Jeżeli chcesz połączyć dane z dwóch plików tekstowych, bazując na wspólnym polu, możesz skorzystać z polecenia join w systemie Linux. To narzędzie dodaje dynamikę do statycznych zbiorów danych. W tym artykule pokażemy, jak z niego korzystać.
Łączenie danych w plikach
Dane stanowią kluczowy element w działalności różnych organizacji, od korporacji po gospodarstwa domowe. Jednakże, gdy dane są przechowywane w różnych plikach i przez różne osoby, ich zarządzanie staje się problematyczne. Należy nie tylko wiedzieć, które pliki otworzyć, aby znaleźć potrzebne informacje, ale także radzić sobie z różnorodnością układów i formatów plików.
Do tego dochodzi również problem administracyjny związany z aktualizacją plików, archiwizacją starszych wersji oraz zarządzaniem tym, co wymaga zmiany, a co już zostało zaktualizowane.
Jeśli natomiast potrzebujesz skonsolidować dane lub przeprowadzić analizy na dużych zbiorach, napotykasz dodatkowy problem. Jak zorganizować i uporządkować dane rozproszone w różnych plikach, zanim przystąpisz do dalszej pracy? Jak zrealizować etap przygotowania danych?
Na szczęście, jeżeli pliki zawierają chociaż jedno wspólne pole, polecenie join w systemie Linux może być Twoim ratunkiem.
Przygotowanie plików danych
Do demonstracji użyjemy fikcyjnych danych z dwóch plików, które prezentują następujące zawartości:
cat file-1.txt
cat file-2.txt
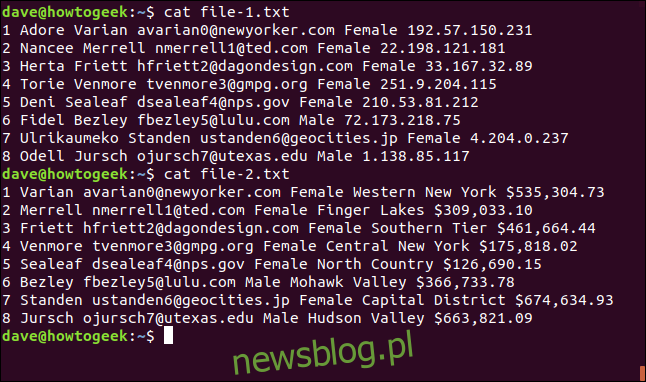
Poniżej znajduje się zawartość pliku-1.txt:
1 Adore Varian avarian0@newyorker.com Female 192.57.150.231 2 Nancee Merrell nmerrell1@ted.com Female 22.198.121.181 3 Herta Friett hfriett2@dagondesign.com Female 33.167.32.89 4 Torie Venmore tvenmore3@gmpg.org Female 251.9.204.115 5 Deni Sealeaf dsealeaf4@nps.gov Female 210.53.81.212 6 Fidel Bezley fbezley5@lulu.com Male 72.173.218.75 7 Ulrikaumeko Standen ustanden6@geocities.jp Female 4.204.0.237 8 Odell Jursch ojursch7@utexas.edu Male 1.138.85.117
Każda linia w tym pliku zawiera następujące informacje:
Numer
Imię
Nazwisko
Adres e-mail
Płeć
Adres IP
1 Varian avarian0@newyorker.com Female Western New York $535,304.73 2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10 3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44 4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02 5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15 6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78 7 Standen ustanden6@geocities.jp Female Capital District $674,634.93 8 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09
Wiersze w tym pliku zawierają następujące informacje:
Numer
Nazwisko
Adres e-mail
Płeć
Region Nowego Jorku
Wartość w dolarach
Polecenie join łączy dane na podstawie „pól”, które w tym kontekście oznaczają fragmenty tekstu oddzielone białymi znakami, końcem lub początkiem wiersza. Aby połączenie mogło zadziałać, każde wiersz w obu plikach musi posiadać wspólne pole.
Możemy użyć adresu e-mail, ponieważ jest on obecny w obu plikach i jest unikalny dla każdej osoby. Po szybkim przeglądzie plików możemy także zauważyć, że wiersze odpowiadają tym samym osobom, co pozwala użyć numerów linii jako pola do dopasowania (później możemy użyć innego pola).
Warto zwrócić uwagę, że oba pliki mają różną liczbę pól, co jest akceptowalne – możemy określić, które pole będzie użyte z każdego z plików.
Uważaj jednak na pola, takie jak regiony Nowego Jorku; w pliku rozdzielanym spacjami każde słowo w nazwie regionu traktowane jest jak osobne pole. Ponieważ niektóre regiony są nazywane dwu- lub trzysłownie, faktycznie masz różną liczbę pól w tym samym pliku. To nie stanowi problemu, o ile dopasujesz tylko te pola, które występują przed regionami.
Wykorzystanie polecenia join
Aby rozpocząć, pole, które zamierzasz dopasować, musi być posortowane. W obu plikach mamy rosnące numery, więc spełniamy to kryterium. Domyślnie, polecenie join używa pierwszego pola w pliku, co jest w naszym przypadku odpowiednie. Oczekuje również, że separatory pól będą białymi znakami, co również jest spełnione, więc możemy przejść do wykonania polecenia.
Używając wartości domyślnych, nasze polecenie będzie wyglądać następująco:
join file-1.txt file-2.txt
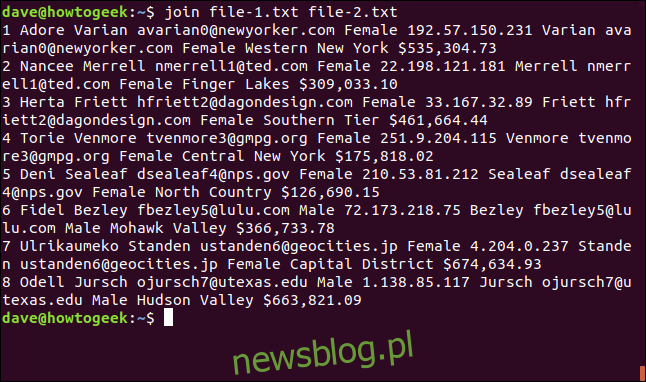
W tym przypadku, join traktuje pliki zgodnie z kolejnością, w jakiej są wymienione w poleceniu.
Wynikiem wykonania polecenia będzie:
1 Adore Varian avarian0@newyorker.com Female 192.57.150.231 Varian avarian0@newyorker.com Female Western New York $535,304.73 2 Nancee Merrell nmerrell1@ted.com Female 22.198.121.181 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10 3 Herta Friett hfriett2@dagondesign.com Female 33.167.32.89 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44 4 Torie Venmore tvenmore3@gmpg.org Female 251.9.204.115 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02 5 Deni Sealeaf dsealeaf4@nps.gov Female 210.53.81.212 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15 6 Fidel Bezley fbezley5@lulu.com Male 72.173.218.75 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen ustanden6@geocities.jp Female 4.204.0.237 Standen ustanden6@geocities.jp Female Capital District $674,634.93 8 Odell Jursch ojursch7@utexas.edu Male 1.138.85.117 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09
Wynik jest zaprezentowany w taki sposób, że najpierw pojawia się pole, na którym dopasowano wiersze, następnie pozostałe pola z pierwszego pliku, a na końcu pola z drugiego pliku, z pominięciem pola dopasowania.
Problemy z niesortowanymi danymi
Spróbujmy przypadku, w którym wiemy, że nie zadziała. Umieścimy wiersze w jednym z plików w nieodpowiedniej kolejności, co sprawi, że polecenie join nie będzie mogło poprawnie przetworzyć danych. Zawartość pliku-3.txt jest identyczna jak plik-2.txt, ale ósmy wiersz znajduje się pomiędzy piątym a szóstym.
Poniżej znajduje się zawartość pliku-3.txt:
1 Varian avarian0@newyorker.com Female Western New York $535,304.73 2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10 3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44 4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02 5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15 8 Jursch ojursch7@utexas.edu Male Hudson Valley $663,821.09 6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78 7 Standen ustanden6@geocities.jp Female Capital District $674,634.93
Wpisujemy polecenie, aby spróbować połączyć plik-3.txt z plikiem-1.txt:
join file-1.txt file-3.txt
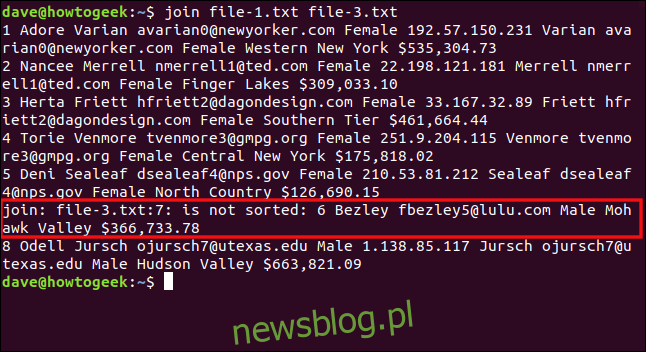
W wyniku działania polecenia join, otrzymujemy informację, że siódmy wiersz w pliku-3.txt jest nieprawidłowy, więc nie zostaje przetworzony. Linia ta zaczyna się od liczby sześć, która powinna znajdować się przed ósmą na prawidłowo posortowanej liście. Ostatni przetworzony wiersz to ten, który zaczyna się od „8 Odell”.
Możesz użyć opcji –check-order, aby sprawdzić, czy pliki są poprawnie posortowane – w przeciwnym razie join nie podejmie próby ich połączenia.
Wpisujemy:
join --check-order file-1.txt file-3.txt
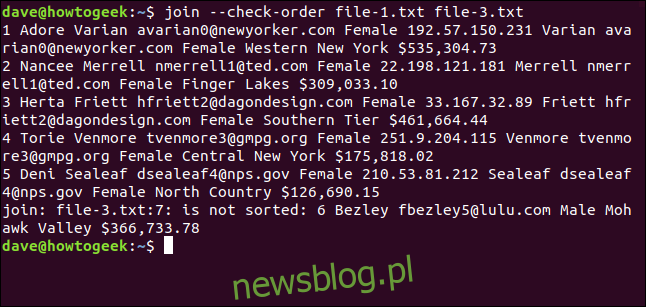
Join informuje nas, że wystąpił problem z linią siódmą w pliku file-3.txt.
Pliki z brakującymi wierszami
W pliku-4.txt usunięto ostatnią linię, więc brakuje ósmego wiersza. Zawartość pliku jest następująca:
1 Varian avarian0@newyorker.com Female Western New York $535,304.73 2 Merrell nmerrell1@ted.com Female Finger Lakes $309,033.10 3 Friett hfriett2@dagondesign.com Female Southern Tier $461,664.44 4 Venmore tvenmore3@gmpg.org Female Central New York $175,818.02 5 Sealeaf dsealeaf4@nps.gov Female North Country $126,690.15 6 Bezley fbezley5@lulu.com Male Mohawk Valley $366,733.78 7 Standen ustanden6@geocities.jp Female Capital District $674,634.93
Wprowadzamy następujące polecenie i, co zaskakujące, join nie zgłasza żadnych błędów i przetwarza wszystkie dostępne wiersze:
join file-1.txt file-4.txt
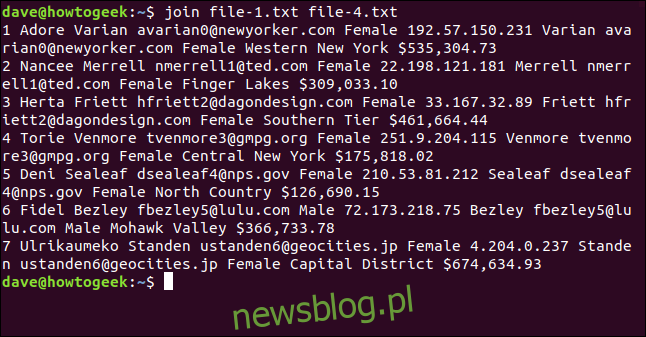
Wynik zawiera siedem połączonych wierszy.
Opcja -a (print unpaired) pozwala na wyświetlenie również wierszy, których nie można połączyć.
Aby polecenie join wypisało wiersze z pliku pierwszego, których nie można dopasować, wpisujemy:
join -a 1 file-1.txt file-4.txt
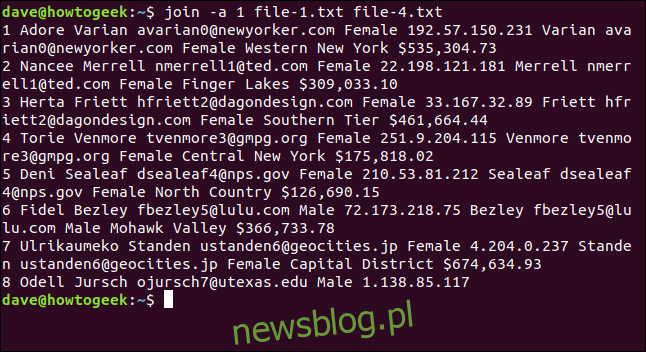
Wynik pokazuje siedem połączonych wierszy oraz linię ósmą z pliku pierwszego, która nie została dopasowana. Nie ma informacji o scaleniu, ponieważ plik-4.txt nie zawierał ósmego wiersza, do którego mogłaby zostać dopasowana. Jednakże, linia ta jest obecna w wyniku, więc można stwierdzić, że brak dopasowania jest wynikiem braku danych w pliku-4.txt.
Wprowadzając polecenie -v (pomijanie połączonych linii), możemy zobaczyć wszystkie linie, które nie pasują:
join -v file-1.txt file-4.txt

Widzimy, że jedyną linią, która nie ma dopasowania w pliku drugim, jest ósmy wiersz.
Dopasowywanie innych pól
Teraz spróbujmy połączyć dwa nowe pliki, korzystając z pola, które nie jest domyślne (pierwsze pole). Oto zawartość pliku-7.txt:
avarian0@newyorker.com Female 192.57.150.231 dsealeaf4@nps.gov Female 210.53.81.212 fbezley5@lulu.com Male 72.173.218.75 hfriett2@dagondesign.com Female 33.167.32.89 nmerrell1@ted.com Female 22.198.121.181 ojursch7@utexas.edu Male 1.138.85.117 tvenmore3@gmpg.org Female 251.9.204.115 ustanden6@geocities.jp Female 4.204.0.237
A oto zawartość pliku-8.txt:
Female avarian0@newyorker.com Western New York $535,304.73 Female dsealeaf4@nps.gov North Country $126,690.15 Male fbezley5@lulu.com Mohawk Valley $366,733.78 Female hfriett2@dagondesign.com Southern Tier $461,664.44 Female nmerrell1@ted.com Finger Lakes $309,033.10 Male ojursch7@utexas.edu Hudson Valley $663,821.09 Female tvenmore3@gmpg.org Central New York $175,818.02 Female ustanden6@geocities.jp Capital District $674,634.93
W tym przypadku, jedynym sensownym polem do połączenia jest adres e-mail, który jest pierwszym polem w pliku pierwszym i drugim polem w pliku drugim. Aby to uwzględnić, użyjemy opcji -1 (pierwszy plik, pierwsze pole) oraz -2 (drugi plik, drugie pole). Następnie podamy numer, który wskazuje, które pole w każdym pliku ma być użyte do połączenia.
Aby polecenie join wykorzystało pierwsze pole w pliku pierwszym oraz drugie pole w pliku drugim, wprowadzamy:
join -1 1 -2 2 file-7.txt file-8.txt
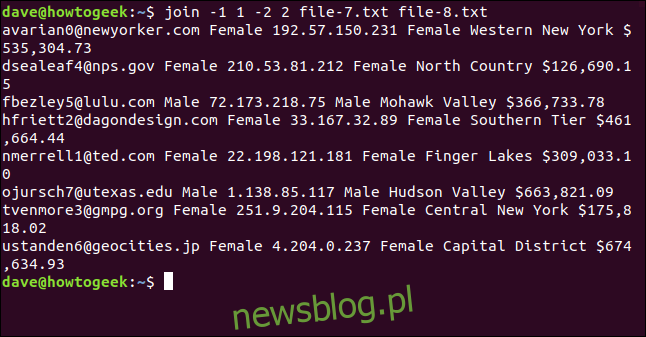
Pliki są łączone na podstawie adresu e-mail, który pojawia się jako pierwsze pole w wynikach.
Używanie różnych separatorów pól
A co, jeśli pliki mają pola oddzielone innymi znakami niż białe znaki?
Poniższe dwa pliki są rozdzielane przecinkami – jedyna spacja występuje między nazwami miejsc składającymi się z wielu słów:
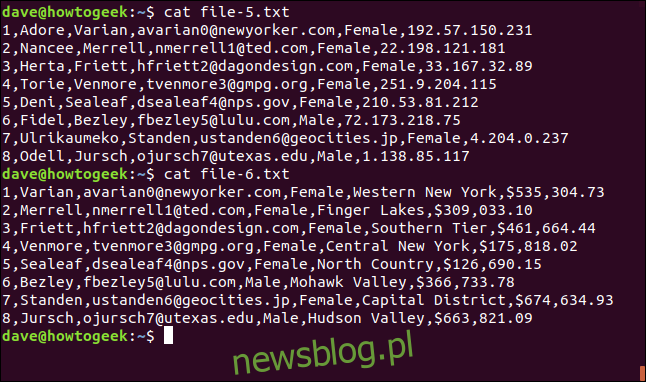
cat file-5.txt
cat file-6.txt
Możemy użyć opcji -t (separator), aby wskazać, którego znaku użyć jako separatora pól. W tym przypadku używamy przecinka, w związku z czym wpiszemy następujące polecenie:
join -t, file-5.txt file-6.txt
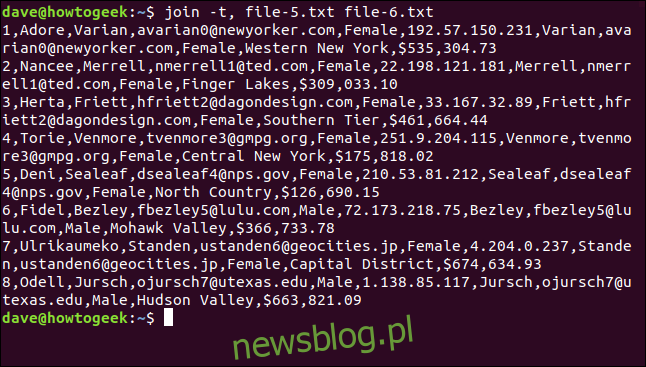
Wszystkie wiersze zostały dopasowane, a spacje zostały zachowane w nazwach miejsc.
Ignorowanie wielkości liter
Inny plik, file-9.txt, jest niemal identyczny z file-8.txt. Jedyną różnicą jest to, że niektóre adresy e-mail mają wielkie litery, co przedstawiono poniżej:
Female avarian0@newyorker.com Western New York $535,304.73 Female dsealeaf4@nps.gov North Country $126,690.15 Male Fbezley5@lulu.com Mohawk Valley $366,733.78 Female hfriett2@dagondesign.com Southern Tier $461,664.44 Female nmerrell1@ted.com Finger Lakes $309,033.10 Male Ojursch7@utexas.edu Hudson Valley $663,821.09 Female tvenmore3@gmpg.org Central New York $175,818.02 Female ustanden6@geocities.jp Capital District $674,634.93
Podczas łączenia plików file-7.txt i file-8.txt wszystko działało idealnie. Zobaczmy, co się stanie, gdy połączymy file-7.txt z file-9.txt.
Wpisujemy:
join -1 1 -2 2 file-7.txt file-9.txt
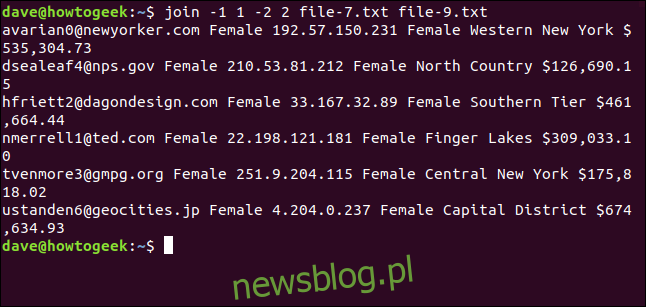
W tym przypadku dopasowano jedynie sześć linii. Różnice w wielkości liter uniemożliwiły połączenie pozostałych dwóch adresów e-mail.
Wpisujemy:
join -1 1 -2 2 -i file-7.txt file-9.txt
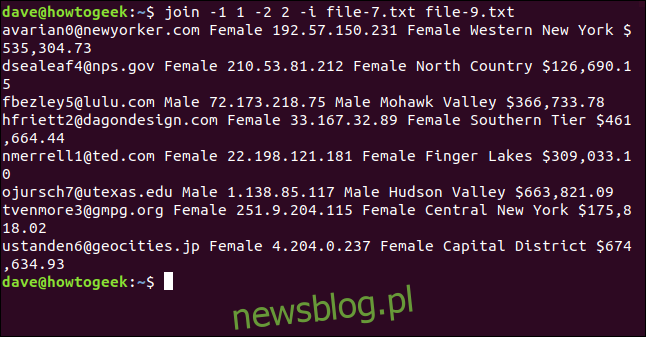
Wszystkie osiem linii zostało dopasowanych i pomyślnie połączonych.
Mieszanie i łączenie danych
Polecenie join jest potężnym narzędziem, które może okazać się niezwykle przydatne w trudnych zadaniach związanych z przygotowaniem danych. Bez względu na to, czy musisz przeanalizować dane, czy też przekształcić je w celu importu do innego systemu, z pewnością docenisz, że masz je w swoim arsenale!
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.