Bezpieczne haszowanie za pomocą Python Hashlib
Ten przewodnik wprowadzi Cię w tajniki tworzenia bezpiecznych skrótów, wykorzystując wbudowane możliwości modułu hashlib w języku Python.
Zrozumienie mechanizmów haszowania i umiejętność programowego generowania bezpiecznych skrótów może okazać się bardzo przydatne, nawet jeśli nie jesteś specjalistą od bezpieczeństwa aplikacji. Dlaczego tak jest?
Podczas pracy nad projektami w Pythonie często pojawiają się sytuacje, w których trzeba chronić hasła i inne wrażliwe dane przed nieautoryzowanym dostępem, na przykład w bazach danych lub plikach z kodem źródłowym. W takich przypadkach o wiele bezpieczniej jest zastosować algorytm haszujący do tych poufnych informacji i przechowywać wygenerowany skrót zamiast ich oryginalnej postaci.
W niniejszym opracowaniu wyjaśnimy, czym właściwie jest haszowanie i na czym polega różnica między nim a szyfrowaniem. Przyjrzymy się także cechom, jakimi powinny charakteryzować się bezpieczne funkcje skrótu. Następnie wykorzystamy popularne algorytmy haszujące do utworzenia skrótu z tekstu w Pythonie, korzystając z wbudowanego modułu hashlib.
To i wiele więcej, więc zaczynajmy!
Czym jest haszowanie?
Haszowanie to proces przetwarzania ciągu znaków (wiadomości) w taki sposób, aby uzyskać wynik o stałej długości, zwany haszem. Oznacza to, że dla danego algorytmu haszującego długość wyjściowego hasza jest zawsze taka sama, niezależnie od długości tekstu wejściowego. Ale jak to się ma do szyfrowania?
Szyfrowanie polega na przekształceniu wiadomości lub tekstu jawnego przy użyciu algorytmu szyfrującego, w wyniku czego otrzymujemy zaszyfrowane dane. Następnie, przy użyciu odpowiedniego algorytmu deszyfrującego, możemy odzyskać pierwotną wiadomość z zaszyfrowanych danych.
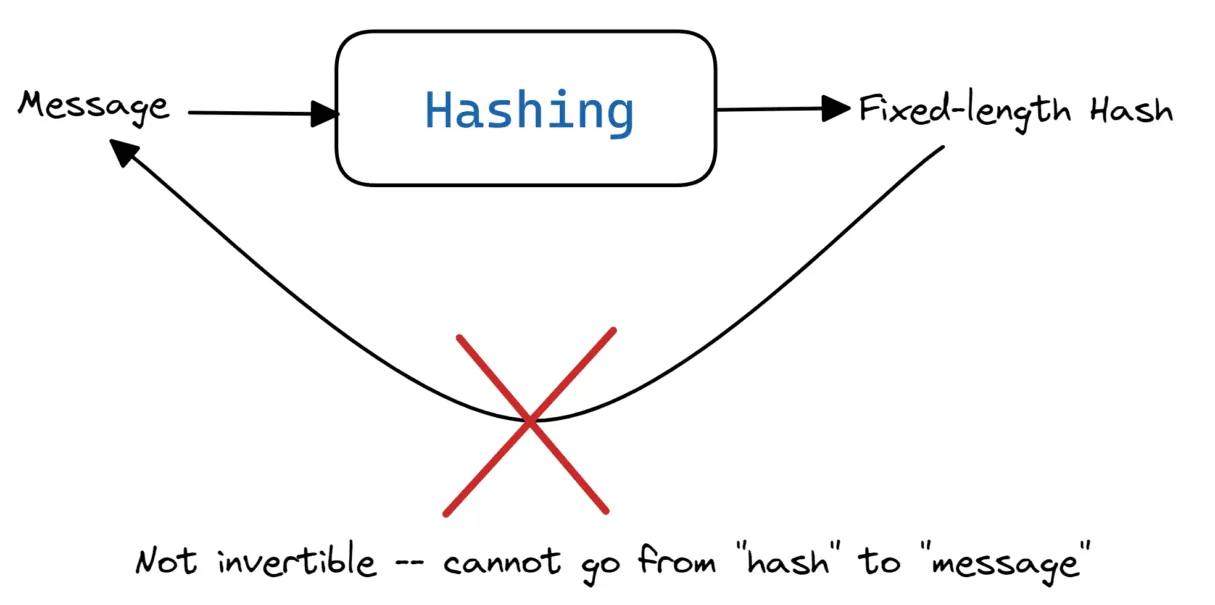
Haszowanie natomiast działa inaczej. Jak już wiemy, szyfrowanie jest procesem odwracalnym, umożliwiającym przejście od zaszyfrowanej wiadomości do jej pierwotnej postaci i odwrotnie.
W odróżnieniu od szyfrowania, haszowanie nie jest procesem odwracalnym. Oznacza to, że nie możemy na podstawie wygenerowanego hasza odzyskać oryginalnej wiadomości wejściowej.
Właściwości funkcji skrótu
Przyjrzyjmy się pokrótce cechom, które powinny charakteryzować funkcje skrótu:
- Determinizm: Funkcje skrótu są deterministyczne. Oznacza to, że dla tej samej wiadomości (m) skrót zawsze będzie taki sam.
- Odporność na atak preimage: Jak już wcześniej wspomniano, haszowanie nie jest procesem odwracalnym. Właściwość odporności na atak preimage oznacza, że niemożliwe jest odtworzenie wiadomości (m) na podstawie jej skrótu.
- Odporność na kolizje: Znalezienie dwóch różnych wiadomości (m1 i m2), których skróty są identyczne, powinno być trudne (lub niemożliwe z obliczeniowego punktu widzenia). Tę cechę nazywamy odpornością na kolizje.
- Odporność na drugi preimage: Oznacza to, że dla danej wiadomości (m1) i odpowiadającego jej skrótu niemożliwe jest znalezienie innej wiadomości (m2), takiej że hash(m1) = hash(m2).
Moduł hashlib w Pythonie
Moduł hashlib, będący częścią standardowej biblioteki Pythona, udostępnia implementacje różnych algorytmów haszujących i skrótów wiadomości, w tym popularnych algorytmów SHA i MD5.
Aby skorzystać z konstruktorów i funkcji oferowanych przez moduł hashlib, należy go najpierw zaimportować do środowiska pracy, używając następującej komendy:
import hashlib
Moduł hashlib udostępnia stałe algorytmy_dostępne i algorytmy_gwarantowane, które reprezentują zbiór algorytmów, których implementacje są odpowiednio dostępne i gwarantowane na danej platformie.
Warto zauważyć, że algorytmy_gwarantowane stanowią podzbiór algorytmów_dostępnych.

Uruchom interpreter Pythona (REPL), zaimportuj moduł hashlib i sprawdź zawartość stałych algorytmy_dostępne i algorytmy_gwarantowane:
>>> hashlib.algorithms_available
# Wynik
{'md5', 'md5-sha1', 'sha3_256', 'shake_128', 'sha384', 'sha512_256', 'sha512', 'md4',
'shake_256', 'whirlpool', 'sha1', 'sha3_512', 'sha3_384', 'sha256', 'ripemd160', 'mdc2',
'sha512_224', 'blake2s', 'blake2b', 'sha3_224', 'sm3', 'sha224'}
>>> hashlib.algorithms_guaranteed
# Wynik
{'md5', 'shake_256', 'sha3_256', 'shake_128', 'blake2b', 'sha3_224', 'sha3_384',
'sha384', 'sha256', 'sha1', 'sha3_512', 'sha512', 'blake2s', 'sha224'}
Jak widać, algorytmy_gwarantowane stanowią faktycznie podzbiór algorytmów_dostępnych.
Jak tworzyć obiekty haszujące w Pythonie

Teraz nauczymy się tworzyć obiekty haszujące w Pythonie. Obliczymy skrót SHA256 dla przykładowego ciągu znaków, korzystając z następujących metod:
- Ogólny konstruktor new().
- Konstruktory specyficzne dla danego algorytmu.
Wykorzystanie konstruktora new().
Zacznijmy od zdefiniowania ciągu znaków, który chcemy poddać haszowaniu:
>>> message = "newsblog.pl jest super!"
Aby utworzyć instancję obiektu haszującego, użyjemy konstruktora new(), przekazując jako argument nazwę algorytmu, jak poniżej:
>>> sha256_hash = hashlib.new("SHA256")
Teraz możemy wywołać metodę update() na obiekcie haszującym, przekazując jako argument nasz ciąg znaków:
>>> sha256_hash.update(message)
W tym momencie zostanie wygenerowany błąd, ponieważ algorytmy haszujące działają tylko na ciągach bajtów.
Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: Unicode-objects must be encoded before hashing
Aby przekształcić ciąg znaków w ciąg bajtów, możemy wywołać na nim metodę encode(), a następnie użyć jej wyniku w wywołaniu metody update(). Po wykonaniu tych czynności, możemy wywołać metodę hexdigest(), która zwróci skrót sha256 odpowiadający naszemu ciągowi znaków.
sha256_hash.update(message.encode()) sha256_hash.hexdigest() # Wynik: '8781401b3a8194d2509c367b8320d35cb85a1ef9f8ab14f34bb898074a00c784'
Zamiast kodować ciąg znaków za pomocą metody encode(), możemy również zdefiniować go od razu jako ciąg bajtów, poprzedzając go literą b, w następujący sposób:
message = b"newsblog.pl jest super!" sha256_hash.update(message) sha256_hash.hexdigest() # Wynik: '8781401b3a8194d2509c367b8320d35cb85a1ef9f8ab14f34bb898074a00c784'
Otrzymany skrót jest taki sam jak poprzednio, co potwierdza deterministyczną naturę funkcji skrótu.
Warto też zauważyć, że nawet niewielka zmiana w treści wiadomości powinna skutkować drastyczną zmianą wygenerowanego skrótu (tzw. „efekt lawinowy”).
Aby to zweryfikować, zmieńmy w naszym tekście słowo "super" na "Super" i obliczmy skrót:
message = "newsblog.pl jest Super!"
h1 = hashlib.new("SHA256")
h1.update(message.encode())
h1.hexdigest()
# Wynik: 'f6c926b6744e2f12f24280e472b438f68716f5a0383d0906c040b8e1056396bb'
Widzimy, że wygenerowany skrót uległ całkowitej zmianie.
Wykorzystanie konstruktora specyficznego dla algorytmu
W poprzednim przykładzie użyliśmy ogólnego konstruktora new() i przekazaliśmy "SHA256" jako nazwę algorytmu w celu utworzenia obiektu haszującego.
Zamiast tego możemy również użyć konstruktora sha256(), jak pokazano poniżej:
sha256_hash = hashlib.sha256() message= "newsblog.pl jest super!" sha256_hash.update(message.encode()) sha256_hash.hexdigest() # Wynik: '8781401b3a8194d2509c367b8320d35cb85a1ef9f8ab14f34bb898074a00c784'
Otrzymany skrót jest identyczny z haszem wygenerowanym wcześniej dla ciągu znaków "newsblog.pl jest super!".
Atrybuty obiektów haszujących
Obiekty haszujące udostępniają kilka przydatnych atrybutów:
- Atrybut digest_size określa rozmiar skrótu w bajtach. Na przykład algorytm SHA256 zwraca 256-bitowy skrót, co odpowiada 32 bajtom.
- Atrybut block_size odnosi się do rozmiaru bloku danych używanego w algorytmie haszującym.
- Atrybut name to nazwa algorytmu, której możemy użyć w konstruktorze new(). Wartość tego atrybutu może okazać się przydatna, gdy obiekty skrótu nie posiadają opisowych nazw.
Sprawdźmy te atrybuty dla utworzonego wcześniej obiektu sha256_hash:
>>> sha256_hash.digest_size 32 >>> sha256_hash.block_size 64 >>> sha256_hash.name 'sha256'
Teraz przyjrzymy się praktycznym zastosowaniom haszowania, wykorzystując moduł hashlib w Pythonie.
Praktyczne przykłady haszowania

Weryfikacja integralności oprogramowania i plików
Jako programiści często pobieramy i instalujemy różne pakiety oprogramowania. Dzieje się tak niezależnie od tego, czy pracujemy na dystrybucji Linuksa, systemie Windows czy macOS.
Należy jednak pamiętać, że niektóre kopie oprogramowania mogą nie pochodzić z zaufanego źródła. Często obok linku do pobrania można znaleźć sumę kontrolną (skrót) pliku. Możesz zweryfikować integralność pobranego oprogramowania, obliczając jego skrót i porównując go z oficjalnym haszem.
Podobne podejście można zastosować do plików przechowywanych na komputerze. Nawet niewielka zmiana zawartości pliku drastycznie zmieni jego skrót, dzięki czemu można łatwo sprawdzić, czy plik nie został zmodyfikowany, weryfikując jego skrót.
Oto prosty przykład. Utwórz plik tekstowy "my_file.txt" w katalogu roboczym i umieść w nim przykładową treść.
$ cat my_file.txt To jest przykładowy plik tekstowy. Obliczymy skrót SHA256 tego pliku i sprawdzimy, czy plik został zmodyfikowany poprzez ponowne obliczenie skrótu.
Następnie możesz otworzyć plik w trybie odczytu binarnego ("rb"), wczytać jego zawartość i obliczyć skrót SHA256, jak poniżej:
>>> import hashlib
>>> with open("my_file.txt","rb") as file:
... file_contents = file.read()
... sha256_hash = hashlib.sha256()
... sha256_hash.update(file_contents)
... original_hash = sha256_hash.hexdigest()
Zmienna original_hash przechowuje skrót pliku "my_file.txt" w jego bieżącym stanie.
>>> original_hash # Wynik: '1a47586d9f1e37ff267401532a4947b14454e74520ddb603ffb98d643a8489a4'
Teraz zmodyfikuj plik "my_file.txt". Możesz na przykład usunąć nadmiarowe spacje przed słowem "Obliczymy". 🙂
Oblicz skrót ponownie i zapisz go w zmiennej computed_hash.
>>> import hashlib
>>> with open("my_file.txt","rb") as file:
... file_contents = file.read()
... sha256_hash = hashlib.sha256()
... sha256_hash.update(file_contents)
... computed_hash = sha256_hash.hexdigest()
Następnie dodaj prostą instrukcję assert, która sprawdzi, czy obliczony_hash jest równy oryginalnemu haszowi.
>>> assert computed_hash == original_hash
Jeśli plik został zmodyfikowany (co w tym przypadku jest prawdą), otrzymasz błąd AssertionError:
Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError
Haszowanie możesz również wykorzystać do przechowywania poufnych danych, takich jak hasła, w bazach danych. Dodatkowo, haszowanie może być pomocne w procesie uwierzytelniania podczas łączenia się z bazą danych – porównujesz skrót wprowadzonego hasła ze skrótem zapisanym w bazie danych.
Podsumowanie
Mam nadzieję, że ten poradnik pomógł Ci zrozumieć, jak generować bezpieczne skróty w Pythonie. Oto kluczowe informacje:
- Moduł hashlib w Pythonie udostępnia gotowe implementacje różnych algorytmów haszujących. Listę algorytmów gwarantowanych na Twojej platformie możesz sprawdzić, korzystając z hashlib.algorithms_guaranteed.
- Aby utworzyć obiekt haszujący, możesz użyć ogólnego konstruktora new() z składnią: hashlib.new("nazwa-algorytmu"). Alternatywnie, możesz skorzystać z konstruktorów dedykowanych konkretnym algorytmom, na przykład: hashlib.sha256() dla skrótu SHA256.
- Po zainicjowaniu ciągu znaków i utworzeniu obiektu haszującego, możesz wywołać na obiekcie haszującym metodę update(), a następnie metodę hexdigest() w celu uzyskania skrótu.
- Haszowanie jest przydatne w wielu zastosowaniach, takich jak weryfikacja integralności plików i oprogramowania, bezpieczne przechowywanie danych poufnych (np. haseł) w bazach danych i wielu innych.
Teraz możesz przejść do kolejnego etapu i nauczyć się, jak napisać generator losowych haseł w Pythonie.
