Kompletny przewodnik po REGEX w Google Search Console
Google Search Console (GSC) to nieocenione narzędzie dla specjalistów SEO, umożliwiające dogłębną analizę efektywności strony internetowej.
Wprowadzenie wyrażeń regularnych (REGEX) znacząco usprawniło proces wyciągania wniosków z danych, a także stało się źródłem nowych inspiracji dla twórców treści.
Funkcjonalność REGEX, długo wyczekiwana w obszarze analityki internetowej, umożliwiła precyzyjne filtrowanie specyficznych elementów z adresów URL, co wcześniej byłoby bardzo trudne lub wręcz niemożliwe.
W dalszej części artykułu skupimy się na praktycznych poradach i wskazówkach dotyczących zastosowania REGEX w Google Search Console. Zaprezentujemy również zbiór operatorów, które w połączeniu z kodami REGEX pozwolą na uzyskanie zamierzonych wyników analizy.
REGEX, czyli wyrażenia regularne: wprowadzenie
Google Search Console to darmowa platforma udostępniana webmasterom do zarządzania efektywnością ich witryn. Oferuje ona rozbudowane raporty dotyczące współczynnika klikalności (CTR), liczby wyświetleń, kliknięć oraz pozycji słów kluczowych, które pomagają w ocenie skuteczności strategii SEO.
Wcześniej jednak, filtry do analizy efektywności adresów URL miały swoje ograniczenia. GSC umożliwiało eksport jedynie 1000 wierszy do analizy, a filtrowanie ograniczało się do określonych sekcji URL, jak ścieżka, właściwości domeny lub przedrostki. Brakowało zaawansowanych opcji filtrowania, pozwalających na wyszukiwanie skomplikowanych ciągów i ich wariantów.
Wyrażenia regularne (Regex) stanowią przełomowe uzupełnienie funkcjonalności GSC. Ich celem jest zapewnienie specjalistom SEO możliwości bardziej efektywnego wykorzystania Google Search Console do analizy wydajności i funkcjonowania strony internetowej.
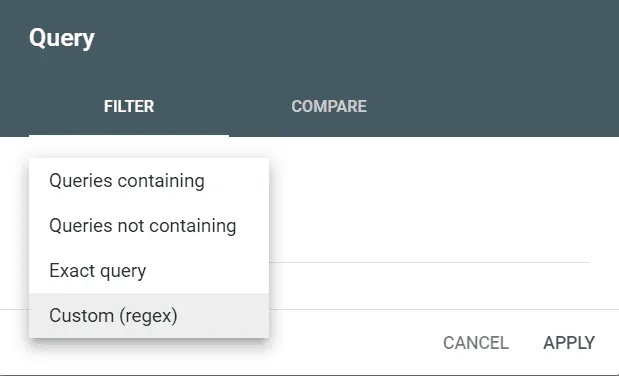
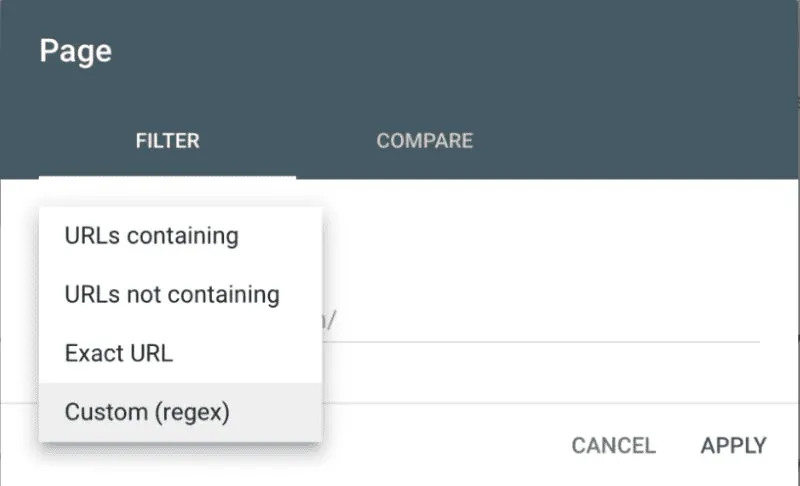
Regex umożliwia dogłębne zrozumienie kluczowych aspektów SEO strony poprzez stosowanie specjalnych kodów w filtrach zapytań i stron. Kody te składają się z metaznaków, tworzących ciąg znaków powiązany z określonym parametrem filtrowania. Po wprowadzeniu wyrażenia regularnego w panelu, wyświetlony zostaje wynik, który można zapisać do celów informacyjnych.
Korzyści z używania Regex w GSC
Podstawowym celem korzystania z Google Search Console jest analiza techniczna strony. Specjaliści SEO używają wielu narzędzi i technik, by opracować strategię optymalizacji, która zapewni wysoką pozycję w wynikach wyszukiwania i zwiększy ruch na stronie.
Regex stanowi dodatkowe wsparcie w procesie gromadzenia istotnych danych, które można wykorzystać do udoskonalenia strategii optymalizacji. Poniżej prezentujemy, jakie informacje można uzyskać dzięki raportom z wykorzystaniem Regex.
✨ Dzięki kodom Regex w zapytaniach możemy zweryfikować liczbę wyszukiwań konkretnych słów kluczowych lub fraz, co jest inspiracją do tworzenia nowych treści na bloga i zwiększenia ruchu.
✨ Kody Regex znacząco oszczędzają czas specjalistom SEO pracującym w dużych firmach, gdzie analizuje się ogromne ilości danych. Sortowanie zapytań i stron według określonych kryteriów wymaga jedynie kilku metaznaków i ciągów znaków we właściwej składni.
✨ Jedną z kluczowych zalet jest możliwość operowania na kombinacjach słów, zdań i adresów URL. Należy pamiętać o umieszczeniu znaków we właściwej kolejności, by stworzyć poprawny kod Regex.
✨ Regex dostarcza lepszy wgląd w działanie witryny, identyfikując strony o wysokiej i niskiej skuteczności, a także prezentując aktualne trendy.
✨ Kody Regex można wykorzystać w raportach niestandardowych do śledzenia przepływu ruchu na stronie internetowej w odniesieniu do konkretnych zapytań. Umożliwia to kierowanie zespołem w konkretnym kierunku.
Możemy ustawić wiele kombinacji znaków regularnych, aby zdefiniować kod i wykorzystać go do oceny skuteczności optymalizacji witryny.
Gdzie stosować Regex w Google Search Console?
Aby wykorzystać funkcję Regex w GSC, konieczne jest posiadanie dostępu do własnej witryny. Jest to warunek niezbędny, ponieważ nie można dodać jej jako własności w Google Search Console w ramach innej procedury analitycznej.
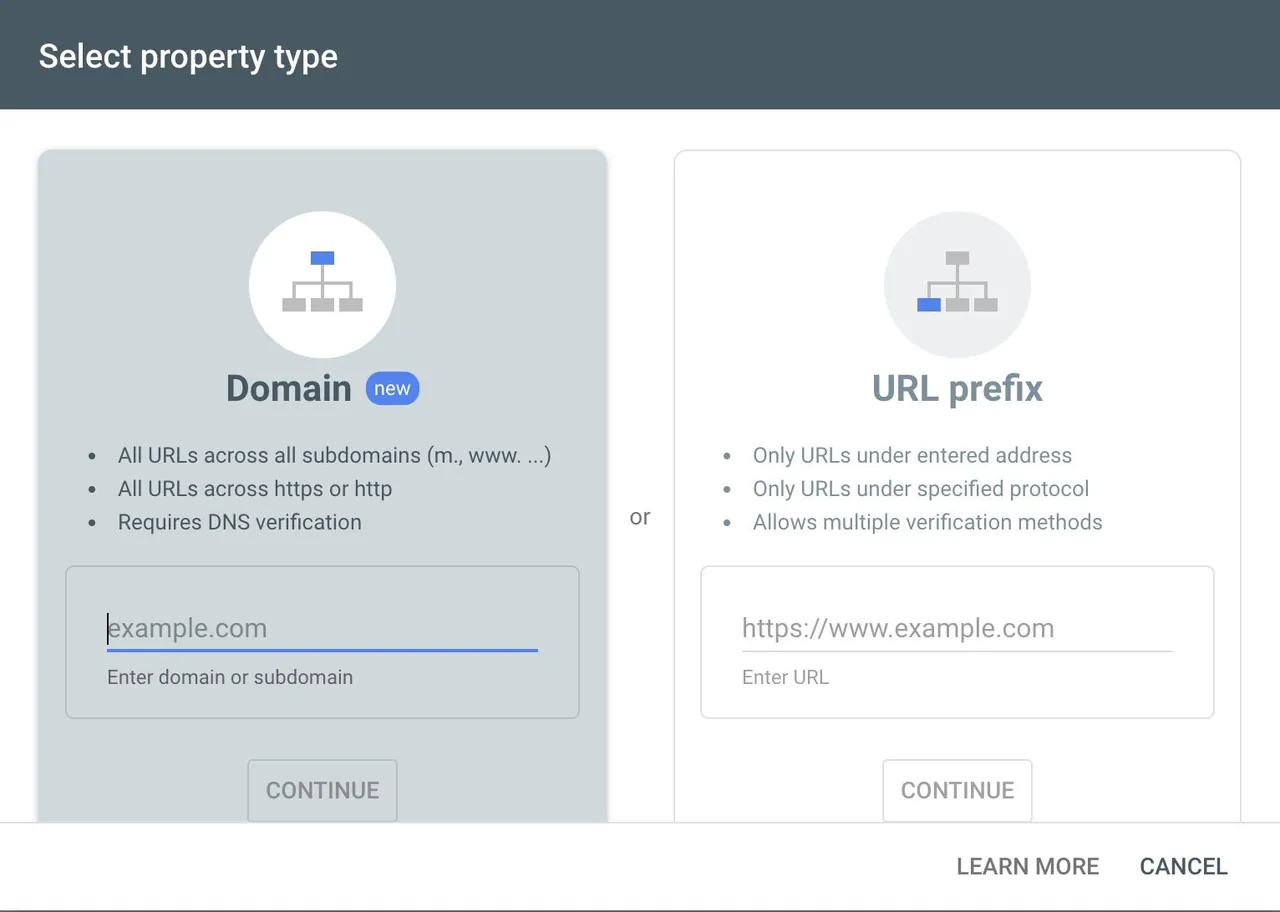
Należy zalogować się do Google Search Console, używając swojego konta Gmail, a następnie dodać właściwość w opcji na pasku bocznym. Właściwość to strona internetowa, której jesteśmy właścicielem lub na której mamy pozwolenie do dostępu w konsoli.
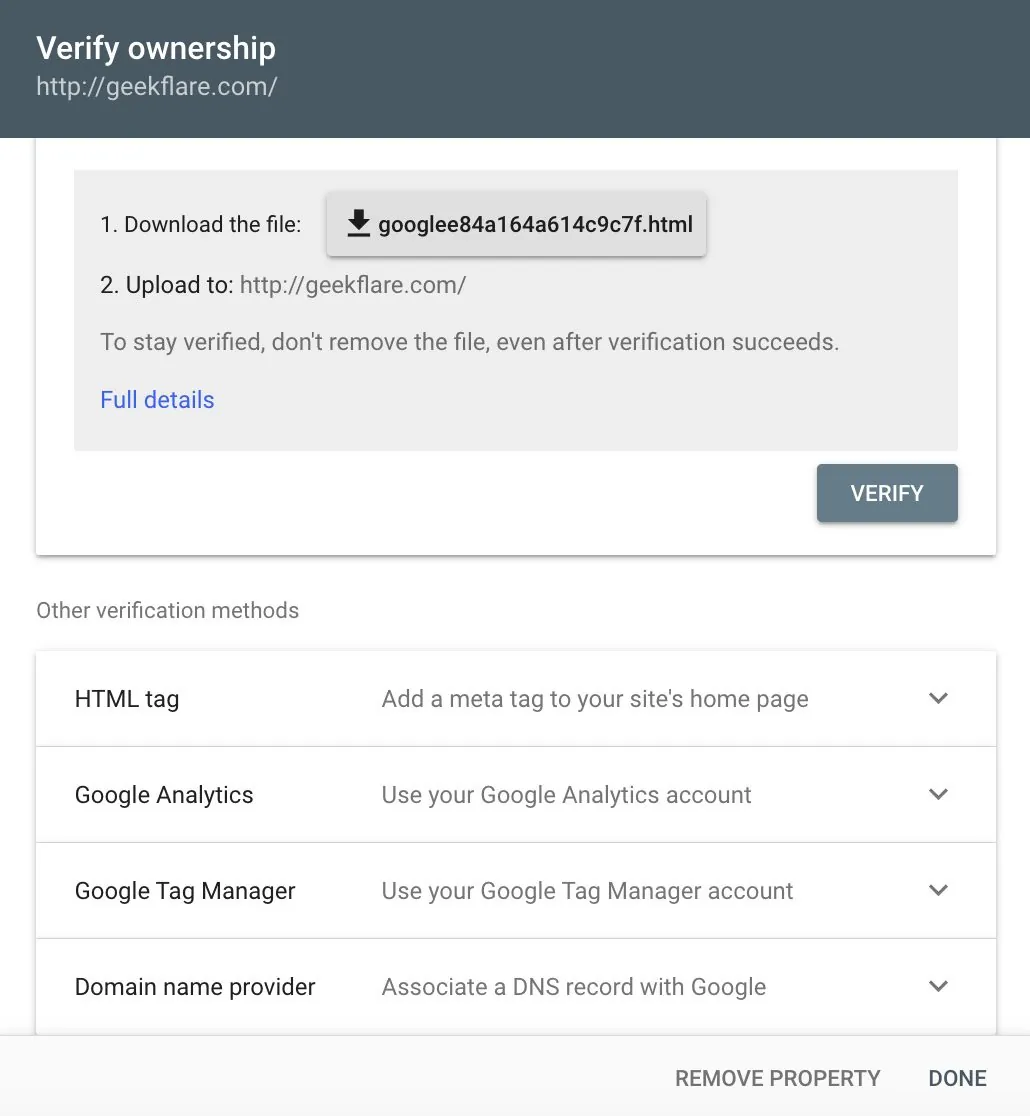
Po dodaniu witryny internetowej lub dowolnego adresu URL panel poprosi o jej weryfikację. Procedura weryfikacji jest przedstawiona w panelu. Po jej zakończeniu możemy wybrać swoją nieruchomość, by rozpocząć dalsze działania.
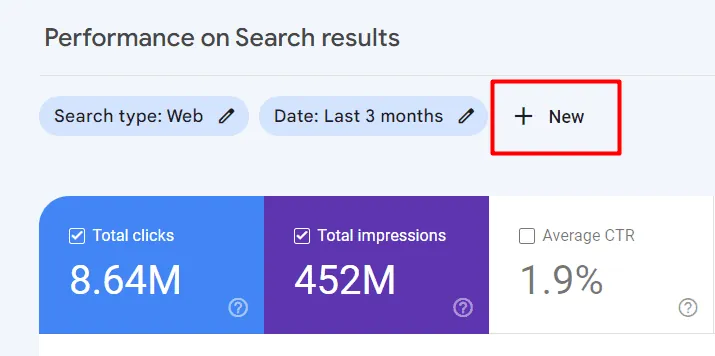
W wybranej właściwości klikamy parametr "Wydajność", a następnie przycisk "Nowy" nad wykresem, by wyświetlić opcje filtrowania.
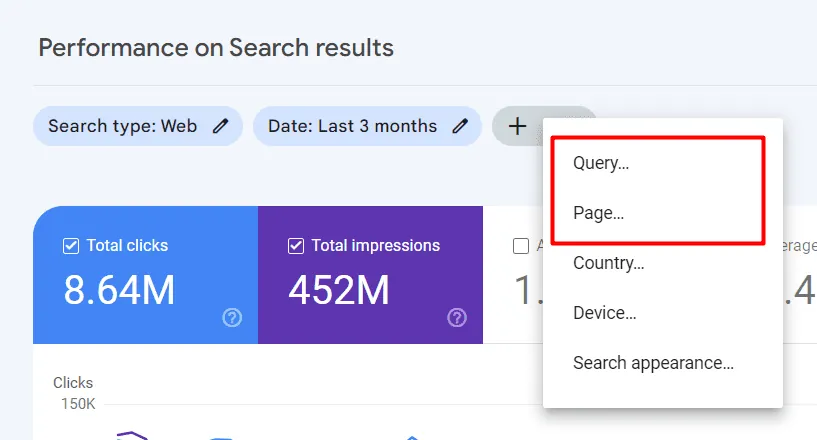
Możemy wybrać zapytanie lub strony, by móc stosować kod Regex do filtrowania wyników.
Wyjaśnienie znaków Regex
Do filtrowania zapytań i stron w Google Search Console wykorzystuje się różne zestawy znaków. Każdy metaznak ma odmienne znaczenie w filtrze. Zrozumienie ich działania znacząco ułatwi analizę GSC za pomocą Regex.
W poniższej tabeli, na przykładach, wyjaśniamy znaczenie wybranych symboli i znaków używanych w kodzie Regex.
| Characters | Usage |
| () | Te nawiasy służą do grupowania znaków lub wyrażeń, nazywanych także grupami przechwytywania. (Geek) |
| [^\mobile] | Jeśli po daszku następuje ukośnik odwrotny, odfiltrowane zostaną adresy URL zawierające podane słowo "mobile". |
| | | To symbol OR, używany w celu zastosowania opcji w kodzie. Telefon komórkowy|PC Raport pobierze wszystkie strony zawierające którekolwiek z dwóch słów. |
| ^ | Symbol karetki pasuje tylko do słowa lub frazy znajdującej się na początku ciągu. ^Mobile Otrzymasz wszystkie strony internetowe ze słowem „Mobile” na początku tytułu lub tagu. |
| $ | Symbol dolara będzie pasował tylko do słowa lub frazy na końcu ciągu. Mobile$ Otrzymasz wszystkie strony internetowe ze słowem „Mobile” na końcu tytułu lub tagu. |
| . | Symbol kropki służy do dopasowywania dowolnego pojedynczego znaku w ciągu. to. Otrzymasz wszystkie strony internetowe ze słowem „Mobile” na końcu tytułu lub tagu. |
| \ | Ukośnik odwrotny służy do pomijania dosłownego znaczenia znaków.\d Dopasowuje strony z cyframi 0-9. |
| [xyz] | Ten kod RegEx dopasuje zapytanie do jednego lub wszystkich znaków w nawiasie; x, y lub z. Mobile[xyz] Kod będzie pasował do stron zawierających wszystkie słowa w kombinacji mobile z x, y lub z, np. mobilex, mobilezy i mobilezxy. |
| [c-m] | Ten kod RegEx dopasuje zapytanie do dowolnej małej lub dużej litery z zakresu od c do m. Mobile[c-m] Kod będzie pasował do stron zawierających wszystkie słowa w kombinacji mobile z literami od c do m; takie jak mobilecjg, mobileeel, mobilecdf. |
| [3-7] | Ten kod RegEx dopasuje zapytanie z liczbami z zakresu od 3 do 7. Mobile[0-9] Kod będzie pasował do stron zawierających wszystkie słowa w kombinacji mobile z liczbami od 3 do 7; takie jak mobile73, mobile654, mobile445. |
| [\w] | Spowoduje to dopasowanie każdego słowa na stronach internetowych z literami „do”, takimi jak w kierunku, do, do. [\w]*Mobilny[\w] Ukośnik odwrotny, po którym następuje mała litera „w” wewnątrz nawiasu. Spowoduje to dopasowanie dowolnego słowa lub znaku, takiego jak litera (zarówno mała, jak i wielka), cyfra lub znak podkreślenia. |
| [\W] | Ten kod Regex dopasuje strony zawierające słowo „mobile” do innych słów, zarówno w tytule, meta, jak i w artykule, np. telefon komórkowy, aplikacja mobilna [\W]*Mobilny[\W] Ukośnik odwrotny, po którym następuje wielka litera „W” wewnątrz nawiasu. To będzie pasować do wszystkiego z wyjątkiem liter i cyfr. Oznacza to puste znaki spacji i symbole takie jak; ?:#@$%. |
Można tworzyć różnorodne kody, wykorzystując wymienione znaki, aby filtrować skomplikowane zapytania w GSC.
Określone wyrażenia regularne w Google Search Console
W Google Search Console możemy używać metaznaków do tworzenia unikalnych wzorców lub kodów o konkretnych przeznaczeniach. Oto kilka przykładów, które można przetestować na swoim portalu GSC.
🔶 ^[\w\W\s\S]{70,}$
Ten kod dopasowuje wszystkie słowa, cyfry, znaki specjalne, symbole, spacje i inne znaki na stronie. Kwantyfikator "70" oznacza, że ciąg ma długość minimum 70 znaków.
Przykład: Kody tego typu wykorzystuje się podczas weryfikacji haseł, sortowania list produktów z długim opisem, lub w innych podobnych sytuacjach.
🔶 (\w+\s){6,}\w+
Ten kod Regex składa się z trzech sekcji. Służy do wyszukiwania słów i liczb oddzielonych spacjami. Kod pobierze ciągi znaków, które zawierają co najmniej 6 słów, na przykład: „Ciągi składające się z co najmniej 6 słów lub dłuższe.”
Przykład: Tego rodzaju kody są użyteczne przy filtrowaniu artykułów o długich tytułach, obszernych komentarzy w mediach społecznościowych itp.
🔶 ^(kto|co|gdzie|kiedy|dlaczego|jak)[“ “]
Ten kod Regex jest prosty i przydatny dla blogerów i specjalistów SEO. Dopasowuje wszystkie zapytania w wyszukiwarkach, które zaczynają się od któregoś z tych słów: kto, co, gdzie i inne wymienione w nawiasach. Ciąg powinien zaczynać się od jednego z tych słów, po którym następuje spacja. Nie pobierze zatem słów takich jak „jednakże”, „cały” itp.
Przykład: Te kody nadają się do analizy trendów rynkowych i dyskusji użytkowników, w celu generowania nowych pomysłów na treści.
🔶 „kto|co|gdzie|kiedy|dlaczego|jak”
Kod ten, podobnie jak poprzedni, będzie dopasowywał wszystkie ciągi zawierające którekolwiek z tych słów, niezależnie od tego, czy ciąg zaczyna się od nich, czy nie.
Przykład: Kod ten jest przydatny do wyróżniania niejasnych stwierdzeń, filtrowania danych wejściowych użytkownika itp.
🔶 .*
Metaznak kropki, po którym następuje gwiazdka, jest często nazywany symbolem wieloznacznym, ponieważ może zostać użyty do dopasowania dowolnego ciągu znaków.
Przykład: Regex .*Android.* pobierze wszystkie strony w witrynie, które zawierają słowo "Android". Kod .* zastosowany bezpośrednio w filtrze, wyodrębni wszystkie strony, które pojawiły się w wynikach wyszukiwania w danym miesiącu.
🔶 [^\/\.\-:0-9A-Za-z_]
Po symbolu karetki następuje ukośnik odwrotny, który wyklucza znaki wskazane w kodzie. W tym przypadku kod dopasuje ciągi, które nie zawierają ukośnika, cyfr, kropki, dwukropka, łącznika ani liter alfabetu (małych i wielkich).
Przykład: Kod ten jest przydatny do wychwytywania adresów URL, metaopisów lub treści, które zawierają znaki specjalne, takie jak &%$@.
🔶 ?i)(((jest|są).(marka|strona|firma)|(marka|strona|firma.(jest|są)).*(szumowiny|niezawodne))
To złożony kod Regex, który ma kilka sekcji. Znak "?i" na początku kodu oznacza flagę ignorowania wielkości liter. Kod dopasuje więc ciągi, niezależnie od tego, czy są zapisane wielkimi, czy małymi literami. W nawiasach występują słowa oddzielone znakami (OR).
Kod Regex wykryje zapytania, niezależnie od wielkości liter, które zawierają słowa "jest" lub "są", "marka", "firma" lub "strona", a także "szumowina" lub "niezawodny".
Przykład: Ten kod Regex można zastosować do znalezienia wzorca zapytań klientów. Pomoże on dowiedzieć się, czy witryna ma pozytywne, czy negatywne opinie.
🔶 (kwd1|kwd2).*
Jest to przykład uproszczonego kodu wyrażenia regularnego rozłącznego, gdzie GSC odfiltruje strony lub zapytania zawierające słowo "kwd1" lub "kwd2", po których następują kolejne litery lub cyfry.
Przykład: Możemy użyć tego wzorca, aby wyodrębnić strony, które zawierają któreś z tych słów powiązane z innymi słowami lub liczbami w adresie URL, tytule, meta lub treści.
🔶 (Słowo kluczowe1 ORAZ Słowo kluczowe2)
Ten kod to przykład wyrażenia koniunkcji. Operator "AND" używany w kodzie Regex umożliwia uzyskanie stron, które zawierają oba słowa w podanej kolejności.
Przykład: Możemy użyć tego kodu w GSC, aby wyszukać strony, których tytuł lub meta zawierają dwa określone słowa w tej samej kolejności.
🔶 „słowo kluczowe1 słowo kluczowe2”
Kod ten umożliwia dopasowanie frazy, czyli dokładnej kolejności słów na stronie internetowej.
Przykład: Zastosowanie kodu w GSC umożliwia wyszukanie stron z tytułem, opisem lub treścią zawierającą określoną frazę.
🔶 (Słowo kluczowe 1 | Słowo kluczowe 2)
Ten kod składa się z dwóch słów oddzielonych znakiem potoku. GSC wyświetli strony, które zawierają "Słowo kluczowe 1" lub "Słowo kluczowe 2", ale nie oba.
Przykład: Kod pozwala wyodrębnić strony, które zawierają jedno z dwóch lub więcej słów oddzielonych znakiem kreski.
🔶 (Słowo kluczowe1)\b(Słowo kluczowe2)\b
Ten kod Regex zawiera dwa określone słowa ze znakiem "\b", który jest symbolem granicy słowa. Kod wyświetli strony, na których te dwa słowa występują obok siebie bez żadnego innego słowa, cyfry lub znaku pomiędzy nimi.
Przykład: Używając tego kodu w filtrze GSC możemy dowiedzieć się o stronach, które mają dwa oddzielne słowa obok siebie.
🔶 (Słowo kluczowe1)\w+(Słowo kluczowe2)
Kod zawiera dwa słowa z metaznakiem "\w+" między nimi, gdzie "w" jest małą literą. Pobierze on wszystkie strony, które zawierają te dwa słowa, niezależnie od liczby słów pomiędzy nimi.
Przykład: Można użyć tego kodu, by wyodrębnić strony w witrynie, które zawierają co najmniej te dwa słowa w dowolnym miejscu tytułu, treści lub meta.
🔶 (Słowo kluczowe)\bfraza
Jest to prosty kod Regex, który dopasowuje ciąg znaków do słowa w nawiasach, po którym następuje słowo "fraza". Metaznak "\b" oznacza granicę słowa, czyli brak innych znaków pomiędzy podanymi słowami.
Przykład: Kod w GSC wyświetli strony zawierające podane słowa w serii, na przykład "fraza kluczowa".
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Ten kod Regex zawiera listę adresów URL "a, b, c, e, g…" oddzielonych znakiem kreski. Odfiltruje on ciągi znaków z każdym z tych adresów URL.
Przykład: Tego typu wzorce możemy użyć w panelu GSC, by uzyskać strony z określonymi adresami URL w tytule lub artykule.
🔶 ^(jabłko|piłka|kot|farma kaczek)$
Kod sugeruje dopasowanie początku ciągu do jednego z podanych słów: "farma jabłek, piłek, kotów lub kaczek", ponieważ są one oddzielone znakiem pionowym. Dodatkowo, kod zapewnia brak innych słów czy znaków w ciągu.
Przykład: Kod ten możemy użyć, by uzyskać informacje o stronach, które na początku mają określone słowa kluczowe.
🔶 .*\/$
Kod Regex ma na celu przechwycenie dowolnego ciągu znaków, zarówno słów, jak i liczb, który kończy się ukośnikiem.
Przykład: Kod ten można wykorzystać do dopasowania stron, których adresy URL kończą się ukośnikiem.
🔶 .(najlepsza|najlepsza|vs|recenzja).*
Kod ten dopasuje ciągi, które zaczynają się kropką, zawierają jedno z podanych słów (oddzielonych kreską) i inne słowa, liczby lub znaki specjalne.
Przykład: Wzorzec ten możemy wykorzystać w raportach komercyjnych, by zrozumieć aktualne trendy rynkowe.
🔶 (kup|tanie|cena|zakup|zamów).
Kod ten dopasuje ciągi, w których jedno z podanych słów jest oddzielone kreską, a po nim następują inne słowa, liczby lub znaki.
Przykład: Kod ten przyda się do dopasowania wyszukiwań transakcyjnych lub zapytań związanych z produktami w Twojej witrynie.
🔶 (twarz(b|be)ook) 🔶 (f(a|e)ce(b|be)ook 🔶 (fa(c|s)(e|i)book)
Kody te zawierają kombinacje słów w nawiasach i znaki kreski pomiędzy nimi.
Pierwsze wyrażenie regularne dopasuje ciągi, które zawierają słowo "twarz", po którym następuje "b" lub "be" i kończy się na "ook". Otrzymane strony będą zawierały słowo "facebook" lub "facebeook".
Drugie wyrażenie regularne dopasuje ciągi zawierające słowo "f", po którym następuje "a" lub "e", potem "ce", a następnie "b" lub "be" i kończy się na "ook". Otrzymane strony będą zawierały dowolną kombinację słów, np. "facebook", "fecebook", "facebeook" lub "fecebeook".
Trzecie wyrażenie regularne dopasuje ciągi zawierające słowo "fa", po którym następuje "c" lub "s", potem "e" lub "i" i kończy się na "book". Otrzymane strony będą zawierały dowolną kombinację, np. "Facebook", "Facibook", "Fasebook" lub "Fasibook".
Przykład: Kody te pozwalają na dopasowanie potencjalnych błędów ortograficznych na stronach internetowych.
🔶 .wp-.
Podany kod dopasuje ciągi znaków zawierające kropkę, po której następuje "wp-", a następnie kolejne znaki.
Przykład: Kod ten nadaje się do wyodrębniania stron z adresami URL WordPress.
🔶 .*/url-1/.* kontra .*/url-2/.*
Podany kod ma dwa różne adresy URL z porównawczym znakiem Regex. Pozwala na pobranie dwóch określonych adresów URL z witryny w celu porównania danych.
Przykład: Możemy użyć tego kodu, aby porównać ruch, liczbę użytkowników i inne dane między dwoma konkretnymi stronami internetowymi w witrynie.
Inne rzadziej stosowane wyrażenia regularne
🔺 (?i)\bsłowo kluczowe\b
Ten kod dopasuje ciąg znaków zawierający słowo "słowo kluczowe". Wyszukiwanie odbywa się bez względu na wielkość liter na stronach internetowych.
🔺 „fraza”
Ten kod po prostu dopasuje strony zawierające słowo "fraza".
🔺 \w{5}
Kod dopasuje zapytania zawierające ciągi znaków składające się z 5 słów.
🔺 \d{3}
Ten kod dopasuje zapytania zawierające dokładnie 3 cyfry.
🔺 ([^” “]*)
Ten kod Regex dopasuje ciągi znaków, które nie zawierają żadnych znaków w cudzysłowie.
🔺 (?i)\b(słowo kluczowe1|słowo kluczowe2|słowo kluczowe3)\b
Ten kod dopasuje ciągi znaków, w których którekolwiek ze słów jest oddzielone znakiem kreski, literami (małymi lub wielkimi).
🔺 \W+
Kod ten dopasuje dowolną liczbę znaków, które nie są wyrazami, zazwyczaj są to znaki specjalne.
🔺 \d{3,5}
Kod dopasuje ciągi znaków zawierające liczby składające się z 3 do 5 cyfr.
🔺 \b\w+\b
Kod dopasuje dowolną liczbę znaków do granic słowa.
Podsumowanie
Wyszukiwarka Google stała się ogromnym źródłem wiedzy dzięki wprowadzeniu kodów Regex w filtrach wydajności. Aby skutecznie wyodrębniać dane analityczne, niezbędne jest zrozumienie struktury tych kodów.
Możemy utworzyć wiele kodów Regex w panelu GSC, by uzyskać szczegółowe informacje na temat skuteczności witryny i wykorzystać je do ulepszania strategii.
Zachęcamy do zapoznania się ze wskazówkami dotyczącymi wyszukiwania Google, które pomogą w bardziej efektywnym wyszukiwaniu informacji online.
