ETL, czyli wyodrębnianie, transformacja i ładowanie, to proces, w którym dane są pozyskiwane z różnych miejsc, modyfikowane do odpowiedniej postaci, a następnie przesyłane do docelowego systemu. Narzędzia ETL służą do pobierania informacji z rozmaitych źródeł, ich konwersji do formatu zrozumiałego dla systemów docelowych lub zgodnego z modelem danych, a finalnie do umieszczania ich w wybranej bazie danych, hurtowni danych, czy nawet jeziorze danych.
Pamiętam czasy, jakieś 15-20 lat temu, kiedy pojęcie ETL było znane tylko wąskiemu gronu specjalistów. Wówczas popularne były niestandardowe zadania wsadowe wykonywane na serwerach lokalnych.
Wiele przedsięwzięć wykorzystywało pewną formę ETL, choć często o tym nie wiedziano lub nie nazywano tego w ten sposób. Gdy wyjaśniałem projekty, w których wykorzystywano procesy ETL, opisywałem je jako coś wyjątkowego, niczym technologię z innego świata.
Dziś sytuacja wygląda inaczej. Migracja do chmury jest priorytetem, a narzędzia ETL stanowią kluczowy element architektury większości projektów.
Przenoszenie danych do chmury wiąże się z pobieraniem informacji z systemów lokalnych i przekształcaniem ich w taki sposób, aby idealnie pasowały do środowiska chmurowego. Jest to dokładnie zadanie, które wykonują narzędzia ETL.
Historia ETL i jej znaczenie we współczesności
Źródło: aws.amazon.com
Podstawowe funkcje ETL od zawsze pozostają niezmienne.
Narzędzia ETL pobierają dane z różnych źródeł, takich jak bazy danych, pliki tekstowe, usługi internetowe, a ostatnio także aplikacje działające w chmurze.
Tradycyjnie proces ten polegał na pobieraniu plików z systemów plików Unix, a następnie ich wstępnym, właściwym i końcowym przetwarzaniu.
Można było zaobserwować powtarzający się wzorzec nazw folderów, takich jak:
- Wejście
- Wyjście
- Błąd
- Archiwum
W obrębie tych folderów istniała dodatkowo struktura podfolderów, najczęściej oparta na datach.
Był to standardowy sposób przetwarzania danych wejściowych i przygotowywania ich do załadowania do bazy danych.
Obecnie systemy plików Unix nie są już tak powszechne, a często brakuje nawet plików. W zamian mamy API – interfejsy programowania aplikacji. Plik jako format wejściowy może, ale nie musi, być używany.
Dane mogą być przechowywane w pamięci podręcznej lub nadal w pliku. Niezależnie od sposobu przechowywania, muszą one mieć określoną strukturę, najczęściej JSON lub XML. W niektórych przypadkach wystarczy zwykły format CSV.
To użytkownik definiuje format wejściowy i decyduje, czy proces ma obejmować historię plików wejściowych. Nie jest to już krok standardowy.
Transformacja
Narzędzia ETL przekształcają dane, aby były odpowiednie do analizy. Obejmuje to czyszczenie, weryfikację, wzbogacanie i agregację danych.
Tradycyjnie dane przechodziły przez złożoną logikę proceduralną napisaną w Pro-C lub PL/SQL, która obejmowała etapy tymczasowego przechowywania, przekształcania i przygotowywania schematów danych. Był to tak samo standardowy proces, jak rozdzielanie plików wejściowych do odpowiednich podfolderów na podstawie etapu przetwarzania.
Choć wydawało się to naturalne, było to fundamentalnie złe. Bezpośrednie przekształcanie danych wejściowych bez ich wcześniejszego zapisu prowadziło do utraty najważniejszej zalety danych surowych – ich niezmienności. Projekty po prostu pozbywały się ich bez możliwości odzyskania.
W dzisiejszych czasach im mniej transformacji surowych danych na samym początku, tym lepiej. Chodzi o pierwsze zapisanie danych w systemie. Kolejnym krokiem będzie ich modyfikacja i transformacja modelu danych, ale ważne jest, aby surowe dane zachować w jak najbardziej nienaruszonej strukturze. To ogromna zmiana w stosunku do czasów przetwarzania danych lokalnie.
Ładowanie
Narzędzia ETL umieszczają przekształcone dane w docelowej bazie danych lub hurtowni danych. Proces ten obejmuje tworzenie tabel, definiowanie relacji między nimi i umieszczanie danych w odpowiednich polach.
Krok ładowania jest chyba jedynym, który od lat przebiega według tego samego schematu. Zmieniła się tylko docelowa baza danych. Tam, gdzie wcześniej najczęściej była to baza Oracle, dziś może być to cokolwiek dostępnego w chmurze AWS.
ETL w obecnym środowisku chmurowym
Przenosząc dane z systemów lokalnych do chmury (AWS), nie obejdzie się bez narzędzia ETL. Ten element architektury chmurowej stał się kluczowy, ponieważ błąd na tym etapie wpływa na wszystko, co nastąpi później.
Choć istnieje wiele rozwiązań, skupię się na trzech, z którymi mam najwięcej osobistych doświadczeń:
- Data Migration Service (DMS) – natywna usługa AWS.
- Informatica ETL – komercyjny lider w dziedzinie ETL, który z powodzeniem przeniósł swoją działalność z rozwiązań lokalnych do chmury.
- Matillion dla AWS – nowy gracz w środowiskach chmurowych, nie jest natywny dla AWS, lecz dla chmury, bez historii porównywalnej z Informatica.
AWS DMS jako narzędzie ETL
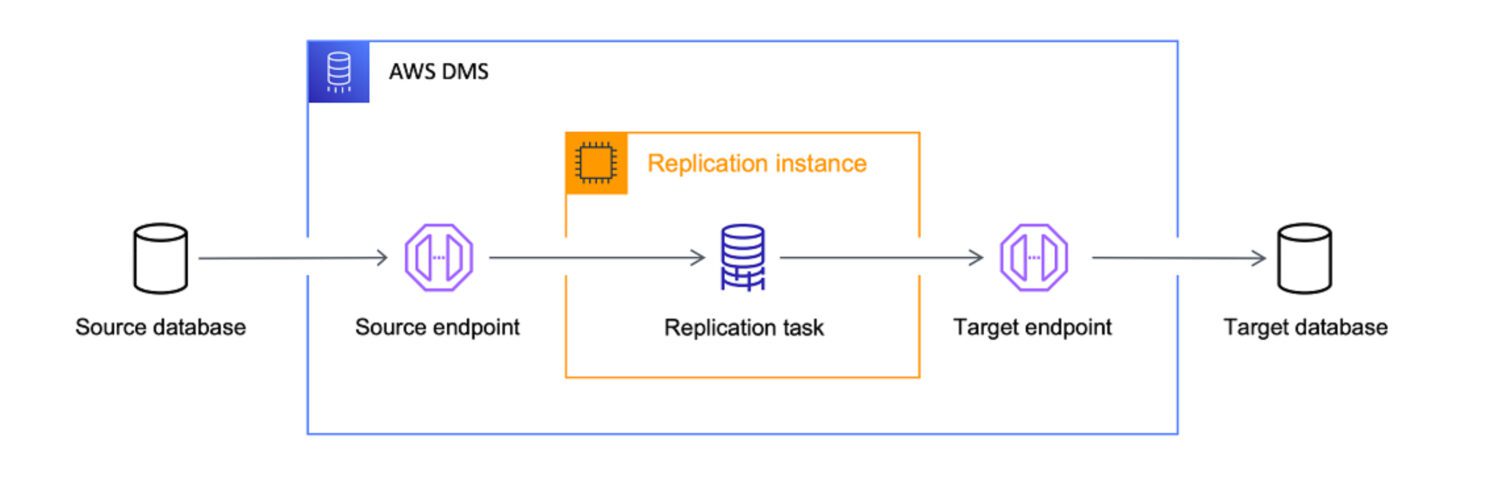
Źródło: aws.amazon.com
AWS Data Migration Services (DMS) to w pełni zarządzana usługa umożliwiająca migrację danych z różnych źródeł do AWS. Obsługuje ona wiele scenariuszy migracji.
- Migracje homogeniczne (np. z Oracle do Amazon RDS for Oracle).
- Migracje heterogeniczne (np. z Oracle do Amazon Aurora).
DMS pozwala na migrację danych z różnych źródeł, w tym baz danych, hurtowni danych i aplikacji SaaS, do różnych celów, takich jak Amazon S3, Amazon Redshift i Amazon RDS.
AWS traktuje DMS jako kluczowe narzędzie do przenoszenia danych z dowolnego źródła do chmury. Chociaż głównym zadaniem DMS jest kopiowanie danych, dobrze radzi sobie również z ich transformacją podczas migracji.
Można zdefiniować zadania DMS w formacie JSON, aby zautomatyzować różne transformacje podczas kopiowania danych ze źródła do celu:
- Połączenie kilku tabel lub kolumn źródłowych w jedną wartość.
- Podział wartości źródłowej na wiele pól docelowych.
- Zamiana danych źródłowych na inne wartości docelowe.
- Usuwanie zbędnych danych lub tworzenie nowych na podstawie kontekstu wejściowego.
DMS może być z powodzeniem wykorzystywany jako narzędzie ETL, choć nie jest tak zaawansowany jak inne rozwiązania. Sprawdzi się jednak, jeśli cel projektu zostanie jasno zdefiniowany.
Czynniki przydatności
DMS oferuje pewne możliwości ETL, ale są one głównie przeznaczone do scenariuszy migracji danych. W pewnych sytuacjach lepszym rozwiązaniem będzie jednak użycie DMS zamiast bardziej rozbudowanych narzędzi ETL, takich jak Informatica czy Matillion:
Matillion ETL
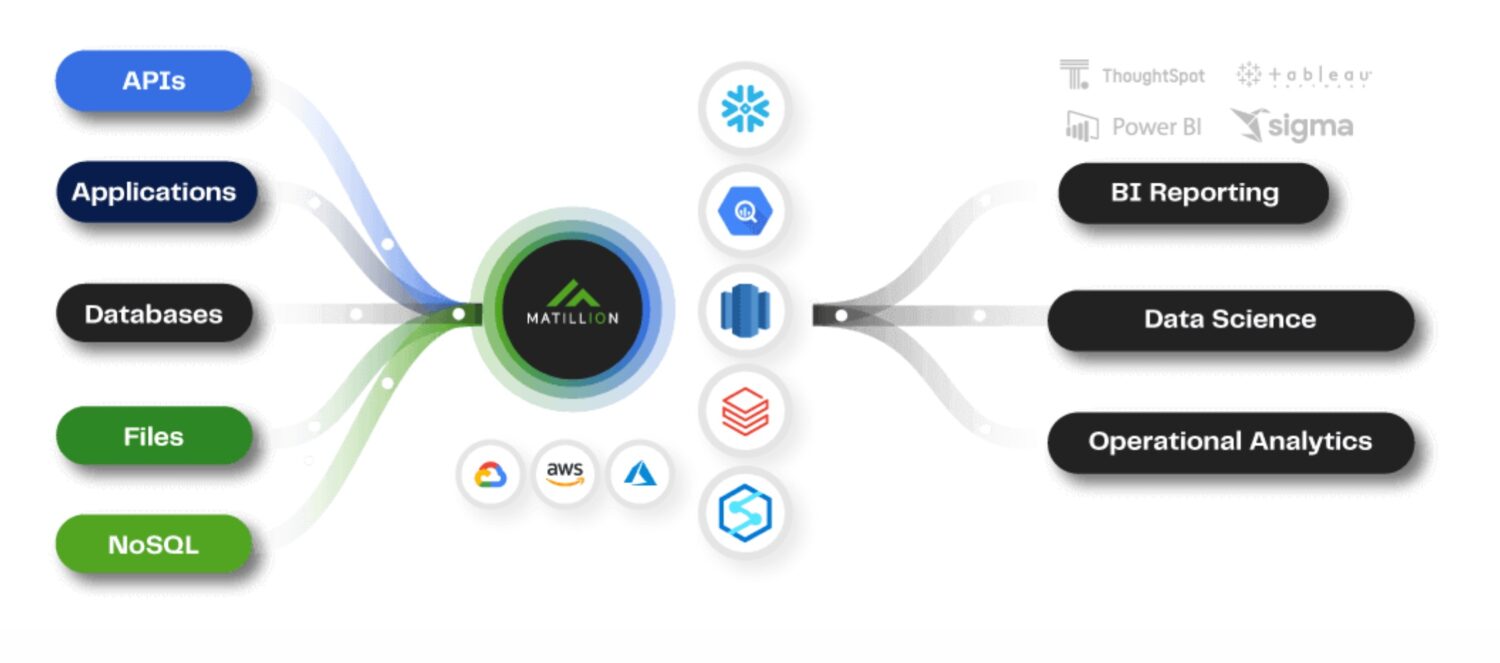
źródło: matillion.com
Matillion jest natywnym rozwiązaniem chmurowym, które integruje dane z różnych źródeł, w tym baz danych, aplikacji SaaS i systemów plików. Oferuje wizualny interfejs do tworzenia potoków ETL oraz współpracuje z różnymi usługami AWS, takimi jak Amazon S3, Amazon Redshift i Amazon RDS.
Matillion jest łatwy w obsłudze i stanowi dobre rozwiązanie dla organizacji, które dopiero zaczynają korzystać z narzędzi ETL lub mają mniej złożone wymagania integracyjne.
Jednak Matillion to w pewnym sensie czysta karta. Ma pewne wbudowane funkcje, ale aby z nich skorzystać, trzeba je zakodować. Nie można oczekiwać, że Matillion zacznie działać od razu, bez dodatkowej konfiguracji.
Matillion często jest określany jako narzędzie ELT, a nie ETL, co oznacza, że bardziej naturalne jest ładowanie danych przed ich transformacją.
Czynniki przydatności
Matillion najefektywniej przekształca dane po ich zapisaniu w bazie danych. Wynika to z konieczności tworzenia niestandardowych skryptów. Efektywność transformacji zależy od jakości napisanego kodu, dlatego lepiej przeprowadzać ją w docelowym systemie bazy danych, a Matillionowi zostawić proste zadanie ładowania danych.
Matillion oferuje szereg funkcji do integracji danych, ale nie zapewnia takiego poziomu jakości danych i funkcji zarządzania, jak niektóre inne narzędzia ETL.
Matillion można skalować w zależności od potrzeb organizacji, ale nie jest idealny do przetwarzania bardzo dużych ilości danych. Przetwarzanie równoległe jest dość ograniczone. Pod tym względem Informatica jest zdecydowanie lepszym wyborem.
Dla wielu organizacji Matillion dla AWS oferuje jednak wystarczającą skalowalność i możliwości przetwarzania równoległego.
Informatica ETL
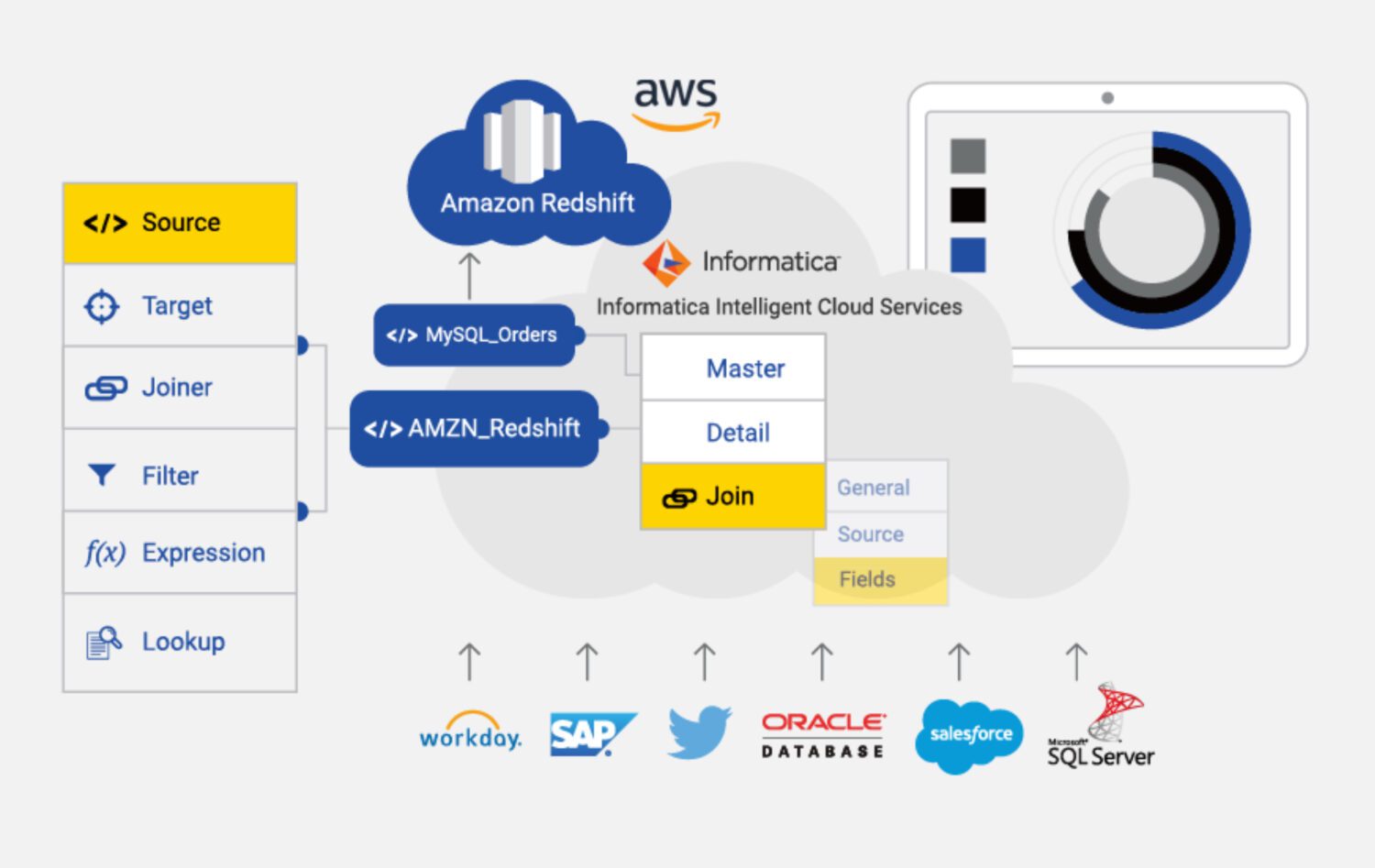
źródło: informatica.com
Informatica dla AWS to oparte na chmurze narzędzie ETL, które pomaga w integracji i zarządzaniu danymi z różnych źródeł. Jest to w pełni zarządzana usługa oferująca funkcje profilowania danych, ich jakości i nadzoru.
Główne cechy Informatica dla AWS to:
Czynniki przydatności
Informatica jest najbardziej zaawansowanym narzędziem ETL na tej liście. Może być jednak droższe i trudniejsze w obsłudze niż niektóre inne rozwiązania dostępne w AWS.
Informatica może być kosztowna, zwłaszcza dla mniejszych organizacji. Model cenowy oparty jest na wykorzystaniu, co oznacza, że koszty mogą wzrosnąć wraz ze zwiększeniem zapotrzebowania.
Konfiguracja może być skomplikowana, zwłaszcza dla osób bez doświadczenia w narzędziach ETL. Wymaga to czasu i zasobów.
Informatica ma złożoną krzywą uczenia się, co może stanowić problem dla osób, które muszą szybko zintegrować dane lub mają ograniczone zasoby szkoleniowe.
Informatica może być mniej skuteczna w integracji danych ze źródeł spoza AWS. W takich przypadkach lepiej sprawdzi się DMS lub Matillion.
Informatica to zamknięty system z ograniczonymi możliwościami dostosowania do specyficznych potrzeb projektu. Użytkownik musi korzystać z gotowej konfiguracji, co ogranicza elastyczność.
Podsumowanie
Nie istnieje jedno uniwersalne rozwiązanie, nawet w przypadku narzędzi ETL w AWS.
Informatica to najbardziej zaawansowane i kosztowne rozwiązanie, które jest warte rozważenia, jeśli:
- Projekt jest duży, a przyszłe dane również będą wykorzystywane w Informatica.
- Organizacja dysponuje zespołem wykwalifikowanych programistów i konfiguratorów Informatica.
- Organizacja ceni sobie solidne wsparcie techniczne i jest gotowa za nie zapłacić.
Matillion sprawdzi się, gdy:
- Projekt nie jest bardzo złożony.
- Potrzebne są niestandardowe kroki w przetwarzaniu danych, a elastyczność jest kluczowa.
- Organizacja jest gotowa samodzielnie zbudować większość funkcjonalności.
Dla mniej skomplikowanych projektów idealny będzie DMS dla AWS, który jako usługa natywna powinien dobrze spełnić swoje zadanie.
Następnie warto zapoznać się z narzędziami do transformacji danych, które pomogą w lepszym zarządzaniu danymi.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.