Co to jest Google JAX? Wszystko co musisz wiedzieć
Google JAX, skrót od Just After Execution, to zaawansowane narzędzie stworzone przez Google, które ma na celu znaczne przyspieszenie procesów związanych z uczeniem maszynowym.
Można o nim myśleć jak o rozszerzeniu możliwości Pythona, które umożliwia szybsze przeprowadzanie obliczeń naukowych, transformacje funkcji, implementacje głębokiego uczenia, budowę sieci neuronowych i wiele innych zaawansowanych zadań.
O Google JAX
Podstawowym narzędziem obliczeniowym w Pythonie jest biblioteka NumPy. Oferuje ona szeroki zakres funkcji, takich jak operacje agregacji, działania na wektorach, algebra liniowa, manipulacja tablicami wielowymiarowymi i macierzami, a także wiele innych złożonych funkcji.
Czy można by jeszcze bardziej zoptymalizować obliczenia wykonywane za pomocą NumPy, zwłaszcza gdy operujemy na ogromnych zbiorach danych?
Czy istnieje rozwiązanie, które działa równie efektywnie na różnych rodzajach procesorów, takich jak GPU i TPU, bez konieczności modyfikacji kodu?
A co gdyby istniał system, który potrafi automatycznie i efektywnie wykonywać transformacje funkcji, które można ze sobą łączyć?
Google JAX to biblioteka (lub framework, jak podaje Wikipedia), która realizuje właśnie te cele i oferuje znacznie więcej. Została zaprojektowana, aby zoptymalizować wydajność i usprawnić wykonywanie zadań w obszarze uczenia maszynowego (ML) i głębokiego uczenia. Google JAX udostępnia unikalne transformacje, które wyróżniają go spośród innych bibliotek ML i wspierają zaawansowane obliczenia naukowe, szczególnie w kontekście głębokiego uczenia i sieci neuronowych. Oto kluczowe transformacje oferowane przez JAX:
- Automatyczne różniczkowanie
- Automatyczna wektoryzacja
- Automatyczne równoległe przetwarzanie
- Kompilacja just-in-time (JIT)
Unikalne możliwości Google JAX
Wszystkie te transformacje korzystają z XLA (Accelerated Linear Algebra), aby osiągnąć wyższą wydajność i zoptymalizować zarządzanie pamięcią. XLA to wyspecjalizowany silnik kompilatora, który optymalizuje algebrę liniową i przyspiesza działanie modeli TensorFlow. Korzystanie z XLA w kodzie Pythona nie wymaga znaczących zmian w sposobie programowania!
Przyjrzyjmy się teraz bliżej każdej z tych kluczowych funkcji.
Funkcje Google JAX
Google JAX posiada zbiór ważnych transformacji, które można ze sobą łączyć, aby zwiększyć wydajność i efektywność zadań głębokiego uczenia. Przykładem jest automatyczne różniczkowanie, które pozwala obliczać gradient funkcji i znajdować pochodne dowolnego rzędu. Podobnie, automatyczne równoległe przetwarzanie i JIT umożliwiają wykonywanie wielu zadań równolegle. Te transformacje są niezwykle istotne w zastosowaniach takich jak robotyka, gry, a nawet badania naukowe.
Transformacja komponowalna to funkcja, która przekształca zbiór danych w inną formę. Są one nazywane komponowalnymi, ponieważ są niezależne od reszty programu i nie posiadają stanu, czyli dla tych samych danych wejściowych zawsze zwracają te same dane wyjściowe.
Y(x) = T: (f(x))
W powyższym równaniu f(x) reprezentuje oryginalną funkcję, na której przeprowadzana jest transformacja. Y(x) jest funkcją wynikową po zastosowaniu transformacji.
Na przykład, jeśli mamy funkcję o nazwie "total_bill_amt" i chcemy uzyskać jej transformację, możemy po prostu zastosować wybraną transformację, np. gradient (grad):
grad_total_bill = grad(total_bill_amt)
Przekształcając funkcje numeryczne za pomocą funkcji takich jak grad(), możemy w łatwy sposób obliczyć ich pochodne wyższego rzędu, które znajdują szerokie zastosowanie w algorytmach optymalizacji uczenia głębokiego, takich jak zejście gradientu, przyspieszając i zwiększając efektywność tych algorytmów. Podobnie, używając jit(), możemy kompilować programy Pythona w trybie just-in-time.
#1. Automatyczne różniczkowanie
Python korzysta z funkcji autograd do automatycznego różniczkowania kodu NumPy i standardowego kodu Pythona. JAX wykorzystuje zmodyfikowaną wersję autogradu (tj. grad) w połączeniu z XLA (Accelerated Linear Algebra) do automatycznego różniczkowania i obliczania pochodnych dowolnego rzędu dla GPU (jednostek przetwarzania graficznego) i TPU (jednostek przetwarzania tensorów).
Krótka informacja o TPU, GPU i CPU: CPU, czyli jednostka centralna, odpowiada za zarządzanie wszystkimi operacjami w komputerze. GPU to dodatkowy procesor, który zwiększa moc obliczeniową i umożliwia wykonywanie zaawansowanych zadań. TPU to wyspecjalizowana jednostka, stworzona z myślą o złożonych i wymagających obciążeniach, takich jak sztuczna inteligencja i algorytmy głębokiego uczenia.
Podobnie jak funkcja autograd, która potrafi różniczkować pętle, rekurencje, rozgałęzienia itd., JAX używa funkcji grad() do obliczania gradientów w trybie odwrotnym (propagacja wsteczna). Co więcej, możemy różniczkować funkcję do dowolnego rzędu za pomocą grad():
grad(grad(grad(sin θ))) (1,0)
Automatyczne różniczkowanie wyższego rzędu
Jak już wspomniano, grad jest niezwykle przydatny do obliczania pochodnych cząstkowych funkcji. Pochodna cząstkowa jest wykorzystywana do wyznaczenia spadku gradientu funkcji kosztu w odniesieniu do parametrów sieci neuronowej, co w głębokim uczeniu pomaga w minimalizacji strat.
Obliczanie pochodnej cząstkowej
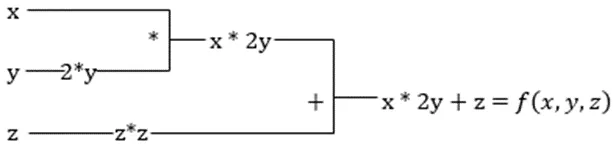
Załóżmy, że funkcja zależy od wielu zmiennych, na przykład x, y i z. Obliczenie pochodnej jednej zmiennej, przy założeniu, że pozostałe zmienne są stałe, nazywamy pochodną cząstkową. Rozważmy funkcję:
f(x,y,z) = x + 2y + z²
Przykład pochodnej cząstkowej
Pochodna cząstkowa względem x będzie wynosić ∂f/∂x, co informuje nas, jak funkcja zmienia się w zależności od zmiennej x, gdy inne zmienne są stałe. Wykonując to ręcznie, musielibyśmy napisać kod do różniczkowania, zastosować go do każdej zmiennej, a następnie obliczyć spadek gradientu. W przypadku wielu zmiennych stałoby się to skomplikowanym i czasochłonnym zadaniem.
Automatyczne różniczkowanie rozkłada funkcję na zbiór podstawowych operacji, takich jak +, -, *, / oraz sin, cos, tan, exp itd., a następnie stosuje regułę łańcucha do obliczenia pochodnej. Możemy to zrobić zarówno w trybie do przodu, jak i do tyłu.
I to nie wszystko! Te obliczenia są przeprowadzane z niezwykłą szybkością. XLA dba o wydajność i szybkość. (Wyobraź sobie, że musisz wykonać milion podobnych obliczeń i czas, który by to zajęło!).
#2. Przyspieszona algebra liniowa
Weźmy pod uwagę poprzednie równanie. Bez XLA obliczenia wymagałyby użycia trzech lub więcej jąder, gdzie każde jądro wykonywałoby mniejsze zadanie. Na przykład:
Jądro k1 –> x * 2y (mnożenie)
k2 –> x * 2y + z (dodawanie)
k3 -> Redukcja
Jeśli to samo zadanie jest wykonywane przez XLA, pojedyncze jądro zajmuje się wszystkimi pośrednimi operacjami, łącząc je w całość. Pośrednie wyniki operacji elementarnych są przesyłane strumieniowo, zamiast przechowywania ich w pamięci, co oszczędza pamięć i zwiększa szybkość.
#3. Kompilacja just-in-time
JAX wewnętrznie wykorzystuje kompilator XLA, aby zwiększyć szybkość wykonywania kodu. XLA może przyspieszyć działanie kodu na CPU, GPU i TPU. Wszystko to jest możliwe dzięki zastosowaniu kompilacji JIT. Aby z niej skorzystać, możemy użyć jit poprzez import:
from jax import jit
def my_function(x):
…………some lines of code
my_function_jit = jit(my_function)
Innym sposobem jest użycie dekoratora @jit nad definicją funkcji:
@jit
def my_function(x):
…………some lines of code
Ten kod wykonuje się znacznie szybciej, ponieważ transformacja zwraca skompilowaną wersję kodu do wywołującego, zamiast korzystać z interpretera Pythona. Jest to szczególnie przydatne w przypadku wejść wektorowych, takich jak tablice i macierze.
Ta sama zasada dotyczy wszystkich istniejących funkcji Pythona, na przykład funkcji z pakietu NumPy. W takim przypadku powinniśmy importować jax.numpy jako jnp zamiast NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Po wykonaniu tej operacji, podstawowy obiekt tablicy JAX, zwany DeviceArray, zastępuje standardową tablicę NumPy. DeviceArray jest leniwy — wartości są przechowywane w akceleratorze do momentu, gdy są potrzebne. Oznacza to, że program JAX nie czeka na wyniki i przesyła dane asynchronicznie.
#4. Automatyczna wektoryzacja (vmap)
W typowym procesie uczenia maszynowego, często pracujemy ze zbiorami danych zawierającymi miliony, a nawet więcej punktów danych. Najprawdopodobniej będziemy musieli wykonać obliczenia lub manipulacje na każdym z tych punktów danych, co jest bardzo czasochłonnym i obciążającym pamięć zadaniem! Na przykład, jeśli chcemy znaleźć kwadrat każdego punktu w zbiorze danych, naturalnym podejściem jest utworzenie pętli i obliczenie kwadratu każdego elementu jeden po drugim, co może być bardzo nieefektywne.
Jeśli punkty danych zostaną potraktowane jako wektory, możemy obliczyć kwadraty wszystkich elementów jednocześnie, wykonując operacje na wektorach lub macierzach za pomocą NumPy. A co jeśli program mógłby to zrobić automatycznie? To jest dokładnie to, co oferuje JAX! Potrafi automatycznie wektoryzować punkty danych, co umożliwia wykonywanie dowolnych operacji w sposób wydajny, co znacznie przyspiesza algorytmy.
JAX używa funkcji vmap do automatycznej wektoryzacji. Rozważmy tablicę:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Wykonanie powyższego spowoduje, że metoda square zostanie wywołana dla każdego elementu tablicy. Jednak wykonanie:
vmap(jnp.square(x))
Spowoduje, że metoda square zostanie wykonana tylko raz. Punkty danych zostaną automatycznie wektoryzowane przy użyciu metody vmap przed wykonaniem funkcji, a pętla zostanie przesunięta na niższy poziom, do operacji na macierzach zamiast mnożenia skalarnego, co zapewnia lepszą wydajność.
#5. Programowanie SPMD (pmap)
SPMD, czyli programowanie wielu danych w jednym programie, jest kluczowe w kontekście uczenia głębokiego. Często te same funkcje są stosowane do różnych zestawów danych znajdujących się na wielu procesorach GPU lub TPU. JAX oferuje funkcję o nazwie pmap, która umożliwia programowanie równoległe na wielu GPU lub innych akceleratorach. Podobnie jak w przypadku JIT, programy korzystające z pmap są kompilowane przez XLA i wykonywane równolegle. Ta automatyczna równoległość działa zarówno w przypadku obliczeń do przodu, jak i do tyłu.
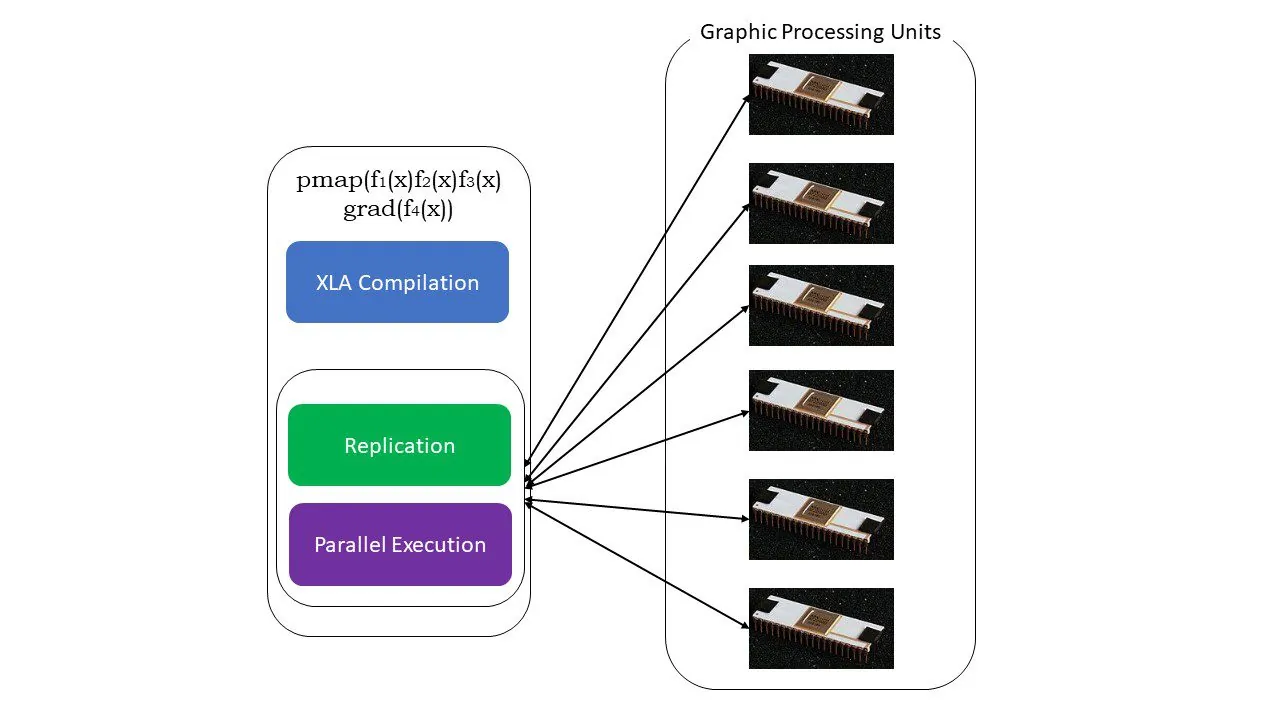 Jak działa pmap
Jak działa pmap
Możemy również zastosować wiele transformacji jednocześnie, w dowolnej kolejności w dowolnej funkcji, na przykład:
pmap(vmap(jit(grad (f(x)))))
Wiele transformacji łańcuchowych
Ograniczenia Google JAX
Twórcy Google JAX skupili się na przyspieszeniu algorytmów głębokiego uczenia poprzez wprowadzenie tych zaawansowanych transformacji. Funkcje i pakiety obliczeń naukowych są wzorowane na NumPy, co ułatwia naukę. Jednak JAX ma też pewne ograniczenia:
- Google JAX jest wciąż w fazie rozwoju i chociaż jego głównym celem jest optymalizacja wydajności, może nie przynosić znaczących korzyści w przypadku obliczeń na CPU. W niektórych przypadkach NumPy może działać lepiej, a korzystanie z JAX może dodatkowo obciążać system.
- JAX jest nadal na etapie badań lub wczesnego rozwoju i wymaga dalszego dopracowania, aby dorównać standardom infrastruktur takim jak TensorFlow, które są bardziej ugruntowane i mają więcej predefiniowanych modeli, projektów open source i materiałów edukacyjnych.
- Obecnie JAX nie obsługuje systemu operacyjnego Windows i do jego działania wymagana jest maszyna wirtualna.
- JAX działa wyłącznie na czystych funkcjach, czyli takich, które nie wywołują żadnych efektów ubocznych. W przypadku funkcji z efektami ubocznymi, JAX może nie być odpowiednim rozwiązaniem.
Jak zainstalować JAX w swoim środowisku Python?
Jeśli masz zainstalowane środowisko Python i chcesz uruchomić JAX na komputerze lokalnym (CPU), użyj następujących poleceń:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Jeśli chcesz uruchomić Google JAX na GPU lub TPU, postępuj zgodnie z instrukcjami podanymi na stronie GitHub JAX. Aby skonfigurować Pythona, odwiedź Oficjalną stronę pobierania plików Pythona.
Podsumowanie
Google JAX doskonale sprawdza się w tworzeniu wydajnych algorytmów dla głębokiego uczenia, robotyki i badań naukowych. Pomimo pewnych ograniczeń, jest szeroko wykorzystywany z innymi frameworkami, takimi jak Haiku, Flax i wiele innych. Docenisz możliwości JAX podczas uruchamiania programów i zobaczysz różnicę w czasie wykonania kodu z JAX i bez niego. Możesz zacząć od zapoznania się z oficjalną dokumentacją Google JAX, która jest bardzo obszerna.
