Część II – Rodzaje technik wektoryzacji
W niniejszym opracowaniu zgłębimy tajniki wektoryzacji – kluczowej techniki w dziedzinie przetwarzania języka naturalnego (NLP). Dokładnie przeanalizujemy jej znaczenie, korzystając z kompleksowego przewodnika omawiającego różnorodne metody wektoryzacji.
Wcześniej zapoznaliśmy się z elementarnymi zasadami wstępnego przetwarzania danych w NLP, w tym z technikami czyszczenia tekstu. Skupiliśmy się na podstawach NLP, jego rozmaitych zastosowaniach oraz metodach takich jak tokenizacja, normalizacja, standaryzacja i oczyszczanie treści.

Zanim przejdziemy do omówienia wektoryzacji, przypomnijmy sobie, na czym polega tokenizacja i czym różni się ona od wektoryzacji.
Czym jest tokenizacja?
Tokenizacja to proces rozkładania zdań na mniejsze elementy, które nazywamy tokenami. Tokeny pomagają komputerom w zrozumieniu tekstu i pracy z nim w sposób bardziej efektywny.
Przykład: „Ten artykuł jest bardzo interesujący”
Tokeny: [„Ten”, „artykuł”, „jest”, „bardzo”, „interesujący”]
Czym jest wektoryzacja?
Jak wiadomo, modele uczenia maszynowego operują na danych liczbowych. Wektoryzacja to proces, w którym dane tekstowe lub kategoryczne przekształcane są w wektory numeryczne. Dzięki konwersji danych do postaci numerycznej możemy precyzyjniej trenować modele.
Po co nam wektoryzacja?
❇️ Tokenizacja i wektoryzacja pełnią odmienne role w przetwarzaniu języka naturalnego. Tokenizacja dzieli tekst na mniejsze tokeny, natomiast wektoryzacja przekształca te tokeny w formę zrozumiałą dla modeli komputerowych.
❇️ Wektoryzacja jest przydatna nie tylko do konwersji danych na postać numeryczną, ale również do uchwycenia ich znaczenia semantycznego.
❇️ Wektoryzacja może redukować wymiarowość danych i poprawiać wydajność. Jest to szczególnie istotne przy pracy z dużymi zbiorami danych.
❇️ Wiele algorytmów uczenia maszynowego, w tym sieci neuronowe, wymaga danych wejściowych w postaci numerycznej, co czyni wektoryzację niezbędną.
Istnieje wiele technik wektoryzacji, które zostaną szczegółowo omówione w tym artykule.
Model worka słów
W przypadku analizy wielu dokumentów lub zdań, model worka słów upraszcza proces, traktując każdy dokument jako zbiór słów.
Podejście to jest przydatne w klasyfikacji tekstu, analizie sentymentu oraz wyszukiwaniu dokumentów.
Załóżmy, że analizujemy dużą ilość tekstu. Model worka słów pomoże nam przedstawić dane tekstowe, tworząc słownik unikalnych słów. Następnie każde słowo jest kodowane jako wektor w zależności od częstotliwości jego występowania w tekście.
Wektory te składają się z liczb nieujemnych (0, 1, 2...), które reprezentują liczbę wystąpień danego słowa w dokumencie.
Model worka słów składa się z trzech kroków:
Krok 1: Tokenizacja
Podział dokumentów na tokeny.
Przykład: (Zdanie: „Uwielbiam pizzę i lubię burgery”)
Krok 2: Tworzenie słownika unikalnych słów
Utworzenie listy wszystkich unikalnych słów występujących w zdaniach.
[„Ja”, „uwielbiam”, „pizzę”, „i”, „burgery”]
Krok 3: Liczenie wystąpień słów / tworzenie wektorów
W tym etapie zliczamy, ile razy każde słowo ze słownika wystąpiło w danym zdaniu, i zapisujemy te wartości w rzadkiej macierzy. Każdy wiersz macierzy reprezentuje wektor zdania, a długość wektora (liczba kolumn) odpowiada wielkości słownika.
Import biblioteki CountVectorizer
Użyjemy biblioteki CountVectorizer, aby wytrenować model worka słów.
from sklearn.feature_extraction.text import CountVectorizer
Utworzenie wektoryzatora
W tym kroku utworzymy model za pomocą CountVectorizer i przeszkolimy go na przykładowych dokumentach tekstowych.
# Przykładowe dokumenty tekstowe
documents = [
"To jest pierwszy dokument.",
"Ten dokument to drugi dokument.",
"A to jest trzeci.",
"Czy to jest pierwszy dokument?",
]
# Utworzenie CountVectorizer
cv = CountVectorizer()
# Dopasowanie i transformacja X = cv.fit_transform(documents)
Konwersja na gęstą tablicę
Przekształcamy reprezentacje w gęstą tablicę, a także uzyskujemy nazwy funkcji czyli słowa.
# Pobranie nazw cech (słów) feature_names = vectorizer.get_feature_names_out() # Konwersja na gęstą tablicę X_dense = X.toarray()
Wyświetlenie matrycy dokument-termin i nazw cech
# Wyświetlenie DTM i nazw cech
print("Macierz Dokument-Termin (DTM):")
print(X_dense)
print("\nNazwy cech:")
print(feature_names)
Macierz Dokument-Termin (DTM):

Nazwy cech:

Jak widać, wektory składają się z liczb nieujemnych, które odzwierciedlają częstotliwość występowania słów w danym dokumencie.
Mamy cztery przykładowe dokumenty tekstowe, w których zidentyfikowaliśmy dziewięć unikalnych słów. Słowa te zostały zapisane w słowniku i przypisano im „nazwy cech”.
Następnie model worka słów analizuje, czy pierwsze unikalne słowo występuje w pierwszym dokumencie. Jeśli występuje, przypisuje wartość 1, w przeciwnym razie 0.
Jeśli słowo pojawia się wielokrotnie (np. 2 razy), model przypisuje odpowiednią wartość.
Na przykład w drugim dokumencie słowo „dokument” powtarza się dwukrotnie, więc jego wartość w macierzy wynosi 2.
Jeśli chcemy, aby pojedyncze słowo było cechą kluczową słownika, mówimy o reprezentacji Unigram.
n-gramy = Unigramy, bigramy itd.
Istnieje wiele bibliotek, np. scikit-learn, które umożliwiają implementację worka słów. Jest to prosty i użyteczny model do różnych zastosowań.
Niemniej jednak model worka słów ma pewne ograniczenia:
- Przypisuje każdemu słowu taką samą wagę, niezależnie od jego znaczenia. Niektóre słowa mogą być ważniejsze niż inne.
- Model ten liczy tylko częstotliwość występowania słowa, co może prowadzić do preferowania popularnych słów, które nie mają dużego znaczenia.
- Dłuższe dokumenty mogą zawierać więcej słów i tworzyć większe wektory, co utrudnia porównywanie i może prowadzić do powstania rzadkiej macierzy.
Aby rozwiązać te problemy, można zastosować inne podejście, takie jak TF-IDF. Przeanalizujmy je szczegółowo.
TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency), czyli miara częstotliwości terminu – odwrotna częstotliwość dokumentów, to reprezentacja numeryczna, która określa ważność słów w dokumencie.
Dlaczego TF-IDF jest lepsze od modelu worka słów?
Model worka słów traktuje wszystkie słowa jednakowo i skupia się wyłącznie na częstotliwości występowania unikalnych słów. TF-IDF przywiązuje wagę do słów, uwzględniając zarówno ich częstotliwość, jak i rzadkość występowania w zbiorze dokumentów.
Dzięki temu słowa powtarzające się zbyt często nie przesłaniają słów rzadszych, a tym samym bardziej istotnych.
TF: Częstotliwość terminu mierzy, jak ważne jest słowo w pojedynczym zdaniu.
IDF: Odwrotna częstotliwość dokumentów mierzy, jak ważne jest słowo w całym zbiorze dokumentów.
TF = Częstotliwość słowa w dokumencie / Całkowita liczba słów w tym dokumencie
DF = Liczba dokumentów zawierających dane słowo / Całkowita liczba dokumentów
IDF = log(Całkowita liczba dokumentów / Liczba dokumentów zawierających dane słowo)
IDF jest odwrotnością DF, ponieważ im częściej słowo występuje w różnych dokumentach, tym mniejsze ma znaczenie w bieżącym dokumencie.
Końcowy wynik TF-IDF: TF-IDF = TF * IDF
TF-IDF pozwala określić, które słowa są unikalne dla danego dokumentu i mogą wskazywać na jego główny temat.
Na przykład:
Doc1 = „Lubię uczenie maszynowe”
Doc2 = „Lubię newsblog.pl”
Musimy obliczyć macierz TF-IDF dla tych dokumentów.
Najpierw tworzymy słownik unikalnych słów.
Słownik = [„Lubię”, „uczenie”, „maszynowe”, „newsblog.pl”]
Mamy więc cztery słowa. Obliczmy TF i IDF dla każdego z nich.
TF = Częstotliwość słowa w dokumencie / Całkowita liczba słów w tym dokumencie
TF:
- Dla „Lubię”: TF dla Doc1: 1/3 ≈ 0,33 i dla Doc2: 1/3 ≈ 0,33
- Dla „uczenie”: TF dla Doc1: 1/3 ≈ 0,33 i dla Doc2: 0/3 = 0
- Dla „maszynowe”: TF dla Doc1: 1/3 ≈ 0,33 i dla Doc2: 0/3 = 0
- Dla „newsblog.pl”: TF dla Doc1: 0/3 = 0 i dla Doc2: 1/3 ≈ 0,33
Teraz obliczamy IDF.
IDF = log(Całkowita liczba dokumentów / Liczba dokumentów zawierających dane słowo)
IDF:
- Dla „Lubię”: IDF wynosi log(2/2) = 0
- Dla „uczenie”: IDF wynosi log(2/1) = log(2) ≈ 0,69
- Dla „maszynowe”: IDF wynosi log(2/1) = log(2) ≈ 0,69
- Dla „newsblog.pl”: IDF wynosi log(2/1) = log(2) ≈ 0,69
Obliczmy ostateczną wartość TF-IDF:
- Dla „Lubię”: TF-IDF dla Doc1: 0,33 * 0 = 0 i TF-IDF dla Doc2: 0,33 * 0 = 0
- Dla „uczenie”: TF-IDF dla Doc1: 0,33 * 0,69 ≈ 0,23 i TF-IDF dla Doc2: 0 * 0,69 = 0
- Dla „maszynowe”: TF-IDF dla Doc1: 0,33 * 0,69 ≈ 0,23 i TF-IDF dla Doc2: 0 * 0,69 = 0
- Dla „newsblog.pl”: TF-IDF dla Doc1: 0 * 0,69 = 0 i TF-IDF dla Doc2: 0,33 * 0,69 ≈ 0,23
Macierz TF-IDF prezentuje się następująco:
Lubię uczenie maszynowe newsblog.pl Doc1 0.0 0.23 0.23 0.0 Doc2 0.0 0.0 0.0 0.23
Wartości w macierzy TF-IDF informują o ważności każdego terminu w każdym dokumencie. Wysokie wartości wskazują, że termin jest istotny dla danego dokumentu, a niskie wartości sugerują, że jest mniej ważny lub bardzo powszechny.
TF-IDF jest często stosowane w klasyfikacji tekstu, budowie wyszukiwarek, chatbotach i streszczaniu tekstu.
Import TfidfVectorizer
Zaimportujmy TfidfVectorizer z biblioteki sklearn.
from sklearn.feature_extraction.text import TfidfVectorizer
Utworzenie wektoryzatora
Utworzymy nasz model TF-IDF za pomocą TfidfVectorizer.
# Przykładowe dokumenty tekstowe
text = [
"To jest pierwszy dokument.",
"Ten dokument to drugi dokument.",
"A to jest trzeci.",
"Czy to jest pierwszy dokument?",
]
# Utworzenie TfidfVectorizer
cv = TfidfVectorizer()
Utworzenie macierzy TF-IDF
Wytrenujemy model, podając tekst. Następnie przekształcimy reprezentatywną macierz na gęstą tablicę.
# Dopasowanie i transformacja w celu utworzenia macierzy TF-IDF X = cv.fit_transform(text)
# Pobranie nazw cech (słów) feature_names = vectorizer.get_feature_names_out() # Konwersja macierzy TF-IDF na gęstą tablicę X_dense = X.toarray()
Wyświetlenie macierzy TF-IDF i nazw cech
# Wyświetlenie macierzy TF-IDF i nazw cech
print("Macierz TF-IDF:")
print(X_dense)
print("\nNazwy cech:")
print(feature_names)
Macierz TF-IDF:

Nazwy cech:
Jak widać, liczby z ułamkami dziesiętnymi wskazują na ważność słów w konkretnych dokumentach.
Można również łączyć słowa w grupy po 2, 3, 4 itd., używając n-gramów.
Istnieją dodatkowe parametry, które można uwzględnić: min_df, max_feature, sublinear_tf itd.
Do tej pory analizowaliśmy podstawowe techniki oparte na częstotliwościach.
Jednak TF-IDF nie jest w stanie zapewnić znaczenia semantycznego i kontekstowego zrozumienia tekstu.
Przyjrzyjmy się zaawansowanym technikom, które zrewolucjonizowały sposób osadzania słów i są lepsze pod względem znaczenia semantycznego i kontekstowego.
Word2Vec
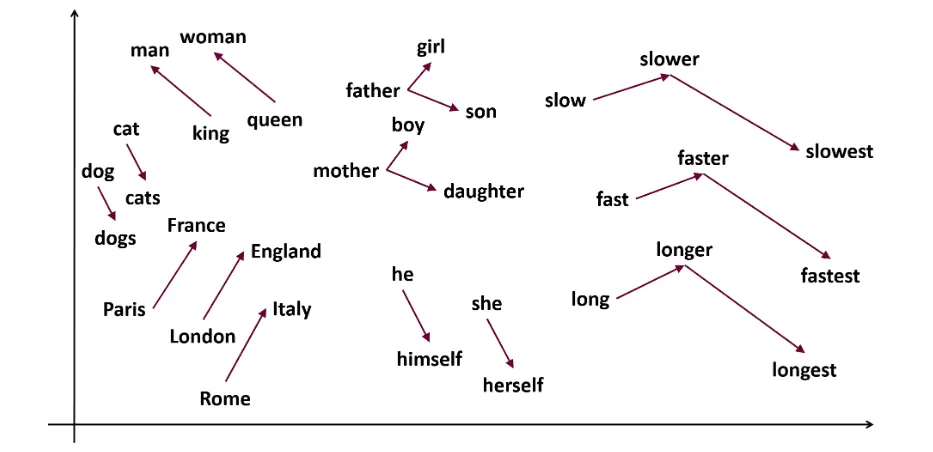
Word2vec to popularna technika osadzania słów, która umożliwia uchwycenie podobieństwa semantycznego i syntaktycznego. Metoda ta została opracowana przez Tomasa Mikolova i jego zespół w Google w 2013 roku. Word2vec reprezentuje słowa jako ciągłe wektory w wielowymiarowej przestrzeni.
Celem Word2vec jest przedstawienie słów w sposób oddający ich znaczenie semantyczne. Wektory słów generowane przez Word2vec są umieszczane w ciągłej przestrzeni wektorowej.
Przykład: Wektory słów „Kot” i „Pies” będą bliżej siebie niż wektory słów „kot” i „dziewczyna”.
Źródło: usna.edu
Word2vec wykorzystuje dwie architektury do osadzania słów:
CBOW (Continuous Bag of Words): CBOW próbuje przewidzieć słowo na podstawie uśrednionego znaczenia słów z jego otoczenia. Pobiera stałą liczbę słów (okno kontekstu) wokół słowa docelowego, a następnie konwertuje je na postać liczbową (osadzanie). Następnie uśrednia wszystkie osadzenia i wykorzystuje tę średnią do przewidzenia słowa docelowego za pomocą sieci neuronowej.
Przykład: Przewidywane słowo: „Lis”
Słowa w zdaniu: „Szybki”, „brązowy”, „lis”, „przeskakuje”, „nad”, „płot”.
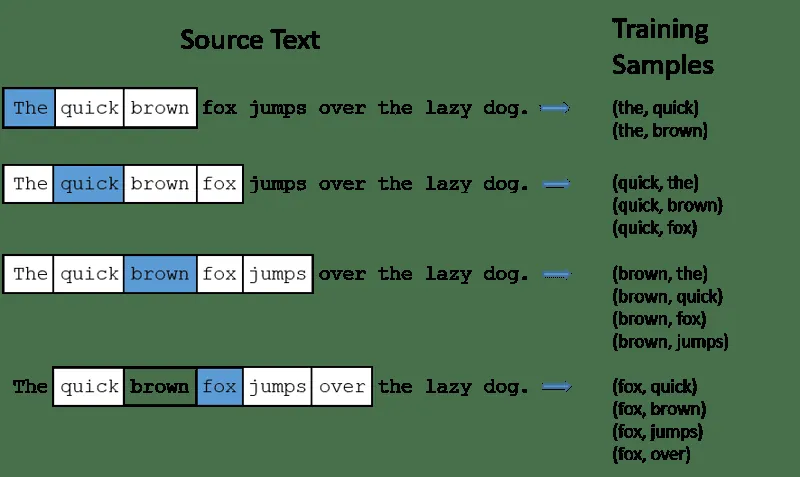
- CBOW przyjmuje okno o stałym rozmiarze, np. 2 (2 słowa z lewej i 2 z prawej).
- Konwertuje słowa na osadzenia.
- Uśrednia osadzenia słów kontekstu.
- Uśredniony wektor jest wykorzystywany do przewidzenia słowa docelowego za pomocą sieci neuronowej.
Teraz zrozumiemy, czym skip-gram różni się od CBOW.
Skip-gram: W odróżnieniu od CBOW, skip-gram przewiduje słowa kontekstu na podstawie zadanego słowa docelowego.
Skip-gramy lepiej oddają relacje semantyczne między słowami.
Przykład: „Król – mężczyzna + kobieta = królowa”
Podczas pracy z Word2Vec można wytrenować własny model lub skorzystać z gotowego. Zapoznamy się z gotowym modelem.
Import biblioteki gensim
Bibliotekę gensim można zainstalować za pomocą pip install:
pip install gensim
Tokenizacja zdań za pomocą word_tokenize:
Najpierw zamienimy zdania na małe litery, a następnie dokonamy tokenizacji za pomocą word_tokenize.
# Import niezbędnych bibliotek
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Przykładowe zdania
sentences = [
"Lubię Thora",
"Hulk jest ważnym członkiem Avengers",
"Ironman pomaga Spidermanowi",
"Spiderman jest jednym z popularnych członków Avengers",
]
# Tokenizacja zdań
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Wytrenowanie modelu:
Wytrenujemy model, podając tokenizowane zdania. W tym przykładzie użyjemy okna o rozmiarze 5. Można dostosować ten parametr do własnych wymagań.
# Wytrenowanie modelu Word2Vec
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Znalezienie podobnych słów
similar_words = model.wv.most_similar("avengers")
# Wyświetlenie podobnych słów
print("Słowa podobne do 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Słowa podobne do "avengers":
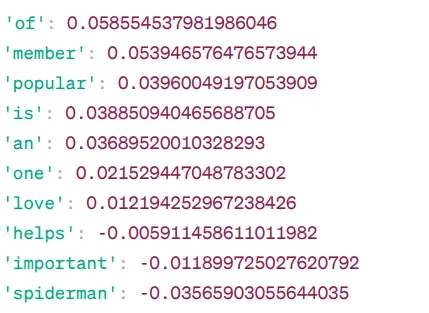
Model oblicza stopień podobieństwa (najczęściej podobieństwo cosinusowe) między wektorem słowa „avengers” a wektorami innych słów ze swojego słownika. Wynik podobieństwa informuje o tym, jak blisko są ze sobą powiązane dwa słowa w przestrzeni wektorowej.
Przykład:
Słowo „pomaga” ma podobieństwo cosinusowe -0.005911458611011982 w stosunku do słowa „avengers”. Wartość ujemna sugeruje, że słowa te mogą się od siebie różnić.
Wartości podobieństwa cosinusowego wahają się od -1 do 1, gdzie:
- 1 oznacza, że oba wektory są identyczne i wykazują dodatnie podobieństwo.
- Wartości bliskie 1 oznaczają duże dodatnie podobieństwo.
- Wartości bliskie 0 oznaczają, że wektory nie są silnie powiązane.
- Wartości bliskie -1 oznaczają dużą odmienność.
- -1 oznacza, że dwa wektory są całkowicie przeciwne i mają doskonałe ujemne podobieństwo.
Aby lepiej zrozumieć działanie modeli Word2Vec, warto odwiedzić tę stronę. To interaktywne narzędzie prezentuje działanie modeli CBOW i skip-gram.
Podobną techniką do Word2Vec jest GloVe. GloVe może tworzyć osadzenia o mniejszym zapotrzebowaniu na pamięć w porównaniu z Word2Vec. Przejdźmy do omówienia GloVe.
GloVe
Globalne wektory dla reprezentacji słów (GloVe) to technika podobna do Word2Vec, która reprezentuje słowa jako wektory w ciągłej przestrzeni. Koncepcja stojąca za GloVe jest taka sama jak w Word2Vec – tworzenie kontekstowych osadzeń słów.
Dlaczego potrzebujemy GloVe?
Word2Vec to metoda oparta na oknie, która do zrozumienia słów wykorzystuje tylko słowa z najbliższego otoczenia. Oznacza to, że na semantyczne znaczenie słowa docelowego wpływają tylko otaczające je słowa w zdaniach, co skutkuje nieefektywnym wykorzystaniem statystyk.
Natomiast GloVe rejestruje zarówno globalne, jak i lokalne statystyki związane z osadzaniem słów.
Kiedy stosować GloVe?
Użyj GloVe, jeśli potrzebujesz osadzeń słów, które oddają szerokie relacje semantyczne i globalne asocjacje.
GloVe jest lepsze od innych modeli w zakresie zadań rozpoznawania nazwanych jednostek, analogii słów i podobieństwa słów.
Najpierw musimy zainstalować gensim:
pip install gensim
Krok 1: Instalacja potrzebnych bibliotek
# Import wymaganych bibliotek import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Krok 2: Import modelu GloVe
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Krok 3: Pobranie wektorowej reprezentacji słowa „słodki”
glove_model["cute"]
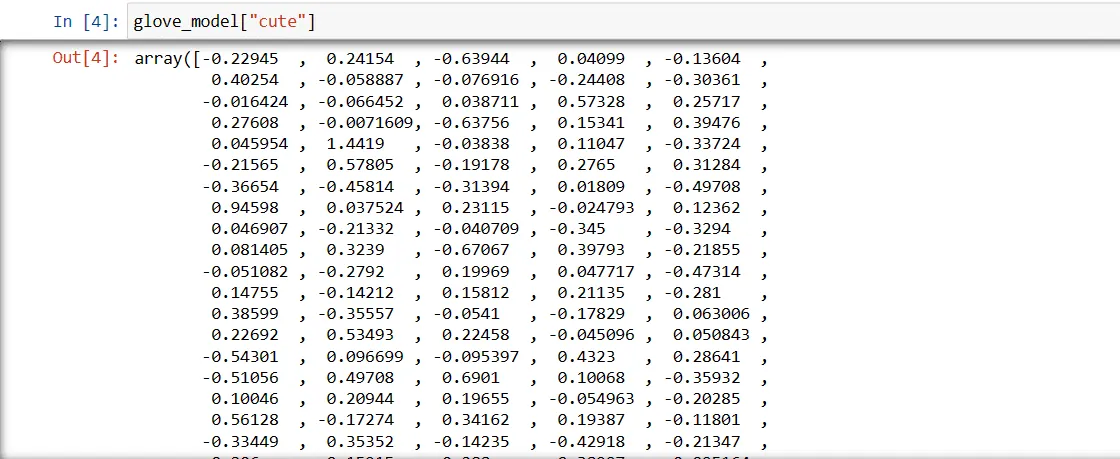
Te wartości oddają znaczenie słowa i jego relacje z innymi słowami. Wartości dodatnie wskazują na pozytywne skojarzenia, a ujemne na negatywne.
W modelu GloVe każdy wymiar wektora słowa reprezentuje pewien aspekt znaczenia lub kontekstu słowa.
Znajdźmy słowa podobne do słowa „chłopiec”.
10 słów najbardziej podobnych do „chłopiec”
# Znajdź podobne słowa
glove_model.most_similar("boy")
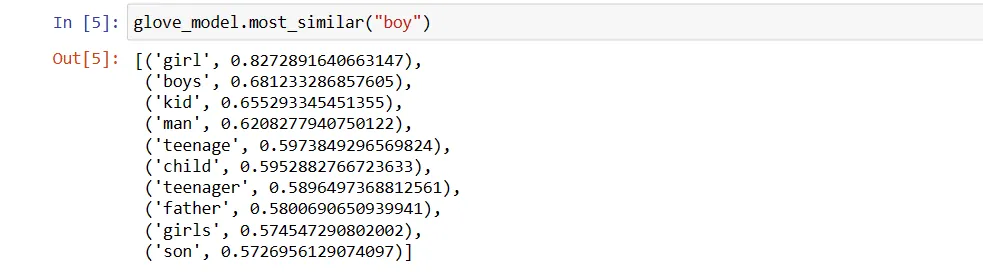
Jak widzimy, najbardziej podobnym słowem do „chłopiec” jest „dziewczyna”.
Teraz sprawdzimy, jak model radzi sobie ze znaczeniem semantycznym na podstawie podanych słów.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)

Nasz model jest w stanie znaleźć idealną relację między słowami.
Zdefiniujmy listę słów:
Spróbujmy zrozumieć znaczenie semantyczne lub relacje między słowami za pomocą wykresu. Zdefiniujmy listę słów, które chcemy wizualizować.
# Zdefiniuj listę słów vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Utwórz macierz osadzania:
Napiszmy kod do utworzenia macierzy osadzania.
# Kod tworzący macierz osadzania
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Zdefiniujmy funkcję wizualizacji t-SNE:
Na podstawie tego kodu zdefiniujemy funkcję dla wykresu wizualizacyjnego.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Zobaczmy, jak wygląda nasz wykres:
<pre class