Data Lakehouse: wspomaganie podróży opartej na danych
Data Lakehouse, czyli dom danych nad jeziorem, to nowa, dynamicznie rozwijająca się koncepcja w obszarze zarządzania danymi. Stanowi ona połączenie najlepszych cech jezior danych i hurtowni danych. Implementacja Data Lakehouse umożliwia gromadzenie różnorodnych danych w jednym miejscu oraz przeprowadzanie zapytań i analiz z zachowaniem zasad ACID.
Jaki jest więc sens stosowania jeziora danych? Jako doświadczony inżynier oprogramowania doskonale zdaję sobie sprawę, jak problematyczne może być zarządzanie i utrzymywanie dwóch osobnych systemów, a także konieczność przesyłania danych między nimi.
Jeśli celem jest wykorzystanie danych do analiz biznesowych i generowania raportów, potrzebne jest przechowywanie ustrukturyzowanych danych w hurtowni. Z kolei gromadzenie danych z różnych źródeł w ich oryginalnych formatach wymaga jeziora danych. Dom danych nad jeziorem eliminuje potrzebę utrzymywania oddzielnych systemów, oferując synergię obu światów.
Kluczowe znaczenie Data Lakehouse

Aby organizacja mogła się rozwijać, niezbędna jest możliwość przechowywania i analizowania danych niezależnie od ich formatu i struktury. Dom danych nad jeziorem staje się kluczowym elementem nowoczesnego zarządzania danymi, rozwiązując ograniczenia zarówno jezior, jak i hurtowni danych.
Często zdarza się, że jeziora danych przeradzają się w nieuporządkowane "bagna", gdzie dane są gromadzone bez żadnej struktury i nadzoru. Utrudnia to wyszukiwanie i wykorzystywanie informacji, co może prowadzić do problemów z ich jakością. Z drugiej strony, hurtownie danych bywają zbyt sztywne i kosztowne w utrzymaniu.
Jezioro danych charakteryzuje się szeregiem specyficznych cech. Przyjrzyjmy się im bliżej.
Charakterystyka Data Lakehouse
Zanim zagłębimy się w architekturę domku nad jeziorem, przeanalizujmy jego najważniejsze cechy i właściwości.
- Obsługa transakcji: W przypadku jeziora danych o dużej skali, często wykonywanych jest wiele równoległych operacji odczytu i zapisu. Zgodność z zasadami ACID gwarantuje, że operacje te nie zakłócają spójności danych.
- Wsparcie dla Business Intelligence: Narzędzia BI można podłączyć bezpośrednio do zaindeksowanych danych, eliminując potrzebę kopiowania ich w inne miejsce. Dostęp do najświeższych danych jest szybszy i tańszy.
- Separacja warstwy przechowywania i obliczeniowej: Pozwala to na niezależne skalowanie obu warstw. W przypadku potrzeby zwiększenia przestrzeni dyskowej można to zrobić bez konieczności zwiększania mocy obliczeniowej.
- Obsługa różnych typów danych: Podobnie jak jezioro danych, Data Lakehouse obsługuje różnorodne typy i formaty danych, takie jak audio, wideo, obrazy czy tekst.
- Otwartość formatów przechowywania: Wykorzystanie standardowych formatów, jak Apache Parquet, umożliwia dostęp do danych z różnych narzędzi i bibliotek.
- Obsługa różnorodnych obciążeń: Data Lakehouse pozwala na wykonywanie szerokiego zakresu operacji, od zapytań SQL, przez BI, po analizę i uczenie maszynowe.
- Obsługa przesyłania strumieniowego w czasie rzeczywistym: Nie ma konieczności tworzenia oddzielnego magazynu danych i potoku dla analiz w czasie rzeczywistym.
- Zarządzanie schematami: Dom danych nad jeziorem promuje niezawodne zarządzanie i audytowanie danych.
Architektura Data Lakehouse
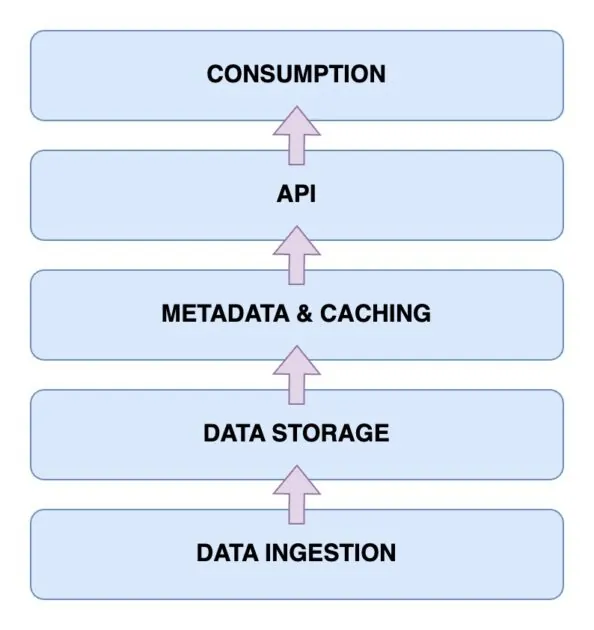
Nadszedł czas, aby przyjrzeć się architekturze Data Lakehouse, która jest kluczowa dla zrozumienia jego działania. Składa się ona z pięciu głównych komponentów. Przeanalizujmy je po kolei.
Warstwa pozyskiwania danych
To tutaj zbierane są wszystkie dane w różnych formatach. Mogą to być zmiany danych w bazach, dane z sensorów IoT, czy strumienie danych w czasie rzeczywistym.
Warstwa przechowywania danych
Po pozyskaniu dane są przechowywane w odpowiednich formatach. Warstwa ta wykorzystuje różne nośniki, np. AWS S3. W praktyce to tutaj znajduje się jezioro danych.
Metadane i warstwa buforowania
Warstwa metadanych i zarządzania danymi zapewnia ujednolicony widok danych zgromadzonych w jeziorze. Dodaje również transakcje ACID, co przekształca jezioro w Data Lakehouse.
Warstwa API
Dostęp do zaindeksowanych danych z warstwy metadanych realizowany jest przez warstwę API. Mogą to być sterowniki baz danych lub punkty końcowe dostępne z dowolnego klienta.
Warstwa zużycia danych
Ta warstwa obejmuje narzędzia analityczne i BI, które wykorzystują dane z Data Lakehouse. Można tu również uruchamiać procesy uczenia maszynowego.
Teraz masz jasny obraz architektury domku nad jeziorem. Jak jednak go zbudować?
Kroki tworzenia Data Lakehouse
Zobaczmy, jak zbudować własne jezioro danych. Niezależnie od tego, czy masz już jezioro, hurtownię, czy dopiero zaczynasz, kroki są podobne.
- Określenie wymagań: Należy zdefiniować typy przechowywanych danych i sposoby ich wykorzystania, np. modele uczenia maszynowego, raporty biznesowe czy analizy.
- Stworzenie potoku pozyskiwania: Potok ten odpowiada za wprowadzanie danych do systemu. W zależności od źródeł danych, można wykorzystać magistralę wiadomości (np. Apache Kafka) lub punkty końcowe API.
- Zbudowanie warstwy pamięci masowej: Jeśli masz już jezioro danych, możesz je wykorzystać jako warstwę pamięci. Alternatywnie, można wybrać AWS S3, HDFS lub Delta Lake.
- Zastosowanie przetwarzania danych: Na tym etapie dane są przetwarzane zgodnie z potrzebami biznesowymi. Można wykorzystać narzędzia open source (np. Apache Spark) do wykonywania zadań okresowych, które pobierają i przetwarzają dane z warstwy pamięci masowej.
- Stworzenie zarządzania metadanymi: Ważne jest śledzenie i przechowywanie różnych typów danych oraz ich właściwości. Ułatwia to katalogowanie i przeszukiwanie. Można również stworzyć warstwę buforowania.
- Zapewnienie opcji integracji: Należy udostępnić punkty integracji dla zewnętrznych narzędzi, które chcą uzyskać dostęp do danych. Mogą to być zapytania SQL, narzędzia ML czy rozwiązania BI.
- Wdrożenie zarządzania danymi: Ze względu na różnorodność danych, należy ustalić zasady zarządzania, w tym kontrolę dostępu, szyfrowanie i audyt. Ma to na celu zapewnienie jakości, spójności i zgodności danych z przepisami.
Zobaczmy teraz, jak przeprowadzić migrację do Data Lakehouse, jeśli masz już istniejące rozwiązanie do zarządzania danymi.
Kroki migracji do Data Lakehouse
Podczas migracji obciążeń do Data Lakehouse należy pamiętać o kilku ważnych krokach. Plan działania pozwala uniknąć problemów w ostatniej chwili.
Krok 1: Analiza danych
Pierwszym i najważniejszym krokiem jest analiza danych. Pozwala ona określić zakres migracji i zidentyfikować zależności. Dzięki temu zyskujesz lepszy wgląd w środowisko i możesz ustalić priorytety zadań.
Krok 2: Przygotowanie danych do migracji
Kolejnym krokiem jest przygotowanie danych, w tym zarówno tych migrowanych, jak i struktur danych wspierających. Warto ustalić, które zbiory danych i kolumny są naprawdę potrzebne, aby zaoszczędzić czas i zasoby.
Krok 3: Konwersja danych do wymaganego formatu
Preferowane jest wykorzystanie automatycznej konwersji. Wiele narzędzi oferuje gotowe rozwiązania z małą ilością kodu. Narzędzia takie jak Alchemist mogą w tym pomóc.
Krok 4: Weryfikacja danych po migracji
Po migracji należy zweryfikować poprawność danych. Warto zautomatyzować ten proces, aby uniknąć żmudnej pracy ręcznej. Ważne jest sprawdzenie, czy procesy biznesowe i zadania związane z danymi pozostają niezmienione.
Kluczowe cechy Data Lakehouse
🔷 Kompleksowe zarządzanie danymi: Otrzymujesz funkcje zarządzania danymi, takie jak czyszczenie, ETL oraz egzekwowanie schematu, które pomagają przygotować dane do analiz i narzędzi BI.
🔷 Otwarte formaty przechowywania: Dane są przechowywane w otwartych i standardowych formatach, co ułatwia pracę z danymi z różnych źródeł. Obsługiwane są formaty takie jak AVRO, ORC czy Parquet.
🔷 Separacja pamięci masowej: Możliwość oddzielenia pamięci masowej od zasobów obliczeniowych pozwala na niezależne skalowanie obu warstw.
🔷 Obsługa strumieni danych: Data Lakehouse umożliwia pozyskiwanie danych w czasie rzeczywistym, co jest istotne przy podejmowaniu szybkich decyzji.
🔷 Zarządzanie danymi: Zapewnia silne zarządzanie i możliwości audytu, co jest kluczowe dla integralności danych.
🔷 Obniżone koszty danych: Koszty operacyjne są niższe niż w przypadku hurtowni danych. Można wykorzystać obiektową pamięć masową w chmurze i wyeliminować potrzebę utrzymywania wielu systemów przechowywania.
Data Lake kontra Hurtownia Danych kontra Data Lakehouse
| Cecha | Data Lake | Hurtownia Danych | Data Lakehouse |
| Przechowywanie danych | Surowe lub nieustrukturyzowane dane | Przetworzone i ustrukturyzowane dane | Zarówno surowe, jak i ustrukturyzowane dane |
| Schemat danych | Brak stałego schematu | Stały schemat | Schemat open source do integracji |
| Transformacja danych | Brak transformacji | Wymagany rozbudowany ETL | ETL w razie potrzeby |
| Zgodność z ACID | Brak | Zgodne | Zgodne |
| Wydajność zapytań | Zwykle wolniej, brak struktury | Szybko, dzięki strukturyzacji | Szybko, częściowa strukturyzacja |
| Koszt | Opłacalne przechowywanie | Wysokie koszty przechowywania i zapytań | Zrównoważone koszty |
| Zarządzanie danymi | Wymaga starannego zarządzania | Wymaga silnego nadzoru | Wspiera środki zarządzania |
| Analiza w czasie rzeczywistym | Ograniczona | Ograniczona | Wspiera |
| Przypadki użycia | Przechowywanie, eksploracja, ML i AI | Raportowanie i analiza BI | Uczenie maszynowe i analityka |
Wnioski
Data Lakehouse to połączenie zalet jezior i hurtowni danych. Pozwala to na rozwiązanie ważnych problemów związanych z zarządzaniem i analizą danych.
Znając już cechy i architekturę domku nad jeziorem, warto podkreślić jego znaczenie w kontekście pracy z danymi ustrukturyzowanymi i nieustrukturyzowanymi. Dom danych nad jeziorem oferuje jednolitą platformę do przechowywania, zapytań i analiz, zapewniając jednocześnie zgodność z zasadami ACID.
Realizacja kroków opisanych w tym artykule, zarówno w kontekście tworzenia, jak i migracji do Data Lakehouse, odblokowuje korzyści płynące z ujednoliconej i ekonomicznej platformy zarządzania danymi. Bądź na bieżąco z nowoczesnymi rozwiązaniami i wspieraj rozwój biznesu poprzez wykorzystanie analiz danych.
Zachęcamy również do zapoznania się z naszym artykułem o replikacji danych.
