Użyj narzędzi inżynierskich Chaos, aby sprawdzić niezawodność produkcji
Sprawdźmy, jak możesz zwiększyć niezawodność swojej produkcji, korzystając z narzędzi inżynierii chaosu.
Inżynieria chaosu to podejście, w którym celowo testujesz swój system lub aplikację, aby zidentyfikować jego słabe punkty i potencjalne awarie. To pozwala odkryć scenariusze, które mogły umknąć Twojej uwadze podczas procesu projektowania. Poprzez celowe wywoływanie zakłóceń w systemie, ujawniasz jego podatności, co umożliwia wprowadzenie ulepszeń i podniesienie poziomu odporności systemu i aplikacji.
Wiele znanych firm, takich jak Netflix, LinkedIn i Facebook, stosuje inżynierię chaosu, aby lepiej zrozumieć swoje architektury mikrousług i systemy rozproszone. Dzięki temu mogą identyfikować potencjalne problemy zanim zgłoszą je użytkownicy, a następnie podejmować odpowiednie kroki naprawcze. W ten sposób te firmy są w stanie obsługiwać miliony użytkowników, zwiększać swoją wydajność i oszczędzać znaczące sumy pieniędzy 🤑.
Zalety inżynierii chaosu:
- Minimalizacja strat finansowych poprzez wczesne wykrywanie krytycznych problemów
- Zmniejszenie prawdopodobieństwa wystąpienia awarii systemów lub aplikacji
- Poprawa doświadczeń użytkowników dzięki minimalizacji zakłóceń i zapewnieniu wysokiej dostępności usług
- Lepsze zrozumienie systemu i zwiększenie pewności co do jego działania
Jak bardzo jesteś przekonany o niezawodności swojej produkcji? Czy Twój system jest naprawdę odporny na nieprzewidziane zdarzenia?
Przekonajmy się, analizując popularne narzędzia do testowania chaosu.
Chaos Mesh
Chaos Mesh to rozwiązanie do zarządzania inżynierią chaosu, które wprowadza zakłócenia w różnych warstwach systemu Kubernetes. Dotyczy to kontenerów (podów), sieci, systemu wejścia/wyjścia i jądra. Chaos Mesh potrafi automatycznie wyłączać pody Kubernetes i symulować opóźnienia. Może zakłócać komunikację między urządzeniami oraz imitować błędy odczytu i zapisu. Umożliwia planowanie zasad eksperymentów i określanie ich zakresu. Eksperymenty te są definiowane za pomocą plików YAML.
Chaos Mesh oferuje panel kontrolny do analizy wyników eksperymentów. Działa na platformie Kubernetes i jest kompatybilny z większością platform chmurowych. Jest to projekt open-source, który niedawno został przyjęty do inkubatora CNCF. Dzięki zastosowaniu zasad inżynierii chaosu, możesz włączyć Chaos Mesh do swojego procesu DevOps, aby tworzyć aplikacje o zwiększonej odporności.
Kluczowe cechy Chaos Mesh:
- Proste wdrożenie w klastrach Kubernetes bez konieczności modyfikacji logiki aplikacji
- Nie wymaga dodatkowych, specyficznych zależności
- Definiowanie obiektów chaosu za pomocą CustomResourceDefinitions (CRD)
- Dostęp do panelu kontrolnego umożliwiającego monitorowanie eksperymentów
Chaos Toolkit to otwarte i proste narzędzie, które pozwala na automatyzację eksperymentów inżynierii chaosu.
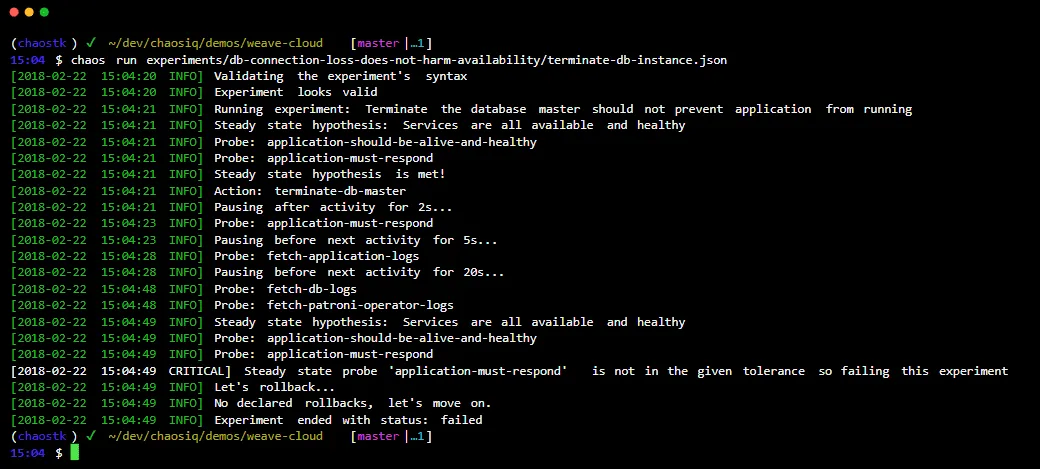
Chaos Toolkit integruje się z Twoim systemem za pomocą zestawu sterowników lub wtyczek, które obsługują m.in. AWS, Google Cloud, Slack i Prometheus.
Główne funkcje Chaos Toolkit:
- Zapewnia deklaratywne Open API do tworzenia eksperymentów chaosu niezależnie od dostawcy lub technologii
- Możliwość łatwej integracji z procesami CI/CD w celu automatyzacji
- Wsparcie komercyjne i korporacyjne dostępne również poprzez: ChaosIQ
ChaosKube
Jak sama nazwa wskazuje, narzędzie to jest przeznaczone dla środowiska Kubernetes.
Chaoskube to open-source'owe narzędzie, które cyklicznie wyłącza losowe pody w klastrze Kubernetes. Pomaga to zrozumieć, jak system zachowa się w przypadku awarii kontenera. Domyślnie narzędzie wyłącza pod w dowolnej przestrzeni nazw co 10 minut. Możesz jednak filtrować docelowe pody za pomocą przestrzeni nazw, etykiet, adnotacji i innych kryteriów. Chaoskube można łatwo zainstalować przy użyciu Helm.

Chaos Monkey
Chaos Monkey to narzędzie służące do weryfikacji odporności systemów w chmurze poprzez celowe wywoływanie awarii, aby zrozumieć, jak te systemy na nie reagują. Zostało stworzone przez firmę Netflix w celu przetestowania odporności i zdolności odzyskiwania ich infrastruktury AWS. Nazwa "Chaos Monkey" odnosi się do chaotycznego zachowania dzikiej małpy, która wywołuje zniszczenia, aby testować system na awarie.
Chaos Monkey dał początek nowej praktyce inżynieryjnej, znanej jako Inżynieria Chaosu. Został opracowany z założeniem, że lepiej wielokrotnie symulować awarie, aby uniknąć jednej, poważnej katastrofy.
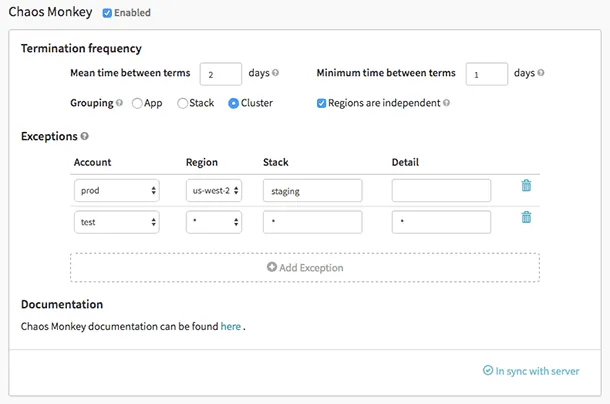
Funkcje Chaos Monkey:
- Pomaga przygotować się na nieoczekiwane awarie instancji.
- Promuje stosowanie redundancji w przypadku niespodziewanych zdarzeń
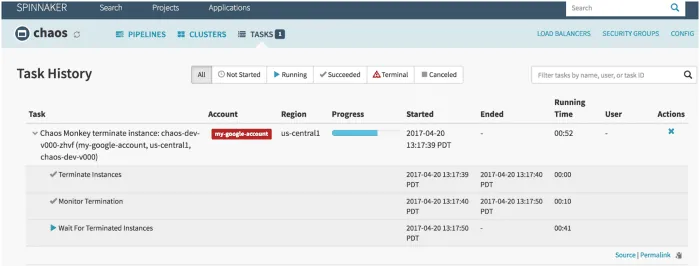
- Wykorzystuje Spinnaker do zapewnienia kompatybilności między różnymi chmurami
- Pozwala konfigurować harmonogram symulacji awarii
- Zintegrowany z govendor, aby umożliwiać dodawanie nowych zależności do Chaos Monkey
Simmy
Simmy to narzędzie do wstrzykiwania błędów, które integruje się z biblioteką Polly, służącą do obsługi odporności w platformie .NET. Umożliwia definiowanie zasad wprowadzania chaosu za pomocą Polly, w miejscach wykonywania kodu. Oferuje różne strategie, np. politykę wyjątków do wstrzykiwania błędów, politykę zachowania do wstrzykiwania nowego zachowania, które są losowo aktywowane.
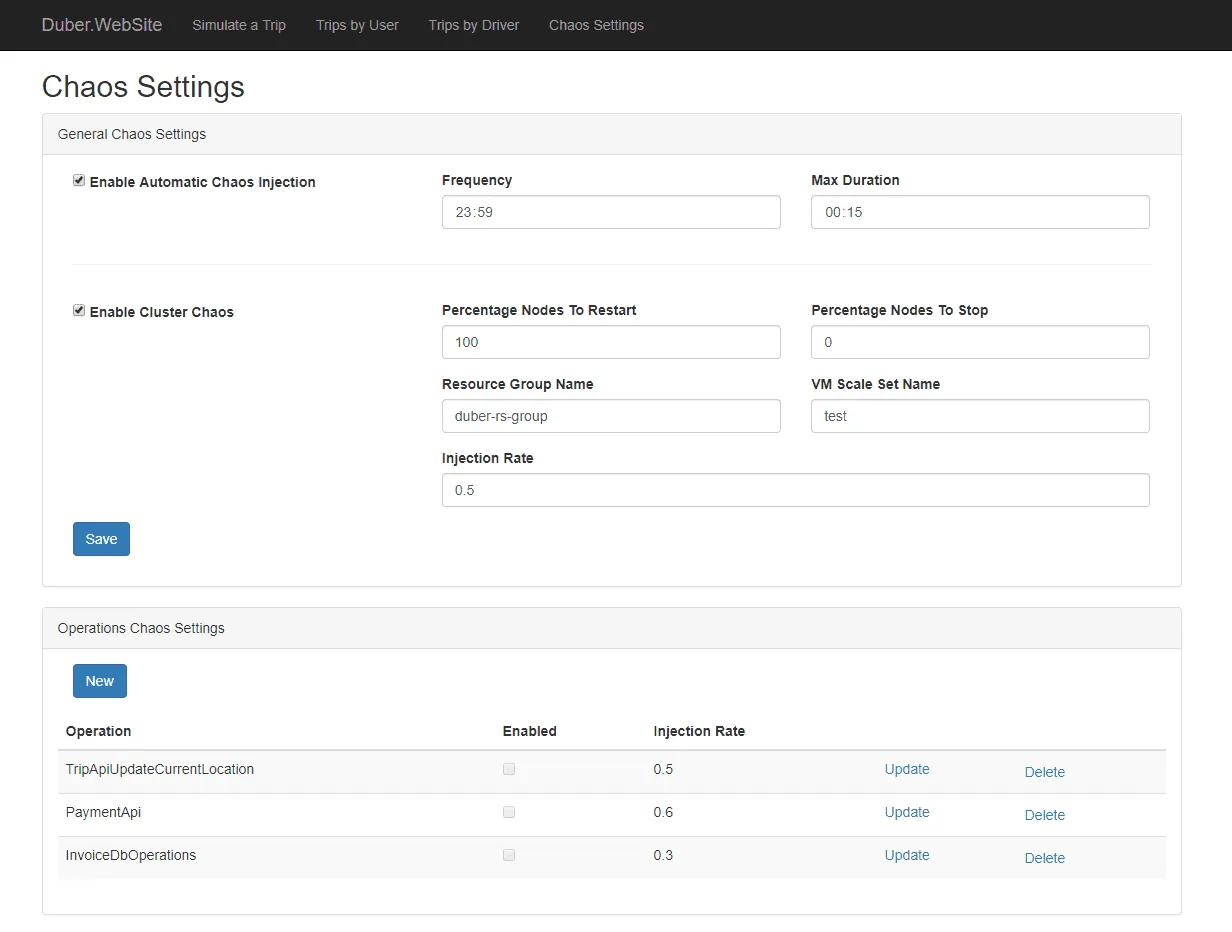
Kluczowe cechy Simmy:
- Umożliwia wprowadzanie chaosu za pomocą zasad Monkey lub Chaos
- Ułatwia testowanie potencjalnych awarii zależności
- Pozwala na szybki powrót do stanu roboczego i kontrolowanie zakresu wpływu awarii
- Jest gotowy do użycia w środowiskach produkcyjnych.
- Umożliwia definiowanie awarii w oparciu o czynniki zewnętrzne (np. awarie spowodowane globalną konfiguracją)
Pistol
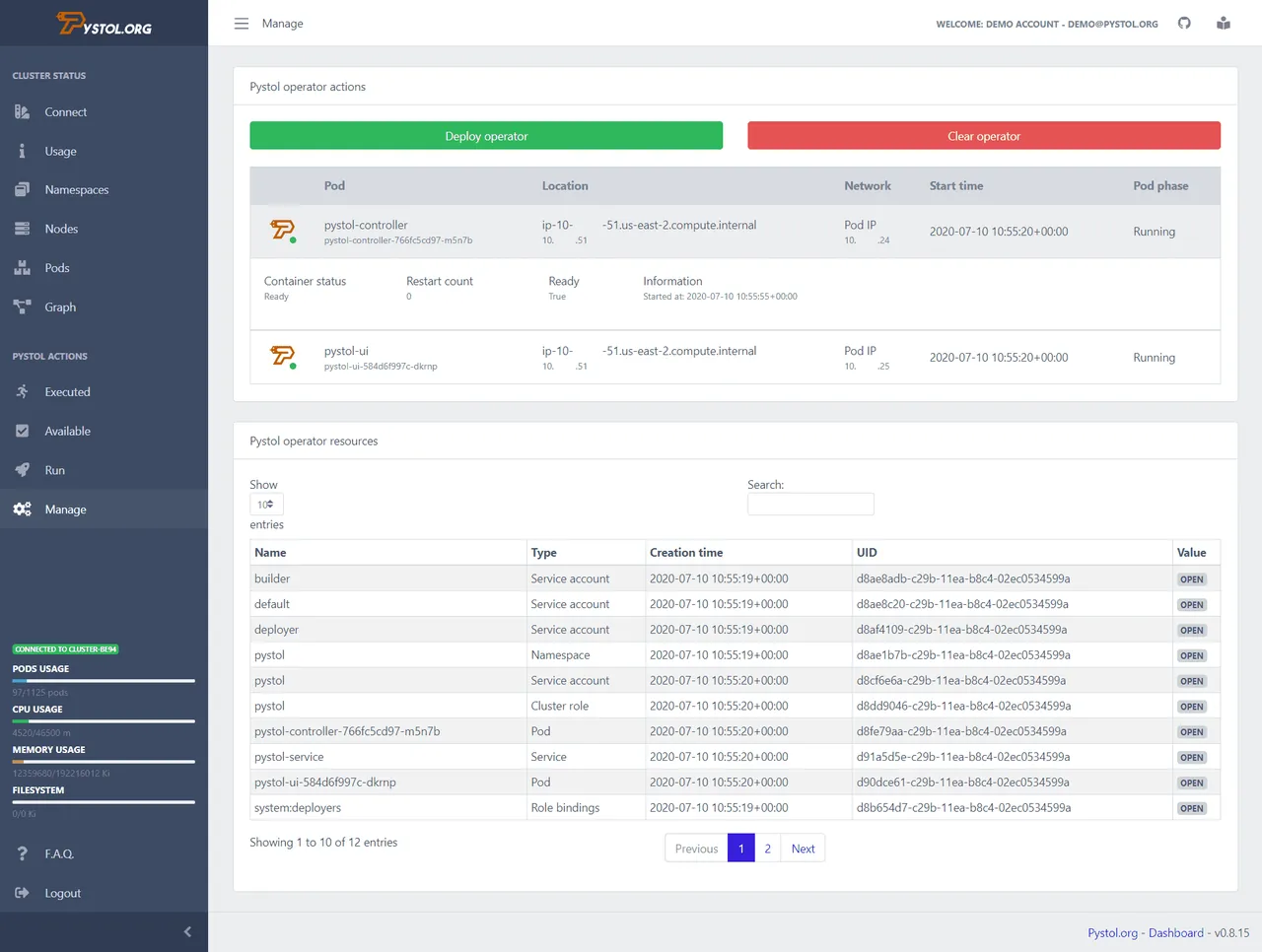
Pistol to narzędzie do wstrzykiwania błędów w środowiskach chmurowych. Monitoruje zdarzenia w ETCD za pośrednictwem operatorów Kubernetes. Po zainicjowaniu akcji wstrzykiwania błędu, operatorzy tworzą pody i uruchamiają zbiór zadań Ansible. Dzięki temu programiści nie muszą samodzielnie pisać kodu do wykonania akcji.
Pystol oferuje gotowe akcje do testowania systemu. Jednak programiści mają możliwość tworzenia własnych akcji za pomocą języków GoLang i Python.
Narzędzie udostępnia panel kontrolny CI/CD, który podsumowuje wszystkie operacje. Pystol można uruchomić lokalnie lub wdrożyć w kontenerze Docker. Pystol oferuje dwa interfejsy: interfejs sieciowy (Web UI) i interfejs CLI. Interfejs sieciowy jest zazwyczaj preferowanym rozwiązaniem.
Muxy
Muxy to serwer proxy do testowania odporności i zdolności do przetrwania awarii systemów rozproszonych. Może manipulować warstwą transportową (warstwa 4), sesją TCP (warstwa 5) i warstwą protokołu HTTP (warstwa 7).
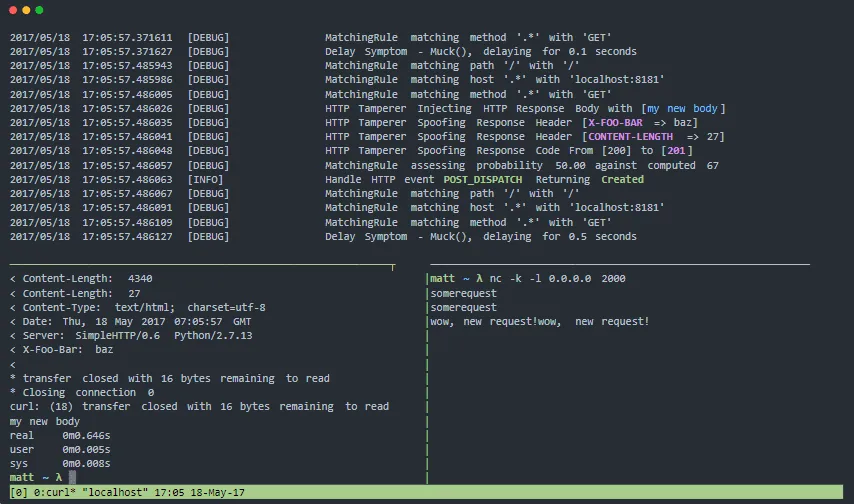
Funkcje Muxy:
- Modułowa architektura i łatwość rozbudowy
- Oficjalny kontener Docker
- Prosta instalacja, nie wymaga żadnych dodatkowych zależności.
- Idealne narzędzie do ciągłego testowania odporności
- Symuluje problemy z łącznością sieciową dla systemów rozproszonych i urządzeń mobilnych
Pumba
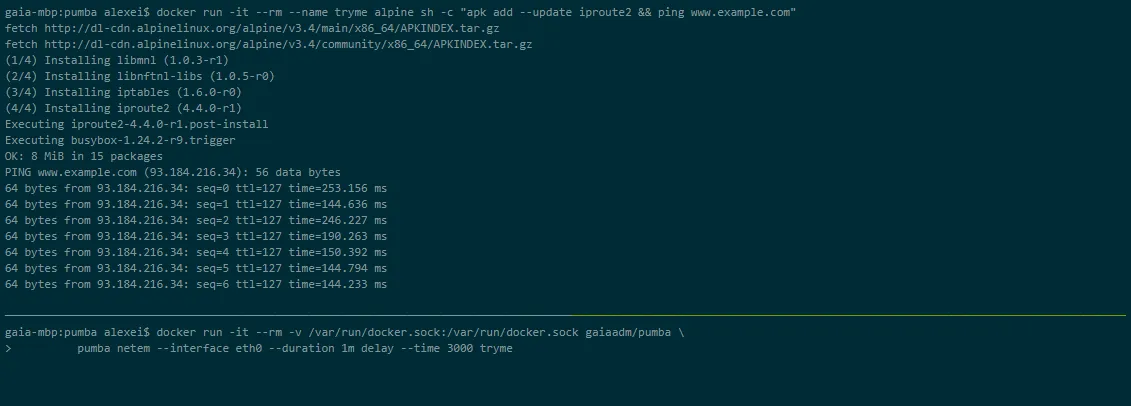
Pumba to narzędzie wiersza poleceń do testowania chaosu w kontenerach Dockera. Pumba umożliwia celowe wstrzymywanie kontenerów Dockera aplikacji, aby sprawdzić, jak na to zareaguje system. Możesz również przeprowadzać testy przeciążeniowe zasobów kontenera, takich jak procesor, pamięć, system plików, wejście/wyjście.
Pumbę można także uruchomić w klastrze Kubernetes. W tym celu musisz użyć DaemonSets, aby wdrożyć Pumbę na węzłach Kubernetes. Możesz użyć wielu kontenerów Pumba, aby uruchomić równocześnie kilka poleceń w ramach tego samego DaemonSet.
Ostrze Chaosu
ChaosBlade to narzędzie open-source do wstrzykiwania eksperymentów, stworzone przez firmę Alibaba. Wykorzystuje doświadczenia Alibaby w zakresie awarii systemów z ostatnich dziesięciu lat i najlepsze praktyki, aby im zapobiegać. Stosuje zasady inżynierii chaosu w celu sprawdzenia odporności systemów rozproszonych na awarie.
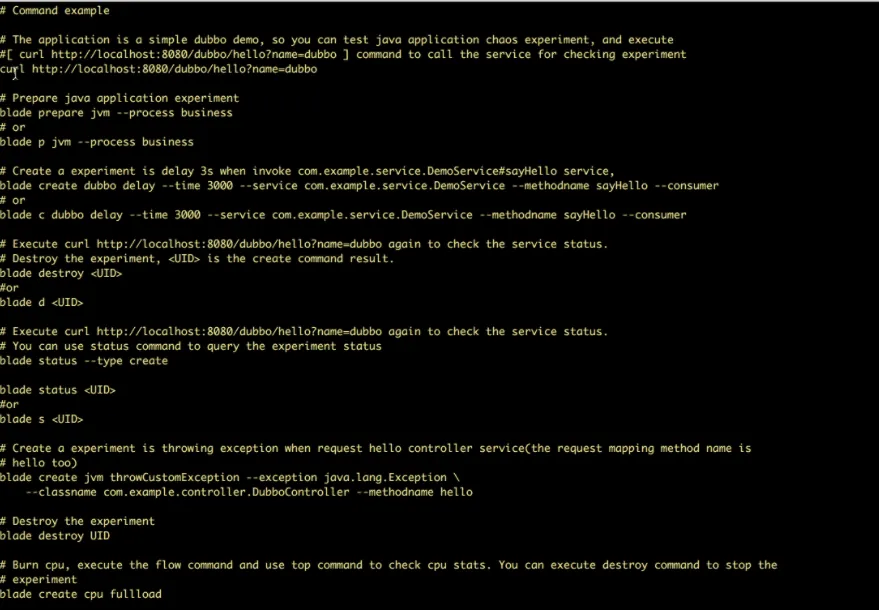
Kluczowe funkcje ChaosBlade:
- Dostępne scenariusze eksperymentalne dla różnych zasobów, takich jak procesor, sieć, pamięć, dysk.
- Scenariusze eksperymentalne dla węzłów, sieci i podów w platformie Kubernetes
- Proste polecenia CLI do wykonywania eksperymentów
Lakmus
Lakmus wdraża zasady inżynierii chaosu w środowiskach natywnych dla chmury. Jego celem jest dostarczenie kompletnego frameworku do identyfikowania słabych punktów w systemach Kubernetes i aplikacjach działających w tym środowisku.
Narzędzie opiera się na operatorze chaosu i CRD (CustomResourceDefinitions), co umożliwia stosowanie funkcji plug-and-play. Logika chaosu jest umieszczana w obrazie Dockera, który następnie jest integrowany z frameworkiem Lakmus za pomocą CRD.

Charakterystyka Lakmus:
- Pomaga inżynierom i programistom ds. niezawodności witryny w odkrywaniu słabości systemów Kubernetes
- Oferuje gotowe do użycia eksperymenty
- Dostarcza Chaos API do zarządzania przepływem chaosu
- Litmus SDK obsługuje Go, Python i Ansible do tworzenia własnych eksperymentów.
Gremlin
Gremlin wspiera inżynierów w budowaniu bardziej odpornego oprogramowania. Dostarcza platformę do bezpiecznego i prostego przeprowadzania eksperymentów inżynierii chaosu.

Gremlin umożliwia celowe wstrzykiwanie błędów do hostów lub kontenerów, niezależnie od ich lokalizacji (chmura publiczna lub własne centrum danych).
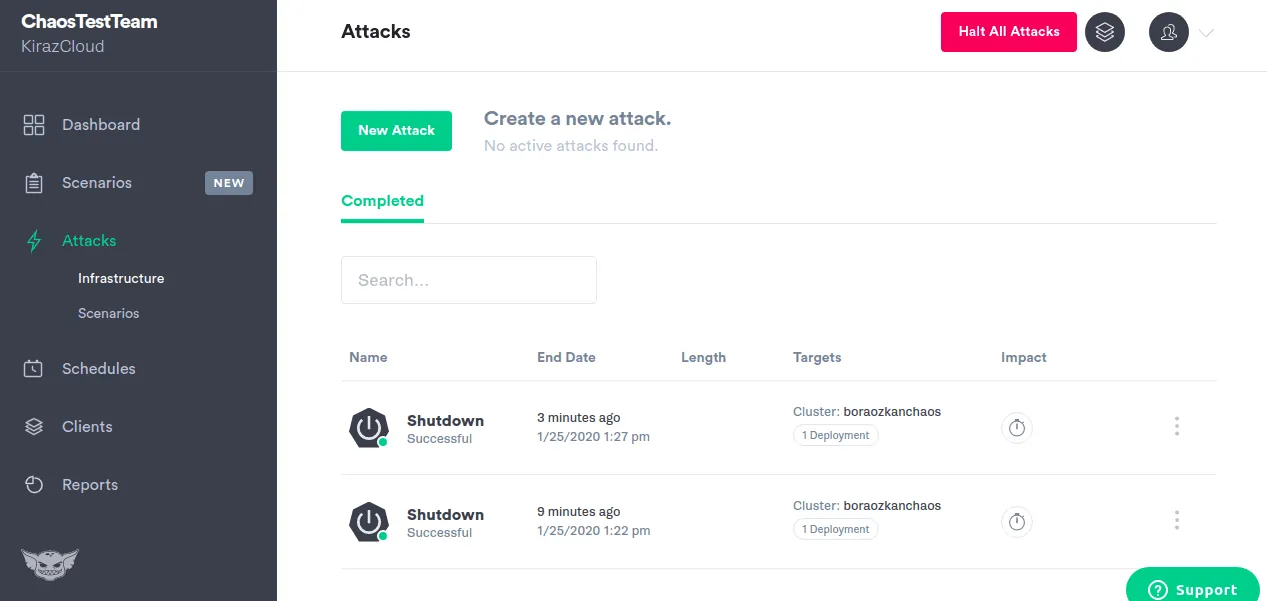
Funkcje Gremlina:
- Instaluje lekkiego agenta na hostach lub kontenerach w celu wprowadzania awarii
- Oferuje ponad 10 różnych rodzajów ataków na infrastrukturę
- Gremliny stanowe pozwalają manipulować czasem systemowym, wyłączać lub restartować hosty i zabijać procesy
- Gremliny sieciowe mogą wprowadzać opóźnienia, powodować utratę pakietów lub blokować ruch
- Ataki biblioteki Gremlin Alfi można konfigurować, uruchamiać i zatrzymywać za pomocą aplikacji internetowej, API lub CLI
- Pozwala precyzyjnie określić zakres wpływu ataku
- Umożliwia natychmiastowe zatrzymanie wszystkich ataków i przywrócenie systemu do stabilnego stanu
Steadybit
Steadybit ma na celu aktywne ograniczanie przestojów i zapewnia wgląd w problemy systemowe. Możesz uruchomić to narzędzie lokalnie w swojej infrastrukturze lub w chmurze jako usługę (SaaS).
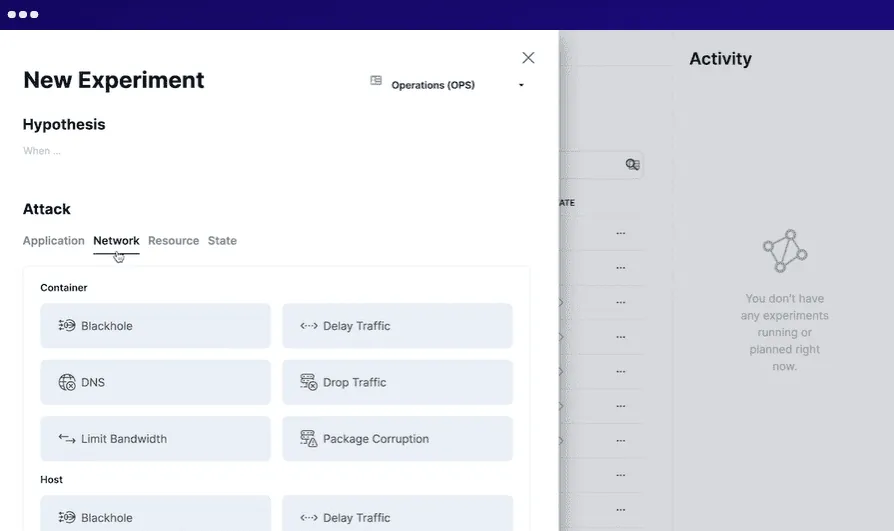
Steadybit umożliwia definiowanie scenariuszy, symulowanie eksperymentów, przeprowadzanie testów w środowisku produkcyjnym i automatyzację wszystkich eksperymentów. W systemie uruchamiane są inteligentne agenty, które wykrywają potencjalne problemy i słabości. Steadybit łatwo integruje się z wieloma systemami.
Podsumowanie
Nie bój się stosować zasad inżynierii chaosu i testować swojej produkcji, korzystając z wyżej wymienionych narzędzi. Pomogą Ci one wykryć wiele ukrytych słabości w Twoim systemie i zwiększyć jego odporność.
