Co to jest nauka zerowego strzału i jak może ulepszyć sztuczną inteligencję
Główne wnioski dotyczące uczenia zero-shot
- Uogólnianie jest kluczowe w głębokim uczeniu, aby modele potrafiły trafnie przewidywać na podstawie nowych informacji. Uczenie zero-shot to umożliwia, pozwalając sztucznej inteligencji korzystać z posiadanej wiedzy do precyzyjnych predykcji dotyczących nieznanych wcześniej kategorii, bez konieczności użycia oznaczonych danych.
- Metoda zero-shot odzwierciedla to, jak ludzie się uczą i przetwarzają informacje. Dzięki dostarczeniu dodatkowych informacji semantycznych, wstępnie wytrenowany model może skutecznie identyfikować nieznane kategorie, podobnie jak człowiek rozpoznaje gitarę z pustym korpusem, znając jej charakterystyczne cechy.
- Uczenie zero-shot usprawnia działanie sztucznej inteligencji, poprawiając uogólnianie, skalowalność i redukując ryzyko nadmiernego dopasowania, a dodatkowo jest efektywne kosztowo. Umożliwia trenowanie modeli na rozleglejszych zbiorach danych, zdobywanie szerszej wiedzy poprzez transfer uczenia, lepsze zrozumienie kontekstu i ograniczenie zapotrzebowania na duże ilości oznaczonych danych. W miarę rozwoju AI, uczenie zero-shot będzie odgrywało coraz większą rolę w rozwiązywaniu skomplikowanych problemów w różnych dziedzinach.
Jednym z zasadniczych celów głębokiego uczenia jest tworzenie modeli, które posiadają zdolność do generalizacji. Jest to niezbędne, ponieważ gwarantuje, że model przyswaja istotne wzorce i jest w stanie dokonywać trafnych prognoz lub podejmować decyzje w konfrontacji z nowymi, nieznanymi danymi. Proces tworzenia takich modeli często wymaga znacznych zasobów oznaczonych danych. Jednak ich pozyskanie może być kosztowne, pracochłonne, a czasem wręcz niemożliwe.
Aby zniwelować tę przeszkodę, wprowadzono uczenie zero-shot, które umożliwia sztucznej inteligencji korzystanie z już posiadanej wiedzy do tworzenia trafnych predykcji, nawet przy braku oznaczonych danych.
Czym jest uczenie zero-shot?
Uczenie zero-shot to wyspecjalizowana metoda transferu wiedzy. Skupia się na wykorzystaniu wstępnie wytrenowanego modelu do identyfikacji nowych, wcześniej nieznanych kategorii, poprzez dostarczenie dodatkowych informacji opisujących cechy nowej kategorii.
Poprzez wykorzystanie ogólnej wiedzy modelu na dany temat i uzupełnienie jej o semantyczne informacje dotyczące tego, czego model ma szukać, powinien on być w stanie z dużą precyzją określić, jaką kategorię ma zidentyfikować.
Załóżmy, że musimy rozpoznać zebrę, ale nie dysponujemy modelem, który by to umożliwiał. W takim przypadku wykorzystujemy model nauczony rozpoznawania koni i informujemy go, że konie w czarno-białe paski to zebry. Kiedy zaczniemy prezentować modelowi obrazy zebr i koni, prawdopodobieństwo, że model poprawnie rozpozna każde zwierzę, jest bardzo wysokie.
Podobnie jak wiele metod głębokiego uczenia, uczenie zero-shot naśladuje sposób, w jaki ludzie się uczą i przetwarzają informacje. Wiemy, że ludzie są naturalnymi uczniami zero-shot. Jeśli w sklepie muzycznym poproszono by cię o znalezienie gitary z pustym korpusem, mógłbyś mieć problem. Jednak kiedy wyjaśnimy, że pusty korpus to gitara z otworem w kształcie litery F po jednej lub obu stronach, prawdopodobnie natychmiast ją odnajdziesz.

Przykładem z życia wziętym jest aplikacja do klasyfikacji zero-shot, stworzona przez platformę hostingową LLM open source Hugging Face, z wykorzystaniem modelu Clip-vit-large.
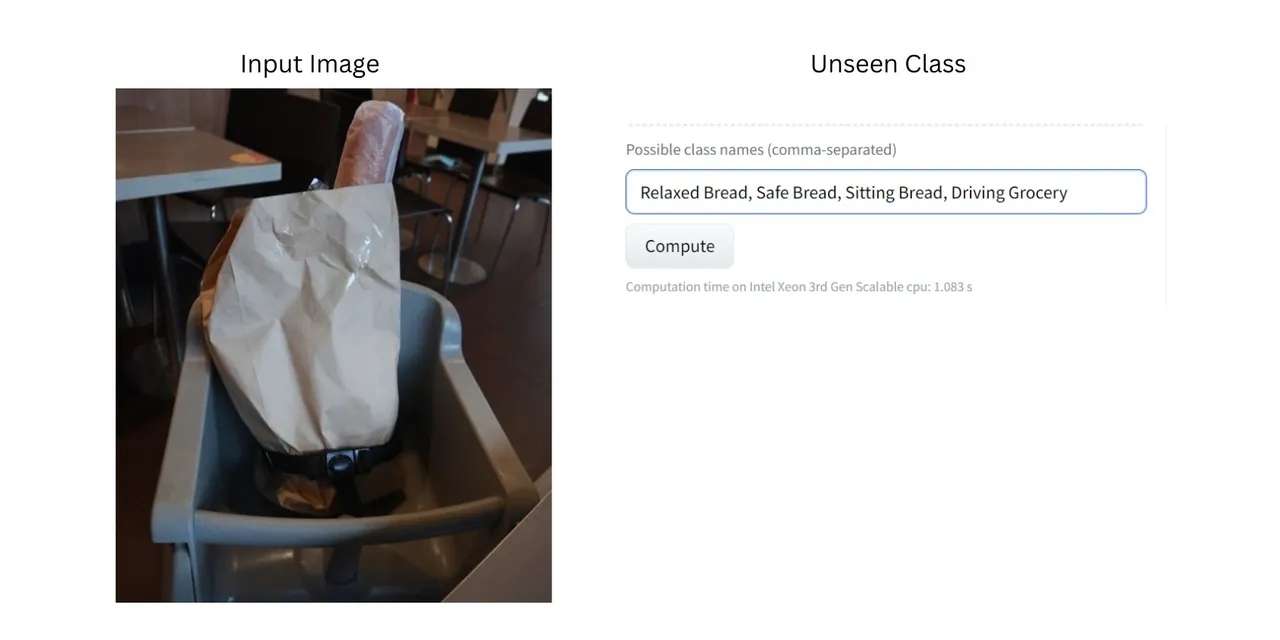
Na przedstawionym zdjęciu widoczny jest chleb w torbie na zakupy, przymocowanej do krzesełka dziecięcego. Ponieważ model był szkolony na rozległym zbiorze danych obrazów, najprawdopodobniej potrafi rozpoznać poszczególne obiekty na zdjęciu, takie jak chleb, zakupy, krzesła i pasy bezpieczeństwa.
Teraz chcemy, aby model zaklasyfikował obraz, używając nowych, nieznanych kategorii. W tym przypadku nowymi kategoriami byłyby "Zrelaksowany chleb", "Bezpieczny chleb", "Chleb na siedząco", "Prowadzenie sklepu spożywczego" i "Bezpieczny sklep spożywczy".
Celowo użyliśmy nietypowych kategorii i obrazów, aby zaprezentować skuteczność klasyfikacji obrazów zero-shot.
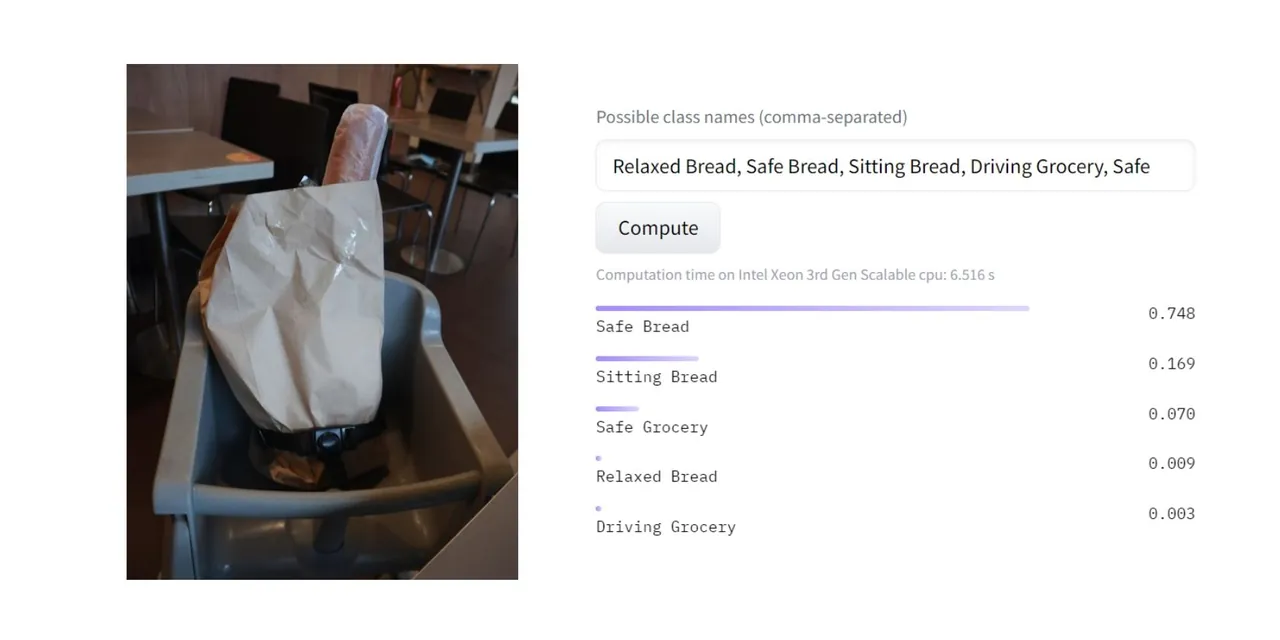
Po przeanalizowaniu, model z około 80% pewnością zaklasyfikował obraz jako "Bezpieczny chleb". Najprawdopodobniej dlatego, że model uznał, że krzesełko dziecięce pełni funkcję bardziej bezpieczeństwa niż siedzenia, relaksu czy prowadzenia samochodu.
Doskonale! Osobiście zgodziłbym się z wynikami modelu. Ale w jaki sposób model uzyskał taki rezultat? Oto ogólne zasady działania uczenia zero-shot.
Jak działa uczenie zero-shot?
Uczenie zero-shot może pomóc wstępnie przeszkolonemu modelowi w identyfikacji nowych kategorii, bez dostarczania oznaczonych danych. W najprostszej formie proces ten składa się z trzech etapów:
1. Przygotowanie
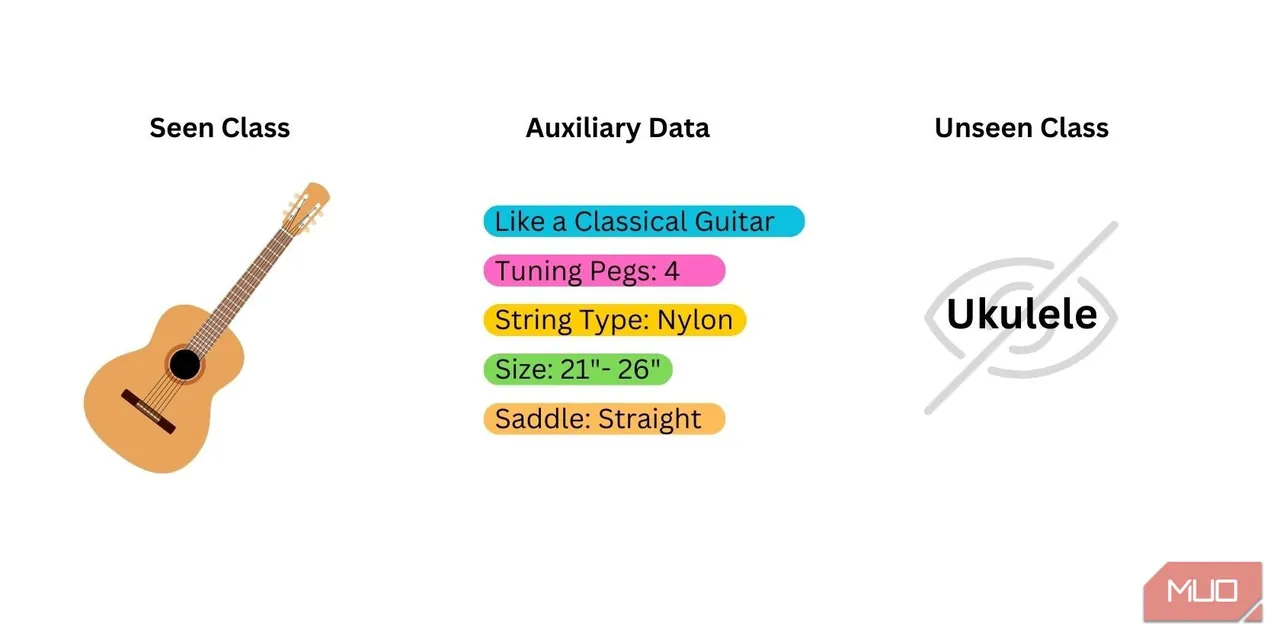
Uczenie zero-shot rozpoczyna się od przygotowania trzech rodzajów danych:
- Klasa widziana: dane wykorzystane do treningu wstępnie przeszkolonego modelu. Model ma już dostęp do tych klas. Najefektywniejsze modele zero-shot to te, które zostały przeszkolone na kategoriach ściśle powiązanych z nową kategorią, którą model ma identyfikować.
- Klasa nieznana/nowa: dane, które nigdy nie zostały użyte podczas treningu modelu. Należy samodzielnie zadbać o te dane, ponieważ nie można ich uzyskać z modelu.
- Dane semantyczne/pomocnicze: dodatkowe informacje, które pomagają modelowi w identyfikacji nowej kategorii. Mogą to być słowa, frazy, osadzenia słów lub nazwy klas.
2. Mapowanie semantyczne
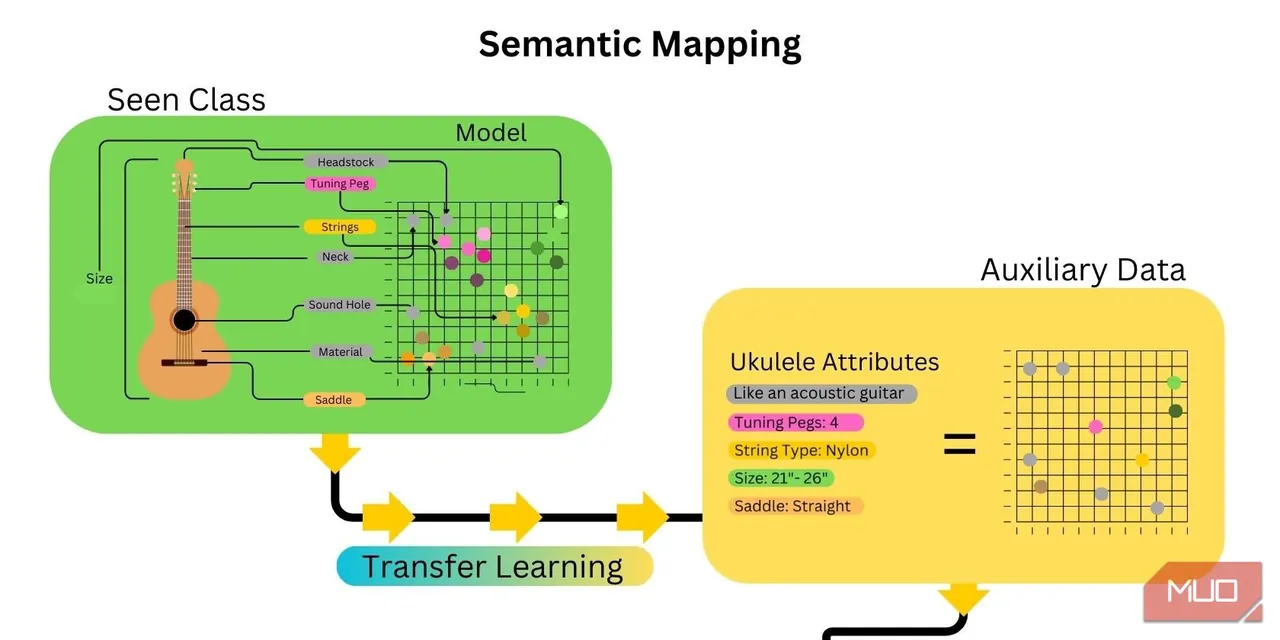
Następnym krokiem jest mapowanie cech nieznanej kategorii. Odbywa się to poprzez osadzanie słów i tworzenie mapy semantycznej, która łączy atrybuty lub cechy nieznanej kategorii z dostarczonymi informacjami pomocniczymi. Transfer uczenia AI znacznie przyspiesza ten proces, ponieważ wiele atrybutów związanych z nieznaną kategorią zostało już zmapowanych.
3. Wnioskowanie
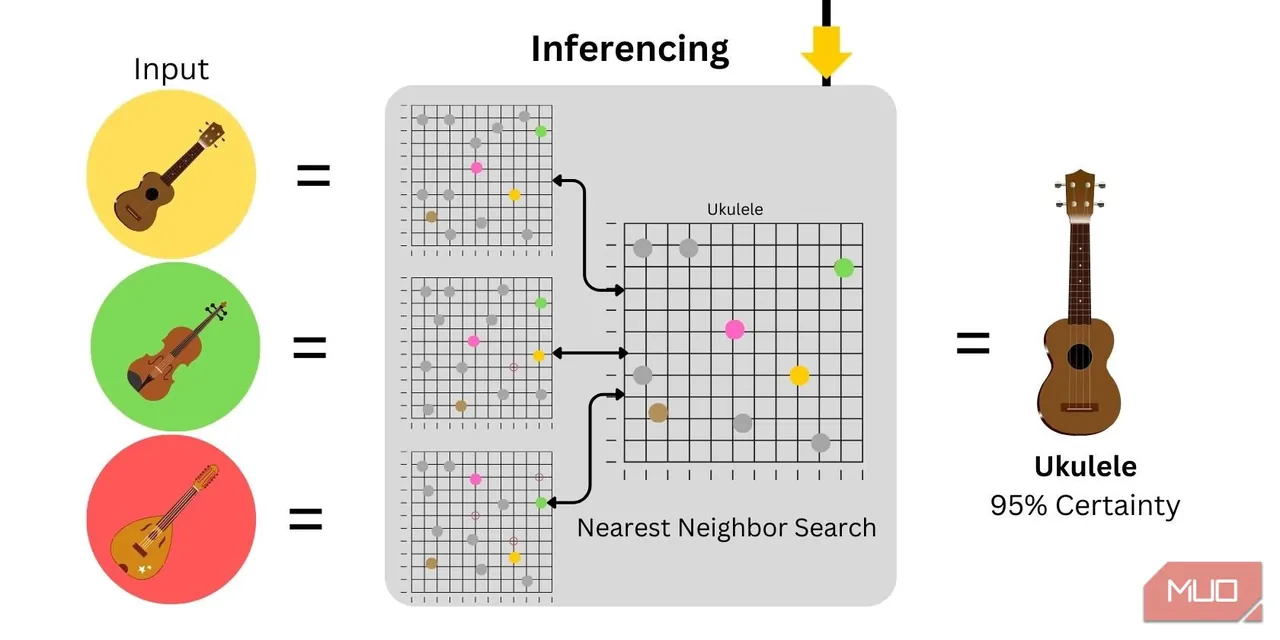
Wnioskowanie to wykorzystanie modelu do generowania prognoz lub wyników. W przypadku klasyfikacji obrazów zero-shot, osadzenia słów są generowane na podstawie danego obrazu wejściowego, a następnie są analizowane i porównywane z informacjami pomocniczymi. Poziom pewności zależy od podobieństwa między danymi wejściowymi a dostarczonymi informacjami pomocniczymi.
Jak uczenie zero-shot ulepsza sztuczną inteligencję?
Uczenie zero-shot usprawnia modele sztucznej inteligencji, rozwiązując wiele problemów związanych z uczeniem maszynowym, takich jak:
- Ulepszona generalizacja: zmniejszenie zależności od danych oznaczonych etykietami pozwala na uczenie modeli na większych zbiorach danych, co zwiększa ich zdolność do generalizacji i sprawia, że model staje się bardziej niezawodny. Wraz ze wzrostem doświadczenia i zdolności do uogólniania, modele mogą nawet nauczyć się zdrowego rozsądku, zamiast bazować na standardowych metodach analizy informacji.
- Skalowalność: modele mogą być ciągle szkolone i zdobywać więcej wiedzy poprzez transfer uczenia. Firmy i niezależni badacze mogą nieustannie ulepszać swoje modele, aby w przyszłości zwiększać ich możliwości.
- Zmniejszone ryzyko nadmiernego dopasowania: do nadmiernego dopasowania może dojść, gdy model jest trenowany na małym zestawie danych, który nie zawiera wystarczającej różnorodności, aby reprezentować wszystkie możliwe dane wejściowe. Uczenie modelu poprzez uczenie zero-shot zmniejsza ryzyko nadmiernego dopasowania, ponieważ model lepiej rozumie kontekst tematów.
- Efektywność kosztowa: pozyskanie dużej ilości oznaczonych danych może być czasochłonne i kosztowne. Dzięki wykorzystaniu transferu uczenia zero-shot, stworzenie solidnego modelu jest możliwe przy znacznie krótszym czasie i przy mniejszym nakładzie oznaczonych danych.
Wraz z rozwojem sztucznej inteligencji, techniki takie jak uczenie zero-shot będą odgrywać jeszcze większą rolę.
Przyszłość uczenia zero-shot
Uczenie zero-shot stało się ważnym elementem uczenia maszynowego. Umożliwia modelom rozpoznawanie i klasyfikowanie nowych kategorii bez konieczności wyraźnego szkolenia. Dzięki stałemu postępowi w architekturze modeli, podejściu opartym na atrybutach i integracji multimodalnej, uczenie zero-shot może znacznie przyczynić się do zwiększenia adaptacyjności modeli i pozwoli im sprostać złożonym wyzwaniom w robotyce, opiece zdrowotnej i wizji komputerowej.
