Llama 2 to zaawansowany model językowy (LLM), udostępniony na licencji otwartego oprogramowania przez firmę Meta. Ten potężny model, charakteryzujący się otwartym kodem źródłowym, prezentuje zdolności konwersacyjne, które mogą przewyższać niektóre zamknięte modele językowe, takie jak GPT-3.5 i PaLM 2. Llama 2 występuje w trzech wariantach, różniących się wielkością – 7, 13 i 70 miliardów parametrów, co pozwala dostosować jego moc obliczeniową do konkretnych zadań.
W dalszej części artykułu dowiesz się, jak wykorzystać potencjał konwersacyjny Llama 2, tworząc interaktywnego chatbota za pomocą platformy Streamlit.
Zrozumienie możliwości i korzyści Llama 2
Czym Llama 2 różni się od swojego poprzednika, czyli modelu Llama 1?
- Zwiększona pojemność modelu: Llama 2 jest znacznie większa, osiągając do 70 miliardów parametrów. Taka skala pozwala na naukę bardziej złożonych zależności pomiędzy słowami i konstrukcjami zdaniowymi.
- Udoskonalone zdolności konwersacyjne: Dzięki zastosowaniu uczenia ze wzmocnieniem opartego na opiniach ludzi (RLHF), model znacznie lepiej radzi sobie w interakcjach konwersacyjnych. Potrafi generować wypowiedzi brzmiące naturalnie, nawet w przypadku bardziej złożonych dialogów.
- Szybsze wnioskowanie: Llama 2 implementuje nowatorską metodę uwagi grupowej, która przyspiesza proces wnioskowania. To zwiększa przydatność modelu w aplikacjach takich jak chatboty czy wirtualni asystenci, gdzie szybkość reakcji ma kluczowe znaczenie.
- Większa wydajność: Model Llama 2 charakteryzuje się większą efektywnością pod względem zapotrzebowania na pamięć i zasoby obliczeniowe w porównaniu do swojej poprzedniej wersji.
- Licencja open source i niekomercyjna: Llama 2 jest dostępna jako oprogramowanie open source, co oznacza, że naukowcy i programiści mogą korzystać z niego i modyfikować je bez ograniczeń, pod warunkiem, że ich zastosowania nie mają charakteru komercyjnego.
Llama 2, pod każdym względem, stanowi znaczący krok naprzód w porównaniu do swojej poprzedniczki. Te ulepszenia sprawiają, że jest to potężne narzędzie do szerokiego zakresu zastosowań, takich jak inteligentne chatboty, wirtualni asystenci czy zaawansowane systemy rozumienia języka naturalnego.
Konfiguracja środowiska Streamlit do tworzenia chatbotów
Aby rozpocząć budowę chatbota, niezbędne jest skonfigurowanie własnego środowiska programistycznego. Dzięki temu odseparujesz projekt od innych działających na twoim komputerze.
Zacznij od utworzenia środowiska wirtualnego przy pomocy biblioteki Pipenv, używając komendy:
pipenv shell
Następnie, zainstaluj niezbędne biblioteki, które umożliwią budowę twojego chatbota:
pipenv install streamlit replicate
Streamlit: To otwarta platforma do tworzenia aplikacji internetowych, która pozwala na szybkie budowanie interfejsów dla modeli uczenia maszynowego i analizy danych.
Replicate: To platforma chmurowa oferująca dostęp do zaawansowanych modeli uczenia maszynowego o otwartym kodzie źródłowym, co pozwala na ich łatwe wdrożenie.
Uzyskanie tokena API Llama 2 z platformy Replicate
Aby wygenerować klucz tokena API, należy założyć konto na Replicate, korzystając z konta GitHub.
Po zalogowaniu przejdź do sekcji „Explore” i wyszukaj „Llama 2 Chat”. Powinien pojawić się model czatu „llama-2–70b”.
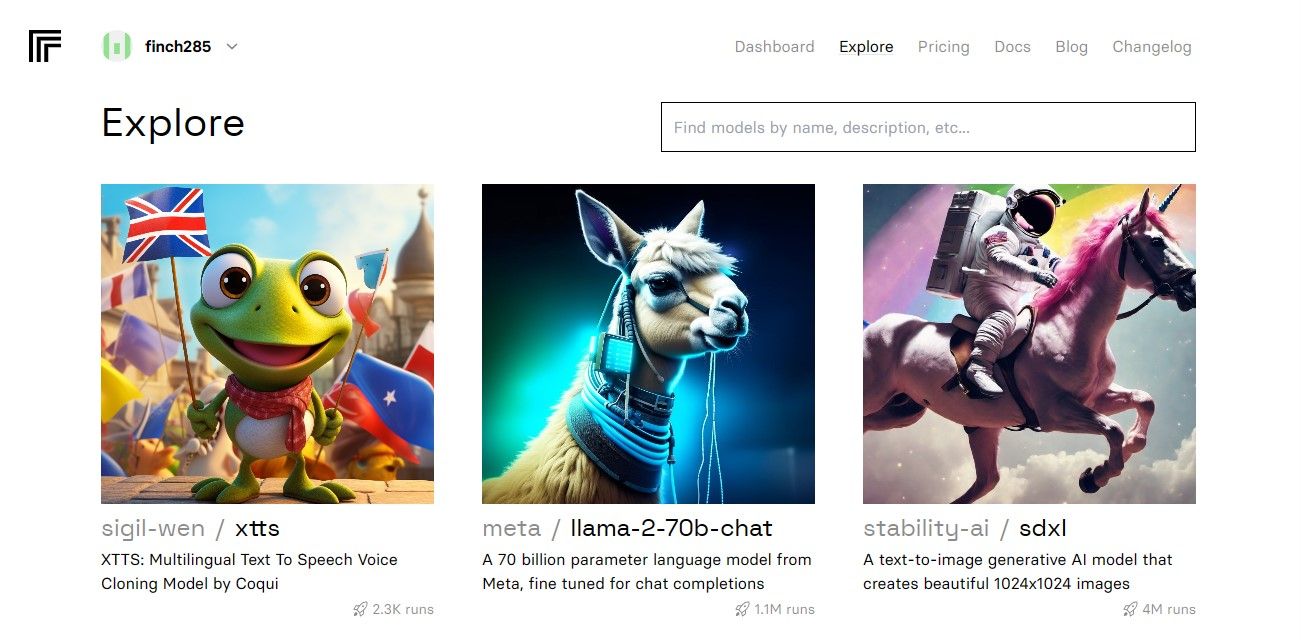
Kliknij model „llama-2–70b-chat”, aby przejść do punktów końcowych interfejsu API Llama 2. Na pasku nawigacyjnym modelu wybierz przycisk „API”. W panelu po prawej stronie wybierz przycisk „Python”. Zostanie wygenerowany token API dla aplikacji Python.
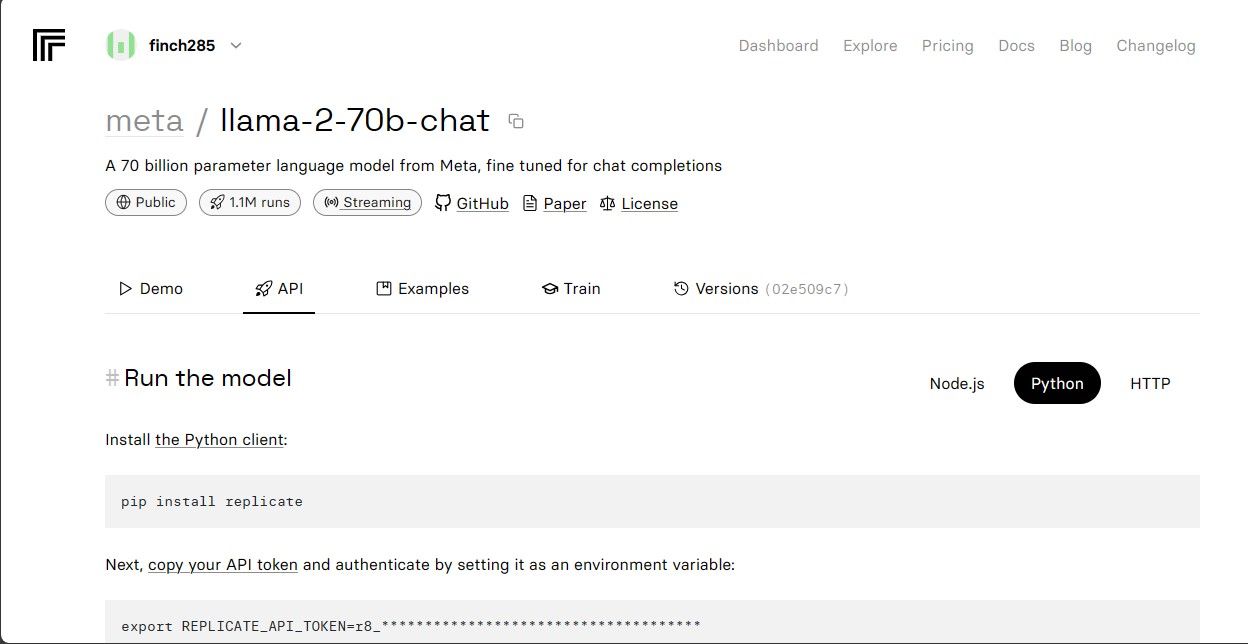
Skopiuj wartość „REPLICATE_API_TOKEN” i przechowuj ją w bezpiecznym miejscu, ponieważ będzie potrzebna w dalszej części projektu.
Tworzenie Chatbota
Na początku utwórz plik o nazwie „llama_chatbot.py” oraz plik środowiska „.env”. Kod aplikacji będziesz umieszczać w pliku „llama_chatbot.py”, natomiast tajne klucze i tokeny API – w pliku „.env”.
W pliku „llama_chatbot.py” zaimportuj niezbędne biblioteki w następujący sposób:
import streamlit as st
import os
import replicate
Następnie ustaw globalne zmienne dla modelu „llama-2–70b-chat”:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
W pliku „.env” dodaj token Replicate oraz punkty końcowe modeli w poniższym formacie:
REPLICATE_API_TOKEN='Twój_Token_Replicate'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Wklej swój token Replicate i zapisz plik „.env”.
Projektowanie schematu rozmów w chatbocie
Zdefiniuj wstępny prompt (instrukcję), który będzie inicjował model Llama 2, informując go, jakie zadanie ma wykonywać. W tym przypadku chcemy, aby model działał jako pomocny asystent.
PRE_PROMPT = "Jesteś pomocnym asystentem. Nie odpowiadaj jako 'Użytkownik' ani nie udawaj 'Użytkownika'. Odpowiadaj tylko raz jako Asystent."
Skonfiguruj ustawienia strony dla swojego chatbota:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Stwórz funkcję, która inicjalizuje i konfiguruje zmienne stanu sesji.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Wybierz model LLaMA2:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Ta funkcja ustawia podstawowe zmienne, takie jak: historię rozmów („chat_dialogue”), wstępny prompt („pre_prompt”), punkt końcowy modelu („llm”), parametr „top_p”, maksymalną długość sekwencji („max_seq_len”) i temperaturę („temperature”) w stanie sesji. Dodatkowo umożliwia wybór modelu Llama 2 w zależności od preferencji użytkownika.
Zdefiniuj funkcję, która renderuje zawartość paska bocznego aplikacji Streamlit:
def render_sidebar():
st.sidebar.header("Chatbot LLaMA2")
st.session_state['temperature'] = st.sidebar.slider('Temperatura:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Maksymalna długość sekwencji:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt przed rozpoczęciem rozmowy. Zmień go jeśli chcesz:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Ta funkcja wyświetla nagłówek oraz elementy sterujące dla parametrów chatbota Llama 2, umożliwiając użytkownikowi dostosowanie jego zachowania.
Zdefiniuj funkcję, która wyświetla historię czatów w głównym obszarze aplikacji Streamlit:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Ta funkcja iteruje po zapisanej w stanie sesji historii rozmów („chat_dialogue”), wyświetlając każdą wiadomość z odpowiednią etykietą roli (użytkownik lub asystent).
Obsłuż dane wprowadzone przez użytkownika za pomocą poniższej funkcji:
def handle_user_input():
user_input = st.chat_input(
"Wpisz tutaj swoje pytanie do LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Ta funkcja udostępnia użytkownikowi pole tekstowe, w którym może on wprowadzać wiadomości i pytania. Wysłana przez użytkownika wiadomość jest dodawana do historii rozmów („chat_dialogue”) z rolą „user”.
Napisz funkcję, która generuje odpowiedzi z modelu Llama 2 i wyświetla je w obszarze czatu:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Ta funkcja tworzy tekstową historię konwersacji, uwzględniając wiadomości zarówno użytkownika, jak i asystenta, a następnie wywołuje funkcję „debounce_replicate_run” w celu uzyskania odpowiedzi od modelu. Odpowiedź jest na bieżąco modyfikowana w interfejsie, zapewniając interakcję w czasie rzeczywistym.
Napisz główną funkcję, która będzie odpowiedzialna za renderowanie całej aplikacji Streamlit:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Ta funkcja wywołuje wszystkie wcześniej zdefiniowane funkcje w logicznej kolejności, aby ustawić stan sesji, wyrenderować pasek boczny, historię czatów, obsłużyć dane wprowadzane przez użytkownika oraz wygenerować odpowiedzi asystenta.
Zdefiniuj funkcję, która wywoła funkcję „render_app” i uruchomi aplikację po wykonaniu skryptu:
def main():
render_app()if __name__ == "__main__":
main()
Od tego momentu aplikacja powinna być gotowa do uruchomienia.
Obsługa zapytań do API
Utwórz plik „utils.py” w katalogu projektu i umieść w nim poniższą funkcję:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Czas ostatniego wywołania: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Odrzucanie zapytania")
return "Witaj! Twoje zapytania są zbyt częste. Poczekaj kilka" \ " sekund przed wysłaniem kolejnego zapytania."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Ta funkcja implementuje mechanizm „odrzucania” zapytań, aby zapobiec zbyt częstym i nadmiernym wywołaniom API w odpowiedzi na zapytania użytkownika.
Następnie zaimportuj funkcję „debounce_replicate_run” do pliku „llama_chatbot.py” w następujący sposób:
from utils import debounce_replicate_run
Teraz uruchom aplikację:
streamlit run llama_chatbot.py
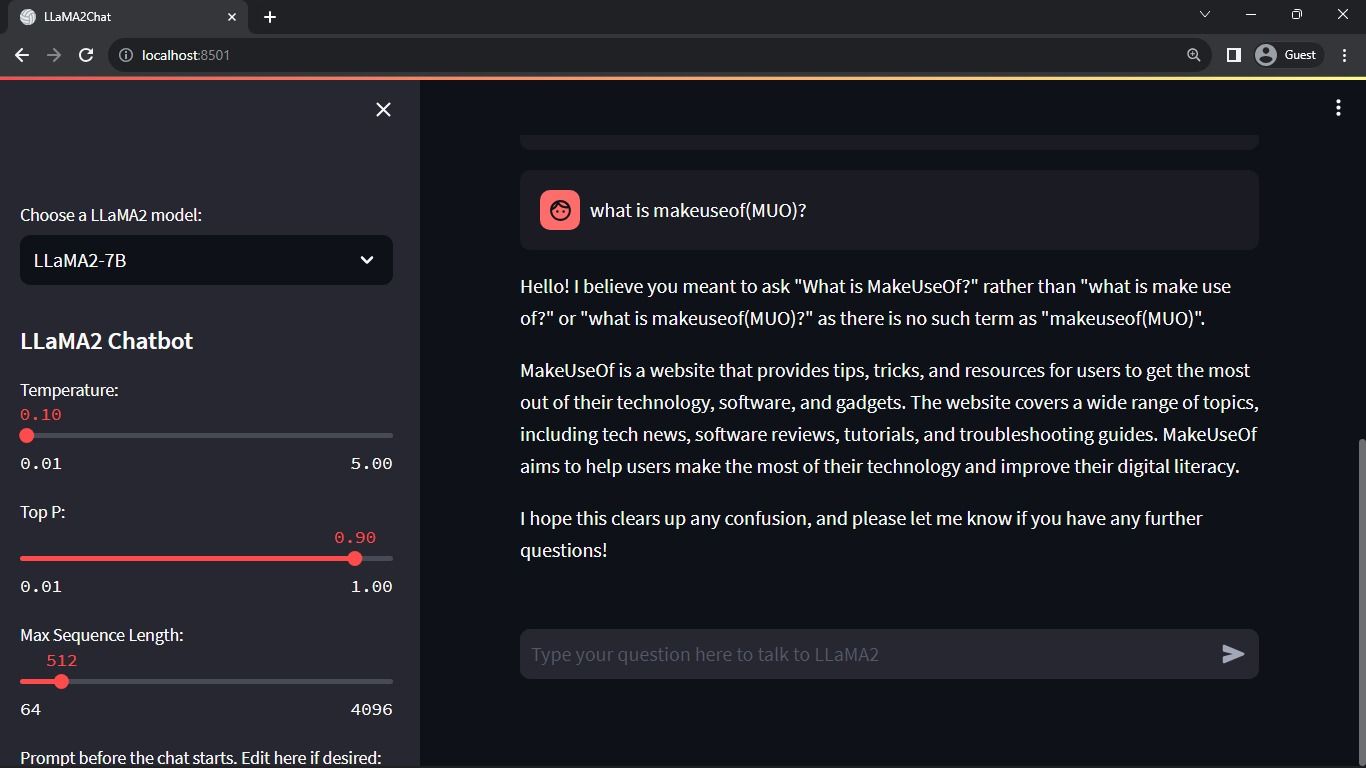
Oczekiwany rezultat:
Wynikiem działania aplikacji jest interaktywna rozmowa pomiędzy użytkownikiem a modelem językowym.
Praktyczne zastosowania chatbotów Streamlit i Llama 2
Oto kilka przykładów rzeczywistych zastosowań modelu Llama 2:
- Chatboty: Tworzenie interaktywnych chatbotów zdolnych do prowadzenia konwersacji w czasie rzeczywistym na różnorodne tematy.
- Wirtualni asystenci: Konstruowanie wirtualnych asystentów, którzy potrafią rozumieć i odpowiadać na zapytania formułowane w języku naturalnym.
- Tłumaczenie językowe: Wykorzystanie modelu w zadaniach związanych z automatycznym tłumaczeniem pomiędzy różnymi językami.
- Streszczanie tekstu: Zastosowanie do tworzenia zwięzłych podsumowań dłuższych tekstów, ułatwiających ich zrozumienie.
- Badania: Wykorzystanie Llama 2 w celach badawczych, w tym do odpowiadania na pytania z różnych dziedzin nauki.
Przyszłość sztucznej inteligencji
W przypadku modeli zamkniętych, takich jak GPT-3.5 i GPT-4, mniejszym firmom i indywidualnym deweloperom trudno jest tworzyć zaawansowane rozwiązania z wykorzystaniem LLM, gdyż dostęp do API modeli GPT wiąże się z wysokimi kosztami.
Udostępnienie zaawansowanych modeli językowych, takich jak Llama 2, społeczności programistów jest zwiastunem nowej ery sztucznej inteligencji. Umożliwi to bardziej kreatywne i innowacyjne wdrażanie modeli w praktycznych zastosowaniach, co może przyspieszyć wyścig w kierunku osiągnięcia sztucznej superinteligencji (ASI).
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.