedopasowaniem schematów i przerw w działaniu, umożliwiając zarządzanie wszystkim we wspólnym repozytorium.
- Cloudera SDX, automatycznie egzekwowane scentralizowane zabezpieczenia, oferuje jednolitą kontrolę i nadzór nad wszystkimi komponentami.
Dzięki Cloudera Stream Processing w mniej niż 10 minut możesz przyspieszyć potok przetwarzania strumieniowego na wybranej platformie chmurowej, takiej jak AWS, Azure czy Google Cloud Platform.
Striim Cloud
Czy twoja platforma danych i analiza w czasie rzeczywistym wymagają obsługi szerokiej gamy producentów i odbiorców danych? Striim Cloud, z wbudowaną obsługą ponad 100 łączników, może być idealnym wyborem. Z łatwością integruje się z istniejącymi magazynami danych i przesyła dane strumieniowo w czasie rzeczywistym za pomocą w pełni zarządzanej platformy SaaS zaprojektowanej dla chmury.
Striim Cloud oferuje prosty interfejs typu „przeciągnij i upuść”, który ułatwia tworzenie potoku i zapewnia wgląd w dane. Współpracuje z popularnymi narzędziami analitycznymi, w tym Google BigQuery, Snowflake, Azure Synapse i Databricks. Dodatkowo, oferuje:
- Możliwości ewolucji schematów Striim, które pomagają w zarządzaniu zmianami struktury danych. Możesz skonfigurować je do automatycznego rozwiązania lub ręcznej interwencji.
- Striim, zbudowany na rozproszonej platformie strumieniowego SQL, umożliwia uruchamianie ciągłych zapytań.
- Wysoka skalowalność i przepustowość. Skalowanie potoku bez dodatkowych kosztów i planowania.
- Metoda „ReadOnlyWriteMany”, która umożliwia dodawanie i usuwanie nowych celów bez wpływu na istniejące magazyny danych.
Płacisz tylko za rzeczywiste wykorzystanie zasobów. Striim oferuje bezpłatne środowisko programistyczne, które pozwala wypróbować platformę z 10 milionami zdarzeń miesięcznie. Ceny rozwiązania chmurowego dla przedsiębiorstw zaczynają się od 2500 USD miesięcznie.
Platforma danych strumieniowych VK

Vertical Knowledge (VK) pomaga osobom fizycznym i firmom w podejmowaniu ważnych decyzji w dużej skali, dzięki wysokim standardom produktów i wglądowi w dane. Platforma danych strumieniowych VK umożliwia przetwarzanie ogromnych ilości danych za pośrednictwem internetowego środowiska przesyłania strumieniowego.
Zyskaj przydatne informacje dzięki zautomatyzowanemu wykrywaniu danych. Oto główne zalety platformy VK:
- Solidne bezpieczeństwo cybernetyczne dzięki stabilnej infrastrukturze VK, chroniącej przed szkodliwymi treściami. Możliwość pobierania danych za pośrednictwem środowiska wirtualnego.
- Zautomatyzowane strumienie danych, które ułatwiają obsługę wielu źródeł danych.
- Szybkie wykrywanie danych, które ogranicza czasochłonne procesy manualne.
- Generowanie dużych zbiorów danych poprzez uruchamianie współbieżnych potoków z wielu źródeł, co umożliwia uzyskanie wyników globalnych dla wybranych słów kluczowych.
- Możliwość eksportowania zbiorów danych w surowym formacie JSON lub CSV lub wykorzystanie API do integracji z systemami zewnętrznymi.
Platforma HStream
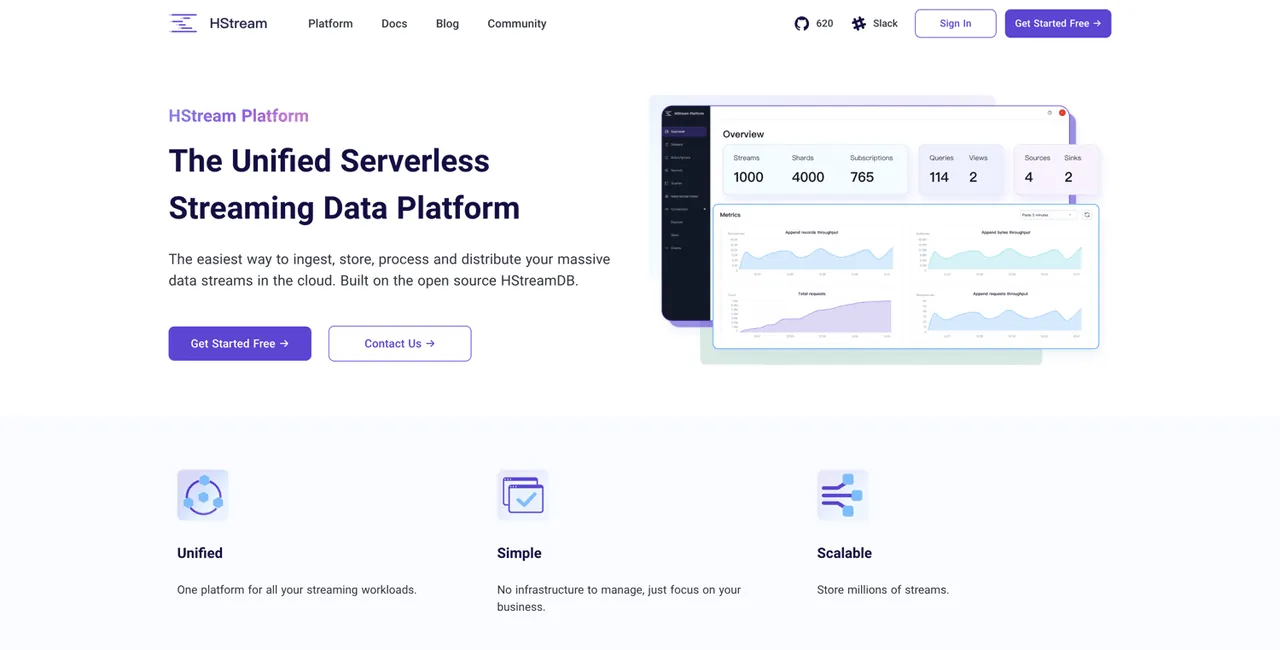
Platforma HStream, oparta na HStreamDB open source, oferuje bezserwerową platformę strumieniowego przesyłania danych. Umożliwia przetwarzanie ogromnych ilości danych i niezawodne przechowywanie milionów strumieni danych. HStreamDB jest tak szybki jak Kafka. Dodatkowo, umożliwia odtwarzanie danych historycznych.
Za pomocą języka SQL można filtrować, przekształcać, agregować i łączyć wiele widoków danych. Pozwala to uzyskać wgląd w dane w czasie rzeczywistym. Platforma HStream jest oszczędna i umożliwia rozpoczęcie pracy od małej skali. Oto jej główne cechy:
- Bezserwerowa architektura, gotowa do użycia od samego początku.
- Brak konieczności korzystania z Kafki.
- Przetwarzanie strumieniowe w miejscu za pomocą standardowego języka SQL.
- Możliwość tworzenia i korzystania w różnych systemach, takich jak bazy danych, hurtownie danych i jeziora danych. Eliminacja konieczności stosowania dodatkowych narzędzi ETL.
- Efektywne zarządzanie wszystkimi obciążeniami na jednej ujednoliconej platformie do przesyłania strumieniowego.
- Architektura natywna dla chmury, umożliwiająca niezależne skalowanie potrzeb w zakresie przetwarzania i przechowywania.
Platforma HStream jest obecnie w fazie publicznej wersji beta. Możesz z niej korzystać bezpłatnie po zarejestrowaniu się.
Podsumowanie
Wybór odpowiedniej platformy do strumieniowego przesyłania danych zależy od wielu czynników, takich jak skala, potrzeby dotyczące różnorodnych połączeń, czas działania i niezawodność.
Niektóre platformy są w pełni zarządzanymi usługami, a inne są open source i zapewniają większe możliwości dostosowania. Zastanów się nad swoimi potrzebami i budżetem, aby wybrać rozwiązanie, które najlepiej odpowiada Twoim wymaganiom.
Na koniec, jeśli nadal zastanawiasz się, jak najlepiej wykorzystać wszystkie zgromadzone dane, warto wypróbować narzędzia do prognozowania oparte na sztucznej inteligencji.
