Ponad 30 pytań i odpowiedzi do wywiadu Hadoop
Według danych statystycznych opublikowanych przez Forbes, imponujące 90% firm na całym świecie wykorzystuje zaawansowaną analitykę Big Data w procesie tworzenia raportów inwestycyjnych.
Wraz ze wzrostem popularności technologii Big Data, obserwujemy niespotykany dotąd przyrost ofert pracy związanych z platformą Hadoop.
Z myślą o osobach aspirujących do roli specjalisty Hadoop, przygotowaliśmy zbiór pytań i odpowiedzi, które mogą okazać się nieocenione podczas rozmowy rekrutacyjnej. Mamy nadzieję, że nasz artykuł pomoże Ci w skutecznym przejściu przez ten etap.
Być może wiedza o atrakcyjnych zarobkach na stanowiskach związanych z Hadoop i Big Data dodatkowo zmotywuje Cię do solidnego przygotowania się do rozmowy, prawda? 🤔
- Według serwisu Indeed.com, średnie roczne wynagrodzenie programisty Big Data Hadoop w Stanach Zjednoczonych wynosi 144 000 USD.
- Brytyjski portal itjobswatch.co.uk podaje, że przeciętne wynagrodzenie specjalisty Hadoop w Wielkiej Brytanii to 66 750 funtów.
- Z kolei w Indiach, dane z Indeed.com wskazują na średnie roczne zarobki na poziomie 16 000 000 funtów.
Brzmi obiecująco, prawda? Zatem, przejdźmy teraz do zgłębiania tajników technologii Hadoop.
Czym jest Hadoop?
Hadoop to popularny framework, napisany w języku Java, który wykorzystuje modele programistyczne do przetwarzania, przechowywania oraz analizy ogromnych zbiorów danych.
Jego architektura umożliwia skalowanie od pojedynczych serwerów do rozległych sieci maszyn, oferując lokalne zasoby obliczeniowe i przestrzenie dyskowe. Dodatkowo, jego zdolność do wykrywania i radzenia sobie z awariami na poziomie aplikacji, skutkująca wysoką dostępnością usług, czyni Hadoop wyjątkowo niezawodnym rozwiązaniem.
Przejdźmy teraz bezpośrednio do najczęściej pojawiających się pytań podczas rekrutacji na stanowisko związane z Hadoopem, wraz z prawidłowymi odpowiedziami.
Pytania i odpowiedzi na rozmowie kwalifikacyjnej z Hadoopem
Jaka jest podstawowa jednostka przechowywania danych w Hadoop?
Odpowiedź: Jednostką pamięci masowej w Hadoop jest Hadoop Distributed File System (HDFS).
Czym różni się Network Attached Storage od rozproszonego systemu plików Hadoop?
Odpowiedź: HDFS, będący podstawowym systemem przechowywania danych w Hadoop, to rozproszony system plików, który pozwala na przechowywanie olbrzymich zbiorów danych na zwykłym sprzęcie. Z drugiej strony, NAS to serwer danych na poziomie plików, umożliwiający heterogenicznym klientom dostęp do informacji.
W przypadku NAS, dane są przechowywane na dedykowanym sprzęcie, natomiast HDFS rozdziela bloki danych pomiędzy wszystkie maszyny w klastrze Hadoop.
NAS wykorzystuje zaawansowane urządzenia pamięci masowej, które są stosunkowo kosztowne, podczas gdy standardowy sprzęt używany w HDFS jest bardziej ekonomiczny.
NAS przechowuje dane oddzielnie od procesów obliczeniowych, co czyni go nieodpowiednim dla MapReduce. Z kolei architektura HDFS jest zoptymalizowana do współpracy z frameworkiem MapReduce. Obliczenia są przenoszone do danych, a nie odwrotnie, jak to ma miejsce w tradycyjnych systemach.
Wyjaśnij koncepcję MapReduce i tasowania danych (shuffling) w Hadoop.
Odpowiedź: MapReduce to dwa podstawowe etapy, które programy Hadoop wykonują, aby umożliwić skalowanie od kilkuset do tysięcy serwerów w klastrze. Z kolei tasowanie danych polega na przeniesieniu wyników etapu mapowania z maperów do odpowiednich reduktorów.
Przybliż architekturę Apache Pig.
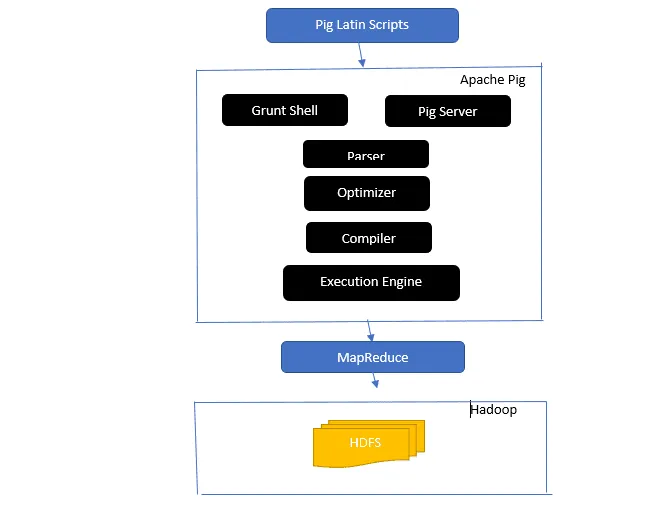 Architektura Apache Pig
Architektura Apache Pig
Odpowiedź: Architektura Apache Pig obejmuje interpreter Pig Latin, który przetwarza i analizuje duże zbiory danych przy użyciu skryptów w języku Pig Latin.
Platforma Pig zawiera również zestaw operacji na danych, takich jak łączenie, ładowanie, filtrowanie, sortowanie i grupowanie.
Język Pig Latin wykorzystuje mechanizmy wykonawcze, takie jak powłoki Grant, UDF i osadzone, do tworzenia skryptów, które wykonują określone zadania.
Pig ułatwia pracę programistom, konwertując skrypty Pig Latin na serię zadań Map-Reduce.
Komponenty architektury Apache Pig obejmują:
- Parser – Analizuje skrypty Pig, weryfikuje składnię i typy danych. Wynikiem działania parsera jest DAG (directed acyclic graph), reprezentujący logiczne instrukcje i operatory Pig Latin.
- Optymalizator – Wprowadza logiczne optymalizacje, takie jak projekcja i naciskanie, do DAG.
- Kompilator – Przekształca zoptymalizowany plan logiczny z optymalizatora na serię zadań MapReduce.
- Execution Engine – Odpowiada za ostateczne wykonanie zadań MapReduce, generując żądany wynik.
- Tryby wykonania – Apache Pig oferuje tryby wykonania, takie jak lokalny i Map Reduce.
Odpowiedź: W Local Metastore usługa działa w tej samej maszynie JVM co Hive, ale łączy się z bazą danych w oddzielnym procesie na tej samej lub zdalnej maszynie. Natomiast Remote Metastore działa w osobnej maszynie JVM, niezależnie od JVM Hive.
Jakie są "pięć V" Big Data?
Odpowiedź: "Pięć V" to kluczowe cechy danych Big Data. Obejmują:
- Wartość (Value): Big Data ma generować istotne korzyści dla organizacji, która je wykorzystuje. Wartość ta wynika z analizy danych, odkrywania wzorców i wglądów, co przekłada się na lepsze relacje z klientami i skuteczniejsze operacje.
- Różnorodność (Variety): Odnosi się do heterogeniczności typów gromadzonych danych. Obejmuje różne formaty, takie jak CSV, wideo, audio itp.
- Wolumen (Volume): Określa znaczną ilość i rozmiar danych, które organizacja analizuje. Dane te rosną w sposób wykładniczy.
- Prędkość (Velocity): Jest to wykładnicza szybkość, z jaką dane są generowane i przetwarzane.
- Wiarygodność (Veracity): Odnosi się do pewności danych – ich dokładności, kompletności i spójności.
Wyjaśnij różne typy danych w języku Pig Latin.
Odpowiedź: Pig Latin oferuje typy danych atomowe oraz złożone.
Atomowe typy danych to podstawowe typy danych używane w wielu językach. Należą do nich:
- Int – 32-bitowa liczba całkowita ze znakiem. Przykład: 13
- Long – 64-bitowa liczba całkowita. Przykład: 10l
- Float – 32-bitowa liczba zmiennoprzecinkowa. Przykład: 2.5F
- Double – 64-bitowa liczba zmiennoprzecinkowa. Przykład: 23.4
- Boolean – wartość logiczna (Prawda/Fałsz)
- Datetime – wartość daty i godziny. Przykład: 1980-01-01T00:00.00.000+00:00
Złożone typy danych to:
- Mapa – zbiór par klucz-wartość. Przykład: [‘color’#’yellow’, ‘number’#3]
- Torba – zbiór krotek (tuples). Symbol: “{}”. Przykład: {(Henryk, 32), (Kiti, 47)}
- Krotka – uporządkowany zbiór pól. Przykład: (wiek, 33 lata)
Czym są Apache Oozie i Apache ZooKeeper?
Odpowiedź: Apache Oozie to harmonogram zadań Hadoop, który pozwala na planowanie i łączenie zadań Hadoop w jedną logiczną całość.
Z kolei Apache Zookeeper współpracuje z różnymi usługami w środowisku rozproszonym, ułatwiając m.in. synchronizację, grupowanie, konfigurację i nazywanie. Zapewnia także wsparcie dla kolejkowania i wyboru lidera.
Jaką rolę pełnią Combiner, RecordReader i Partitioner w operacji MapReduce?
Odpowiedź: Sumator działa jak mini-reduktor. Przetwarza dane z zadań mapowania, a następnie przekazuje wynik do reduktora.
RecordReader komunikuje się z InputSplit i konwertuje dane na pary klucz-wartość, aby program mapujący mógł z nich korzystać.
Partitioner decyduje o liczbie zadań redukcji, które są potrzebne do podsumowania danych, i określa, jak wyniki sumatora są przesyłane do reduktora. Kontroluje również partycjonowanie kluczy pośrednich z wyjścia mapowania.
Wymień różne dystrybucje Hadoop oferowane przez konkretnych dostawców.
Odpowiedź: Dostawcy rozszerzający możliwości Hadoop to:
- IBM Open Platform
- Cloudera CDH Hadoop Distribution
- MapR Hadoop Distribution
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Key Big Data Suite
- Datastax Enterprise Analytics
- Microsoft Azure HDInsight — dystrybucja Hadoop oparta na chmurze
Dlaczego HDFS jest odporny na awarie?
Odpowiedź: HDFS replikuje dane w różnych węzłach, zapewniając odporność na błędy. W przypadku awarii jednego z węzłów dane mogą zostać pobrane z innego.
Wyjaśnij różnicę między federacją a wysoką dostępnością w HDFS.
Odpowiedź: Federacja HDFS umożliwia ciągły przepływ danych w przypadku awarii jednego węzła, natomiast wysoka dostępność wymaga dwóch oddzielnych maszyn, na których działają aktywny i pasywny węzeł NameNode.
Federacja może mieć wiele niezależnych węzłów NameNode, podczas gdy w przypadku wysokiej dostępności mamy tylko dwa: aktywny i rezerwowy.
Węzły nazw w federacji współdzielą metadane, ale każdy ma własną pulę. W przypadku wysokiej dostępności aktywny węzeł działa, podczas gdy pasywny pozostaje w trybie uśpienia i aktualizuje swoje metadane.
Jak sprawdzić status bloków i kondycję systemu plików HDFS?
Odpowiedź: Aby sprawdzić stan systemu plików HDFS, użyj polecenia `hdfs fsck /` jako użytkownik root lub z poziomu konkretnego katalogu.
Polecenie HDFS fsck:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Opis polecenia:
- `-files`: Wyświetla sprawdzane pliki.
- `–locations`: Wyświetla lokalizacje bloków podczas sprawdzania.
Polecenie sprawdzające stan bloków:
hdfs fsck <ścieżka> -files -blocks
- `<ścieżka>`: Ścieżka, od której rozpoczyna się sprawdzanie.
- `–blocks`: Wyświetla bloki pliku podczas sprawdzania.
Kiedy używamy poleceń `rmadmin-refreshNodes` i `dfsadmin-refreshNodes`?
Odpowiedź: Polecenia te służą do odświeżania informacji o węzłach, które zostały uruchomione lub zakończyły działanie.
Polecenie `dfsadmin-refreshNodes` odświeża konfigurację węzła NameNode. Polecenie `rmadmin-refreshNodes` wykonuje zadania administracyjne w ResourceManager.
Co to jest punkt kontrolny (checkpoint) w HDFS?
Odpowiedź: Punkt kontrolny to operacja łączenia najnowszych zmian w systemie plików z najnowszym FSImage, co zmniejsza rozmiar plików dziennika edycji i przyspiesza uruchamianie NameNode. Punkt kontrolny jest wykonywany przez Secondary NameNode.
Dlaczego HDFS jest odpowiedni do aplikacji przetwarzających duże zbiory danych?
Odpowiedź: Architektura HDFS, oparta na węzłach DataNode i NameNode, implementuje rozproszony system plików o wysokiej wydajności. NameNode przechowuje metadane w pamięci RAM, co ogranicza liczbę plików HDFS.
Co robi polecenie `jps`?
Odpowiedź: Polecenie `jps` (Java Virtual Machine Process Status) sprawdza, czy działają demony Hadoop, takie jak NodeManager, DataNode, NameNode i ResourceManager. Należy je uruchomić z poziomu katalogu głównego.
Co to jest „wykonanie spekulacyjne” w Hadoop?
Odpowiedź: Jest to proces uruchamiania dodatkowej instancji zadania (zadanie spekulacyjne) na innym węźle, w przypadku wykrycia powolnego zadania, zamiast próby naprawy go na pierwotnym węźle. Wykonanie spekulacyjne oszczędza czas, szczególnie w środowiskach o dużym obciążeniu.
Wymień trzy tryby, w których może działać Hadoop.
Odpowiedź: Hadoop może działać w trzech trybach:
- Węzeł autonomiczny (Standalone): Usługi Hadoop są uruchamiane na lokalnym systemie plików w jednym procesie Java.
- Pseudo-rozproszony (Pseudo-distributed): Wszystkie usługi Hadoop są uruchamiane na jednym wdrożeniu Hadoop.
- W pełni rozproszony (Fully distributed): Usługi główne i podrzędne Hadoop są uruchamiane na oddzielnych węzłach.
Co to jest UDF?
Odpowiedź: UDF (funkcje zdefiniowane przez użytkownika) pozwalają na kodowanie niestandardowych funkcji, które mogą być wykorzystywane do przetwarzania wartości kolumn podczas zapytań Impala.
Co to jest DistCp?
Odpowiedź: DistCp (Distributed Copy) to narzędzie do kopiowania dużych ilości danych między klastrami lub wewnątrz klastra. Wykorzystując MapReduce, DistCp efektywnie realizuje rozproszone kopiowanie danych, obsługuje błędy i raportuje o przebiegu.
Odpowiedź: Hive metastore to usługa, która przechowuje metadane tabel Hive w relacyjnej bazie danych, np. MySQL. Zapewnia interfejs API do zarządzania metadanymi.
Zdefiniuj RDD.
Odpowiedź: RDD (Resilient Distributed Datasets) to struktura danych Sparka, niezmienny zbiór danych, który jest przetwarzany na różnych węzłach klastra.
W jaki sposób można dołączyć biblioteki natywne do zadań YARN?
Odpowiedź: Można to zrobić, używając `-Djava.library.path` lub ustawiając `LD+LIBRARY_PATH` w pliku `.bashrc`:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Wyjaśnij „WAL” w HBase.
Odpowiedź: WAL (Write Ahead Log) to protokół odzyskiwania, który rejestruje zmiany danych z MemStore w HBase w magazynie plików. WAL odzyskuje te dane w razie awarii RegionalServer lub przed opróżnieniem MemStore.
Czy YARN zastępuje Hadoop MapReduce?
Odpowiedź: Nie, YARN nie jest zamiennikiem MapReduce. Jest za to częścią Hadoop 2.0 (MapReduce 2), który wspiera MapReduce.
Jaka jest różnica między `ORDER BY` a `SORT BY` w Hive?
Odpowiedź: Oba polecenia sortują dane, ale `SORT BY` może sortować dane tylko częściowo. `SORT BY` wymaga reduktora do sortowania wierszy. Jeśli używamy wielu reduktorów, wynik może być częściowo posortowany.
`ORDER BY` wymaga tylko jednego reduktora, zapewniając całkowite posortowanie wyników. Można go też używać ze słowem kluczowym `LIMIT`, aby skrócić czas sortowania.
Jaka jest różnica między Spark a Hadoop?
Odpowiedź: Obie platformy służą do przetwarzania rozproszonego, ale różnią się podejściem. Hadoop jest wydajny w przetwarzaniu wsadowym, a Spark w przetwarzaniu danych w czasie rzeczywistym.
Hadoop odczytuje i zapisuje dane do HDFS, a Spark używa koncepcji RDD (Resilient Distributed Dataset), przetwarzając dane w pamięci RAM.
Hadoop to platforma o dużych opóźnieniach, bez interaktywnego trybu przetwarzania, a Spark charakteryzuje się niskimi opóźnieniami i możliwością interaktywnego przetwarzania danych.
Porównaj Sqoop i Flume.
Odpowiedź: Sqoop i Flume to narzędzia Hadoop, które pozyskują dane z różnych źródeł i ładują je do HDFS.
- Sqoop (SQL-to-Hadoop) pobiera ustrukturyzowane dane z baz danych (np. Teradata, MySQL, Oracle), a Flume służy do pozyskiwania danych nieustrukturyzowanych (np. z logów) i ładowania ich do HDFS.
- Flume jest sterowany zdarzeniami, a Sqoop nie.
- Sqoop używa architektury opartej na konektorach, a Flume architektury opartej na agentach.
- Flume łatwo gromadzi i agreguje dane, a Sqoop służy do równoległego przesyłania danych, co skutkuje wieloma plikami wyjściowymi.
Wyjaśnij, czym jest BloomMapFile.
Odpowiedź: BloomMapFile rozszerza klasę MapFile i wykorzystuje filtry Blooma do szybkiego testowania obecności klucza.
Wymień różnice między HiveQL a PigLatin.
Odpowiedź: HiveQL to deklaratywny język podobny do SQL, a PigLatin jest proceduralnym językiem przepływu danych wysokiego poziomu.
Co to jest czyszczenie danych?
Odpowiedź: Czyszczenie danych to proces usuwania lub naprawiania błędów danych, takich jak nieprawidłowe, niekompletne, uszkodzone, zduplikowane czy źle sformatowane dane. Poprawia jakość danych i zapewnia dokładniejsze informacje do podejmowania decyzji w organizacji.
Podsumowanie 💃
W obliczu rosnącej liczby ofert pracy w dziedzinie Big Data i Hadoop, warto zwiększyć swoje szanse na zdobycie wymarzonej posady. Pytania i odpowiedzi zamieszczone w tym artykule pomogą Ci przygotować się do nadchodzącej rozmowy rekrutacyjnej.
Warto także zapoznać się z polecanymi zasobami do nauki Big Data i Hadoop.
Powodzenia! 👍
