Zrozumienie terminologii odzyskiwania po awarii — RTO, RPO, Failover, BCP i nie tylko
Plan naprawczy po wystąpieniu kryzysowej sytuacji jest fundamentalnym elementem, który każda organizacja powinna wdrożyć jeszcze zanim spotka ją nieszczęście.
W sektorze IT, proces ten rozpoczyna się od opracowania formalnego dokumentu, który definiuje plany, działania oraz procedury postępowania w przypadku wystąpienia katastrofy i jej skutków.
Katastrofa to niespodziewane zdarzenie, które może przybrać różne formy i wystąpić bez wcześniejszego ostrzeżenia. Gdy już do niej dojdzie, zarówno osoby fizyczne, jak i całe organizacje stają w obliczu rozmaitych trudności, obejmujących problemy finansowe oraz negatywny wpływ na doświadczenie użytkownika.
W sytuacji ataku, kluczowe jest przygotowanie, które pozwoli zminimalizować jego konsekwencje i przyspieszyć powrót do normalnej działalności. W tym kontekście, wdrożenie praktycznego planu odzyskiwania po awarii jest niezbędne, by zapobiec katastrofie lub przynajmniej ograniczyć jej negatywne skutki w zakresie komfortu użytkowania, kosztów i przestojów.
Ponadto, konieczne jest posiadanie gotowych planów, odpowiednich ludzi, strategii, sprzętu i systemów, aby umożliwić jak najszybszy powrót do normalnego funkcjonowania. Jednak aby to osiągnąć, trzeba dogłębnie zrozumieć, na czym polega odzyskiwanie po awarii.
W dalszej części artykułu szczegółowo omówię to zagadnienie, włączając w to kluczowe definicje związane z odzyskiwaniem po awarii. Dzięki temu, będziesz mógł skuteczniej stawić czoła przeciwnościom i wyjść z kryzysowej sytuacji silniejszym.
Zaczynajmy!
Czym jest katastrofa?
Katastrofa to nieprzewidziane wydarzenie, które może wystąpić w dowolnym miejscu, także w branży IT. Może być spowodowana czynnikami naturalnymi lub działalnością człowieka i zakłócać funkcjonowanie firmy, naruszając infrastrukturę.
Jej konsekwencje dotykają organizację, jej klientów, dostawców, pracowników oraz partnerów. Katastrofa wywiera presję na firmę w obszarach finansów, reputacji w branży, zaufania klientów i bezpieczeństwa.
Dlatego tak ważne jest, aby przygotować się na taki scenariusz z wyprzedzeniem. W tym celu należy jak najszybciej przywrócić wszystkie operacje i dostęp do danych. Krótko mówiąc, organizacja musi być przygotowana na szybkie odzyskanie pełnej funkcjonalności dla dobra swoich klientów.
Katastrofy przybierają różne formy. Może to być cyberatak, sabotaż, akt terrorystyczny, oprogramowanie ransomware, ale też zagrożenia fizyczne, takie jak huragany, trzęsienia ziemi, pożary, powodzie, awarie przemysłowe, przerwy w dostawie energii elektrycznej i wiele innych.
Co oznacza odzyskiwanie po awarii?
Odzyskiwanie po awarii to proces przywracania normalnego funkcjonowania po wystąpieniu katastrofy. Obejmuje wznowienie dostępu do sprzętu, oprogramowania, infrastruktury, komunikacji, sieci, zasilania i danych. Konieczne jest opracowanie zasad i procedur w formie udokumentowanego procesu, aby przygotować organizację na ewentualność katastrofy.
Jeżeli obiekty firmy zostaną zniszczone, zakres działań musi być szerszy i obejmować komunikację, transport, logistykę, miejsca pracy i inne aspekty.
Dlaczego plan odzyskiwania po awarii jest tak ważny?
Opracowanie skutecznego planu działania w przypadku katastrofy naturalnej lub zdarzenia spowodowanego przez człowieka jest kluczowe dla każdej firmy z branży IT. Niezbędne jest upewnienie się, że odpowiednie osoby i narzędzia znajdują się we właściwym miejscu, aby sprawnie wdrożyć plan.
Przyjrzyjmy się bliżej, dlaczego odzyskiwanie danych po awarii ma tak fundamentalne znaczenie.
Ograniczenie strat
Katastrofa jest zdarzeniem nieprzewidywalnym. Nikt nie wie, kiedy nastąpi i jak długo potrwa. Jednak, dzięki wcześniejszemu przygotowaniu, możemy kontrolować straty, które dotkną naszą infrastrukturę.
Na przykład, w rejonach zagrożonych powodzią, ważne dokumenty i sprzęt można umieścić na wyższych piętrach budynku, aby uniknąć uszkodzeń.
Podobnie, tworzenie kopii zapasowych ważnych danych pomoże w sytuacji, gdy cyberprzestępcy będą próbowali je wykraść lub uszkodzić.
Przywrócenie usług
Dzięki solidnemu planowi reagowania na katastrofy, przywrócenie wszystkich usług do ich normalnego stanu będzie szybkie i łatwe. Oznacza to, że w krótkim czasie możliwe jest odzyskanie kluczowych zasobów i usług.
Minimalizacja zakłóceń
Nikt nie jest w stanie przewidzieć przyszłości. Jednak, dzięki dobrze przygotowanemu planowi naprawczemu, nie musisz martwić się konsekwencjami katastrofy. Twoja infrastruktura będzie mogła funkcjonować z minimalnymi zakłóceniami.
Szkolenie i przygotowanie

Infrastruktura IT obejmuje wielu pracowników pracujących w jednym zespole. Wszyscy oni muszą być zaznajomieni z procedurami odzyskiwania, aby móc działać natychmiast zgodnie z wymaganiami i oczekiwaniami w sytuacji zagrożenia.
Odpowiednie przygotowanie pozwoli również zredukować stres wszystkich osób związanych z organizacją. Co więcej, można przeszkolić pracowników, by byli w stanie podejmować niezbędne działania w przypadku wystąpienia nieoczekiwanej sytuacji.
Terminologia odzyskiwania po awarii
Zacznijmy od definicji, aby lepiej zrozumieć zagadnienie odzyskiwania po awarii.
RTO
Docelowy Czas Odzyskiwania (RTO) to okres czasu, który organizacja, w zależności od rodzaju prowadzonej działalności, jest w stanie tolerować bez negatywnego wpływu na swoją kondycję finansową.
Przy ustalaniu RTO, firma musi przeanalizować przestoje, które mogą wpływać na jej funkcjonowanie w różny sposób. Pomaga to w opracowaniu opłacalnych strategii kontynuowania działalności nawet po wystąpieniu katastrofy. Gdy klienci napotykają trudności z dostępem do aplikacji, zadają pytanie o czas potrzebny na jej ponowne uruchomienie. Odpowiedzią jest RTO danej organizacji.
Przykład: Załóżmy, że prowadzisz firmę zajmującą się transakcjami online, taką jak PayPal czy Pioneer, i niespodziewanie doświadczasz kryzysu. W takim przypadku, Twoje RTO będzie musiało być bardzo krótkie, aby umożliwić jak najszybsze wznowienie działalności.
Innymi słowy, firma ustala RTO na poziomie godziny lub dwóch, aby uniknąć negatywnych konsekwencji finansowych lub utraty danych.
RPO
Docelowy Punkt Odzyskiwania (RPO) to określenie maksymalnej dopuszczalnej utraty danych, z którą infrastruktura IT jest w stanie sobie poradzić w zakresie czasu i ilości informacji.
Brzmi skomplikowanie?
Rozważmy przykład bazy danych, która przechowuje informacje o transakcjach bankowych, takie jak przelewy, harmonogramy i płatności. W przypadku awarii, baza danych musi być przywrócona w czasie rzeczywistym. W tym scenariuszu, różnica między stanem bazy danych w momencie awarii a stanem po jej odzyskaniu wynosi zero.
W przypadku niektórych firm, odzyskanie wszystkich informacji z kopii zapasowej może zająć około 24 godzin, co w pewnych sytuacjach może okazać się katastrofalne. Kluczowe jest dostosowanie infrastruktury do wymagań RPO. Może to obejmować zwiększenie częstotliwości tworzenia kopii zapasowych, dodanie rezerwowej bazy danych do struktury i inne działania.
Przełączanie awaryjne
Wyobraź sobie sytuację, w której jesteś w długiej podróży. Nagle, z nieprzewidzianych przyczyn, łapiesz gumę. Na szczęście masz w samochodzie koło zapasowe oraz narzędzia potrzebne do jego wymiany.
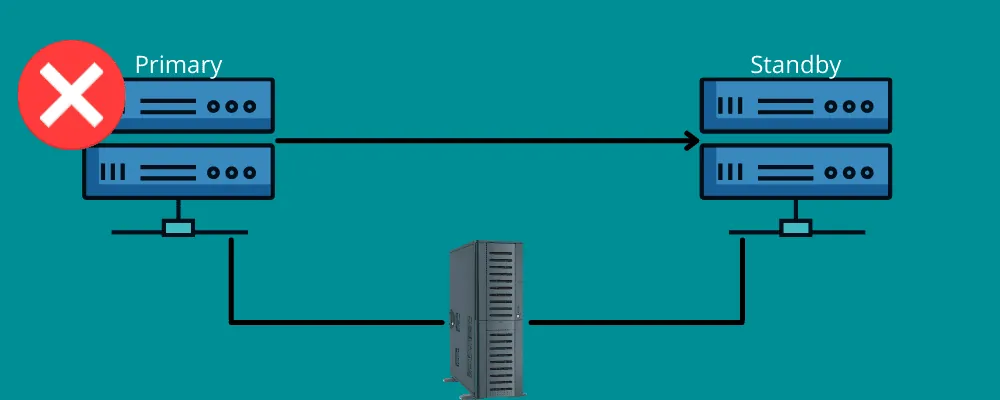
Przełączanie awaryjne działa na podobnej zasadzie.
Oznacza to, że w sytuacji kryzysowej potrzebne jest alternatywne połączenie. Mówiąc w skrócie, przełączanie awaryjne to posiadanie sieci i systemów, które można wykorzystać w przypadku awarii, aby przekierować informacje do systemu odzyskiwania.
Przełączanie awaryjne gwarantuje ciągłość działania wszystkich usług, nawet w przypadku awarii infrastruktury lub sprzętu. Pozwala to uniknąć utraty danych i przychodów, a także przerw w świadczeniu usług użytkownikom końcowym.
Można skonfigurować je ręcznie lub włączyć automatyczne działanie w celu przeniesienia danych na serwer rezerwowy.
Powrót po awarii
Powrót po awarii w IT to proces, w którym pierwotna produkcja zostaje przywrócona do swojego pierwotnego miejsca (systemu) po rozwiązaniu awarii. Podczas ataku firmy realizują procedurę przełączania awaryjnego, dzięki której wszystkie obciążenia przenoszone są na replikę maszyny wirtualnej lub do systemu kopii zapasowej.
Nie można jednak pominąć kolejnego kroku, jakim jest powrót po awarii. Po odzyskaniu pełnej funkcjonalności, należy przenieść wszystkie obciążenia z powrotem na ich oryginalne maszyny wirtualne lub systemy. Ten proces powrotu do pierwotnego miejsca pracy lub systemu nazywany jest powrotem po awarii. Oznacza to „powrót” po ataku.
Powrót po awarii jest także stosowany podczas planowanych prac konserwacyjnych w firmie. Prawdą jest, że powrót po awarii zawsze następuje po przełączeniu awaryjnym. Innymi słowy, przełączenie awaryjne to pierwszy krok, a powrót po awarii to drugi krok w procesie odzyskiwania danych. Możliwa jest konfiguracja tego procesu między chmurami, lokalnie, z lokalnego do chmurowego środowiska lub dowolna ich kombinacja.
DR
Odzyskiwanie po awarii (DR) to proces, w którym masz przygotowane plany odzyskania zasobów w określonym czasie.
DR umożliwia organizacji szybkie reagowanie i odzyskiwanie każdej usługi po wystąpieniu nieoczekiwanego zdarzenia. Obejmuje również formalną dokumentację zawierającą instrukcje dotyczące natychmiastowego działania w sytuacjach awaryjnych.
BCP
Plan ciągłości działania (BCP) to jeden z najczęściej stosowanych planów odzyskiwania po awarii, który pozwala infrastrukturze IT opracować strategie postępowania w przypadku zakłóceń w działaniu serwerów, urządzeń mobilnych, komputerów stacjonarnych i sieci.
BCP różni się nieco od odzyskiwania po awarii, ponieważ jego celem jest wsparcie organizacji w planowaniu przywrócenia funkcjonowania oprogramowania korporacyjnego i produktywności, aby zaspokoić kluczowe potrzeby biznesowe.
Firma tworzy system odzyskiwania, który ma na celu przezwyciężenie potencjalnych zagrożeń, takich jak cyberataki czy klęski żywiołowe. Został zaprojektowany w celu zabezpieczenia zasobów i zapewnienia szybkiego wznowienia działania wszystkich usług po ataku.
BCM

Zarządzanie ciągłością działania (BCM) to proces zarządzania ryzykiem, który ma na celu ochronę przed zagrożeniami dla procesów biznesowych. BCM jest rozwinięciem BCP i koncentruje się na weryfikacji planów naprawczych, aby upewnić się, że wszyscy pracownicy firmy będą mogli natychmiast wdrożyć plan i odzyskać wszystkie niezbędne elementy.
BCM działa jako system zarządzania do identyfikowania ryzyk infrastrukturalnych w przypadku zagrożeń zewnętrznych i wewnętrznych. Ponadto, zapewnia sprawne funkcjonowanie struktury dzięki regularnym testom, które pozwalają zwiększyć przewidywalność, zmniejszyć ryzyko i dostosować plan do przyszłych ataków.
BIA
Analiza wpływu na działalność (BIA) to proces analizy poziomu przetrwania firmy poprzez identyfikację kluczowych systemów, operacji i procesów. BIA pozwala ocenić skutki katastrofy dla organizacji spowodowane przerwą w jej działaniu.
BIA przewiduje konsekwencje, zanim dojdzie do ataku. Dzięki temu można zebrać informacje, które pomogą w stworzeniu efektywnych strategii odzyskiwania. Ponadto, analiza ta pozwala oszacować koszty związane z awariami, takie jak wymiana sprzętu, utrata płynności finansowej, zyski, pensje i inne.
Podczas tworzenia raportu BIA, należy wziąć pod uwagę kluczowe procesy związane z firmą, wpływ zakłóceń na różne obszary, akceptowalny czas trwania przestoju, obszary tolerancji, koszty finansowe i inne czynniki.
Drzewo połączeń
Drzewo połączeń to proces tworzenia listy pracowników, do których należy zadzwonić w sytuacjach awaryjnych. Jest to procedura o strukturze przypominającej drzewo.
Na przykład, w sytuacji katastrofy, jedna osoba kontaktuje się z wybranymi członkami zespołu, przekazując im pilną wiadomość. Następnie ci pracownicy dzwonią do kolejnych osób w swoich grupach. W ten sposób wszyscy pracownicy zostają poinformowani o zagrożeniu i mogą przystąpić do realizacji zadań potrzebnych do odzyskania wszystkich funkcji i procesów. Stworzenie listy jest proste, ale jej wdrożenie w praktyce może powodować zamieszanie.
Konieczne jest regularne sprawdzanie drzewa telefonicznego, aby każdy pracownik odpowiedzialny za reagowanie w sytuacjach awaryjnych był przygotowany. Regularne testowanie pomaga również zidentyfikować zmienione lub brakujące numery, co może poważnie wpłynąć na efektywność działań.
Drzewo połączeń zawiera informacje, które należy wykorzystać w sytuacjach kryzysowych w celu przekazania instrukcji. Proces ten można wykonać ręcznie, ale w dzisiejszym cyfrowym świecie wiele osób korzysta z automatyzacji, która przyspiesza cały proces i pozwala na powiadamianie członków zespołu w czasie rzeczywistym.
Centrum dowodzenia/Centrum kontroli
Jest to wirtualne lub fizyczne miejsce, które służy do zarządzania planami naprawczymi w sytuacji kryzysowej. Centrum komunikuje się z zespołem, aby kierować systemami i funkcjami podczas katastrofy.
Tradycyjnie infrastruktura zależała od centrum dowodzenia radzącego sobie z kryzysami bez odpowiedniego planu działania. W obecnych czasach, organizacje tworzą doskonale zaprojektowane centra dowodzenia, które zapewniają natychmiastową reakcję na kluczowe wyzwania.
Po wykryciu katastrofy, centrum dowodzenia szybko przechodzi do fazy odzyskiwania. Ponadto, służy ono jako punkt raportowania w sprawach usług, mediów, dostaw i innych. W takich sytuacjach, centrum skupia osoby z różnych obszarów.
Reagowanie na incydenty

Reagowanie na incydent to działania podejmowane w celu poradzenia sobie z atakiem. Odbywa się to przy pomocy odpowiednich procedur i przeszkolonego personelu, tak aby skutecznie zapewnić bezpieczeństwo sieci i danych w czasie rzeczywistym.
Jeśli firma posiada plan reagowania na incydenty, może chronić swoje dane przed zagrożeniami w czasie rzeczywistym. Specjaliści reagujący na incydenty monitorują sytuację i podejmują odpowiednie działania podczas incydentu. Zastosowanie odpowiednich środków pozwala uniknąć naruszeń bezpieczeństwa i daje pewność, że wszystkie kroki w procesie odzyskiwania po awarii zostaną zrealizowane.
Na początek należy określić, które dane są kluczowe i przechowywać je w chmurze lub innej zdalnej lokalizacji, aby zapewnić ich bezpieczeństwo. Należy regularnie aktualizować plany reagowania na incydenty, aby odpowiadać na bieżące potrzeby związane z infrastrukturą i stale zmieniające się zagrożenia cybernetyczne.
Kopia zapasowa
Rozwiązania do tworzenia kopii zapasowych pomagają infrastrukturze IT w utrzymaniu kopii danych i bezpiecznym przechowywaniu ich w odpowiednim czasie. W przypadku uszkodzenia bazy danych, przypadkowego usunięcia danych lub jakichkolwiek innych problemów, niezbędne jest posiadanie kopii zapasowej, aby móc natychmiast przywrócić dane i kontynuować korzystanie z usług.

Polega to na replikowaniu plików i przechowywaniu ich w bezpiecznym miejscu, aby można było łatwo uzyskać do nich dostęp po wystąpieniu nieoczekiwanego zdarzenia. Warto tworzyć kopie zapasowe danych w kilku lokalizacjach, co zapewni możliwość ich przywrócenia nawet w przypadku awarii jednego z tych miejsc.
Odporność
Zdolność społeczności, państw, organizacji i osób fizycznych do przetrwania katastrofy bez szkody dla usług i systemów jest określana jako odporność na katastrofy.
Organizacja musi być przygotowana na radzenie sobie z presją wywołaną zagrożeniami. Ważne jest, by dążyć do minimalizacji strat dzięki lepszemu planowaniu, zamiast czekać, aż ktoś nas uratuje. Pomoże to w radzeniu sobie z awariami i szybkim odzyskaniu infrastruktury IT.
Tutaj, najważniejszym celem jest zachowanie i przywrócenie podstawowych funkcji i struktur w odpowiednim czasie, gdy jest to potrzebne. Aby stać się organizacją odporną na katastrofy, należy wcześniej się do tego przygotować i umieć przewidywać zagrożenia, dostosowywać się do zmian, dzielić się i uczyć, integrować różne sektory i zarządzać poziomami ryzyka.
SLA

Umowa o gwarantowanym poziomie świadczenia usług (SLA) to plan awaryjny, w którym określa się czas potrzebny na przywrócenie usług w sytuacji kryzysowej.
Umowa SLA gwarantuje klientom bezpieczeństwo danych i ochronę przed ich udostępnieniem osobom trzecim. SLA jest jednym punktem kontaktu w sprawach związanych z klientami.
Każda infrastruktura IT musi przedstawić swoim klientom gwarancję SLA. Dlatego tak istotna jest wcześniejsza komunikacja z klientami.
SPOF
Pojedynczy punkt awarii (SPOF) to element sprzętu, jednostka, zasób lub aplikacja, z którą połączonych jest wiele innych systemów lub aplikacji.
Jeśli taki element lub zasób ulegnie awarii, wszystkie powiązane z nim części systemu przestaną działać. W ten sposób awaria wpłynie na cały proces i działalność firmy.
Dlatego tak ważne jest, aby opracować strategię radzenia sobie z tego typu sytuacjami. Pierwszą rzeczą, którą należy zrobić, jest zidentyfikowanie tego jednego elementu sprzętu lub systemu, który może mieć największy wpływ na funkcjonowanie firmy. Następnie należy przeprowadzić analizę wpływu na biznes i ocenę ryzyka, aby wiedzieć, czego można się spodziewać. Należy rozpoznać wszystkie słabe punkty systemu jeszcze przed wystąpieniem potencjalnej awarii.
Po zidentyfikowaniu wszystkich SPOF, należy je sklasyfikować według procedury odzyskiwania. Każdy z elementów SPOF należy umieścić w jednej z trzech kategorii:
- Odzyskanie danych jest proste i można je zrealizować w krótkim czasie przy minimalnych kosztach.
- Odzyskanie danych jest trudniejsze, ale można opracować niezawodny proces naprawczy.
- Brak możliwości odzyskania sprawności systemu w przypadku awarii.
Dalsze działania należy podjąć w oparciu o przypisaną kategorię.
Odzyskiwanie systemu
W przypadku awarii sprzętu, należy uruchomić proces odzyskiwania, aby przywrócić dany system lub serwer do jego pierwotnego stanu. Aby odzyskać cały system, należy być przygotowanym na wymagania dotyczące odzyskiwania, tworzenia kopii zapasowych, zgodności oprogramowania układowego oraz zgodności sprzętu.
Odzyskiwanie systemu to proces, który resetuje urządzenie do wcześniejszych ustawień lub do stanu w jakim było nowe. Spowoduje to usunięcie wszelkich infekcji wirusowych, które mogły powstać w wyniku zainstalowania szkodliwego oprogramowania lub aplikacji.
Proces ten obejmuje planowanie odzyskiwania infrastruktury IT, które określa i stosuje określone procedury, aby zapewnić dostępność danych w przypadku zakłóceń spowodowanych przez człowieka lub czynniki naturalne.
Przywracanie systemu
Przywracanie systemu to narzędzie, które umożliwia przywrócenie określonych plików i informacji do ich wcześniejszego stanu.
Dzięki przywracaniu systemu, można odzyskać klucze rejestru, zainstalowane programy, sterowniki, pliki systemowe i inne elementy do ich poprzedniej wersji. Może to być nieocenione w przypadku wystąpienia katastrofy.
Plan testów
Plan testów to dokument, który zawiera informacje na temat strategii testowania, szacunków, zasobów, terminów, celów i harmonogramów. Działa jako plan, który prowadzi testy mające na celu zapewnienie bezpieczeństwa sprzętu i oprogramowania.
Obejmuje on różne testy, które są wykonywane zgodnie z procedurami i krokami zaplanowanymi na wypadek katastrofy. Należy regularnie przeprowadzać testy, aby przygotować siebie i organizację na każdą ewentualność i upewnić się, że podczas prawdziwego zdarzenia nie zostanie pominięty żaden ważny krok. W ten sposób, infrastruktura IT może zidentyfikować słabe punkty i być gotowa do działania w sytuacjach kryzysowych.
Podsumowanie
Nikt nie wie, kiedy wydarzy się katastrofa. Dlatego też, odpowiednie środki bezpieczeństwa i ochrony są niezbędne dla każdej firmy.
Znajomość terminologii związanej z odzyskiwaniem po awarii pomoże Ci zrozumieć, jak reagować na ataki i katastrofy. Dzięki temu, będziesz w stanie przygotować się z wyprzedzeniem i zabezpieczyć swoją infrastrukturę na wypadek nieoczekiwanego zdarzenia. Pozwoli Ci to na stworzenie skutecznej strategii odzyskiwania po awarii, a w efekcie, możesz zaoszczędzić miliony dolarów i zachować zaufanie swoich klientów.
