Zrozumienie i Wykorzystanie Ramek Danych w R
Ramki danych stanowią kluczową strukturę danych w środowisku R, zapewniając uporządkowany fundament do analizy i modyfikacji informacji. Ich wszechstronność i funkcjonalność są nieocenione w różnych dziedzinach, od statystyki, przez analizę danych, po wspomaganie decyzji w wielu branżach.
Dzięki ramkom danych, dane stają się zorganizowane i łatwe do interpretacji, co przekłada się na efektywne wyciąganie wniosków i podejmowanie decyzji opartych na solidnych podstawach.
Struktura ramek danych w R przypomina arkusz kalkulacyjny, z wierszami reprezentującymi poszczególne obserwacje, a kolumnami opisującymi zmienne. Ta klarowna organizacja ułatwia pracę z danymi, umożliwiając przechowywanie różnorodnych typów informacji, takich jak liczby, teksty czy daty, co czyni je niezwykle uniwersalnymi.
W tym artykule zgłębimy znaczenie ramek danych, przedstawiając metody ich tworzenia za pomocą funkcji `data.frame()`. Omówimy również techniki manipulacji danymi, sposoby importowania informacji z plików CSV i Excel, transformację innych struktur danych w ramki, oraz zalety korzystania z biblioteki tibble.
Poniżej przedstawiamy kluczowe argumenty, dlaczego ramki danych są tak istotne w R:
Znaczenie Ramek Danych

- Uporządkowane przechowywanie danych: Ramki danych oferują tabelaryczny format przechowywania danych, który przypomina arkusz kalkulacyjny. Dzięki temu, zarządzanie i organizacja danych stają się prostsze i bardziej przejrzyste.
- Obsługa różnorodnych typów danych: W ramach jednej ramki danych można przechowywać kolumny z różnymi typami informacji, w tym wartościami numerycznymi, ciągami znaków, kategoriami, datami i innymi. Ta elastyczność jest kluczowa przy analizie danych ze świata rzeczywistego.
- Przejrzysta organizacja danych: Każda kolumna w ramce danych odpowiada konkretnej zmiennej, a każdy wiersz reprezentuje pojedynczą obserwację. Ta struktura ułatwia zrozumienie organizacji danych i poprawia ich czytelność.
- Łatwość importu i eksportu: Ramki danych umożliwiają bezproblemowy import i eksport danych z różnych źródeł, takich jak pliki CSV, Excel oraz bazy danych. Usprawnia to przepływ pracy z danymi zewnętrznymi.
- Kompatybilność: Ramki danych są szeroko wykorzystywane przez pakiety i funkcje R, co zapewnia ich kompatybilność z różnorodnymi narzędziami statystycznymi i bibliotekami analitycznymi. Pozwala to na płynną integrację z ekosystemem R.
- Zaawansowana manipulacja danymi: R oferuje bogaty wybór pakietów do manipulacji danymi, a `dplyr` jest doskonałym przykładem. Pakiety te umożliwiają filtrowanie, transformację i podsumowywanie danych w ramach ramek, co jest kluczowe przy ich przygotowaniu do analizy.
- Analiza statystyczna: Ramki danych to standardowy format danych dla wielu funkcji statystycznych i analiz w R. Umożliwiają one efektywne przeprowadzanie analiz regresji, testowania hipotez i wielu innych procedur.
- Wizualizacja: Pakiety do wizualizacji danych w R, takie jak `ggplot2`, doskonale współpracują z ramkami danych. Ułatwia to tworzenie czytelnych wykresów, które wspierają eksplorację i prezentację wyników.
- Eksploracja danych: Ramki danych ułatwiają eksplorację danych, dostarczając podsumowań statystycznych, umożliwiając wizualizację i inne techniki analityczne. Pomaga to analitykom i badaczom w zrozumieniu charakterystyki danych i identyfikacji wzorców lub odchyleń.
Tworzenie Ramek Danych w R
Istnieje kilka metod tworzenia ramek danych w R. Poniżej przedstawiamy te najbardziej popularne:
#1. Użycie funkcji `data.frame()`
# Wczytanie potrzebnej biblioteki, jeśli nie jest jeszcze załadowana
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# Ustawienie ziarna losowości dla powtarzalności
set.seed(42)
# Utworzenie przykładowej ramki danych z danymi sprzedaży
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Wyświetlenie ramki danych
print(sales_data)
Powyższy kod weryfikuje obecność biblioteki `dplyr`, w razie potrzeby instaluje ją, następnie ustawia ziarno losowości, tworzy przykładową ramkę danych z informacjami o sprzedaży, i na końcu wyświetla ją w konsoli.
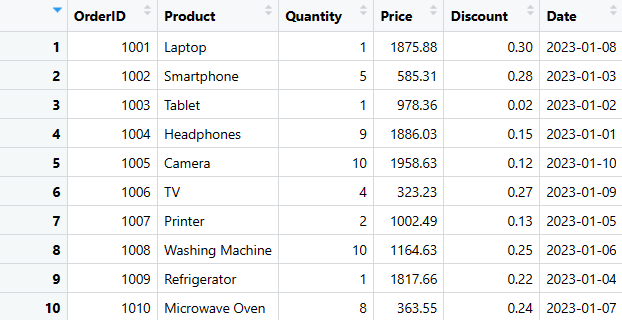 Przykładowa ramka danych sprzedaży
Przykładowa ramka danych sprzedaży
To jeden z najprostszych sposobów tworzenia ramek danych. Zobaczymy teraz, jak wyodrębniać, dodawać, usuwać i wybierać określone kolumny lub wiersze, a także jak podsumowywać dane.
Wyodrębnianie Kolumn
Istnieją dwie metody na wyodrębnianie kolumn z ramki danych:
- Wykorzystanie indeksowania pozwala na pobranie ostatnich kolumn.
- Operator `$` umożliwia dostęp do kolumn po nazwie.
Oto przykład wykorzystujący obie metody:
# Wyodrębnienie trzech ostatnich kolumn (Discount, Price, i Date) za pomocą indeksowania
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Wyświetlenie wyodrębnionych kolumn
print(last_three_columns)
############################################# LUB #########################################################
# Wyodrębnienie trzech ostatnich kolumn za pomocą operatora $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Utworzenie nowej ramki danych z wyodrębnionymi kolumnami
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Wyświetlenie wyodrębnionych kolumn
print(last_three_columns)
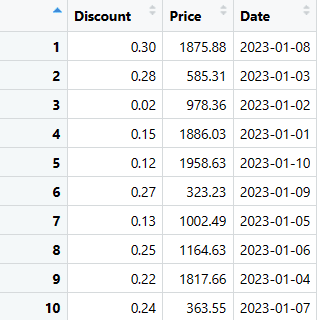
W obu przypadkach, kod ten służy do wyodrębnienia kolumn z ramki danych.
Wiersze można wyodrębnić z ramki danych na różne sposoby, na przykład w ten sposób:
# Wyodrębnienie określonych wierszy (3, 6 i 9) z ramki danych last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Wyświetlenie wybranych wierszy print(selected_rows)
Można też użyć określonych warunków:
# Wyodrębnienie i uporządkowanie wierszy spełniających określone warunki
selected_rows <- sales_data %>%
filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>%
arrange(OrderID) %>%
select(Discount, Price, Date)
# Wyświetlenie wybranych wierszy
print(selected_rows)
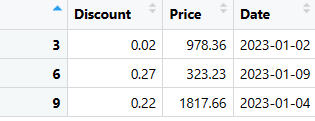 Wyodrębnione wiersze
Wyodrębnione wiersze
Dodawanie Nowego Wiersza
Do dodawania nowego wiersza do ramki danych w R można użyć funkcji `rbind()`:
# Utworzenie nowego wiersza jako ramki danych
new_row <- data.frame(
OrderID = 1011,
Product = "Coffee Maker",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Dodanie nowego wiersza do ramki danych
sales_data <- rbind(sales_data, new_row)
# Wyświetlenie zaktualizowanej ramki danych
print(sales_data)
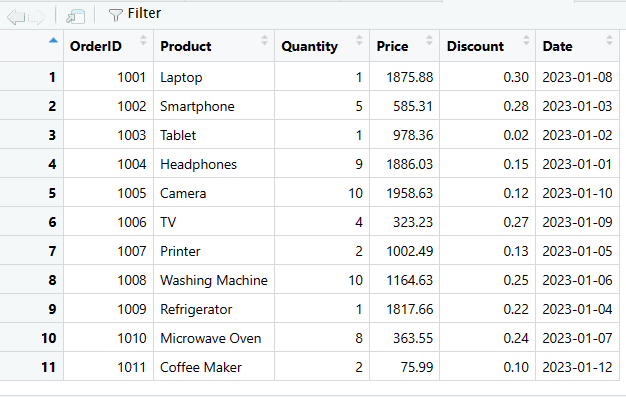 Dodano nowy wiersz
Dodano nowy wiersz
Dodawanie Nowej Kolumny
Dodawanie kolumn do ramki danych jest proste, oto przykład dodania kolumny `PaymentMethod`:
# Utworzenie nowej kolumny "PaymentMethod" z wartościami dla każdego wiersza
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Wyświetlenie zaktualizowanej ramki danych
print(sales_data)
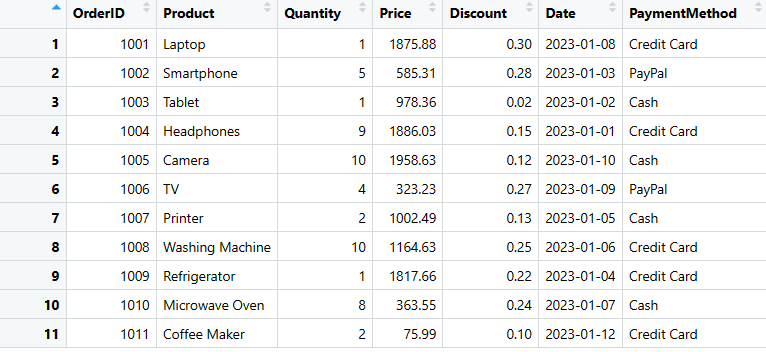 Kolumna dodana w ramce danych
Kolumna dodana w ramce danych
Usuwanie Wierszy
Usuwanie wierszy można zrealizować w taki sposób:
# Identyfikacja wiersza do usunięcia na podstawie OrderID row_to_delete <- sales_data$OrderID == 1010 # Usunięcie wiersza z ramki danych sales_data <- sales_data[!row_to_delete, ] # Wyświetlenie zaktualizowanej ramki danych bez usuniętego wiersza print(sales_data)
Usuwanie Kolumn
Do usuwania kolumn można wykorzystać pakiet `dplyr`:
# Załadowanie pakietu dplyr library(dplyr) # Usunięcie kolumny "Discount" przy użyciu funkcji select() sales_data <- sales_data %>% select(-Discount) # Wyświetlenie zaktualizowanej ramki danych bez kolumny "Discount" print(sales_data)
Podsumowanie Danych
Funkcja `summary()` pozwala uzyskać podsumowanie danych, zawierające podstawowe statystyki opisowe zmiennych numerycznych:
# Uzyskanie podsumowania danych data_summary <- summary(sales_data) # Wyświetlenie podsumowania print(data_summary)
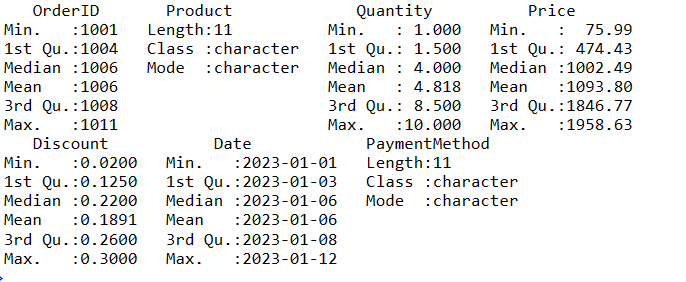
Powyższe przykłady przedstawiają podstawowe techniki manipulacji danymi w ramkach danych.
Przejdźmy teraz do kolejnej metody tworzenia ramek danych.
#2. Tworzenie Ramki Danych z Pliku CSV
Do utworzenia ramki danych z pliku CSV można wykorzystać funkcję `read.csv()`:
# Wczytanie danych z pliku CSV do ramki danych
df <- read.csv("my_data.csv")
# Wyświetlenie kilku pierwszych wierszy ramki danych
head(df)
Funkcja ta wczytuje dane z pliku CSV i konwertuje je do ramki danych. Następnie można pracować z tymi danymi w R.
# Instalacja i wczytanie pakietu readr, jeśli nie jest zainstalowany
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Wczytanie danych z pliku CSV do ramki danych
df <- read_csv("data.csv")
# Wyświetlenie kilku pierwszych wierszy ramki danych
head(df)
Do wczytania pliku CSV można także wykorzystać pakiet `readr` i funkcję `read_csv()`, która jest szybsza niż standardowa metoda.
#3. Użycie Funkcji `as.data.frame()`
Funkcja `as.data.frame()` umożliwia konwersję innych struktur danych, takich jak macierze lub listy, na ramkę danych:
# Utworzenie zagnieżdżonej listy reprezentującej dane
data_list <- list(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Konwersja listy na ramkę danych
sales_data <- as.data.frame(data_list)
# Wyświetlenie ramki danych
print(sales_data)
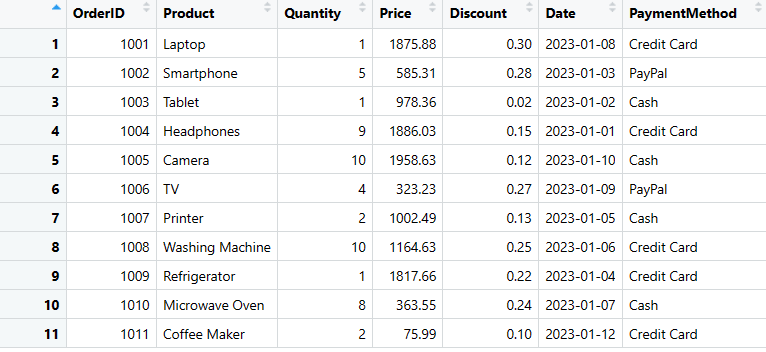 Dane_sprzedaży
Dane_sprzedaży
Ta metoda pozwala na szybkie utworzenie ramki danych bez definiowania każdej kolumny oddzielnie, co jest przydatne przy dużych zbiorach danych.
#4. Z Istniejącej Ramki Danych
Nową ramkę danych można stworzyć, wybierając określone kolumny lub wiersze z istniejącej, za pomocą indeksowania:
# Wybór wierszy i kolumn
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Wyświetlenie wybranego podzbioru
print(sales_subset)
W tym kodzie, tworzymy nową ramkę danych `sales_subset` zawierającą wybrane wiersze i kolumny z `sales_data`.
 Podzbiór sprzedaży
Podzbiór sprzedaży
#5. Z Wektora
Wektor to jednowymiarowa struktura danych. Ramkę danych można utworzyć, łącząc kilka wektorów o tym samym rozmiarze:
# Utworzenie wektorów dla każdej kolumny
OrderID <- 1001:1011
Product <- c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Utworzenie ramki danych przy użyciu funkcji data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Wyświetlenie ramki danych
print(sales_data)
W tym kodzie, tworzymy oddzielne wektory, a następnie łączymy je w ramkę danych przy pomocy funkcji `data.frame()`.
#6. Z Pliku Excel
Do wczytywania plików Excel można użyć pakietów zewnętrznych, na przykład `readxl`, ponieważ podstawowy R nie obsługuje bezpośrednio plików Excel. Oto przykład:
# Załadowanie biblioteki readxl library(readxl) # Zdefiniowanie ścieżki do pliku Excel excel_file_path <- "your_file.xlsx" # Zastąp rzeczywistą ścieżką # Wczytanie pliku Excel i utworzenie ramki danych data_frame_from_excel <- read_excel(excel_file_path) # Wyświetlenie ramki danych print(data_frame_from_excel)
Powyższy kod odczytuje plik Excel i zapisuje dane w ramce danych R.
#7. Z Pliku Tekstowego
Do importu plików tekstowych można użyć funkcji `read.table()`, która wymaga nazwy pliku i separatora pól:
# Zdefiniowanie nazwy pliku i separatora file_name <- "your_text_file.txt" # Zastąp nazwą pliku delimiter <- "\t" # Zastąp rzeczywistym separatorem (np. "\t" dla tabulatora, "," dla CSV) # Utworzenie ramki danych za pomocą read.table() data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Wyświetlenie ramki danych print(data_frame_from_text)
Ten kod wczytuje plik tekstowy i tworzy z niego ramkę danych w R.
#8. Użycie Tibble
Biblioteka `tidyverse` oferuje typ danych `tibble`, który jest rozszerzeniem ramki danych. Oto jak go użyć:
# Załadowanie biblioteki tidyverse
library(tidyverse)
# Utworzenie tibble przy użyciu dostarczonych wektorów
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Wyświetlenie utworzonego tibble
print(sales_data)
Format `tibble` zapewnia bardziej informatywne drukowanie danych w porównaniu z domyślną ramką danych w R.
Efektywne Wykorzystanie Ramek Danych w R
Efektywne używanie ramek danych jest kluczowe dla sprawnej analizy danych. Oto kilka wskazówek, jak zoptymalizować pracę:
- Upewnij się, że dane są czyste i uporządkowane przed utworzeniem ramki.
- Ustaw odpowiednie typy danych dla kolumn.
- Wykorzystuj indeksowanie i podzbiory, aby pracować z mniejszymi porcjami danych.
- Unikaj używania funkcji `attach()` i `detach()`.
- Korzystaj z operacji wektorowych zamiast pętli.
- Zamiast zagnieżdżonych pętli, używaj operacji wektorowych lub funkcji typu `lapply` czy `sapply`.
- Rozważ użycie pakietów `data.table` lub `dtplyr` dla większych zestawów danych.
- Wykorzystuj pakiety takie jak `dplyr`, `tidyr` i `data.table` do efektywnej transformacji danych.
- Minimalizuj użycie zmiennych globalnych.
- Używaj `group_by()` i `summarise()` z `dplyr` do efektywnego agregowania danych.
- Rozważ przetwarzanie równoległe dla większych zbiorów danych.
- Do importu danych używaj funkcji z pakietów `readr` lub `data.table`, zamiast podstawowej funkcji `read.csv`.
- Dla bardzo dużych zbiorów danych, rozważ wykorzystanie systemów baz danych lub dedykowanych formatów przechowywania danych.
Stosowanie się do tych zasad pozwoli na bardziej wydajną pracę z ramkami danych.
Podsumowanie
Tworzenie ramek danych w R jest proste, a do dyspozycji jest wiele metod. W artykule przedstawiliśmy znaczenie ramek danych i omówiliśmy ich tworzenie za pomocą funkcji `data.frame()`. Zbadaliśmy także sposoby manipulacji danymi, tworzenia ramek danych z plików CSV i Excel, transformacji innych struktur danych oraz korzystania z biblioteki tibble.
Zachęcamy także do zapoznania się z najlepszymi środowiskami IDE do programowania w języku R.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.