Pipeline jako kod wyjaśniony w najprostszy możliwy sposób
W procesie tworzenia oprogramowania, kluczową rolę odgrywają potoki CI/CD (Continuous Integration/Continuous Delivery), czyli ciągłej integracji i ciągłego dostarczania. Ułatwiają one automatyzację procesu budowania i wdrażania kodu w różnych środowiskach.
Niemniej jednak, samo tworzenie i zarządzanie takim potokiem może okazać się skomplikowanym zadaniem. W tym kontekście pojawia się koncepcja "Potoku jako Kodu" (Pipeline as Code), która zakłada definiowanie całego potoku CI/CD za pomocą kodu. Zamiast korzystać z graficznych interfejsów użytkownika i narzędzi opartych na zasadzie "przeciągnij i upuść", wykorzystuje się pliki konfiguracyjne do określenia, jak kod aplikacji ma być budowany, testowany i wdrażany.
Zanim jednak przejdziemy do szczegółowej analizy "Potoku jako Kodu" i sposobów jego implementacji, warto najpierw dokładnie zrozumieć, czym właściwie jest potok w kontekście rozwoju oprogramowania.
Czym jest potok w rozwoju oprogramowania?
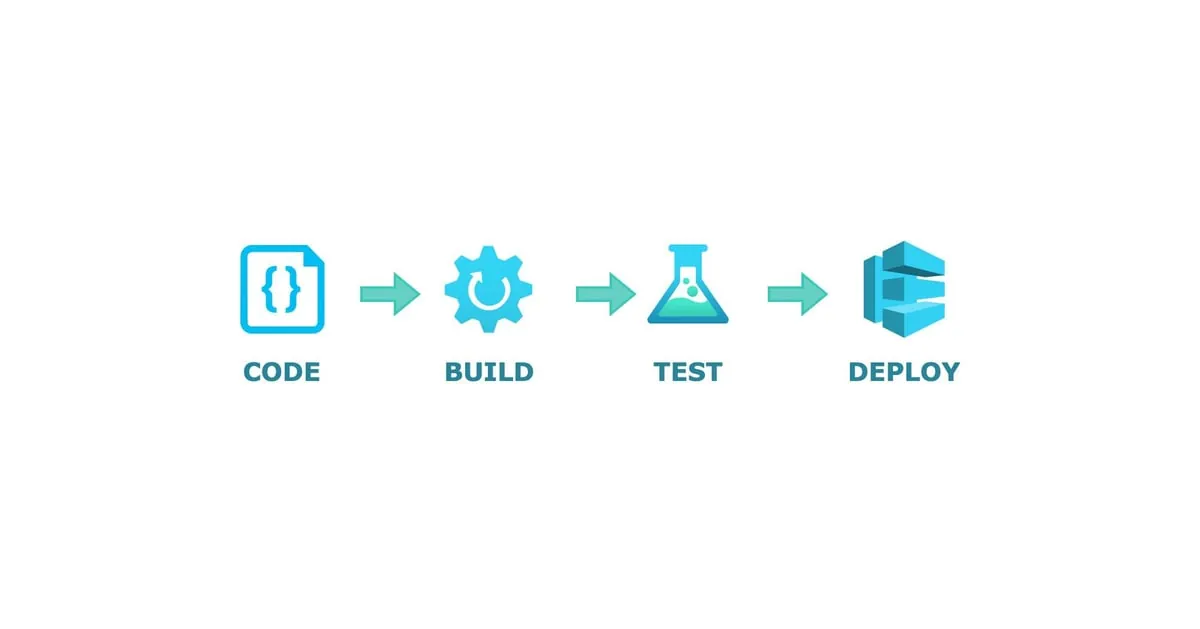
Potok w procesie wytwarzania oprogramowania to zautomatyzowana sekwencja kroków, która przetwarza najnowsze zmiany w kodzie. Wykonuje na nich ustalone procedury i wdraża je w docelowym środowisku. Aby lepiej to zobrazować, posłużmy się przykładem.
Załóżmy, że pracujesz nad projektem składającym się z trzech mikrousług. W jednej z nich wprowadziłeś nowe funkcje. W pierwszym kroku, chcesz przeprowadzić testy jednostkowe, które zweryfikują poprawność nowego kodu. Następnie, planujesz sprawdzić, czy kod jest zgodny ze standardami formatowania. Kolejnym etapem jest budowa kodu, a po niej wdrożenie go w dwóch różnych środowiskach, z których każde składa się z wielu maszyn. Na koniec, powinieneś wykonać testy integracyjne, aby upewnić się, że zmiany są kompatybilne z pozostałymi usługami.
Wszystkie te kroki można wykonać ręcznie, ale jest to czasochłonne i podatne na błędy. Czy istnieje więc sposób na zautomatyzowanie tego procesu? Oczywiście! Możesz zdefiniować potok, w którym określisz każdy z tych kroków. Wówczas, za każdym razem, gdy wprowadzisz zmiany w kodzie, wystarczy uruchomić potok, a cały proces odbędzie się automatycznie, eliminując konieczność manualnego wykonywania poszczególnych etapów.
Korzyści wynikające z Potoku jako Kodu
W przypadku korzystania z narzędzi opartych na interfejsach graficznych (np. typu "przeciągnij i upuść"), śledzenie zmian, utrzymanie standardów oraz wspieranie współpracy staje się wyzwaniem. Potok jako Kod stanowi lepsze podejście do definiowania potoku rozwoju oprogramowania.
Pomaga w zachowaniu spójności, promuje automatyzację, umożliwia powtarzalność procesów i ponowne wykorzystanie tego samego potoku w innych systemach. Ponadto, podobnie jak kod aplikacji, kod definiujący potok wspiera współpracę zespołową.
#1. Spójność
Zapisanie definicji potoku w formie tekstowej gwarantuje, że proces będzie przebiegał w jednolity sposób. Poprzez narzucenie standardowego przepływu pracy dla wszystkich kompilacji i wdrożeń, osiąga się spójność i redukuje ryzyko wystąpienia nieoczekiwanych problemów.
Spójność przyczynia się również do lepszej kontroli zgodności i bezpieczeństwa. Definiując potok w spójny sposób, można wprowadzić skanowanie bezpieczeństwa i testy podatności na ataki w taki sposób, aby wyeliminować ryzyko przeoczenia jakiegokolwiek zagrożenia.
#2. Powtarzalność
Po stworzeniu potoku i włączeniu automatyzacji, ma się pewność, że każdy fragment kodu przechodzi przez te same etapy i weryfikacje.
Kod jest poddawany identycznemu procesowi kompilacji i wdrożenia za każdym razem, gdy uruchamiany jest potok, co zapewnia powtarzalność we wszystkich cyklach.
#3. Współpraca
Ponieważ kod jest podstawowym medium, za pomocą którego tworzy się potok, sprzyja to współpracy. Członkowie zespołu mogą wspólnie pracować nad kodem potoku, podobnie jak pracują nad kodem aplikacji.
Potok jako Kod umożliwia również kontrolę wersji i przeglądanie kodu, co gwarantuje przestrzeganie najlepszych praktyk oraz wczesne wykrywanie potencjalnych problemów.
Teraz, gdy znamy zalety Potoku jako Kodu, zobaczmy, jak możemy utworzyć własny potok.
Potok jako Kod w Jenkins
W kontekście systemów ciągłej integracji i ciągłego dostarczania (CI/CD), Jenkins jest jednym z wiodących serwerów automatyzacji typu open source. Umożliwia on łatwą integrację zmian w kodzie, automatyzację testowania i budowania, a także wdrażanie oprogramowania. Wszystko to w sposób niezawodny i efektywny.
Niezależnie od tego, czy jesteś hobbystą, który chce nauczyć się więcej o potokach automatyzacji, czy też budujesz złożone systemy dla przedsiębiorstw, Jenkins jest w stanie dostosować się do unikalnych wymagań każdego projektu. Szeroki wybór wtyczek i stale rosnąca społeczność użytkowników pomagają w pełni wykorzystać możliwości automatyzacji.
W Jenkins, potok jest zbiorem różnorodnych wtyczek, ułożonych w określonej kolejności, które tworzą system CI/CD. Niezależnie od tego, czy masz do czynienia z prostymi, czy złożonymi przypadkami użycia, możesz zdefiniować potok za pomocą kodu, korzystając ze składni języka DSL (Domain Specific Language) specyficznej dla potoków. Język DSL jest oparty na Apache Groovy.
Podstawowym elementem Potoku jako Kodu w Jenkins jest Jenkinsfile – plik tekstowy, który zawiera kod definiujący wszystkie etapy i działania potoku. Zobaczmy, jak utworzyć potok jako kod za pomocą pliku Jenkinsfile.
Jak utworzyć potok jako kod?
Po zainstalowaniu i uruchomieniu Jenkins, otwórz interfejs webowy w przeglądarce. Może być konieczne zalogowanie się. Następnie, zostaniesz przekierowany na stronę główną Panelu. To stąd będziesz tworzyć swój potok.
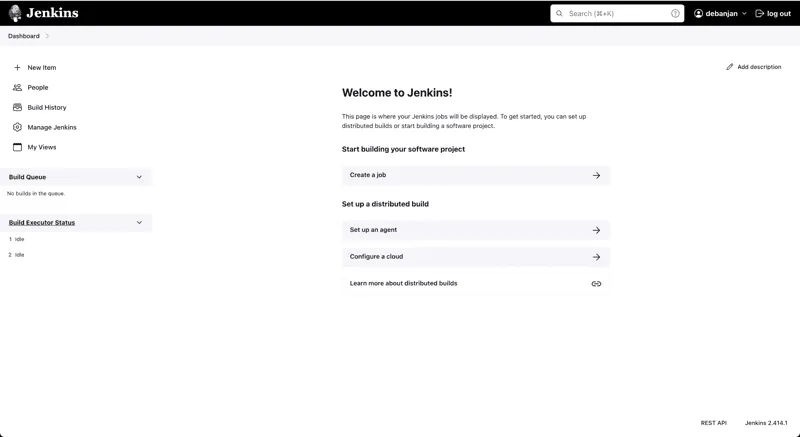
- W panelu po lewej stronie znajdź przycisk "Nowy element".
- Kliknij go, aby przejść do kolejnej strony.
- Na nowej stronie zostaniesz poproszony o utworzenie elementu.
- W polu "Wprowadź nazwę elementu" podaj jego nazwę. Jest to pole obowiązkowe.
- Pamiętaj, że na podstawie podanej nazwy zostanie utworzony katalog. Dlatego warto unikać białych znaków, aby uniknąć ewentualnych problemów.
- Następnie, wybierz opcję "Potok" i kliknij przycisk "OK" u dołu ekranu.
- Zostanie wyświetlone okno konfiguracji.
- Kliknij opcję "Potok" w lewym panelu lub przewiń w dół do sekcji "Potok".
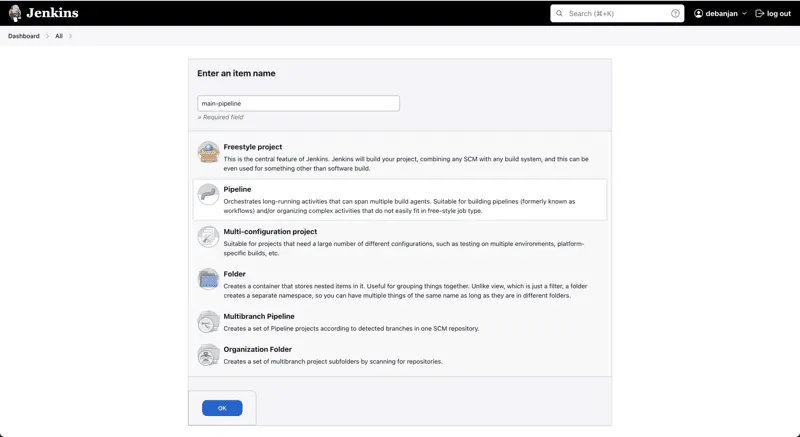
Zacznijmy od prostego potoku, który można skonfigurować bezpośrednio w interfejsie użytkownika.
Utwórz potok jako kod bezpośrednio w Jenkins
Po przejściu do sekcji "Potok", możesz utworzyć swój pierwszy potok jako kod.
W menu rozwijanym "Definicja" wybierz opcję "Skrypt potoku". Poniżej pojawi się obszar "Skrypt", w którym możesz zakodować swój potok. Jenkins będzie przechowywać skrypt utworzony w tym miejscu.
Jenkins umożliwia wybór pomiędzy dwoma stylami kodowania lub składniami: składnią deklaratywną i składnią skryptową. Składnia deklaratywna jest łatwa w użyciu i idealna dla prostych potoków, natomiast składnia skryptowa jest przeznaczona dla zaawansowanych użytkowników i projektowania złożonych przepływów.
Używając składni deklaratywnej, utwórz 3 proste etapy: "Zbuduj kod", "Przetestuj kod" i "Wdróż kod", korzystając z poniższego kodu:
pipeline {
agent any
stages {
stage('Build Code') {
steps {
echo 'To jest krok budowania...'
}
}
stage('Test Code') {
steps {
echo 'To jest krok testowania...'
}
}
stage('Deploy Code') {
steps {
echo 'To jest krok wdrażania...'
}
}
}
}
Możesz także użyć składni skryptowej, jak pokazano poniżej:
node {
stage('Build Code') {
echo 'To jest krok budowania...'
}
stage('Test Code') {
echo 'To jest krok testowania...'
}
stage('Deploy Code') {
echo 'To jest krok wdrażania...'
}
}
Kliknij "Zapisz". Następnie kliknij przycisk "Buduj teraz" w lewym panelu, co uruchomi utworzony potok.
Po zakończeniu potoku, można sprawdzić jego przebieg w "Historii kompilacji". Jeśli jest to pierwsze uruchomienie, kliknij obecny numer kompilacji nr 1. Następnie, wybierz "Wyjście konsoli" w lewym panelu. Dla każdego etapu, znajdziesz 3 instrukcje echo zdefiniowane w kodzie potoku.
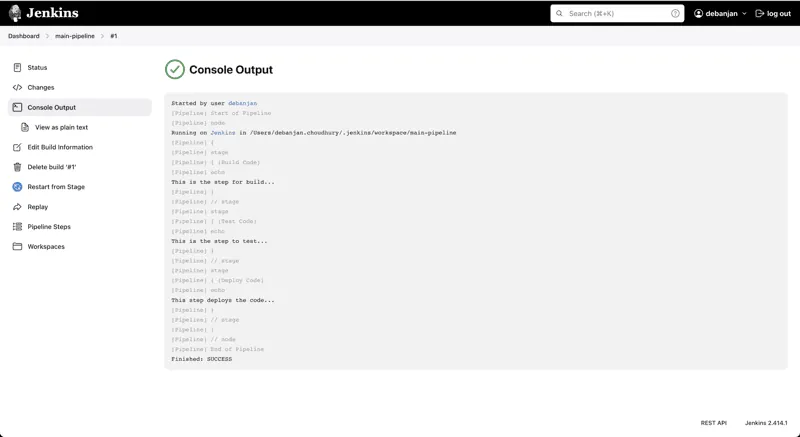
Utwórz potok jako kod, korzystając z pliku zewnętrznego
Utrzymywanie potoku bezpośrednio w Jenkins staje się trudne, gdy zaczyna się on komplikować. W takim przypadku, lepiej jest utworzyć plik zewnętrzny i użyć go do zdefiniowania potoku.
Przed utworzeniem potoku w Jenkins, potrzebne będzie zewnętrzne repozytorium i system kontroli wersji. Utwórzmy repozytorium Git i umieśćmy je w GitHub. Tam zapiszesz plik Jenkinsfile.
- Przejdź do swojego profilu na GitHub. Jeśli nie masz konta, możesz założyć je bezpłatnie.
- Utwórz nowe repozytorium, na przykład o nazwie "customJenkins".
- Upewnij się, że masz zainstalowanego Gita na swoim komputerze.
- Utwórz folder w wybranej lokalizacji.
- Przejdź do tego folderu i otwórz terminal.
- Zainicjuj puste repozytorium Git za pomocą polecenia "git init".
- Teraz utwórz nowy plik, który będzie Twoim plikiem Jenkinsfile. Nazwij go na przykład "customJenkinsfile".
- W tym pliku zapisz kod definiujący potok. Jako przykład, użyj kodu z poniższego przykładu:
pipeline {
agent any
stages {
stage('Build Code') {
steps {
echo 'To jest krok budowania zdefiniowany w pliku zewnętrznym...'
}
}
stage('Test Code') {
steps {
echo 'To jest krok testowania zdefiniowany w pliku zewnętrznym...'
}
}
stage('Deploy Code') {
steps {
echo 'To jest krok wdrażania zdefiniowany w pliku zewnętrznym...'
}
}
}
}
- Dodaj nowo utworzony plik do Gita, używając polecenia "git add --all" w terminalu.
- Zatwierdź zmiany w Git za pomocą polecenia "git commit -m "Utworzono niestandardowy plik jenkinsfile"".
- Połącz swoje lokalne repozytorium Git ze zdalnym repozytorium, używając polecenia "git remote add origin [email protected]:
/customJenkins.git". - Następnie, prześlij plik do zdalnego repozytorium (GitHub) za pomocą polecenia "git push --set-upstream origin master".
W ten sposób, utworzyłeś zdalne repozytorium w GitHub, które zawiera Twój niestandardowy plik Jenkinsfile. Teraz skonfigurujmy Jenkins, aby z niego korzystał.
Skonfiguruj Jenkins, aby używał pliku Jenkinsfile z GitHub
- Otwórz pulpit nawigacyjny Jenkins.
- Utwórz nowy potok lub kliknij opcję "Konfiguruj" w lewym panelu w istniejącym potoku.
- Przewiń w dół do sekcji "Potok".
- Z rozwijanej listy "Definicja" wybierz opcję "Skrypt potoku z SCM".
- W opcji "SCM" wybierz "Git".
- W sekcji "Repozytoria" w polu "Adres URL repozytorium" podaj link do swojego repozytorium na GitHub.
- Upewnij się, że w sekcji "Branches to build" specyfikator gałęzi jest ustawiony na "*/master".
- Przewiń w dół do opcji "Ścieżka skryptu". W tym miejscu podaj nazwę swojego pliku Jenkins, np. "customJenkinsfile". Kliknij "Zapisz".
Teraz możesz uruchomić swój potok. Jenkins najpierw pobierze kod ze zdalnego repozytorium. Następnie, utworzy potok na podstawie niestandardowego pliku Jenkinsfile i uruchomi wszystkie zdefiniowane etapy.
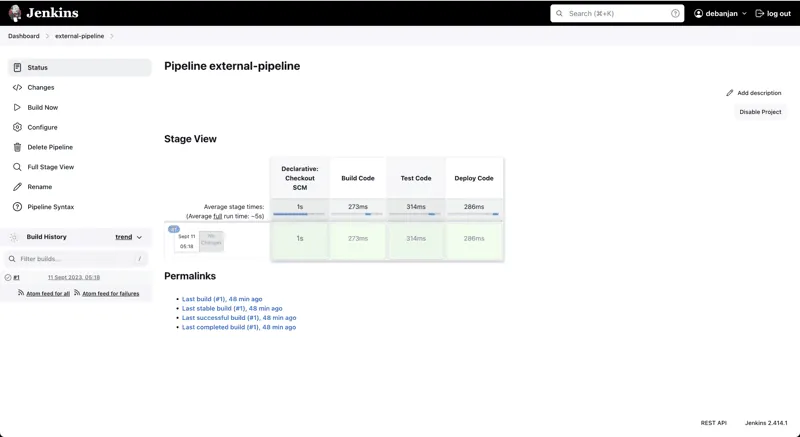
Udało Ci się z powodzeniem utworzyć własny potok wytwarzania oprogramowania, korzystając z podejścia Potok jako Kod. Dodatkowo, skrypt potoku jest objęty kontrolą wersji. Wszystkie zmiany wprowadzone w kodzie potoku, mogą być teraz śledzone za pomocą systemu Git. Warto teraz przyjrzeć się najlepszym praktykom związanym z Potokiem jako Kodem.
Najlepsze praktyki tworzenia skutecznego Potoku jako Kodu
Oto kilka najlepszych praktyk, których należy przestrzegać podczas tworzenia potoku jako kodu:
- Utrzymuj przejrzystość potoku i unikaj tworzenia zbyt skomplikowanych warunków.
- Jeśli wykonujesz w potoku zbyt wiele poleceń, podziel je na mniejsze, oddzielne kroki.
- Używaj zewnętrznych plików, objętych kontrolą wersji, do przechowywania skryptów potoku.
- Wykorzystuj funkcje języka kodowania, takie jak Groovy, do integracji różnych kroków potoku.
- Unikaj wywołań Jenkins.getInstance lub jego metod dostępu, aby zapobiegać problemom z bezpieczeństwem i wydajnością.
- Nie nadpisuj wbudowanych poleceń potoku, takich jak "sh" i "timeout".
- Twórz zewnętrzne narzędzia lub skrypty do złożonych zadań wymagających dużej mocy obliczeniowej i podłączaj je do potoku.
- Wykorzystaj szeroką gamę dostępnych wtyczek dla Jenkins, aby rozwiązać konkretne potrzeby.
- Upewnij się, że uwzględniłeś obsługę wyjątków i błędów, ponieważ zawsze istnieje możliwość, że coś pójdzie nie tak.
- Nie twórz potoku jako kodu, który jest ściśle powiązany z dużą ilością logiki biznesowej.
- W miarę możliwości używaj sparametryzowanych argumentów, aby umożliwić ponowne wykorzystanie potoku.
Potok jako Kod: prosty sposób na złożone procesy
Podsumowując, Potok jako Kod upraszcza automatyzację potoku CI/CD, poprzez przedstawienie całego procesu w formie kodu. Potoki CI/CD automatyzują budowanie, testowanie i wdrażanie zmian w kodzie. Potok jako Kod idzie o krok dalej. Pozwala on zdefiniować przepływ pracy za pomocą kodu tekstowego, zamiast opierać się na interfejsach graficznych.
Dzięki Potokowi jako Kodowi, masz pewność, że każdy etap przepływu pracy odbywa się we właściwej kolejności. Zmniejszasz ryzyko napotkania nieoczekiwanych problemów. Dodatkowo, zyskujesz korzyści, takie jak spójność, powtarzalność i lepsza współpraca.
Dzięki temu przewodnikowi wiesz już, jak tworzyć własne potoki za pomocą Jenkins, popularnego narzędzia CI/CD. Jenkins oferuje silną i elastyczną platformę do wdrażania Potoku jako Kodu za pośrednictwem plików Jenkinsfile. Postępuj zgodnie z najlepszymi praktykami i twórz przepływy pracy, które odpowiadają wszystkim Twoim wymaganiom.
Jeśli chcesz dowiedzieć się więcej o Jenkins, możesz sprawdzić, jak stworzyć swój własny potok Jenkinsa.
