Jak wykorzystać wgląd w dzienniki AWS do wysyłania zapytań o metryki pulpitu nawigacyjnego z dzienników usług AWS
Każda usługa w ramach AWS rejestruje swoją aktywność w plikach, które są grupowane w CloudWatch Logs. Grupy te są zazwyczaj nazywane w oparciu o konkretną usługę, co ułatwia ich identyfikację. Komunikaty systemowe danej usługi, a także ogólne informacje o jej statusie, są domyślnie zapisywane w tych plikach.
Jednakże, istnieje możliwość dodawania własnych, niestandardowych informacji do tych domyślnych logów. Odpowiednio skonfigurowane dzienniki mogą być podstawą do tworzenia użytecznych paneli kontrolnych CloudWatch, które dostarczają szczegółowych danych o przetwarzaniu zadań, wykraczających poza standardowe metryki systemowe.
Za pomocą niestandardowych widżetów lub danych, możesz rozszerzyć zakres informacji wyświetlanych na panelu kontrolnym, zbierając dane, które są najbardziej istotne z punktu widzenia Twojej aplikacji.
Przeszukiwanie plików dziennika
Źródło: aws.amazon.com
Usługa AWS CloudWatch Log Insights umożliwia przeszukiwanie i analizowanie danych dziennika z zasobów AWS w czasie rzeczywistym. Można ją traktować jako interfejs do bazy danych. Definiujesz zapytanie na panelu kontrolnym, a panel pobiera dane w momencie jego odwiedzenia lub w określonym przedziale czasu z przeszłości, zgodnie z ustawieniami widoku panelu.
Do przeszukiwania i analizy danych dziennika wykorzystywany jest język zapytań CloudWatch Logs Insights, oparty na podzbiorze SQL. Umożliwia on wyszukiwanie, filtrowanie danych dziennika, identyfikację konkretnych zdarzeń, niestandardowych tekstów lub słów kluczowych, a także agregację danych z jednego lub wielu plików dziennika w celu generowania zbiorczych metryk i wizualizacji.
Po uruchomieniu zapytania, CloudWatch Log Insights przeszukuje dane dziennika w wybranej grupie, zwracając teksty, które spełniają określone kryteria.
Przykłady zapytań do plików dziennika
Przyjrzyjmy się kilku podstawowym zapytaniom, aby lepiej zrozumieć ich działanie.
Każda usługa domyślnie rejestruje kluczowe błędy. Nawet jeśli nie utworzysz dedykowanych dzienników dla zdarzeń błędów, prostym zapytaniem możesz policzyć ich liczbę w logach aplikacji w ciągu ostatniej godziny:
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
Poniżej znajduje się przykład monitorowania średniego czasu odpowiedzi interfejsu API w ciągu ostatniego dnia:
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
Ponieważ domyślne wykorzystanie procesora jest rejestrowane przez usługę w CloudWatch, możesz również zbierać metryki tego typu:
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
Powyższe zapytania można dostosować do konkretnych potrzeb i wykorzystać do tworzenia niestandardowych metryk i wizualizacji na panelach CloudWatch. W tym celu umieszcza się odpowiedni widżet na panelu, a w jego kodzie definiuje się zapytanie.
Oto niektóre z widżetów, które można wykorzystać na panelach CloudWatch, korzystając z danych z Log Insights:
- Widżety tekstowe - do wyświetlania informacji tekstowych, np. wyników zapytań CloudWatch Insights.
- Widżety zapytań dziennika - do wyświetlania wyników zapytań CloudWatch Insights, takich jak liczba błędów w dziennikach aplikacji.
Jak tworzyć użyteczne informacje dziennika dla panelu kontrolnego
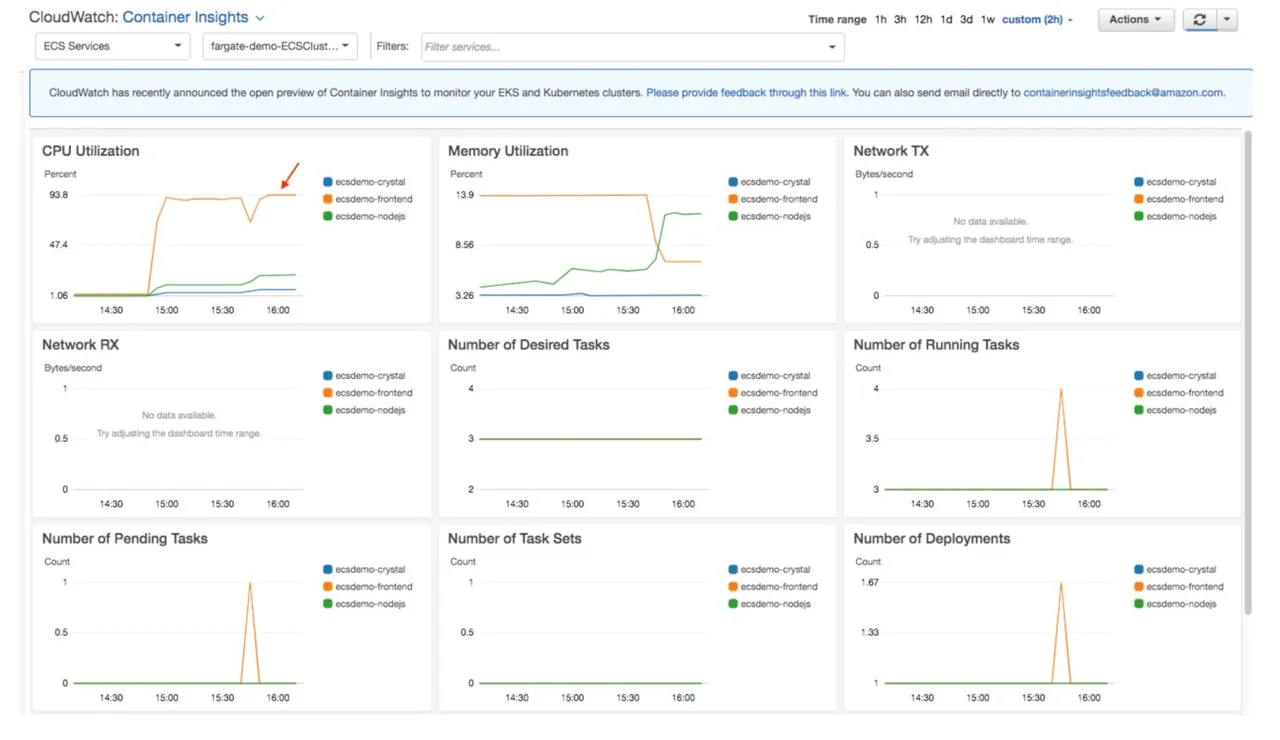 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Aby skutecznie korzystać z zapytań CloudWatch Insights w CloudWatch Dashboards, zaleca się stosowanie najlepszych praktyk podczas tworzenia dzienników dla każdej usługi w systemie. Oto kilka wskazówek:
# 1. Użyj logowania strukturalnego
Zaleca się stosowanie formatu logowania, który wykorzystuje predefiniowany schemat do rejestrowania danych w formacie strukturalnym. Ułatwia to wyszukiwanie i filtrowanie danych za pomocą zapytań CloudWatch Insights.
Istotne jest standaryzowanie dzienników we wszystkich usługach w ramach architektury. Zdefiniowanie tego w standardach programistycznych jest bardzo pomocne.
Przykładowo, można ustalić, że każdy problem związany z konkretną tabelą bazy danych będzie rejestrowany z komunikatem rozpoczynającym się od "[NAZWA_TABELI] Ostrzeżenie / Błąd:
Można również oddzielić zadania pełnych danych od zadań danych delta za pomocą prefiksów, np. "[FULL/DELTA]", aby wybierać tylko komunikaty dotyczące konkretnych procesów.
Można zdefiniować, że podczas przetwarzania danych z określonego systemu źródłowego, nazwa tego systemu będzie poprzedzać każdy powiązany wpis w dzienniku. Ułatwia to późniejsze filtrowanie wiadomości i tworzenie na ich podstawie metryk.
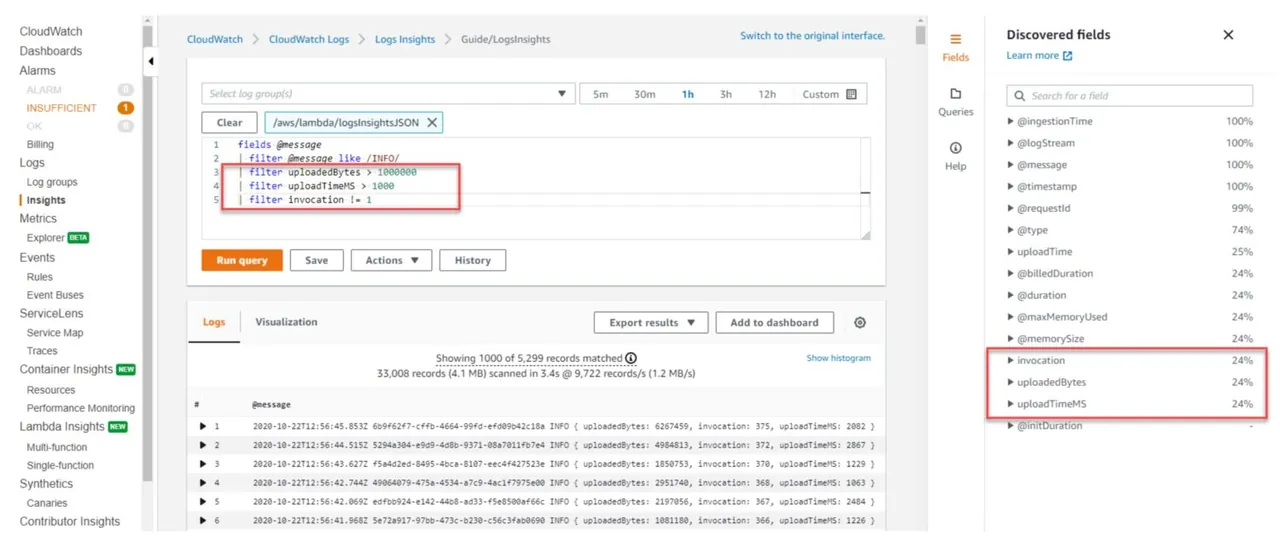 Źródło: aws.amazon.com
Źródło: aws.amazon.com
#2. Używaj spójnych formatów dziennika
Używaj spójnych formatów dzienników w obrębie wszystkich zasobów AWS, aby ułatwić wyszukiwanie i filtrowanie danych za pomocą zapytań CloudWatch Insights.
Jest to w pewnym stopniu powiązane z poprzednim punktem, ale faktem jest, że im bardziej ujednolicony jest format dziennika, tym łatwiej jest korzystać z danych. Programiści mogą polegać na tym formacie i korzystać z niego intuicyjnie.
Niestety, wiele projektów nie przykłada wagi do standardów logowania. Co więcej, wiele z nich w ogóle nie generuje żadnych niestandardowych dzienników. Jest to zaskakujące, ale jednocześnie bardzo powszechne.
Trudno zliczyć, ile razy zastanawiałem się, jak można funkcjonować bez odpowiedniego podejścia do obsługi błędów. A jeśli ktoś już próbował coś zrobić w tym zakresie, to robił to w sposób nieprawidłowy.
Dlatego spójny format dziennika jest bardzo ważny. Niewielu go posiada.
#3. Dołącz odpowiednie metadane
Dołączaj do danych dziennika metadane, takie jak sygnatury czasowe, identyfikatory zasobów i kody błędów, aby ułatwić wyszukiwanie i filtrowanie za pomocą zapytań CloudWatch Insights.
#4. Włącz rotację dziennika
Włącz rotację dzienników, aby zapobiec nadmiernemu rozrostowi danych i ułatwić wyszukiwanie i filtrowanie za pomocą zapytań CloudWatch Insights.
Brak danych dziennika to problem, ale posiadanie ich zbyt wiele, bez struktury, jest równie uciążliwe. Jeśli nie można korzystać z danych, to tak jakby ich w ogóle nie było.
#5. Użyj agentów dzienników CloudWatch
Jeśli nie chcesz budować niestandardowego systemu dzienników, skorzystaj z agentów CloudWatch Logs. Automatycznie wysyłają one dane z zasobów AWS do CloudWatch Logs. Ułatwia to wyszukiwanie i filtrowanie danych za pomocą zapytań CloudWatch Insights.
Bardziej złożone przykłady zapytań
Zapytania CloudWatch Insights mogą być bardziej skomplikowane niż tylko dwuwierszowe instrukcje.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*\[(?<timestamp>[^\]]+)\].*\"(?<method>[^\s]+)\s+(?<path>[^\s]+).*\" (?<status>\d+) (?<response_time>\d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
Powyższe zapytanie wykonuje następujące czynności:
To zapytanie identyfikuje najczęstsze błędy w aplikacji i śledzi średni czas odpowiedzi dla każdej kombinacji metody HTTP, ścieżki i kodu statusu. Możesz wykorzystać te wyniki do tworzenia niestandardowych wskaźników i wizualizacji na panelach CloudWatch, monitorując wydajność aplikacji internetowej i rozwiązując problemy.
Inny przykład zapytania dotyczącego komunikatów Amazon S3:
fields @timestamp, @message | filter @message like /REST\.API\.REQUEST/ | parse @message /.*\"(?<method>[^\s]+)\s+(?<path>[^\s]+).*\" (?<status>\d+) (?<response_time>\d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- Zapytanie wybiera zdarzenia dziennika, które zawierają ciąg "REST.API.REQUEST".
- Następnie analizuje komunikat, wyodrębniając metodę HTTP, ścieżkę, kod statusu i czas odpowiedzi.
- Oblicza średni czas odpowiedzi i liczbę zdarzeń dla każdej kombinacji metody HTTP, ścieżki i kodu statusu, a następnie sortuje wyniki według liczby w kolejności malejącej.
- Ogranicza wyniki do 20.
Wyniki tego zapytania można wykorzystać do utworzenia wykresu liniowego na panelu CloudWatch, który pokazuje średni czas odpowiedzi dla każdej kombinacji metody HTTP, ścieżki i kodu statusu w czasie.
Budowanie panelu nawigacyjnego
Aby wypełnić metryki i wizualizacje na panelach CloudWatch danymi z zapytań dziennika CloudWatch Insights, przejdź do konsoli CloudWatch i skorzystaj z kreatora, aby utworzyć odpowiednią zawartość.
Oto przykład kodu panelu CloudWatch, który zawiera metryki zasilane danymi z zapytań CloudWatch Insights:
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
Ten panel CloudWatch zawiera dwa widżety:
Powyższy kod to plik w formacie JSON z definicją panelu i metryk. Zawiera on również (jako właściwość) samo zapytanie CloudWatch Insights.
Możesz wziąć ten kod i wdrożyć go na dowolnym koncie AWS. Zakładając, że usługi i komunikaty dziennika są spójne na wszystkich kontach i etapach, panel będzie działał poprawnie bez potrzeby zmiany kodu źródłowego.
Podsumowanie
Budowa solidnej struktury logowania zawsze była dobrą inwestycją w przyszłą niezawodność systemu. Obecnie, dzięki CloudWatch Insights, może ona służyć jeszcze większemu celowi. Dodatkowo, możesz uzyskać użyteczne panele kontrolne z danymi i wizualizacjami, bez większego nakładu pracy.
Wykonując to zadanie tylko raz, z niewielkim dodatkowym wysiłkiem, zespół programistów, zespół testerów i użytkownicy produkcyjni mogą korzystać z tego samego rozwiązania.
Sprawdź również najlepsze narzędzia do monitorowania AWS.
