Jak zainstalować Beautiful Soup i używać go do projektów Web Scraping?
W obecnych czasach, kiedy dane stanowią fundament wielu działań, tradycyjne, ręczne metody ich pozyskiwania odeszły do lamusa. Dostęp do internetu z każdego komputera uczynił z sieci przeogromne źródło informacji. Z tego powodu, zdecydowanie bardziej efektywnym i oszczędzającym czas podejściem jest tzw. web scraping, czyli automatyczne pobieranie danych ze stron internetowych. W kontekście tego procesu, Python oferuje wyjątkowe narzędzie – bibliotekę Beautiful Soup. W tym artykule przeprowadzę Cię przez proces instalacji Beautiful Soup, abyś mógł rozpocząć swoją przygodę ze skrobanem danych z sieci.
Zanim jednak przejdziemy do instalacji i używania Beautiful Soup, przyjrzyjmy się, dlaczego warto z niej korzystać.
Czym jest Beautiful Soup?
Wyobraźmy sobie, że prowadzisz badania na temat "Wpływu COVID na zdrowie ludzi" i natknąłeś się na wiele stron internetowych zawierających interesujące Cię dane. Co jednak, jeśli witryny te nie umożliwiają pobrania tych informacji jednym kliknięciem? Właśnie w takich sytuacjach Beautiful Soup przychodzi z pomocą.
Beautiful Soup to jedna z czołowych bibliotek Pythona służących do ekstrakcji danych ze stron internetowych. Ułatwia ona pobieranie informacji z plików HTML i XML.
Leonard Richardson zapoczątkował projekt Beautiful Soup w 2004 roku i nadal aktywnie go rozwija. Z entuzjazmem ogłasza każdą nową wersję na swoim koncie na Twitterze.
Chociaż Beautiful Soup została początkowo stworzona dla Pythona 3.8, bez problemu działa zarówno z Pythonem 3, jak i starszym Pythonem 2.4.
Często zdarza się, że strony internetowe stosują zabezpieczenia captcha, aby chronić swoje dane przed automatycznym pobieraniem. W takich przypadkach, modyfikacja nagłówka "user-agent" w Beautiful Soup lub wykorzystanie API do rozwiązywania captcha może pomóc w symulowaniu zachowania prawdziwej przeglądarki i obejściu zabezpieczeń.
Jeśli jednak brakuje Ci czasu na zgłębianie tajników Beautiful Soup, lub szukasz szybkiego i wygodnego rozwiązania, warto rozważyć wykorzystanie specjalnych API do skrobania stron internetowych. W takim przypadku wystarczy podać adres URL, a dane zostaną Ci dostarczone.
Dla programistów zaznajomionych z językiem Python, użycie Beautiful Soup do skrobania nie będzie wyzwaniem, dzięki prostej składni i intuicyjnemu poruszaniu się po strukturze stron internetowych. Jednocześnie, biblioteka jest przyjazna również dla początkujących użytkowników.
Chociaż Beautiful Soup nie jest przeznaczona do zaawansowanych operacji skrobania, doskonale sprawdza się w ekstrakcji danych z plików w językach znaczników.
Dodatkowym atutem Beautiful Soup jest jej przejrzysta i szczegółowa dokumentacja.
Przejdźmy teraz do prostego sposobu instalacji Beautiful Soup na Twoim komputerze.
Jak zainstalować Beautiful Soup do web scrapingu?
Pip, czyli bezproblemowy menedżer pakietów Pythona, który został stworzony w 2008 roku, jest obecnie standardowym narzędziem używanym przez programistów do instalacji bibliotek i zależności Pythona.
Pip jest domyślnie instalowany razem z najnowszymi wersjami Pythona. Jeśli więc masz zainstalowaną aktualną wersję Pythona, możesz od razu przejść do instalacji Beautiful Soup.
Otwórz wiersz poleceń i wpisz następujące polecenie, aby szybko zainstalować Beautiful Soup:
pip install beautifulsoup4
Na ekranie powinieneś zobaczyć komunikat podobny do poniższego zrzutu ekranu.
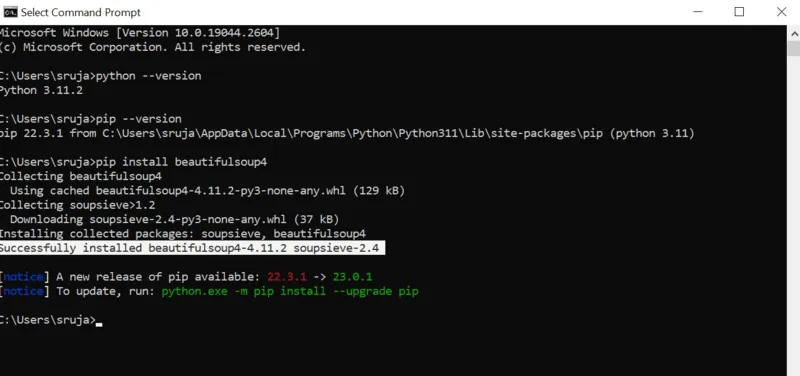
Upewnij się, że instalator PIP jest zaktualizowany do najnowszej wersji, aby uniknąć problemów podczas instalacji.
Polecenie aktualizujące instalator pip do najnowszej wersji wygląda następująco:
pip install --upgrade pip
W tym miejscu omówiliśmy połowę zagadnienia.
Teraz, gdy masz zainstalowaną Beautiful Soup na swoim komputerze, przyjrzyjmy się, jak wykorzystać ją do skrobania danych z sieci.
Jak importować i używać Beautiful Soup do web scrapingu?
Aby zaimportować Beautiful Soup do swojego skryptu Pythona, wpisz następujące polecenie w IDE:
from bs4 import BeautifulSoup
Teraz możesz używać Beautiful Soup w swoim pliku Pythona do skrobania danych.
Przeanalizujmy przykład kodu, aby zobaczyć, jak wyodrębnić interesujące nas dane za pomocą Beautiful Soup.
Możemy poinstruować Beautiful Soup, aby wyszukała konkretne tagi HTML na stronie internetowej i zeskrobała dane, które się w nich znajdują.
W tym przykładzie wykorzystamy stronę marketwatch.com, która aktualizuje ceny akcji różnych firm w czasie rzeczywistym. Spróbujemy wyciągnąć z niej trochę danych, aby zapoznać się z biblioteką Beautiful Soup.
Zaimportuj pakiet "requests", który pozwoli na odbieranie i odpowiadanie na żądania HTTP, oraz "urllib", który umożliwi pobranie strony internetowej z podanego adresu URL.
from urllib.request import urlopen import requests
Zapisz link do strony internetowej w zmiennej, aby łatwiej go używać w dalszej części kodu.
url="https://www.marketwatch.com/investing/stock/amzn"
Następnie, wykorzystując metodę "urlopen" z biblioteki "urllib", zapiszemy kod HTML strony w zmiennej. Przekaż adres URL do funkcji "urlopen" i przypisz wynik do zmiennej.
page = urlopen(url)
Utwórz obiekt Beautiful Soup i przeanalizuj kod HTML pobranej strony, wykorzystując parser "html.parser".
soup_obj = BeautifulSoup(page, 'html.parser')
W tym momencie cały skrypt HTML docelowej strony jest przechowywany w zmiennej "soup_obj".
Zanim przejdziemy dalej, przyjrzyjmy się kodowi źródłowemu strony, aby lepiej zrozumieć jego strukturę i tagi HTML.
Kliknij prawym przyciskiem myszy w dowolnym miejscu na stronie i wybierz opcję "Zbadaj" (lub podobną, w zależności od przeglądarki), jak pokazano poniżej.
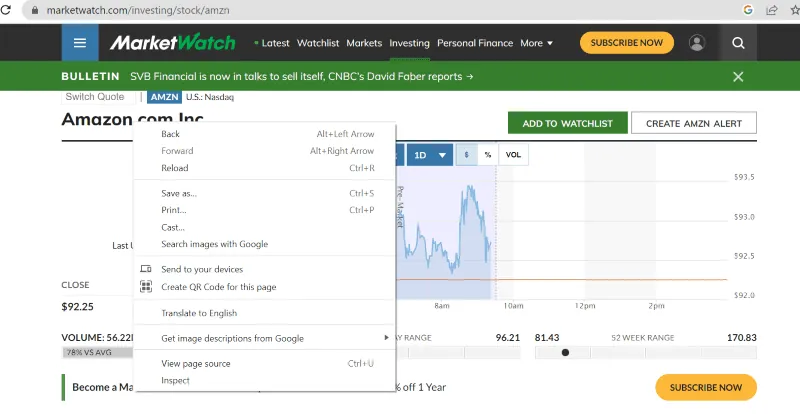
Kliknięcie "Zbadaj" otworzy panel z kodem źródłowym.
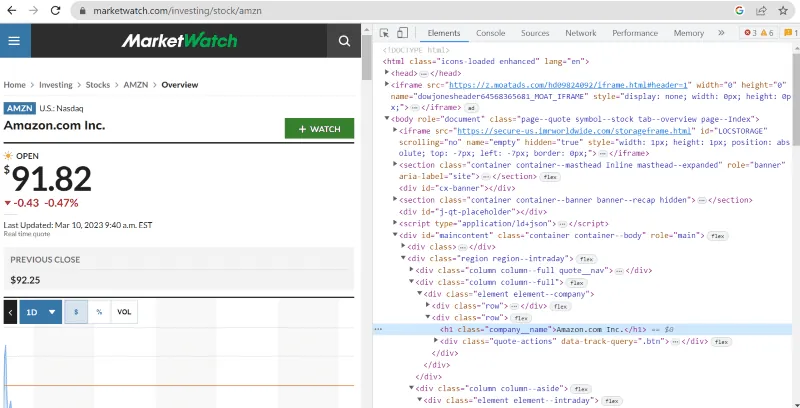
W kodzie źródłowym możesz znaleźć tagi, klasy CSS i inne szczegółowe informacje o każdym elemencie widocznym na stronie.
Metoda "find" w Beautiful Soup umożliwia wyszukiwanie konkretnych tagów HTML i pobieranie z nich danych. Aby tego dokonać, podajemy nazwę klasy i tagu, które chcemy wyodrębnić.
Na przykład, nazwa firmy "Amazon.com Inc." wyświetlana na stronie ma klasę CSS: "company__name" i znajduje się w tagu "h1". Możemy przekazać te informacje do metody "find", aby wyodrębnić odpowiedni fragment kodu HTML do zmiennej.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Wyświetlmy teraz kod HTML przechowywany w zmiennej "name" i sam tekst, który nas interesuje.
print(name) print(name.text)

Na ekranie zobaczysz wyodrębnione dane.
Web scraping strony IMDb
Wielu z nas sprawdza oceny filmów na stronie IMDb przed podjęciem decyzji o obejrzeniu. Ten przykład pokaże Ci, jak pobrać listę najwyżej ocenianych filmów i pomoże Ci lepiej zrozumieć, jak wykorzystywać Beautiful Soup do skrobania danych.
Krok 1: Zaimportuj biblioteki Beautiful Soup i requests.
from bs4 import BeautifulSoup import requests
Krok 2: Przypisz adres URL strony, którą chcemy zeskrobać, do zmiennej "url".
Wykorzystaj pakiet "requests" do pobrania kodu HTML z podanego adresu URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Krok 3: W poniższym fragmencie kodu przeanalizujemy kod HTML strony za pomocą Beautiful Soup, aby utworzyć obiekt "soup_obj".
soup_obj = BeautifulSoup(url.text, 'html.parser')
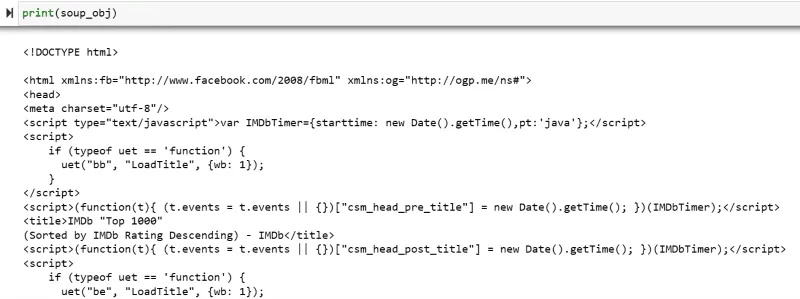
Zmienna "soup_obj" zawiera teraz cały skrypt HTML strony internetowej, jak na poniższym obrazku.
Przyjrzyjmy się kodowi źródłowemu strony, aby znaleźć fragment HTML zawierający dane, które chcemy pobrać.
Najedź kursorem na element strony, który chcesz wyodrębnić, kliknij go prawym przyciskiem myszy i wybierz opcję "Zbadaj" (lub podobną). Poniższe wizualizacje pomogą Ci lepiej zrozumieć ten proces.
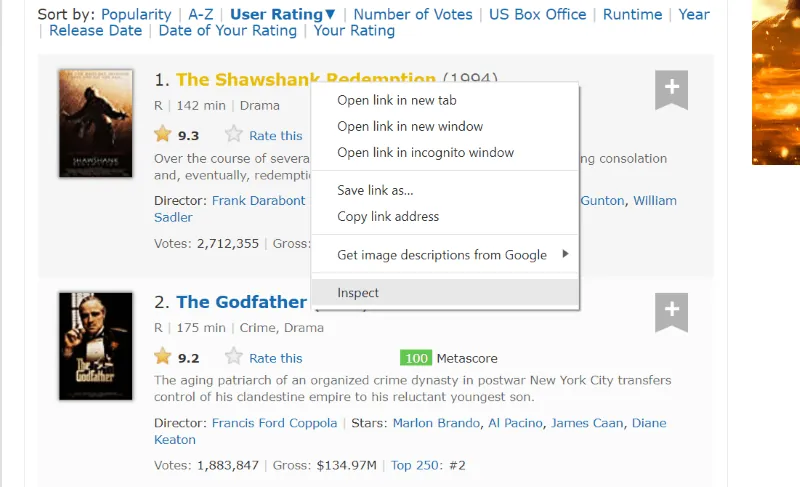
Klasa CSS "lister-list" zawiera wszystkie dane o filmach w postaci podziałów w kolejnych tagach "div".
W strukturze HTML każdego filmu, w klasie "lister-item mode-advanced", znajduje się tag "h3", w którym umieszczona jest nazwa filmu, jego pozycja na liście i rok wydania, jak pokazano na obrazku poniżej.
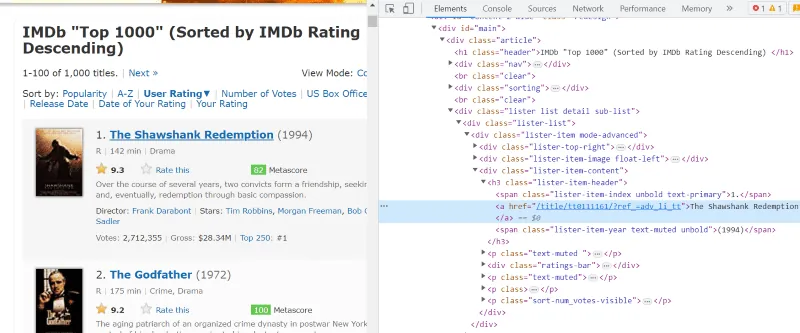
Uwaga: Metoda "find" w Beautiful Soup zwraca pierwszy tag pasujący do podanej nazwy. W przeciwieństwie do "find", metoda "find_all" zwraca wszystkie tagi pasujące do danego kryterium.
Krok 4: Możesz użyć metod "find" i "find_all", aby zapisać fragmenty kodu HTML zawierające nazwę, rangę i rok wydania każdego filmu w zmiennej listy.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Krok 5: Przejdź przez listę filmów przechowywaną w zmiennej "top_movies" i wyodrębnij nazwę, rangę i rok wydania każdego filmu jako tekst z fragmentów HTML, wykorzystując poniższy kod.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Na zrzucie ekranu z wynikiem zobaczysz listę filmów z ich nazwami, pozycjami na liście i rokiem wydania.
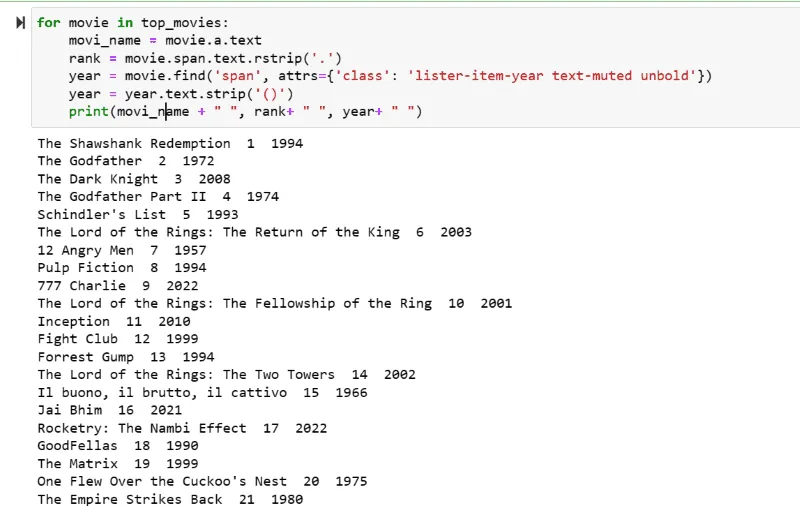
Możesz łatwo przenieść wyodrębnione dane do arkusza programu Excel, a następnie wykorzystać je do analizy.
Podsumowanie
Ten artykuł przeprowadził Cię przez proces instalacji biblioteki Beautiful Soup do skrobania stron internetowych. Dodatkowo, przedstawione przykłady skrobania powinny pomóc Ci rozpocząć własną przygodę z Beautiful Soup.
Jeśli interesuje Cię temat web scrapingu z użyciem Pythona, polecam zapoznanie się z kompleksowym przewodnikiem, który pogłębi Twoją wiedzę w tym zakresie.
