Przewodnik krok po kroku dotyczący konfiguracji i uruchamiania
W dzisiejszym świecie systemy komputerowe każdego dnia generują ogromne ilości danych. Mówimy tu o milionach rekordów, obejmujących Twoje transakcje finansowe, zamówienia internetowe czy informacje przesyłane przez czujniki w Twoim samochodzie. Aby efektywnie przetwarzać te strumienie danych w czasie rzeczywistym i sprawnie przenosić rekordy między różnymi systemami w przedsiębiorstwie, niezbędne jest narzędzie takie jak Apache Kafka.
Apache Kafka, będąca otwartym oprogramowaniem do strumieniowego przetwarzania danych, charakteryzuje się zdolnością do obsługi ponad miliona rekordów na sekundę. Oprócz tej imponującej przepustowości, platforma Kafka oferuje wysoką skalowalność, niezawodność, minimalne opóźnienia oraz trwałą pamięć masową.
Firmy o globalnym zasięgu, takie jak LinkedIn, Uber czy Netflix, wykorzystują Apache Kafka do przetwarzania i przesyłania strumieniowego danych w czasie rzeczywistym. Najprostszym sposobem na rozpoczęcie przygody z Apache Kafka jest uruchomienie jej lokalnie na swoim komputerze. Pozwala to na bezpośrednie obserwowanie działania serwera Apache Kafka, a także na tworzenie i odbieranie wiadomości.
Dzięki praktycznemu doświadczeniu w uruchamianiu serwera, definiowaniu tematów oraz pisaniu kodu w języku Java przy użyciu klienta Kafka, zdobędziesz solidne podstawy do wykorzystania Apache Kafka w różnorodnych projektach związanych z przetwarzaniem danych.
Jak pobrać Apache Kafka na komputer osobisty?
Najnowszą wersję Apache Kafka znajdziesz pod tym oficjalnym linkiem. Pobrany plik będzie miał format .tgz. Po zakończeniu pobierania, konieczne będzie jego rozpakowanie.
Jeśli pracujesz na systemie Linux, otwórz terminal i przejdź do lokalizacji, w której zapisałeś pobrany plik. Następnie użyj poniższego polecenia:
tar -xzvf kafka_2.13-3.5.0.tgz
Po wykonaniu polecenia pojawi się nowy katalog o nazwie kafka_2.13-3.5.0. Przejdź do niego, używając komendy:
cd kafka_2.13-3.5.0
Teraz, wpisując polecenie ls, możesz zobaczyć zawartość tego folderu.
Użytkownicy systemu Windows mogą postępować analogicznie. Jeśli nie masz dostępu do polecenia tar, możesz skorzystać z narzędzia takiego jak WinZip, aby rozpakować archiwum.
Jak uruchomić Apache Kafka na komputerze lokalnym?
Po pobraniu i rozpakowaniu Apache Kafka, jesteśmy gotowi do jej uruchomienia. Nie jest wymagana instalacja – możesz od razu zacząć korzystać z niej za pomocą wiersza poleceń lub terminala.
Zanim rozpoczniesz pracę z Apache Kafka, upewnij się, że na Twoim systemie jest zainstalowana Java w wersji 8 lub nowszej, gdyż Kafka wymaga działającego środowiska Java.
#1. Uruchom serwer Apache Zookeeper
Pierwszym krokiem jest uruchomienie Apache Zookeeper. Jest on dostarczany razem z archiwum i służy do przechowywania konfiguracji oraz synchronizacji usług.
Będąc w katalogu, do którego rozpakowałeś archiwum, wprowadź następujące polecenie:
Dla użytkowników systemu Linux:
bin/zookeeper-server-start.sh config/zookeeper.properties
Dla użytkowników systemu Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Plik zookeeper.properties zawiera ustawienia konfiguracyjne serwera Apache Zookeeper. Możesz tam skonfigurować m.in. ścieżkę do lokalnego katalogu z danymi oraz port, na którym serwer będzie działał.
#2. Uruchom serwer Apache Kafka
Po uruchomieniu serwera Apache Zookeeper, kolejnym krokiem jest uruchomienie serwera Apache Kafka.
Otwórz nowe okno terminala lub wiersza poleceń i przejdź do katalogu, w którym rozpakowałeś pliki. Następnie uruchom serwer Apache Kafka za pomocą odpowiedniego polecenia:
Dla użytkowników Linuxa:
bin/kafka-server-start.sh config/server.properties
Dla użytkowników Windowsa:
bin/windows/kafka-server-start.bat config/server.properties
Serwer Apache Kafka jest teraz uruchomiony. Jeśli chcesz wprowadzić zmiany w domyślnej konfiguracji, możesz to zrobić edytując plik server.properties. Szczegółowe informacje na temat dostępnych opcji znajdziesz w oficjalnej dokumentacji.
Jak korzystać z Apache Kafka na komputerze lokalnym?
Teraz możesz zacząć korzystać z Apache Kafka na swoim lokalnym komputerze do tworzenia i przesyłania wiadomości. Ponieważ serwery Apache Zookeeper i Apache Kafka są już uruchomione, zobaczmy, jak utworzyć pierwszy temat, zapisać pierwszą wiadomość i ją odczytać.
Jakie kroki należy wykonać, aby utworzyć temat w Apache Kafka?
Zanim utworzysz swój pierwszy temat, wyjaśnijmy, czym on właściwie jest. W Apache Kafka temat to logiczny magazyn danych, ułatwiający strumieniowanie danych. Można go traktować jako kanał, przez który dane przesyłane są między różnymi komponentami systemu.
Temat obsługuje wielu producentów i wielu konsumentów – więcej niż jeden system może zapisywać i odczytywać dane z tematu. W przeciwieństwie do innych systemów przesyłania wiadomości, każda wiadomość z tematu może być wykorzystana więcej niż raz. Dodatkowo, można określić czas przechowywania wiadomości.
Załóżmy, że jeden system (producent) generuje dane transakcji bankowych, a inny system (konsument) wykorzystuje te dane do wysyłania powiadomień użytkownikowi. Do ułatwienia tej komunikacji potrzebny jest temat.
Otwórz nowe okno terminala lub wiersza poleceń i przejdź do katalogu, w którym rozpakowałeś archiwum. Następujące polecenie utworzy temat o nazwie "transakcje":
Dla użytkowników Linuxa:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Dla użytkowników Windowsa:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
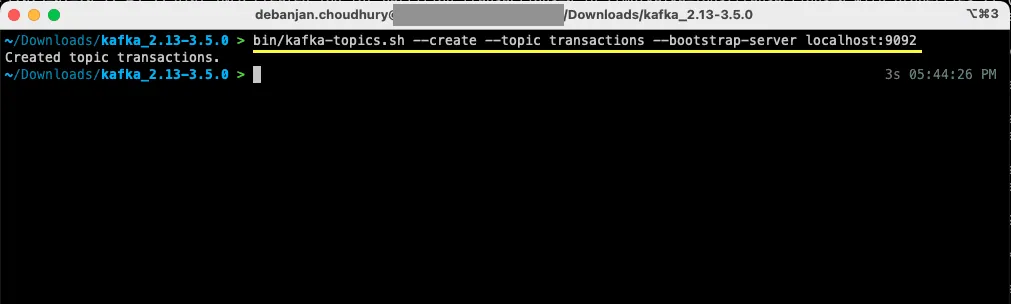
Twój pierwszy temat został utworzony. Możesz teraz zacząć tworzyć i odbierać wiadomości.
Jak wysłać wiadomość do Apache Kafka?
Mając gotowy temat, możesz teraz wysłać pierwszą wiadomość. Otwórz nowe okno terminala lub wiersza poleceń, lub wykorzystaj to, którego użyłeś do utworzenia tematu. Upewnij się, że jesteś w odpowiednim katalogu z rozpakowanymi plikami. Możesz użyć wiersza poleceń, aby zapisać wiadomość w temacie, używając poniższego polecenia:
Dla użytkowników systemu Linux:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Dla użytkowników systemu Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Po uruchomieniu tego polecenia, terminal lub wiersz poleceń będzie oczekiwał na Twoje wpisy. Wpisz pierwszą wiadomość i zatwierdź ją klawiszem Enter.
> This is a transactional record for $100

Twoja pierwsza wiadomość została wysłana do Apache Kafka na Twojej lokalnej maszynie. Teraz możesz ją odczytać.
Jak odczytać wiadomość z Apache Kafka?
Mając utworzony temat i wysłaną wiadomość, możesz teraz ją odczytać.
Apache Kafka umożliwia podłączenie wielu konsumentów do tego samego tematu. Każdy konsument może należeć do grupy konsumentów, identyfikowanej logicznie. Na przykład, jeśli dwie usługi potrzebują tych samych danych, mogą one korzystać z różnych grup konsumentów.
Jeśli natomiast masz dwie instancje tej samej usługi, chcesz uniknąć dwukrotnego odczytu i przetworzenia tej samej wiadomości. W takim przypadku obydwie instancje będą korzystać z tej samej grupy konsumentów.
W terminalu lub wierszu poleceń upewnij się, że znajdujesz się w odpowiednim katalogu. Użyj następującego polecenia, aby uruchomić konsumenta:
Dla użytkowników systemu Linux:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Dla użytkowników systemu Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
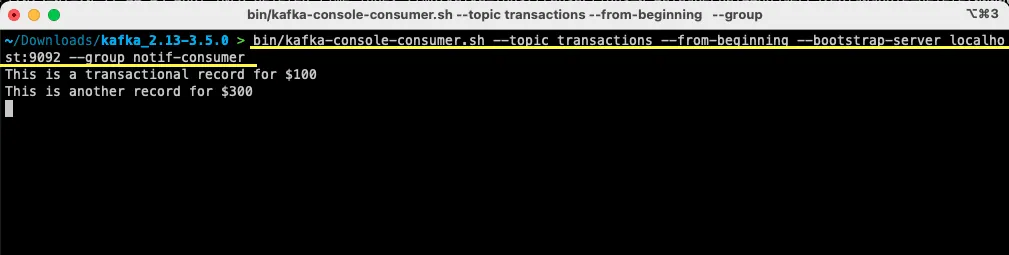
W terminalu pojawi się wiadomość, którą wcześniej wysłałeś. Wykorzystałeś już Apache Kafka do odczytania pierwszej wiadomości.
Polecenie kafka-console-consumer przyjmuje wiele argumentów. Sprawdźmy, co każdy z nich oznacza:
- –topic wskazuje temat, z którego będziesz odczytywał wiadomości.
- –from-beginning instruuje konsumenta, aby rozpoczął odczytywanie od pierwszej dostępnej wiadomości.
- Twój serwer Apache Kafka jest określony za pomocą opcji –bootstrap-server.
- Dodatkowo możesz określić grupę konsumentów za pomocą parametru –group.
- W przypadku braku parametru grupy konsumentów jest ona generowana automatycznie.
Teraz, gdy klient konsoli jest uruchomiony, możesz spróbować wysłać nowe komunikaty. Zobaczysz, jak są odczytywane i pojawiają się w Twoim terminalu.
Po utworzeniu tematu i pomyślnym wysłaniu i odczytaniu wiadomości, zintegrujmy to z aplikacją Java.
Jak stworzyć producenta i konsumenta Apache Kafka przy użyciu Javy?
Zanim zaczniesz, upewnij się, że na swoim komputerze masz zainstalowaną wersję Java 8 lub nowszą. Apache Kafka oferuje bibliotekę klienta, która ułatwia komunikację. Jeśli do zarządzania zależnościami korzystasz z Mavena, dodaj następującą zależność do pliku pom.xml:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Bibliotekę możesz również pobrać ze strony Maven Repository i dodać ją do ścieżki klas Java.
Po dodaniu biblioteki, otwórz wybrany przez Ciebie edytor kodu. Zobaczmy, jak możesz uruchomić swojego producenta i konsumenta przy użyciu Javy.
Utwórz producenta Apache Kafka w Javie
Mając bibliotekę kafka-clients, możesz rozpocząć tworzenie producenta Kafka.
Stwórzmy klasę o nazwie SimpleProducer.java. Będzie ona odpowiedzialna za wysyłanie wiadomości na wcześniej utworzony temat. Wewnątrz tej klasy utworzysz instancję org.apache.kafka.clients.producer.KafkaProducer. Następnie użyjesz tego producenta do wysyłania wiadomości.
Do utworzenia producenta Kafka potrzebny jest host i port serwera Apache Kafka. Ponieważ pracujesz na komputerze lokalnym, hostem będzie localhost. Jeśli nie zmieniłeś domyślnych właściwości, portem będzie 9092. Zapoznaj się z poniższym kodem, który pomoże Ci utworzyć producenta:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Zauważysz, że ustawiane są trzy właściwości. Przeanalizujmy każdą z nich:
- BOOTSTRAP_SERVERS_CONFIG określa adres serwera Apache Kafka.
- KEY_SERIALIZER_CLASS_CONFIG informuje producenta, w jakim formacie wysyłać klucze wiadomości.
- Format wysyłania samej wiadomości jest definiowany za pomocą właściwości VALUE_SERIALIZER_CLASS_CONFIG.
Ponieważ będziesz wysyłał wiadomości tekstowe, obie właściwości ustawione są na użycie StringSerializer.class.
Aby wysłać wiadomość do tematu, musisz użyć metody producer.send(), która przyjmuje ProducerRecord. Poniższy kod przedstawia metodę, która wyśle wiadomość do tematu i wypisze odpowiedź wraz z przesunięciem wiadomości.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Po dodaniu całego kodu, możesz teraz wysyłać wiadomości do swojego tematu. Możesz użyć metody main, aby to przetestować, jak pokazano w poniższym kodzie:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
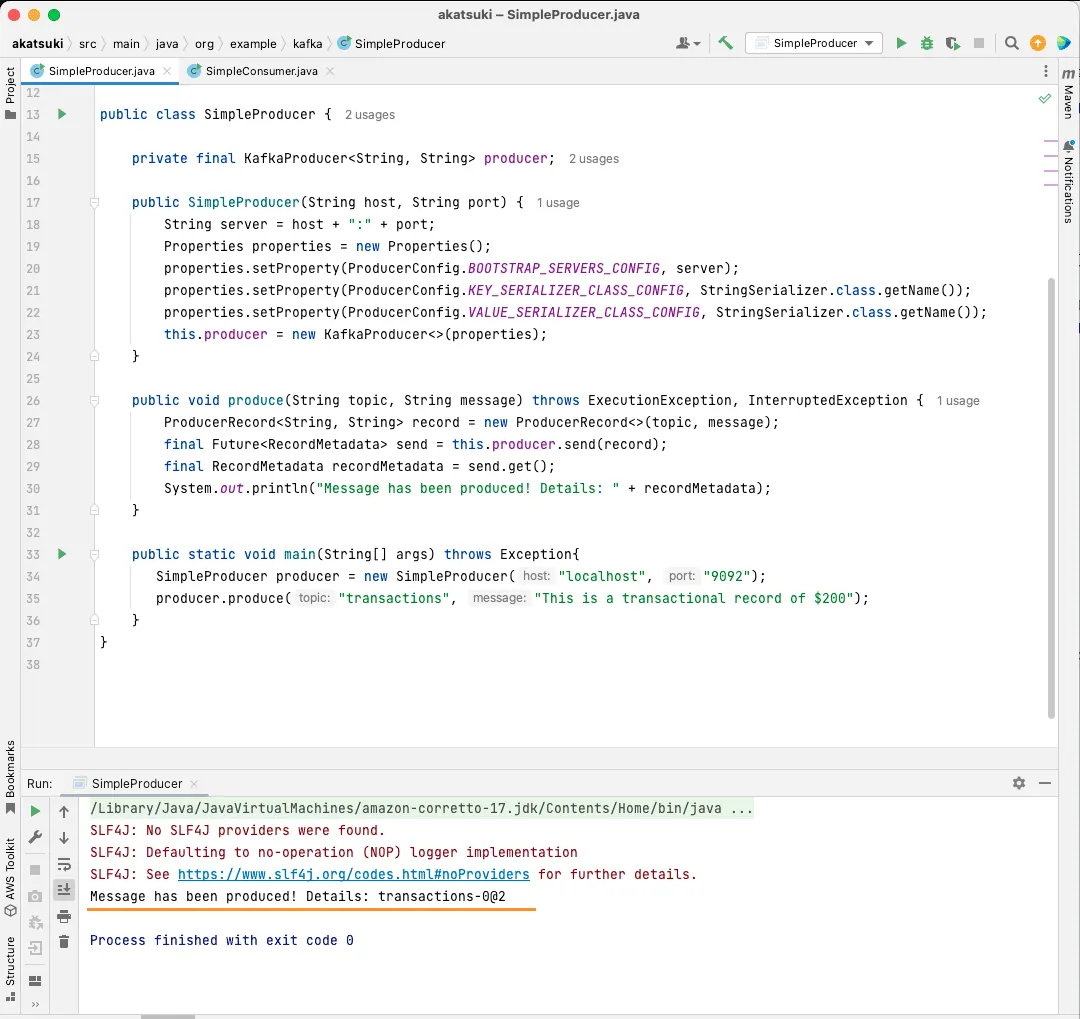
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
W tym kodzie tworzysz obiekt SimpleProducer, który łączy się z serwerem Apache Kafka na komputerze lokalnym. Wewnątrz wykorzystuje on KafkaProducer do wysyłania wiadomości tekstowych do Twojego tematu.
Utwórz konsumenta Apache Kafka w Javie
Nadszedł czas, aby stworzyć konsumenta Apache Kafka przy użyciu klienta Java. Utwórz klasę o nazwie SimpleConsumer.java. Następnie utwórz konstruktor dla tej klasy, który zainicjuje org.apache.kafka.clients.consumer.KafkaConsumer. Do utworzenia konsumenta potrzebny jest adres hosta i port, na którym działa serwer Apache Kafka. Dodatkowo, potrzebujesz grupy konsumentów i tematu, z którego chcesz odczytywać wiadomości. Wykorzystaj fragment kodu podany poniżej:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Podobnie jak producent Kafka, konsument Kafka również przyjmuje obiekt Properties. Przyjrzyjmy się wszystkim ustawieniom:
- BOOTSTRAP_SERVERS_CONFIG informuje konsumenta, gdzie działa serwer Apache Kafka.
- Grupa konsumentów jest określona za pomocą GROUP_ID_CONFIG.
- AUTO_OFFSET_RESET_CONFIG pozwala określić, od którego miejsca konsument ma zacząć odczytywać wiadomości.
- KEY_DESERIALIZER_CLASS_CONFIG informuje konsumenta o typie klucza wiadomości.
- VALUE_DESERIALIZER_CLASS_CONFIG informuje konsumenta o typie samej wiadomości.
Ponieważ będziesz odczytywał wiadomości tekstowe, właściwości deserializatora są ustawione na StringDeserializer.class.
Teraz będziesz odczytywać wiadomości z wybranego tematu. Dla uproszczenia, po odczytaniu wiadomości, zostanie ona wypisana na konsoli. Zobaczmy, jak można to zrealizować za pomocą poniższego kodu:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Ten kod będzie nieustannie sprawdzał temat. Gdy otrzymasz jakikolwiek rekord konsumenta, wiadomość zostanie wyświetlona. Przetestuj działanie swojego konsumenta w metodzie main. Uruchomisz aplikację Java, która będzie odczytywała dane z tematu i wyświetlała komunikaty. Zatrzymaj aplikację, aby zakończyć działanie konsumenta.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Po uruchomieniu tego kodu zobaczysz, że konsumuje on nie tylko wiadomość wysłaną przez Twojego producenta Java, ale także te, które wysłałeś za pomocą producenta konsoli. Dzieje się tak, ponieważ parametr AUTO_OFFSET_RESET_CONFIG został ustawiony na "earliest".
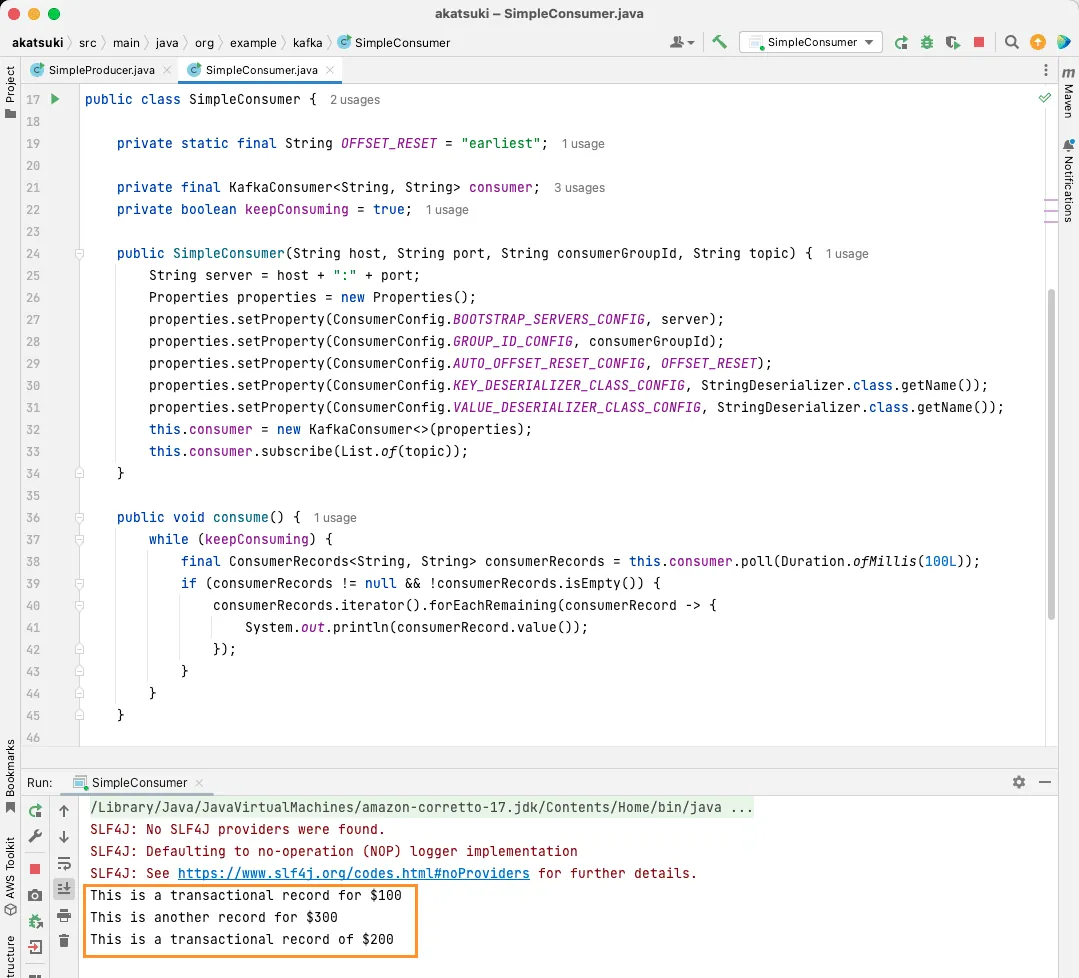
Gdy SimpleConsumer działa, możesz użyć producenta konsoli lub aplikacji Java SimpleProducer, aby wysłać dodatkowe wiadomości do tematu. Zobaczysz, jak są one odczytywane i wypisywane na konsoli.
Zaspokój wszystkie potrzeby związane z potokami danych z Apache Kafka
Apache Kafka pozwala na łatwą obsługę wszystkich wymagań związanych z potokami danych. Dzięki konfiguracji Apache Kafka na lokalnym komputerze możesz poznać wszystkie jego funkcje. Ponadto, oficjalny klient Java umożliwia wydajne pisanie, łączenie i komunikację z serwerem Apache Kafka.
Będąc uniwersalnym, skalowalnym i wydajnym systemem do strumieniowego przesyłania danych, Apache Kafka może naprawdę zrewolucjonizować Twoje podejście do przetwarzania danych. Możesz go używać do lokalnego rozwoju lub zintegrować z systemami produkcyjnymi. Tak jak łatwo jest go skonfigurować lokalnie, tak samo jego konfiguracja dla większych aplikacji nie jest dużym wyzwaniem.
Jeśli szukasz platform do strumieniowego przesyłania danych, możesz przejrzeć listę najlepszych platform do analizy i przetwarzania w czasie rzeczywistym.
