Jak codziennie synchronizować lokalną bazę danych Oracle z AWS
Analizując ewolucję oprogramowania dla przedsiębiorstw na przestrzeni ostatnich dwóch dekad, dostrzegalny jest wyraźny trend w ostatnich latach – migracja zasobów bazodanowych do środowisk chmurowych.
Uczestniczyłem w kilku projektach migracyjnych, których celem było przeniesienie lokalnych baz danych do chmury Amazon Web Services (AWS). Mimo że dokumentacja AWS sugeruje prostotę tego procesu, realia pokazują, że implementacja takiego planu często napotyka trudności i nie zawsze kończy się sukcesem.
W tym opracowaniu skupię się na praktycznych doświadczeniach z następującym scenariuszem:
- Źródło: Choć teoretycznie wybór źródła nie ma kluczowego znaczenia (podobne podejście można zastosować do większości popularnych baz danych), to Oracle przez długi czas był preferowanym systemem w dużych korporacjach i to na nim się skoncentruję.
- Cel: W tym aspekcie nie ma potrzeby precyzowania. Można wybrać dowolną docelową bazę danych w AWS, a metoda pozostanie adekwatna.
- Tryb: Migracja może być pełna lub przyrostowa, obejmując ładowanie wsadowe danych (z opóźnieniem między stanami źródłowym i docelowym) lub ładowanie (niemal) w czasie rzeczywistym. Omówię obie opcje.
- Częstotliwość: Może być wymagana jednorazowa migracja, po której nastąpi całkowite przejście do chmury, lub też okres przejściowy z równoczesnym dostępem do aktualnych danych w obu środowiskach, co implikuje potrzebę regularnej synchronizacji między infrastrukturą lokalną a AWS. Pierwsza opcja jest prostsza i bardziej racjonalna, lecz druga jest częściej spotykana i obarczona większą liczbą potencjalnych problemów. Analizuję obie możliwości.
Opis wyzwania
Często spotykamy się z prostym żądaniem:
Chcemy rozpocząć rozwój usług w ramach AWS, dlatego prosimy o przeniesienie wszystkich naszych danych do bazy „ABC”. Chcemy to zrobić szybko i sprawnie. Musimy zacząć korzystać z danych w AWS, a później zajmiemy się dostosowaniem struktur bazy danych do naszych potrzeb.
Zanim jednak przejdziemy dalej, należy wziąć pod uwagę kilka istotnych aspektów:
- Unikaj pochopnego podejścia „po prostu skopiujmy dane i zajmiemy się tym później”. Choć jest to najłatwiejsze i najszybsze rozwiązanie, może ono generować poważne problemy architektoniczne, których naprawa będzie wymagała znaczącej refaktoryzacji nowej platformy chmurowej. Pamiętaj, że ekosystem chmurowy jest zasadniczo różny od lokalnego. Wraz z upływem czasu pojawią się nowe usługi, które będą wykorzystywały dane w różnorodny sposób. Replikowanie stanu lokalnego 1:1 w chmurze rzadko jest dobrym pomysłem. Może to być odpowiednie w konkretnym przypadku, ale warto to dokładnie zweryfikować.
- Zweryfikuj wymaganie, zadając istotne pytania:
- Kim będą użytkownicy nowej platformy? Lokalne środowisko może być nastawione na transakcyjnych użytkowników biznesowych, ale w chmurze mogą to być analitycy danych, analitycy hurtowni danych lub usługi (np. Databricks, Glue, modele uczenia maszynowego).
- Czy codzienne operacje mają pozostać niezmienne po przejściu do chmury? Jeśli nie, w jaki sposób się zmienią?
- Czy spodziewany jest znaczny wzrost ilości danych w przyszłości? Zazwyczaj jest to jeden z głównych powodów migracji do chmury. Nowy model danych powinien być na to przygotowany.
- Zastanów się, jakie zapytania będą kierowane do nowej bazy danych. To pomoże określić, jak bardzo należy zmodyfikować obecny model danych, aby utrzymać akceptowalną wydajność.
Przygotowanie migracji
Po ustaleniu docelowej bazy danych i omówieniu modelu danych, kolejnym krokiem jest zapoznanie się z narzędziem AWS Schema Conversion Tool. Narzędzie to może być pomocne w kilku obszarach:
 Odniesienie: Dokumentacja AWS
Odniesienie: Dokumentacja AWS
Oto kilka porad dotyczących korzystania z narzędzia do konwersji schematów.
Po pierwsze, wygenerowane dane wyjściowe rzadko nadają się do bezpośredniego wykorzystania. Potraktuj je jako punkt odniesienia, który wymaga dostosowania na podstawie zrozumienia danych, ich przeznaczenia i sposobu wykorzystania w chmurze.
Po drugie, wcześniej tabele były projektowane z myślą o szybkim uzyskiwaniu wyników dla konkretnych jednostek danych. Teraz dane mogą być wykorzystywane do celów analitycznych. Na przykład indeksy baz danych, które działały dobrze lokalnie, mogą okazać się bezużyteczne i nie poprawią wydajności systemu w nowym kontekście. Możliwe jest też, że dane należy podzielić w inny sposób w systemie docelowym, niż miało to miejsce w systemie źródłowym.
Warto również rozważyć przeprowadzenie transformacji danych w trakcie migracji, co zasadniczo oznacza zmianę docelowego modelu danych dla niektórych tabel, tak aby nie były one kopiami 1:1. Reguły transformacji trzeba będzie zaimplementować w narzędziu do migracji.
Jeśli źródłowa i docelowa baza danych są tego samego typu (np. Oracle on-premise vs. Oracle w AWS, PostgreSQL vs. Aurora Postgresql itp.), najlepiej skorzystać z dedykowanego narzędzia do migracji, które natywnie wspiera dana baza (np. eksport i import danych, Oracle Goldengate itp.).
Jednak najczęściej źródłowa i docelowa baza nie są kompatybilne, a wówczas naturalnym wyborem staje się usługa migracji bazy danych AWS.
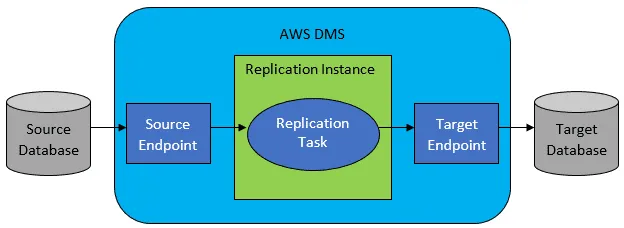 Odniesienie: Dokumentacja AWS
Odniesienie: Dokumentacja AWS
AWS DMS umożliwia skonfigurowanie zadań migracji na poziomie tabeli, określając:
- Dokładną lokalizację źródłowej bazy danych i tabelę, z której dane mają być pobierane.
- Instrukcje pobierania danych dla tabeli docelowej.
- Narzędzia transformacji (jeśli są potrzebne) definiujące sposób mapowania danych źródłowych na docelowe (jeśli nie jest to 1:1).
- Dokładną lokalizację docelowej bazy danych i tabelę, do której dane mają być załadowane.
Konfiguracja zadań DMS odbywa się za pomocą przyjaznego formatu, takiego jak JSON.
W najprostszym scenariuszu wystarczy uruchomić skrypty wdrożeniowe w docelowej bazie danych oraz zadanie DMS. W praktyce jednak jest to znacznie bardziej skomplikowane.
Jednorazowa pełna migracja danych

Najłatwiejszy przypadek to jednokrotne przeniesienie całej bazy do chmury. Wówczas wystarczy wykonać następujące kroki:
Jeśli konfiguracja DMS jest prawidłowa, ten scenariusz powinien przebiec bezproblemowo. Każda tabela źródłowa zostanie pobrana i skopiowana do docelowej bazy danych w AWS. Należy jedynie upewnić się, że rozmiar jest odpowiedni na każdym etapie, aby uniknąć problemów z brakiem miejsca na dysku.
Przyrostowa synchronizacja codzienna

W tym scenariuszu sytuacja staje się bardziej złożona. W idealnym świecie wszystko działałoby bez zarzutu, ale rzeczywistość nie zawsze jest idealna.
DMS można skonfigurować w dwóch trybach:
- Pełne ładowanie – tryb domyślny, omówiony powyżej. Zadania DMS są uruchamiane i po zakończeniu są zamykane.
- Przechwytywanie zmian danych (CDC) – w tym trybie zadania DMS działają w sposób ciągły. DMS monitoruje źródłową bazę danych w poszukiwaniu zmian na poziomie tabeli. Jeśli zmiana wystąpi, jest ona natychmiast replikowana w bazie docelowej, zgodnie z konfiguracją zadania DMS.
Decydując się na CDC, należy jeszcze wybrać sposób wyodrębniania zmian delta ze źródłowej bazy.
# 1. Czytnik dzienników powtórzeń Oracle
Jedną z opcji jest wykorzystanie natywnego czytnika dzienników powtórzeń Oracle, który CDC może wykorzystać do pobrania zmian i ich replikowania do bazy docelowej.
Choć dla źródeł Oracle wydaje się to logicznym wyborem, wiąże się z pewnym utrudnieniem: czytnik dzienników powtórzeń Oracle korzysta z klastra źródłowego Oracle, wpływając bezpośrednio na inne procesy działające w bazie danych (tworzy aktywne sesje w bazie).
Im więcej skonfigurujesz zadań DMS (lub im więcej równoległych klastrów DMS), tym bardziej prawdopodobne jest, że konieczne będzie rozbudowanie klastra Oracle (skalowanie pionowe). W efekcie wpłynie to na całkowity koszt rozwiązania, szczególnie jeśli codzienna synchronizacja ma być długoterminowa.
#2. Koparka dzienników AWS DMS
To alternatywne, natywne rozwiązanie AWS. W tym przypadku DMS nie obciąża źródłowej bazy Oracle. Zamiast tego, dzienniki powtórzeń są kopiowane do klastra DMS i tam przetwarzane. Choć oszczędza to zasoby Oracle, jest to wolniejsze rozwiązanie, gdyż wymaga więcej operacji. Dodatkowo niestandardowy czytnik dzienników powtórzeń Oracle może być wolniejszy od natywnego.
W zależności od rozmiaru źródłowej bazy i liczby codziennych zmian, w najlepszym przypadku można osiągnąć niemalże rzeczywistą synchronizację danych z lokalnej bazy Oracle do chmury AWS.
W innych scenariuszach synchronizacja nie będzie w czasie rzeczywistym, ale można próbować zminimalizować opóźnienie (między źródłem a celem) poprzez dostrojenie wydajności klastrów źródłowych i docelowych, eksperymentując z liczbą zadań DMS i ich dystrybucją między instancje CDC.
Warto też sprawdzić, które zmiany w tabeli źródłowej są obsługiwane przez CDC (np. dodawanie kolumn), ponieważ nie wszystkie zmiany są obsługiwane. W niektórych przypadkach jedynym rozwiązaniem jest ręczna modyfikacja tabeli docelowej i ponowne uruchomienie zadania CDC od zera (z utratą danych w docelowej bazie).
Gdy coś idzie nie tak, niezależnie od wszystkiego

Z doświadczenia wiem, że istnieje specyficzny scenariusz związany z DMS, w którym obietnica codziennej replikacji jest trudna do zrealizowania.
DMS może przetwarzać dzienniki powtórzeń tylko z określoną prędkością. Nie ma znaczenia, czy działa więcej instancji DMS. Każda instancja czyta dzienniki tylko z pewną prędkością i każda musi przeczytać je w całości. Nie ma znaczenia, czy używasz dzienników przeróbek Oracle, czy eksploratora dzienników AWS, oba mają to ograniczenie.
Jeśli źródłowa baza generuje dużo zmian w ciągu dnia, a dzienniki powtórzeń Oracle stają się bardzo duże (np. 500 GB +) każdego dnia, CDC po prostu nie zadziała. Replikacja nie zakończy się przed końcem dnia. Nowa porcja zmian do replikacji już czeka, a ilość nieprzetworzonych danych rośnie każdego dnia.
W tym konkretnym przypadku CDC nie było rozwiązaniem (po licznych testach wydajnościowych). Jedynym sposobem, aby upewnić się, że wszystkie zmiany zostaną zreplikowane w danym dniu, było:
- Oddzielenie dużych tabel, które nie są często zmieniane i replikowanie ich tylko raz w tygodniu (np. w weekendy).
- Podzielenie replikacji dużych tabel między kilka zadań DMS. Jedna tabela była migrowana równolegle przez 10 lub więcej zadań DMS, z odrębnym podziałem danych między zadaniami (niestandardowe kodowanie) i uruchamianiem tych zadań codziennie.
- Dodanie większej liczby (do 4) instancji DMS i równomierne rozdzielenie między nimi zadań DMS, biorąc pod uwagę nie tylko liczbę tabel, ale i ich rozmiar.
Zasadniczo, używaliśmy trybu pełnego ładowania systemu DMS do codziennej replikacji, ponieważ tylko w ten sposób można było zapewnić zakończenie replikacji danych tego samego dnia.
Nie jest to idealne rozwiązanie, ale jest skuteczne i działa od wielu lat. Może więc wcale nie jest takie złe. 😃
