Przewodnik dotyczący zapobiegania włamaniom do sieci
W dzisiejszym krajobrazie biznesowym dane stanowią fundament działania firm i organizacji. Ich wartość jest jednak w pełni realizowana dopiero wtedy, gdy są odpowiednio ustrukturyzowane i skutecznie zarządzane.
Z danych statystycznych wynika, że aż 95% przedsiębiorstw boryka się z trudnościami w zakresie zarządzania i organizacji danych nieustrukturyzowanych.
W odpowiedzi na to wyzwanie pojawia się eksploracja danych – proces, który umożliwia odkrywanie, analizowanie oraz wyodrębnianie istotnych wzorców i wartościowych informacji z obszernych zbiorów danych, które nie posiadają sprecyzowanej struktury.
Firmy wykorzystują specjalistyczne oprogramowanie do identyfikacji wzorców w rozległych zbiorach danych, co pozwala im lepiej poznać swoich klientów, zdefiniować docelowe grupy odbiorców oraz opracować skuteczne strategie biznesowe i marketingowe. Efektem tego jest wzrost sprzedaży i redukcja kosztów operacyjnych.
Jednakże, poza tymi korzyściami, kluczowym zastosowaniem eksploracji danych jest również wykrywanie oszustw oraz identyfikacja anomalii, czyli odchyleń od standardowego zachowania.
W dalszej części tego artykułu skupimy się na zagadnieniu wykrywania anomalii, szczegółowo analizując, w jaki sposób może ono przyczynić się do ochrony danych, zapobiegając naruszeniom bezpieczeństwa i włamaniom do sieci.
Czym jest wykrywanie anomalii i jakie są jego rodzaje?
Eksploracja danych, choć skupia się na poszukiwaniu powiązań, korelacji i tendencji, jest także doskonałym narzędziem do identyfikacji anomalii, czyli nietypowych punktów danych wyróżniających się w sieci.
Anomalie w kontekście eksploracji danych to te punkty, które różnią się od pozostałych elementów w zbiorze danych, odbiegając od normatywnego schematu zachowania.
Anomalie można podzielić na różne typy i kategorie, wśród których wyróżniamy:
- Zmiany w zdarzeniach: Obejmują one nagłe lub systematyczne odchylenia od wcześniejszego, typowego wzorca zachowania.
- Wartości odstające: To niewielkie, nieregularne odchylenia, które pojawiają się w sposób niesystematyczny podczas gromadzenia danych. Dzielą się one na wartości odstające globalne, kontekstowe i zbiorowe.
- Dryfy: Są to stopniowe, jednostronne i długoterminowe zmiany w obrębie zbioru danych.
W konsekwencji, wykrywanie anomalii stanowi niezwykle przydatną technikę przetwarzania danych, która znajduje zastosowanie w identyfikacji nieuczciwych transakcji, analizie przypadków z niezrównoważeniem danych oraz w diagnozowaniu chorób, co przyczynia się do tworzenia bardziej precyzyjnych modeli analizy danych.
Na przykład, firma może monitorować swoje przepływy pieniężne w poszukiwaniu nietypowych lub powtarzających się transakcji na nieznanym koncie bankowym, co jest sygnałem do przeprowadzenia szczegółowego dochodzenia w celu wykrycia potencjalnych oszustw.
Jakie korzyści przynosi wykrywanie anomalii?
Wykrywanie anomalii w zachowaniu użytkowników znacząco podnosi poziom bezpieczeństwa systemów, czyniąc je bardziej dokładnymi i precyzyjnymi.
Dzięki analizie i interpretacji różnorodnych informacji dostarczanych przez systemy zabezpieczeń, możliwa staje się skuteczna identyfikacja zagrożeń i potencjalnych niebezpieczeństw w sieci.
Oto kluczowe zalety wykrywania anomalii dla firm:
- Wykrywanie zagrożeń cybernetycznych i naruszeń danych w czasie rzeczywistym, dzięki algorytmom sztucznej inteligencji, które nieustannie skanują dane w poszukiwaniu nietypowych wzorców.
- Szybsze i łatwiejsze śledzenie nietypowych działań i wzorców w porównaniu z ręcznym poszukiwaniem anomalii, co pozwala zaoszczędzić czas i nakład pracy potrzebny do rozwiązania problemów bezpieczeństwa.
- Redukcja ryzyka operacyjnego poprzez identyfikację błędów, takich jak nagłe spadki wydajności, zanim one wystąpią.
- Minimalizacja poważnych szkód biznesowych dzięki szybkiemu wykrywaniu anomalii, gdyż bez odpowiedniego systemu firmy mogą potrzebować tygodni lub nawet miesięcy, aby zidentyfikować potencjalne zagrożenia.
W związku z powyższym, wykrywanie anomalii jest bezcennym narzędziem dla firm, które przechowują rozległe zbiory danych klientów oraz informacje biznesowe, ponieważ umożliwia identyfikację możliwości rozwoju, a także eliminację zagrożeń bezpieczeństwa i wąskich gardeł operacyjnych.
Jakie są techniki wykrywania anomalii?
Wykrywanie anomalii wykorzystuje szereg procedur i algorytmów uczenia maszynowego, które monitorują dane i wykrywają potencjalne zagrożenia.
Poniżej przedstawiamy główne techniki stosowane w wykrywaniu anomalii:
# 1. Techniki uczenia maszynowego

Techniki uczenia maszynowego wykorzystują zaawansowane algorytmy do analizy danych i wykrywania nietypowych wzorców. Do najczęściej stosowanych algorytmów należą:
- Algorytmy klastrowania
- Algorytmy klasyfikacji
- Algorytmy głębokiego uczenia
W praktyce, w wykrywaniu anomalii i zagrożeń często wykorzystuje się maszyny wektorów nośnych (SVM), grupowanie k-średnich oraz autoenkodery.
#2. Techniki statystyczne
Techniki statystyczne wykorzystują modele, które identyfikują nietypowe wzorce w danych, takie jak nieoczekiwane wahania wydajności maszyny, co pozwala wykryć wartości odbiegające od normy.
Typowe metody statystyczne wykrywania anomalii obejmują testowanie hipotez, IQR, wynik Z, zmodyfikowany wynik Z, oszacowanie gęstości, wykres pudełkowy, analizę wartości ekstremalnych oraz histogram.
#3. Techniki eksploracji danych

Techniki eksploracji danych wykorzystują klasyfikację i grupowanie danych do identyfikacji anomalii w zbiorach danych. Popularne metody to klastrowanie widmowe, klastrowanie oparte na gęstości oraz analiza głównych składowych.
Algorytmy klastrowania grupują punkty danych w klastry na podstawie ich podobieństwa, co ułatwia wykrywanie anomalii, które wykraczają poza te grupy.
Z kolei algorytmy klasyfikacji przypisują punkty danych do wcześniej zdefiniowanych kategorii, a następnie identyfikują punkty, które nie pasują do żadnej z nich.
#4. Techniki oparte na regułach
Techniki wykrywania anomalii oparte na regułach wykorzystują zbiór wcześniej zdefiniowanych reguł do identyfikacji nieprawidłowości w danych.
Techniki te są stosunkowo proste i łatwe w konfiguracji, jednak mogą być mniej elastyczne i mniej skuteczne w adaptacji do zmieniających się wzorców danych.
Na przykład, można zaprogramować system, aby oznaczał transakcje przekraczające określoną wartość jako podejrzane.
#5. Techniki specyficzne dla domeny
Techniki specyficzne dla domeny pozwalają na wykrywanie anomalii w konkretnych systemach danych. Chociaż są bardzo efektywne w danej dziedzinie, mogą być mniej wydajne w innych obszarach.
Na przykład, można stworzyć techniki specjalnie do wyszukiwania nieprawidłowości w transakcjach finansowych, które jednak mogą nie sprawdzić się przy wykrywaniu spadków wydajności maszyn.
Dlaczego uczenie maszynowe jest niezbędne w wykrywaniu anomalii?
Uczenie maszynowe odgrywa kluczową rolę w skutecznym wykrywaniu anomalii.
Większość firm i organizacji musi obecnie przetwarzać ogromne ilości danych, od tekstu i informacji o klientach, po pliki multimedialne.
Ręczne przeglądanie wszystkich transakcji i danych generowanych w każdej sekundzie jest praktycznie niemożliwe. Dodatkowo, wiele firm zmaga się z wyzwaniem uporządkowania nieustrukturyzowanych danych.
W tym kontekście, narzędzia i techniki uczenia maszynowego są nieocenione w gromadzeniu, oczyszczaniu, porządkowaniu, analizowaniu i przechowywaniu ogromnych ilości danych.
Algorytmy uczenia maszynowego zapewniają elastyczność w stosowaniu i łączeniu różnych technik, co prowadzi do uzyskania najlepszych wyników.
Ponadto, uczenie maszynowe usprawnia procesy wykrywania anomalii i oszczędza cenne zasoby.
Oto dodatkowe korzyści wynikające z zastosowania uczenia maszynowego w wykrywaniu anomalii:
- Ułatwienie skalowania wykrywania anomalii poprzez automatyczną identyfikację wzorców, bez konieczności ręcznego programowania.
- Możliwość dostosowania algorytmów do zmieniających się wzorców danych, co zapewnia ich niezawodność i wydajność.
- Efektywne przetwarzanie dużych i złożonych zbiorów danych, co umożliwia skuteczne wykrywanie anomalii, nawet w trudnych przypadkach.
- Wczesna identyfikacja anomalii, co pozwala zaoszczędzić czas i zasoby.
- Wyższa dokładność wykrywania anomalii w porównaniu z tradycyjnymi metodami.
Podsumowując, wykrywanie anomalii w połączeniu z uczeniem maszynowym umożliwia szybsze i bardziej precyzyjne wykrywanie nieprawidłowości, co pozwala na zapobieganie zagrożeniom bezpieczeństwa i złośliwym naruszeniom.
Jakie algorytmy uczenia maszynowego wykorzystuje się do wykrywania anomalii?
Anomalie i wartości odstające można wykrywać za pomocą różnych algorytmów eksploracji danych, które służą do klasyfikacji, grupowania oraz uczenia się reguł asocjacyjnych.
Algorytmy te dzielą się na dwie kategorie – nadzorowane i nienadzorowane algorytmy uczenia się.
Uczenie nadzorowane
Uczenie nadzorowane opiera się na algorytmach takich jak maszyny wektorów nośnych, regresja logistyczna i liniowa, a także klasyfikacja wieloklasowa. Algorytmy te są trenowane na danych z etykietami, co oznacza, że zbiór danych treningowych zawiera zarówno normalne dane wejściowe, jak i odpowiadające im dane wyjściowe. Pozwala to na stworzenie modelu predykcyjnego, który jest w stanie generować prognozy dla nowych, nieznanych danych.
Zastosowania uczenia nadzorowanego to rozpoznawanie obrazu i mowy, modelowanie predykcyjne oraz przetwarzanie języka naturalnego.
Uczenie nienadzorowane
W uczeniu nienadzorowanym nie wykorzystuje się oznaczonych danych. Algorytm samodzielnie odkrywa złożone procesy i struktury danych, bez dostarczania konkretnych wskazówek dotyczących uczenia się.
Uczenie nienadzorowane znajduje zastosowanie w wykrywaniu anomalii, szacowaniu gęstości oraz kompresji danych.
Przyjrzyjmy się teraz kilku popularnym algorytmom wykrywania anomalii, opartym na uczeniu maszynowym.
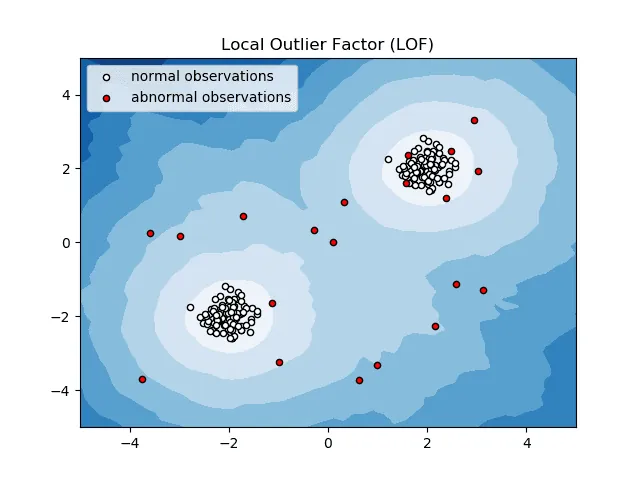
Lokalny współczynnik odstający (LOF)
Lokalny współczynnik odstający, czyli LOF, to algorytm wykrywania anomalii, który analizuje gęstość lokalnych danych, aby określić, czy dany punkt danych jest anomalią.
 Źródło: scikit-learn.org
Źródło: scikit-learn.org
Algorytm ten porównuje lokalną gęstość danego elementu z gęstością jego sąsiadów, analizując obszary o podobnej gęstości i identyfikując te elementy, których gęstość jest wyraźnie mniejsza – są to właśnie anomalie.
Innymi słowy, gęstość otoczenia anomalii różni się od gęstości otoczenia sąsiadujących z nią punktów. Stąd też, algorytm LOF jest często nazywany algorytmem wykrywania wartości odstających opartym na gęstości.
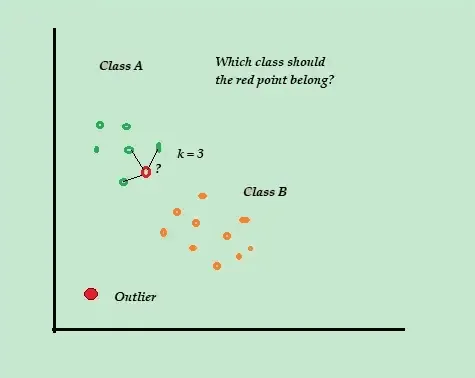
K-najbliższy sąsiad (K-NN)
K-NN to prosty algorytm klasyfikacji i nadzorowanego wykrywania anomalii, który jest łatwy do wdrożenia. Algorytm ten przechowuje wszystkie dostępne przykłady i dane, a następnie klasyfikuje nowe przykłady na podstawie metryk odległości.
 Źródło: w kierunkudatascience.com
Źródło: w kierunkudatascience.com
Algorytm K-NN jest nazywany "leniwym uczniem", ponieważ nie przeprowadza żadnych obliczeń podczas procesu uczenia. Przechowuje on jedynie oznaczone dane treningowe.
Gdy pojawia się nowy, nieoznaczony punkt danych, algorytm sprawdza K najbliższych punktów danych treningowych, aby wykorzystać je do sklasyfikowania i określenia klasy nowego punktu.
Algorytm K-NN wykorzystuje następujące metody w celu określenia najbliższych punktów danych:
- Odległość euklidesowa do pomiaru odległości dla danych ciągłych.
- Odległość Hamminga do pomiaru bliskości dwóch ciągów tekstowych dla danych dyskretnych.
Na przykład, jeśli zbiór danych treningowych składa się z dwóch etykiet, A i B, i pojawi się nowy punkt danych, algorytm obliczy odległość między tym punktem a wszystkimi punktami w zbiorze. Następnie wybierze punkty, które są mu najbliższe.
Załóżmy, że K=3, a 2 z 3 najbliższych punktów są oznaczone jako A. W takim przypadku, nowy punkt danych zostanie oznaczony jako należący do klasy A.
Algorytm K-NN jest szczególnie przydatny w dynamicznych środowiskach, gdzie często wymagane są aktualizacje danych.
Jest to popularny algorytm wykrywania anomalii i eksploracji tekstu, znajdujący zastosowanie w finansach i biznesie do wykrywania nieuczciwych transakcji.
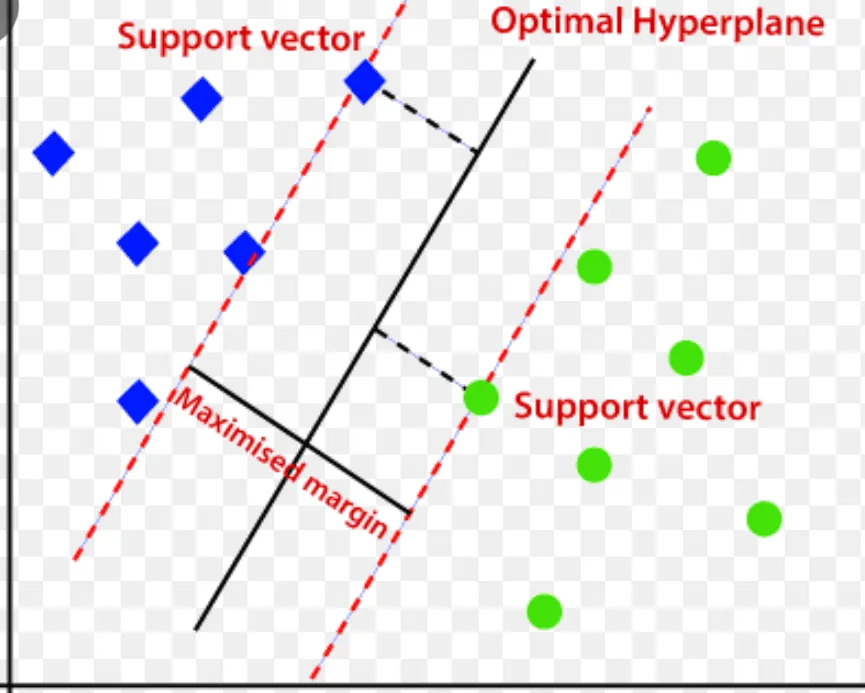
Maszyna wektorów nośnych (SVM)
Maszyna wektorów nośnych to nadzorowany algorytm wykrywania anomalii, który znajduje szerokie zastosowanie w problemach regresji i klasyfikacji.
Wykorzystuje on wielowymiarową hiperpłaszczyznę do podziału danych na dwie grupy – nowe i normalne. Hiperpłaszczyzna stanowi granicę decyzyjną, która oddziela normalne dane od anomalii.
 Źródło: www.analyticsvidhya.com
Źródło: www.analyticsvidhya.com
Odległość między punktami danych nazywana jest marginesem.
Algorytm SVM stara się zwiększyć tę odległość, wybierając optymalną hiperpłaszczyznę, która maksymalizuje margines, czyli odległość między dwoma klasami.
W kontekście wykrywania anomalii, SVM oblicza margines nowego punktu danych względem hiperpłaszczyzny.
Jeśli margines przekracza określony próg, nowa obserwacja jest uznawana za anomalię. Jeśli natomiast jest mniejszy od progu, jest klasyfikowana jako normalna.
Algorytmy SVM są bardzo efektywne w obsłudze wielowymiarowych i złożonych zbiorów danych.
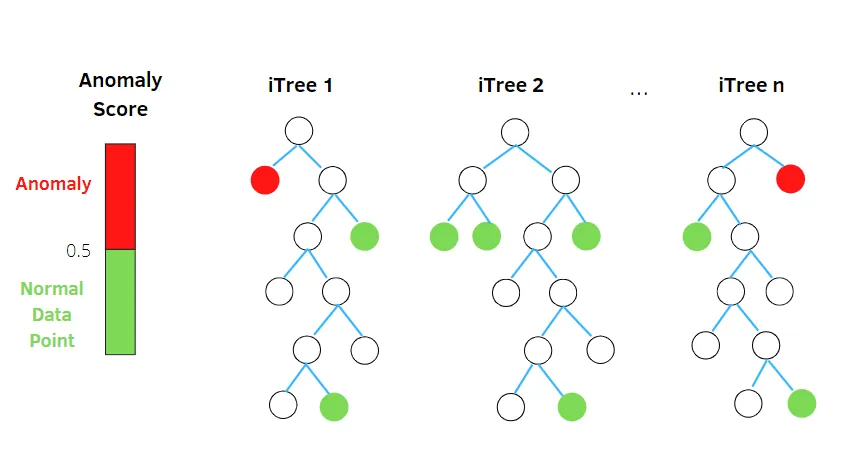
Las izolacji
Isolation Forest to nienadzorowany algorytm wykrywania anomalii, oparty na koncepcji losowego klasyfikatora lasu.
 Źródło: Betterprogramming.pub
Źródło: Betterprogramming.pub
Algorytm ten losowo dzieli podpróbkowane dane w strukturze drzewa na podstawie losowych atrybutów. Konstruuje on kilka drzew decyzyjnych w celu wyizolowania obserwacji. Dana obserwacja jest uznawana za anomalię, jeśli jest wyizolowana na mniejszej liczbie drzew.
Innymi słowy, algorytm lasu izolacyjnego dzieli punkty danych na różne drzewa decyzyjne, dbając o to, aby każda obserwacja była odizolowana od pozostałych.
Anomalie zazwyczaj znajdują się poza głównym klastrem punktów danych, co ułatwia ich identyfikację.
Algorytmy lasu izolacyjnego mogą z łatwością obsługiwać dane kategorialne i liczbowe, są szybkie w treningu i skuteczne w wykrywaniu anomalii w wielowymiarowych i dużych zbiorach danych.
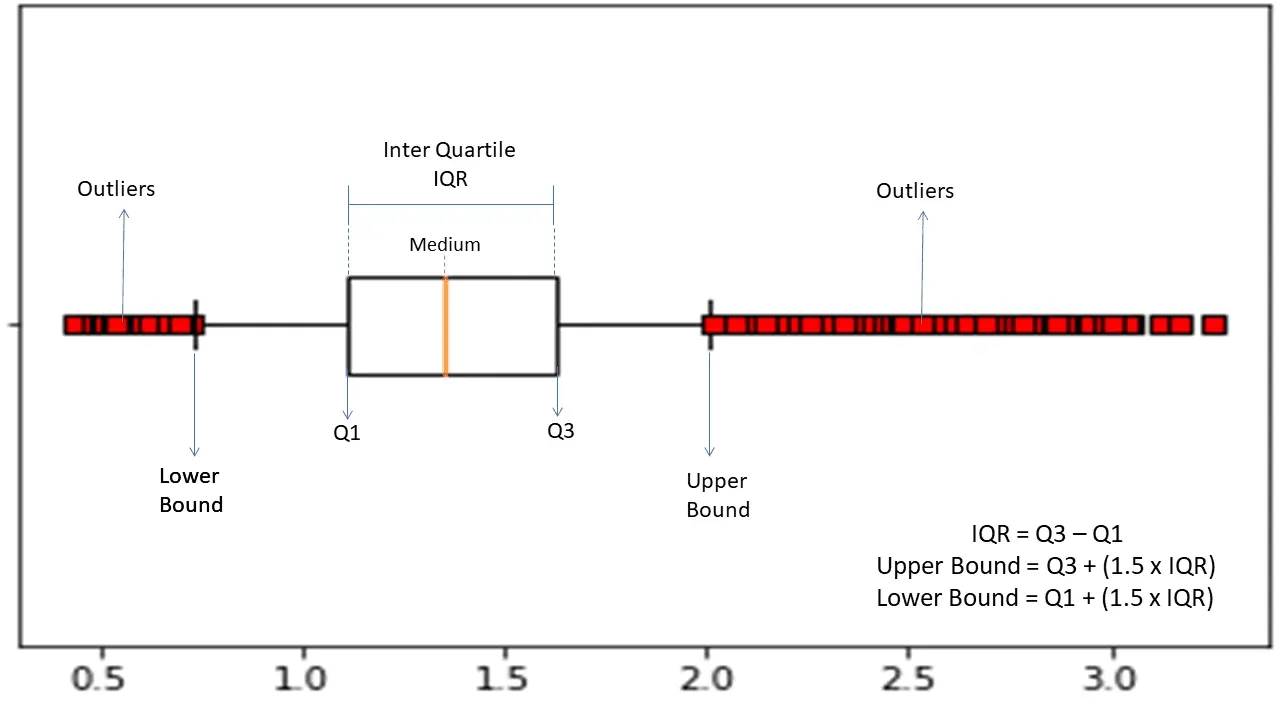
Zakres międzykwartylowy
Rozstęp międzykwartylowy (IQR) służy do pomiaru zmienności statystycznej i wykrywania anomalii w zbiorach danych poprzez podział danych na kwartyle.
 źródło: morioh.com
źródło: morioh.com
Algorytm sortuje dane w porządku rosnącym i dzieli zbiór na cztery równe części. Wartości oddzielające te części to Q1, Q2 i Q3, czyli pierwszy, drugi i trzeci kwartyl.
Oto rozkład percentylowy tych kwartyli:
- Q1 oznacza 25 percentyl danych.
- Q2 oznacza 50. percentyl danych.
- Q3 oznacza 75. percentyl danych.
IQR to różnica między trzecim i pierwszym percentylem zbioru danych, która reprezentuje 50% danych.
Do wykrywania anomalii za pomocą IQR, należy obliczyć IQR i zdefiniować dolną i górną granicę danych.
- Dolna granica: Q1 – 1,5 * IQR
- Górna granica: Q3 + 1,5 * IQR
Obserwacje wykraczające poza te granice są zazwyczaj uznawane za anomalie.
Algorytm IQR jest skuteczny w przypadku danych o nierównomiernym rozkładzie, gdzie struktura nie jest dobrze poznana.
Podsumowanie
Ryzyka związane z cyberbezpieczeństwem i naruszeniami danych stale rosną, a przewiduje się, że branża ta będzie się dalej rozwijać w nadchodzących latach. Szacuje się, że ataki cybernetyczne na urządzenia IoT podwoją się do 2025 roku.
Co więcej, do 2025 roku straty wynikające z cyberprzestępstw będą kosztować globalne firmy i organizacje około 10,3 bilionów dolarów rocznie.
Dlatego też techniki wykrywania anomalii stają się coraz bardziej popularne i niezbędne do wykrywania oszustw i zapobiegania włamaniom do sieci.
Ten artykuł przybliżył tematykę anomalii w eksploracji danych, przedstawił ich różne rodzaje oraz sposoby na zapobieganie włamaniom do sieci za pomocą technik wykrywania anomalii, opartych na uczeniu maszynowym.
Zachęcamy do zgłębienia wiedzy na temat macierzy nieporozumień w uczeniu maszynowym.
