Jak analizować tekst
Jeżeli posiadasz wiedzę z zakresu programowania w kilku językach, z pewnością spotkałeś się z pojęciem parsowania tekstu. Jest to proces, który pozwala na uporządkowanie złożonych danych zawartych w pliku. Ten artykuł ma na celu wyjaśnienie, jak dokonywać analizy tekstu przy użyciu różnych technik programistycznych. Dodatkowo, jeżeli natkniesz się na problem z parsowaniem tekstu oznaczony jako "błąd parsowania tekstu x", dowiesz się tutaj, jak go rozwiązać.
Sposoby analizowania tekstu
W tym materiale przedstawiamy kompleksowy przewodnik po metodach parsowania tekstu, a także krótkie wprowadzenie do samego zagadnienia.
Definicja parsowania tekstu
Zanim przejdziemy do praktycznych aspektów parsowania tekstu za pomocą kodu, warto zapoznać się z podstawowymi założeniami języka i kodowania.
NLP, czyli przetwarzanie języka naturalnego
Do analizy tekstu wykorzystuje się przetwarzanie języka naturalnego (NLP), będące poddziedziną sztucznej inteligencji. Jednym z języków programowania wykorzystywanych w tym celu jest Python.
Techniki NLP umożliwiają komputerom rozumienie i przetwarzanie języka ludzkiego, dostosowując go do różnorodnych zastosowań. Aby móc wykorzystać algorytmy uczenia maszynowego, nieustrukturyzowane dane tekstowe muszą zostać przekształcone w ustrukturyzowane dane tabelaryczne. Właśnie w tym procesie zmiany formatu danych wykorzystywany jest język Python.
Czym jest parsowanie tekstu?
Parsowanie tekstu to nic innego jak konwersja danych z jednego formatu na inny. Format, w którym plik jest zapisany, musi zostać zinterpretowany i przekształcony na inny, umożliwiając korzystanie z niego w różnych aplikacjach.
- Mówiąc prościej, proces ten obejmuje analizę ciągu znaków lub tekstu i przekształcenie go w logiczne komponenty poprzez zmianę formatu pliku.
- Do realizacji tego często wykonywanego zadania programistycznego stosuje się specyficzne reguły języka Python. W trakcie parsowania tekstu, ciąg znaków jest dzielony na mniejsze elementy.
Dlaczego parsowanie tekstu jest istotne?
W tej części omówimy powody, dla których parsowanie tekstu jest niezbędne. Wiedza ta jest kluczowa przed przystąpieniem do nauki technik parsowania.
- Dane skomputeryzowane mogą mieć różne formaty, w zależności od ich przeznaczenia.
- Formaty danych różnią się w zależności od aplikacji, a niekompatybilność formatów może prowadzić do błędów.
- Nie istnieje uniwersalny program komputerowy zdolny do obsługi wszystkich formatów danych.
Metoda 1: Użycie klasy DataFrame
Klasa DataFrame w języku Python oferuje wszystkie niezbędne narzędzia do parsowania tekstu. Ta wbudowana biblioteka zawiera kod potrzebny do przekształcenia danych z jednego formatu do innego.
Krótkie wprowadzenie do klasy DataFrame
DataFrame Class to zaawansowana struktura danych, która służy jako narzędzie do analizy danych. Jest to skuteczne narzędzie, które umożliwia analizę danych przy minimalnym wysiłku.
- Kod jest wczytywany do DataFrame za pomocą biblioteki pandas, co pozwala na analizę w języku Python.
- Klasa zawiera wiele pakietów dostarczonych przez pandas, które są wykorzystywane przez analityków danych Pythona.
- Cechą tej klasy jest abstrakcja, czyli ukrycie wewnętrznej logiki działania funkcji przed użytkownikami biblioteki NumPy. NumPy to biblioteka Pythona, która oferuje funkcje i polecenia do pracy z tablicami.
- Klasa DataFrame może służyć do reprezentacji dwuwymiarowej tablicy z wieloma indeksami wierszy i kolumn. Indeksy te ułatwiają przechowywanie danych wielowymiarowych, dlatego są nazywane MultiIndex. Ich modyfikacja jest kluczowa do zrozumienia, jak rozwiązać problem z analizą.
Biblioteka pandas w Pythonie pozwala na wykonywanie operacji w stylu SQL, zapewniając precyzję i uniknięcie błędów w tekście podczas analizy. Zawiera również narzędzia IO, które ułatwiają analizę plików CSV, MS Excel, JSON, HDF5 i innych formatów danych.
Proces parsowania tekstu z użyciem klasy DataFrame
Aby zrozumieć, jak parsować tekst, można zastosować standardową metodę przy użyciu klasy DataFrame.
- Zacznij od analizy formatu danych wejściowych.
- Określ format danych wyjściowych, na przykład CSV.
- Zapisz dane jako typ prymitywny, na przykład lista lub słownik.
Uwaga: Pisanie kodu w pustej ramce DataFrame może być żmudne i skomplikowane. Biblioteka pandas umożliwia tworzenie danych w klasie DataFrame na podstawie tych typów danych. Dzięki temu dane w pierwotnym typie można łatwo przetransformować do wymaganego formatu.
- Przeanalizuj dane za pomocą narzędzia pandas DataFrame i wypisz wynik.
Opcja I: Format standardowy
Poniżej przedstawiono standardowy sposób formatowania dowolnego pliku do określonego formatu, na przykład CSV.
- Zapisz plik z danymi na dysku lokalnym. Na przykład nadaj mu nazwę data.txt.
- Zaimportuj plik do biblioteki pandas, nadając mu nazwę i przypisując dane do zmiennej. W podanym przykładzie pandas jest importowany pod nazwą pd.
- Import powinien zawierać kod z informacjami o nazwie pliku wejściowego, funkcji i formacie pliku.
Uwaga: W tym przykładzie zmienna o nazwie "res" jest używana do wykonania funkcji odczytu danych z pliku data.txt za pomocą pandas, który został zaimportowany jako "pd". Format danych wejściowych to CSV.
- Wywołaj nazwę pliku i wyświetl przeanalizowany tekst. Na przykład, polecenie "res" po wykonaniu w wierszu poleceń spowoduje wyświetlenie przeanalizowanego tekstu.
Poniżej znajduje się przykładowy kod dla powyższego procesu, który pomoże zrozumieć, jak parsować tekst.
import pandas as pd
res = pd.read_csv('data.txt')
res
W tym przypadku, jeśli w pliku data.txt wprowadzi się dane w formie [1,2,3], zostaną one przeanalizowane i wyświetlone jako 1 2 3.
Opcja II: Metoda operacji na ciągach
Jeżeli tekst w kodzie zawiera tylko ciągi znaków lub znaki alfanumeryczne, można użyć znaków specjalnych (przecinki, spacje itp.) do rozdzielenia i przeanalizowania tekstu. Proces jest podobny do typowych operacji na ciągach. Aby dowiedzieć się, jak naprawić błąd parsowania, należy postępować zgodnie z poniższym procesem.
- Dane są pobierane z ciągu znaków, a wszystkie znaki specjalne, które rozdzielają tekst, są zapisywane.
Na przykład, w poniższym kodzie znaki specjalne w ciągu my_string to "," i ":". Ten proces wymaga staranności, aby uniknąć "błędu parsowania tekstu x".
- Tekst w ciągu jest dzielony na poszczególne wartości na podstawie pozycji i wartości znaków specjalnych.
Na przykład, ciąg jest dzielony na wartości danych tekstowych za pomocą polecenia "split".
- Wartości danych w ciągu są wypisywane jako przeanalizowany tekst. W tym przypadku instrukcja "print" służy do wyświetlenia przeanalizowanej wartości danych tekstu.
Poniżej znajduje się przykładowy kod dla opisanego powyżej procesu.
my_string = 'Names: Tech, computer'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print("Names: {}".format(sfinal))
W tym przypadku wynik przeanalizowanego ciągu zostanie wyświetlony w następujący sposób:
Names: ['Tech', 'computer']
Aby lepiej zrozumieć analizę tekstu przy użyciu ciągów, można zastosować pętlę "for". Kod można zmodyfikować w następujący sposób:
my_string = 'Names: Tech, computer'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print("Step {}: {}".format(idx, item))
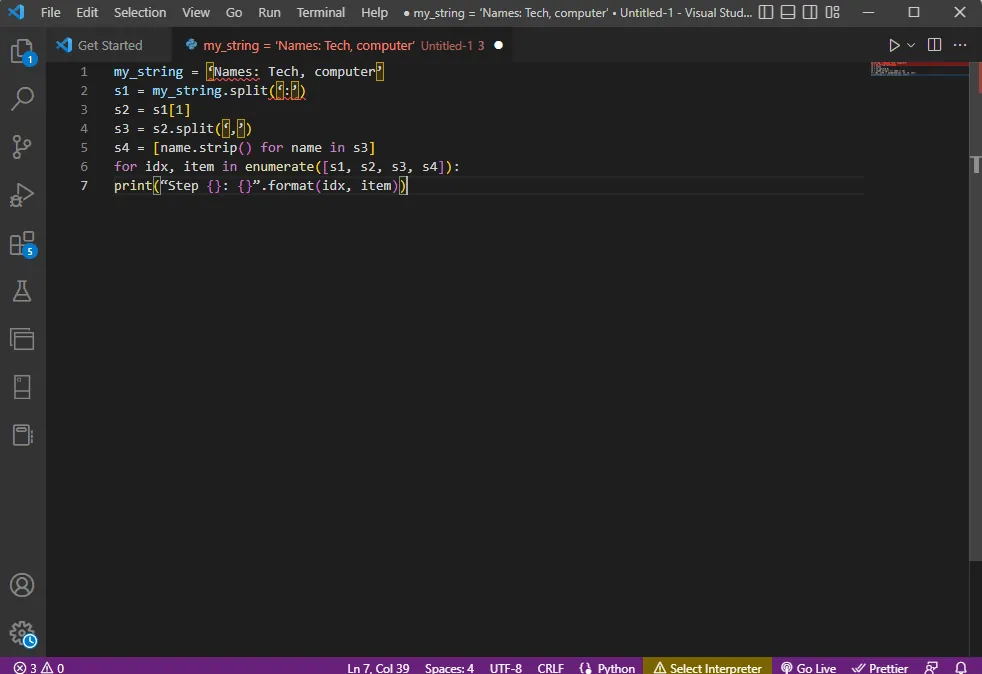
Wynik analizy tekstu dla każdego kroku jest wyświetlany poniżej. Widać, że w kroku 0 ciąg jest rozdzielany na podstawie znaku specjalnego ":", a wartości danych tekstowych są rozdzielane w kolejnych krokach.
Step 0: ['Names', 'Tech, computer'] Step 1: Tech, computer Step 2: [' Tech', ' computer'] Step 3: ['Tech', 'computer']
Opcja III: Parsowanie złożonego pliku
W wielu przypadkach dane pliku, które należy przeanalizować, zawierają różne typy i wartości. W takiej sytuacji przeanalizowanie pliku za pomocą wcześniej opisanych metod może być problematyczne.
Funkcje parsowania złożonych danych w pliku mają na celu wyświetlenie wartości danych w formie tabelarycznej.
- Metadane wartości (tytuł) są umieszczane na początku pliku,
- Zmienne i pola są wyświetlane w formie tabelarycznej, a
- Wartości danych tworzą klucz złożony.
Zanim przejdziemy do szczegółów tej metody, należy poznać podstawowe pojęcia. Parsowanie wartości danych odbywa się przy użyciu wyrażeń regularnych (Regex).
Wzorce wyrażeń regularnych
Aby wiedzieć, jak rozwiązać błąd parsowania, należy upewnić się, że wzorce Regex są prawidłowe. Kod do analizy wartości danych ciągów zawiera typowe wzorce Regex, które zostały wymienione poniżej.
-
'd' : dopasowuje cyfrę dziesiętną w ciągu,
-
's' : dopasowuje znak odstępu,
-
'w' : dopasowuje znak alfanumeryczny,
-
'+' lub '*' : wykonuje zachłanne dopasowanie, dopasowując jeden lub więcej znaków w ciągu,
-
'a-z' : dopasowuje grupy małych liter w wartościach danych tekstowych,
-
'A-Z' lub 'a-z' : dopasowuje grupy wielkich i małych liter,
-
'0-9' : dopasowuje wartości liczbowe.
Wyrażenia regularne (Regex)
Moduły wyrażeń regularnych są ważnym elementem biblioteki pandas w języku Python. Niepoprawne użycie Regex może prowadzić do "błędu parsowania tekstu x". Regex to mały język wbudowany w Pythonie, który służy do wyszukiwania wzorców ciągów znaków w tekście. Wyrażenia regularne to ciągi znaków o specjalnej składni. Pozwalają one użytkownikowi na dopasowanie wzorców w innych ciągach na podstawie określonych wartości.
Regex tworzy się na podstawie typu danych i wymagań dotyczących wyrażenia w ciągu, np. "String = (.*)n". Wyrażenie regularne jest umieszczane przed wzorcem w każdym wyrażeniu. Symbole używane w wyrażeniach regularnych, które ułatwią zrozumienie parsowania tekstu, są wymienione poniżej:
-
. : aby pobrać dowolny znak z danych,
-
* : aby użyć zera lub więcej danych z poprzedniego wyrażenia,
-
(.*) : aby zgrupować część wyrażenia regularnego w nawiasach,
-
n : aby utworzyć nowy znak linii na końcu wiersza w kodzie,
-
d : aby utworzyć wartość całkowitą w zakresie od 0 do 9,
-
+ : aby użyć jednego lub więcej danych z poprzedniego wyrażenia,
-
| : aby utworzyć logiczne stwierdzenie; używane dla wyrażeń typu "lub".
Obiekty Regex
RegexObject jest wartością zwracaną przez funkcję kompilacji i służy do zwracania MatchObject, jeśli wyrażenie jest zgodne z wartością dopasowania.
1. Obiekt MatchObject
Wartość logiczna obiektu MatchObject zawsze zwraca True, dlatego można użyć instrukcji "if" do zidentyfikowania pozytywnych dopasowań. W przypadku instrukcji "if", grupa, do której odnosi się indeks, służy do znalezienia dopasowania w wyrażeniu.
-
group() zwraca jedną lub więcej podgrup dopasowania,
-
group(0) zwraca całe dopasowanie,
-
group(1) zwraca pierwszą podgrupę w nawiasach,
-
W przypadku odwoływania się do wielu grup, należy użyć rozszerzenia specyficznego dla Pythona. Rozszerzenie to służy do zdefiniowania nazwy grupy, w której ma zostać znalezione dopasowanie. Na przykład, wyrażenie (?P
regex1) odnosi się do grupy o nazwie "group1" i sprawdza dopasowanie w wyrażeniu regularnym "regex1". Aby dowiedzieć się, jak naprawić błąd parsowania, należy sprawdzić, czy grupa jest poprawnie zdefiniowana.
2. Metody MatchObject
Podczas nauki parsowania tekstu, ważne jest, aby wiedzieć, że MatchObject ma dwie podstawowe metody. Jeśli MatchObject zostanie znaleziony w wyrażeniu, zwróci jego wystąpienie; w przeciwnym razie zwróci "None".
- Metoda "match(string)" służy do wyszukiwania dopasowań ciągu na początku wyrażenia regularnego, a
- Metoda "search(string)" służy do przeglądania ciągu w celu znalezienia dopasowania w wyrażeniu regularnym.
Funkcje wyrażeń regularnych
Funkcje Regex to linie kodu, które wykonują konkretne działanie zdefiniowane przez użytkownika, na podstawie pozyskanych danych.
Uwaga: Podczas tworzenia funkcji, w wyrażeniach regularnych używa się nieprzetworzonych ciągów, aby uniknąć błędów w przetwarzaniu tekstu "x". W tym celu dodaje się indeks dolny "r" przed każdym wzorcem w wyrażeniu.
Poniżej zostały omówione często używane funkcje:
1. re.findall()
Ta funkcja zwraca wszystkie wzorce w ciągu, jeśli zostanie znalezione dopasowanie. Jeżeli nie ma dopasowania, zwraca pustą listę. Na przykład funkcja "string = re.findall('[aeiou]', regex_filename)" służy do znalezienia wystąpień samogłosek w nazwie pliku.
2. re.split()
Ta funkcja służy do dzielenia ciągu w miejscu, gdzie zostanie znalezione dopasowanie, np. ze spacją. Jeżeli nie zostanie znalezione dopasowanie, zwraca pusty ciąg.
3. re.sub()
Ta funkcja zastępuje dopasowany tekst zawartością podanej zmiennej "replace". W przeciwieństwie do innych funkcji, jeśli nie zostanie znaleziony żaden wzorzec, zwracany jest oryginalny ciąg.
4. re.search()
Jedną z podstawowych funkcji pomagających w nauce parsowania tekstu jest funkcja "search()". Pomaga ona w wyszukiwaniu wzorca w ciągu i zwraca obiekt dopasowania. Jeżeli wyszukiwanie nie znajdzie dopasowania, nie zostanie zwrócona żadna wartość.
5. re.compile(wzór)
Ta funkcja służy do kompilowania wzorców wyrażeń regularnych do obiektu RegexObject, który został omówiony wcześniej.
Dodatkowe wymagania
Wymienione poniżej wymagania to dodatkowe funkcje wykorzystywane przez doświadczonych programistów w analizie danych.
- Do wizualizacji wyrażenia regularnego stosuje się wyrażenie regularne, a
- Do testowania wyrażenia regularnego stosuje się regex101.
Proces parsowania tekstu
Sposób parsowania tekstu w tej złożonej opcji został opisany poniżej:
- Najważniejszym krokiem jest zrozumienie formatu wejściowego poprzez odczytanie zawartości pliku. Na przykład, funkcje "with open" i "read()" służą do otwierania i odczytywania zawartości pliku o nazwie sample. Przykładowy plik zawiera zawartość pliku "file.txt". Aby zrozumieć, jak rozwiązać błąd parsowania, plik musi zostać odczytany w całości.
- Zawartość pliku jest drukowana w celu ręcznej analizy danych i znalezienia metadanych wartości. Funkcja "print()" służy do wyświetlenia zawartości przykładowego pliku.
- Do kodu importowane są wymagane pakiety danych do analizy tekstu. Nadaje się również nazwę klasie do dalszego kodowania. W tym przypadku importuje się moduły "re" i "pandas".
- Wyrażenia regularne wymagane dla kodu są definiowane w pliku poprzez dodanie wzorca Regex i funkcji Regex. Pozwala to obiektowi tekstowemu pobrać kod do analizy danych.
- Aby dowiedzieć się, jak parsować tekst, można odwołać się do kodu. Funkcja "compile()" służy do kompilacji ciągu ze zbioru "stringname1" w pliku "nazwapliku". Funkcja sprawdzania dopasowań w wyrażeniu regularnym jest wykorzystywana przez polecenie "ief_parse_line(line)".
- Parser linii dla kodu jest napisany za pomocą funkcji "def_parse_file(ścieżka pliku)", która sprawdza wszystkie dopasowania regex w określonej funkcji. Metoda "regex search()" wyszukuje klucz "rx" w nazwie pliku i zwraca klucz oraz dopasowanie pierwszego pasującego wyrażenia regularnego. Jakikolwiek problem w tym kroku może prowadzić do "błędu parsowania tekstu x".
- Kolejnym krokiem jest napisanie parsera plików z użyciem funkcji "def_parse_file(ścieżka pliku)". Tworzona jest pusta lista do zbierania danych kodu, ponieważ "data = []" dopasowanie jest sprawdzane w każdym wierszu przez "match = _parse_line(line)", a poprawne dane są zwracane na podstawie typu danych.
- Do wyodrębnienia numeru i wartości z tabeli używana jest komenda "line.strip().split(',')". Polecenie "row{}" służy do tworzenia słownika z wierszem danych. Polecenie "data.append(row)" służy do zrozumienia danych i przetworzenia ich do formatu tabelarycznego.
Polecenie "data = pd.DataFrame(data)" służy do utworzenia obiektu DataFrame z wartości dict. Alternatywnie, można użyć poniższych poleceń w odpowiednich celach:
-
data.set_index(['string', 'integer'], inplace=True), aby ustawić indeks tabeli,
-
data = data.groupby(level=data.index.names).first(), aby skonsolidować i usunąć wartości NaN,
-
data = data.apply(pd.to_numeric, error='ignore'), aby zaktualizować wynik z wartości zmiennoprzecinkowej na całkowitą.
Ostatnim krokiem jest przetestowanie parsera za pomocą instrukcji "if", przypisanie wartości do zmiennej "data" i wyświetlenie jej za pomocą polecenia "print(data)".
Poniżej znajduje się przykładowy kod dla powyższych wyjaśnień:
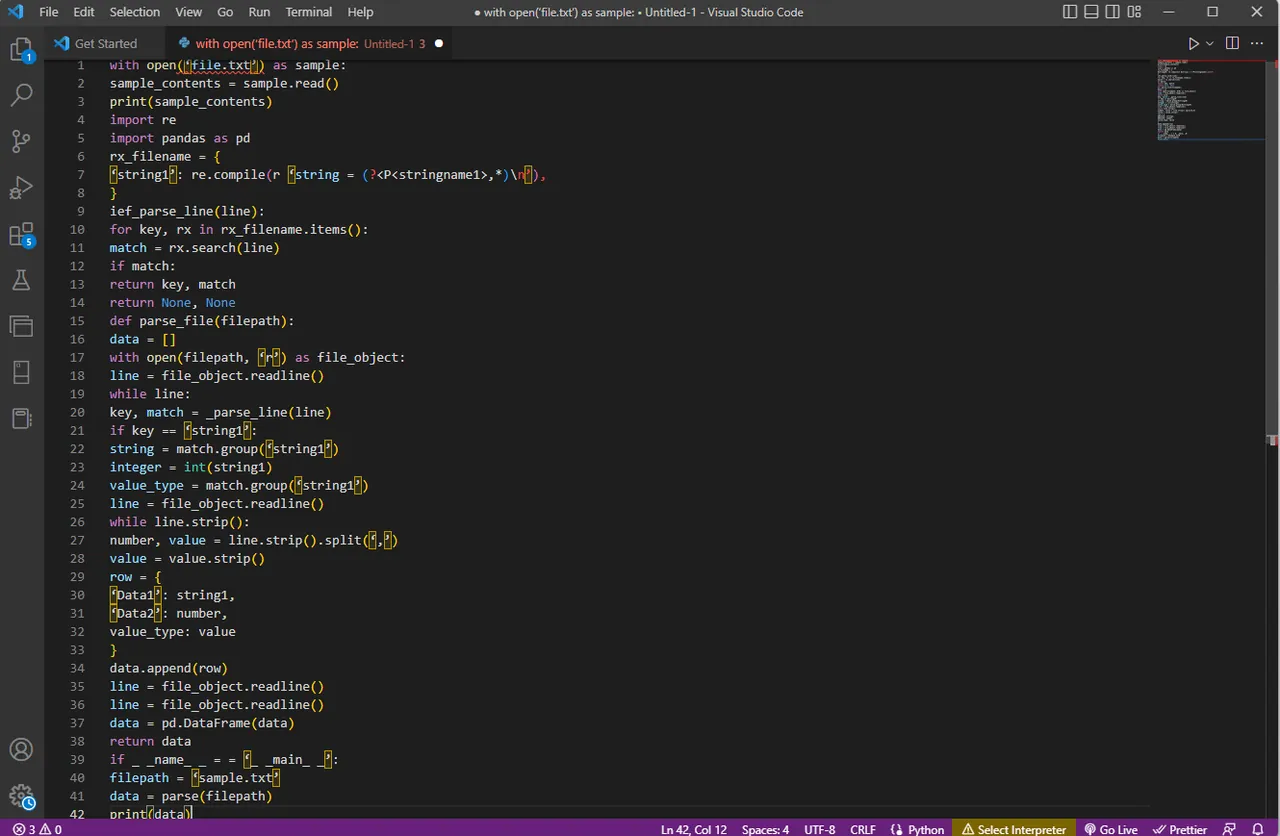
with open('file.txt') as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
'string1': re.compile(r'string = (?P<stringname1>.*)n'),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == 'string1':
string = match.group('string1')
integer = int(string1)
value_type = match.group('string1')
line = file_object.readline()
while line.strip():
number, value = line.strip().split(',')
value = value.strip()
row = {
'Data1': string1,
'Data2': number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if __name__ == '__main__':
filepath = 'sample.txt'
data = parse(filepath)
print(data)
Metoda 2: Tokenizacja słów
Proces przekształcania tekstu w mniejsze fragmenty (tokeny) zgodnie z określonymi regułami nazywa się tokenizacją. Aby zrozumieć, jak naprawić błąd parsowania, należy dokładnie przeanalizować polecenia tokenizacji słów w kodzie. Podobnie jak w przypadku wyrażeń regularnych, w tej metodzie można tworzyć własne reguły, które pomagają w zadaniach wstępnego przetwarzania tekstu, takich jak mapowanie części mowy. W tej metodzie wykonuje się również takie operacje jak wyszukiwanie i dopasowywanie typowych słów, czyszczenie tekstu i przygotowywanie danych do zaawansowanej analizy, takiej jak analiza sentymentu. Nieprawidłowa tokenizacja może skutkować "błędem parsowania tekstu x".
Biblioteka Nltk
W procesie tokenizacji używa się biblioteki narzędzi językowych "nltk", która oferuje wiele funkcji do zadań NLP. Bibliotekę można pobrać za pomocą pakietów instalacyjnych Pip. Aby dowiedzieć się, jak parsować tekst, można użyć podstawowej dystrybucji pakietu Anaconda, która domyślnie zawiera bibliotekę.
Formy tokenizacji
Popularnymi formami tokenizacji są tokenizacja słów i tokenizacja zdań. Tokenizacja słów wyświetla każde słowo oddzielnie, natomiast tokenizacja zdań wyświetla słowa w kontekście zdań.
Proces parsowania tekstu
- Importowana jest biblioteka "nltk", a następnie importowane są formy tokenizacji z biblioteki.
- Podany jest ciąg znaków i polecenia wykonania tokenizacji.
- Po wyświetleniu ciągu znaków, wyjściem będzie tekst "komputer to słowo".
- W przypadku tokenizacji słowa (word_tokenize()), każde słowo w zdaniu jest wypisywane osobno, w cudzysłowach i oddzielone przecinkami. Wyjściem polecenia jest: "komputer", "to", "słowo", ".".
- W przypadku tokenizacji zdań (sent_tokenize()), poszczególne zdania są umieszczane w cudzysłowach i dozwolone jest powtarzanie słów. Wyjściem polecenia jest "komputer to słowo".
Poniżej znajduje się kod wyjaśniający powyższe kroki tokenizacji:
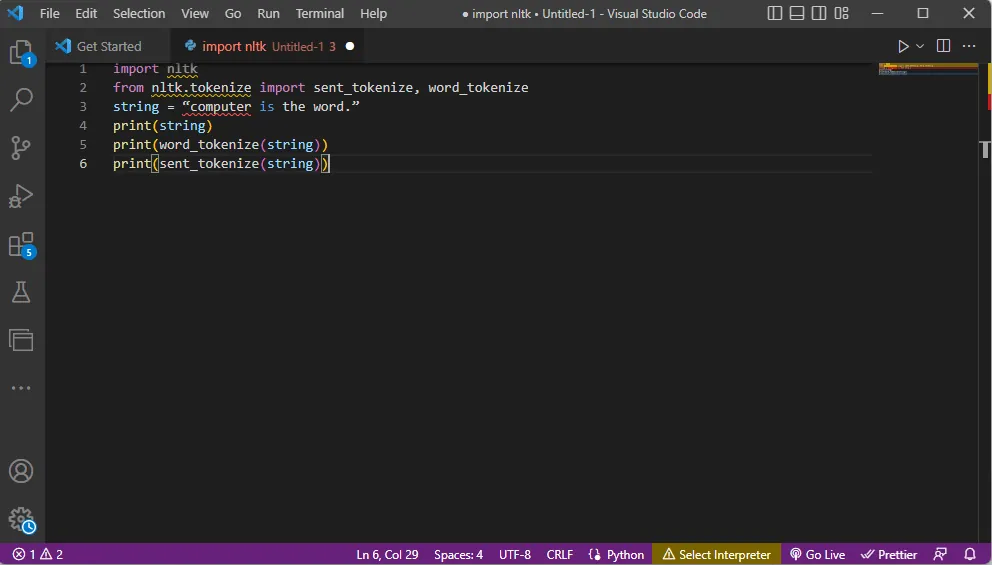
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = "computer is the word." print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metoda 3: Klasa DocParser
Podobnie jak w przypadku klasy DataFrame, klasa DocParser może być użyta do analizy tekstu w kodzie. Klasa umożliwia wywołanie funkcji "parse" ze ścieżką do pliku.
Proces parsowania tekstu
Aby dowiedzieć się, jak parsować tekst za pomocą klasy DocParser, należy postępować zgodnie z poniższymi krokami:
- Funkcja "get_format(filename)" służy do pobrania rozszerzenia pliku, zwrócenia go do zmiennej set funkcji i przekazania do kolejnej funkcji. Na przykład, "p1 = get_format(nazwapliku)" pobierze rozszerzenie pliku z nazwy pliku, przypisze do zmiennej "p1" i przekaże do następnej funkcji.
- Struktura logiczna z innymi funkcjami jest tworzona za pomocą instrukcji i funkcji "if-elif-else".
- Jeśli rozszerzenie pliku jest poprawne i struktura jest logiczna, funkcja "get_parser" służy do analizy danych w ścieżce pliku i zwraca obiekt ciągu znaków do użytkownika.
Uwaga: Aby uniknąć błędów parsowania, ta funkcja musi być zaimplementowana poprawnie.
- Analiza wartości danych odbywa się na podstawie rozszerzenia pliku. Konkretna implementacja klasy, czyli "parse_txt" lub "parse_docx", służy do generowania obiektów ciągu znaków z danej części pliku.
- Parsowanie można wykonać dla innych rozszerzeń, takich jak "parse_pdf", "parse_html" i "parse_pptx".
- Wartości danych i interfejs można zaimportować do aplikacji za pomocą instrukcji "import" i utworzyć instancję obiektu DocParser. Można to zrobić poprzez parsowanie plików w języku Python, takich jak "parse_file.py". Operację tę należy wykonać ostrożnie, aby uniknąć "błędu parsowania tekstu x".
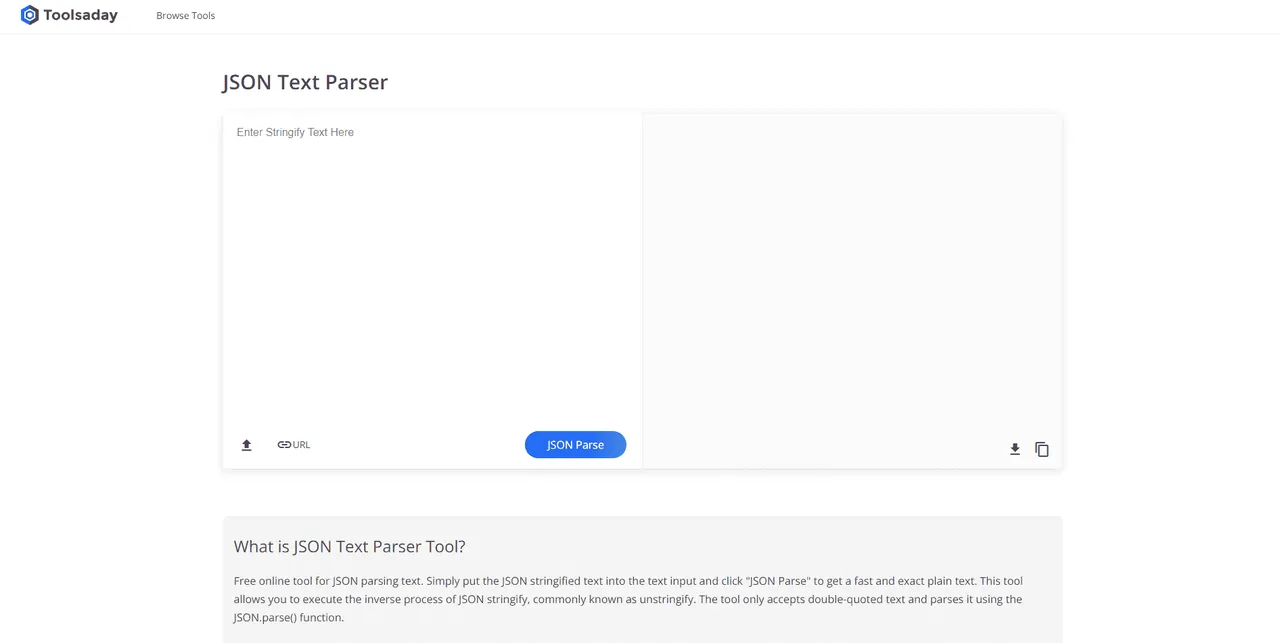
Metoda 4: Narzędzia do analizy tekstu
Narzędzie do parsowania tekstu służy do wyodrębniania określonych danych ze zmiennych i mapowania ich na inne zmienne. Jest to niezależne od innych narzędzi używanych w zadaniu. Platforma BPA służy do wykorzystania i wyprowadzenia zmiennych. Aby uzyskać dostęp do narzędzia Parse Text Tool online i skorzystać z wcześniej podanych informacji, jak parsować tekst, kliknij podany link.
Metoda 5: TextFieldParser (Visual Basic)
TextFieldParser używa obiektów do analizowania i przetwarzania bardzo dużych plików o strukturze opartej na separatorach. W tej metodzie można wykorzystać szerokości i kolumny tekstu, takie jak pliki dziennika. Metoda parsowania jest podobna do iteracji kodu po pliku tekstowym i służy głównie do wyodrębniania pól tekstowych, podobnie jak metody manipulacji ciągami. Ma na celu tokenizację ciągów rozdzielonych separatorem i pól o różnych szerokościach przy użyciu ogranicznika, takiego jak przecinek lub spacja tabulacji.
Funkcje do analizy tekstu
Do analizy tekstu w tej metodzie można wykorzystać następujące funkcje:
- Do zdefiniowania separatora używa się "SetDelimiters". Na przykład polecenie "testReader.SetDelimiters(vbTab)" ustawia spację tabulacji jako separator.
- Do ustawienia szerokości pola można użyć polecenia "testReader.SetFieldWidths(integer)".
- Aby przetestować typ pola tekstu, można użyć polecenia "testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth".
Metody znajdowania MatchObject
Istnieją dwie podstawowe metody znajdowania MatchObject w kodzie lub przeanalizowanym tekście.
- Pierwsza metoda polega na zdefiniowaniu formatu i pętli pliku za pomocą metody "ReadFields". Metoda ta pomaga w przetwarzaniu każdego wiersza kodu.
- Metoda "PeekChars" służy do indywidualnego sprawdzania każdego pola przed jego odczytaniem, definiowania wielu formatów i reagowania.
W obu przypadkach, jeżeli pole nie pasuje do określonego formatu podczas analizowania tekstu, zwracany jest wyjątek "MalformedLineException".
Porada: Analiza tekstu w MS Excel
Ostatnią, prostą metodą parsowania tekstu jest użycie aplikacji MS Excel do tworzenia plików rozdzielonych tabulatorami i przecinkami. Pomoże to zweryfikować przeanalizowany wynik i znaleźć sposób na naprawienie błędu parsowania.
1. Wybierz dane w pliku źródłowym i naciśnij jednocześnie Ctrl + C, aby skopiować plik.
2. Otwórz aplikację Excel za pomocą paska wyszukiwania systemu Windows.
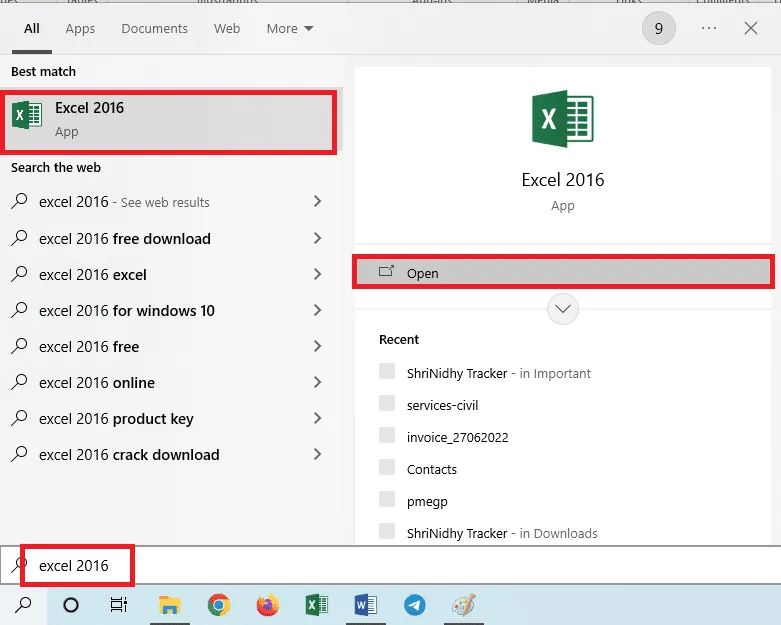
3. Kliknij komórkę A1 i naciśnij jednocześnie Ctrl + V, aby wkleić skopiowany tekst.
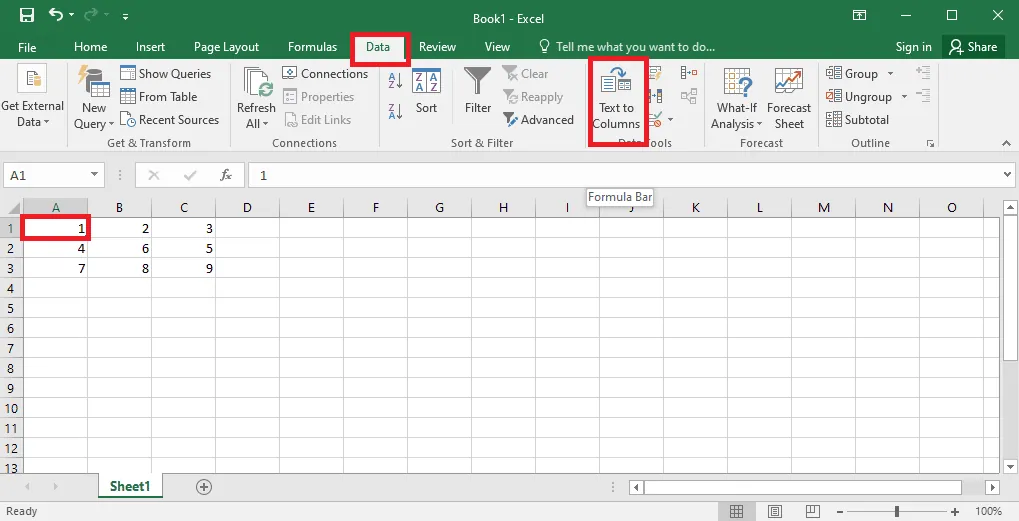
4. Wybierz komórkę A1, przejdź do zakładki "Dane" i kliknij opcję "Tekst jako kolumny" w sekcji Narzędzia danych.
 </p
</p
